Reactor事件驱动的两种设计实现:面向对象 VS 函数式编程
Reactor事件驱动的两种设计实现:面向对象 VS 函数式编程
这里的函数式编程的设计以muduo为例进行对比说明;
Reactor实现架构对比
面向对象的设计类图如下:

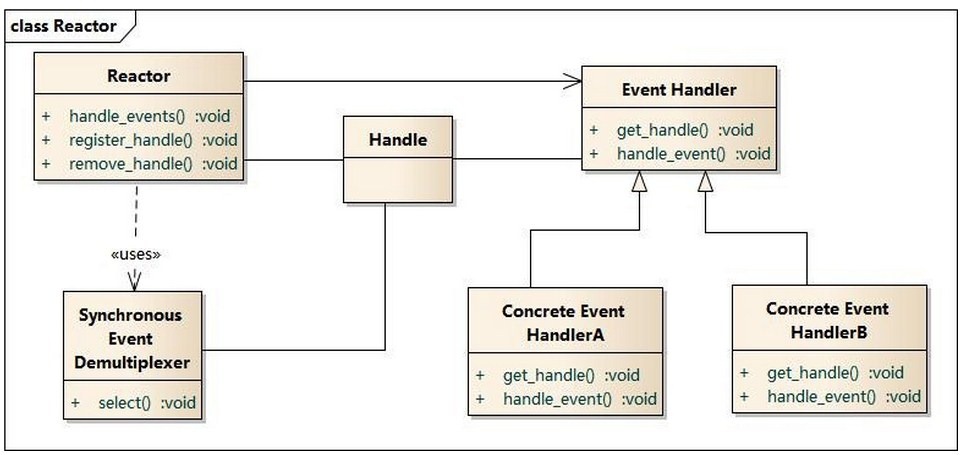
函数式编程以muduo为例,设计类图如下:
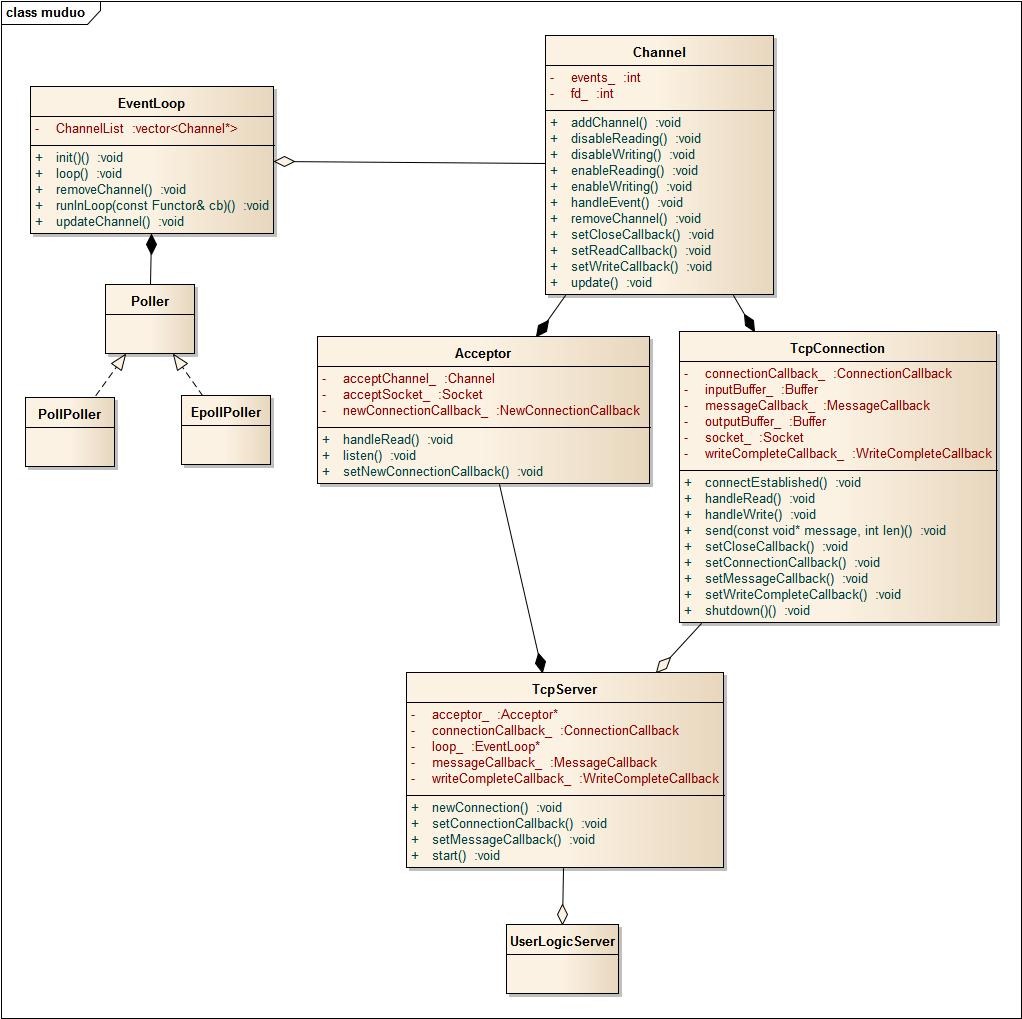
面向对象的Reactor方案设计
我们先看看面向对象的设计方案,想想为什么这么做;
拿出Reactor事件驱动的模式设计图,对比来看,清晰明了;
从左边开始,事件驱动,需要一个事件循环和IO分发器,EventLoop和Poller很好理解;为了让事件驱动支持多平台,Poller上加一个继承结构,实现select、epoller等IO分发器选用;
Channel是要监听的事件封装类,核心成员:fd文件句柄;
成员方法围绕着fd展开展开,如关注fd的读写事件、取消关注fd的读写事件;
核心方法:
enableReading/Writing;
disableReading/Writing;
以及事件到来后的处理方法:
handleEvent;
在OO设计这里,handleEvent设计成一个虚函数,回调上层实际的数据处理;
AcceptChannel和ConnetionChannel派生自Channel,负责实际的网络数据处理;根据职责的不同而区分,AcceptChannel用于监听套接字,接收新连接请求;有新的请求到来时,生成新的socket并加入到事件循环,关注读事件;
ConnetionChannel用于真实的用户数据处理,处理用户的读写请求;涉及到具体的数据处理,当然,在这里会需要用到应用层的缓存区;
比较困难的是用户逻辑层的设计;放在哪里合适?
先看看需求,用户逻辑层需要知道的事件点(在这之后可能会有应用层的逻辑):
连接建立、消息到来、消息发送完毕、连接关闭;
这四个事件的源头是Channel的handleEvent(),直接调用者应该Channel的派生类(AcceptChannel和ConnetionChannel),貌似可以将用户逻辑层的指针放到Channel里;
且不说架构上是否合理,单是实现上右边Channel这一块(含AcceptChannel和ConnetionChannel)对用户是透明的,用户只需要关注以上四个事件点,底层的细节用户层并不关心(比如是否该在事件循环中关注某个事件,取消关注某个事件,对用户都是透明的),所以外部用户无法直接将用户逻辑层的指针给Channel;
想想用户与网络库的接口在哪里?
IO分发器对用户也是透明的,用户可见就是EventLoop,在main方法中:
EventLoop loop;
loop.loop();用户逻辑层也就只有通过EventLoop与Channel的派生类关联上;
这样,就形成的最终的设计类图,在main方法中:
UserLogicCallBack callback;
EventLoop loop(&callback); //在定义 EventLoop时,将callback的指针传入,供后续使用;
loop.loop();而网络层调用业务层代码时,则通过eventloop_的过渡调用到业务逻辑的函数;
比如ConnetionChannel中数据到达的处理:
eventloop_->getCallBack()->onMessage(this);函数式编程的Reactor设计
函数式编程中,类之间的关系主要通过组合来实现,而不是通过派生实现;
整个类图中仅有Poller处使用了继承关系;其它的都没有使用;
这也是函数式编程的一个设计理念,更多的使用组合而不是继承来实现类之间的关系,而支撑其能够这样设计的根源在于function()+bind()带来的函数自由传递,实现回调非常简单;
而OO设计中,只能使用基于虚函数/多态来实现回调,不可避免的使用继承结构;
下面再看看各个类的实现;
事件循环EventLoop和IO分发器没有区别;
Channel的职责也和上面类似,封装事件,所不同的是,Channel不再是继承结构中的基类,而是作为一个实体;
这样,handleEvent方法就不再是一个纯虚函数,而是包含具体的逻辑处理,当然,只有最基本的事件判断,然后调用上层的读写回调:
void Channel::handleEvent()
{
if (revents_ & (POLLIN | POLLPRI | POLLRDHUP))
{
if (readCallback_) readCallback_();
}
if (revents_ & POLLOUT)
{
if (writeCallback_) writeCallback_();
}
}这样的关键是设置一堆回调函数,通过boost::function()+boost::bind()可以轻松的做到;
Acceptor 和TcpConnection
Acceptor类,这个对应到上面的AcceptChannel,但实现不是通过继承,而是通过组合实现;
Acceptor用于监听,关注连接,建立连接后,由TCPConnection来接管处理;
这个类没有业务处理,用来处理监听和连接请求到来后的逻辑;
所有与事件循环相关的都是channel,Acceptor不直接和EventLoop打交道,所以在这个类中需要有一个channel的成员,并包含将channel挂到事件循环中的逻辑(listen());
TcpConnection,处理连接建立后的收发数据;业务处理回调完成;
TCPServer
TCPServer就是胶水,作用有二:
- 作为最终用户的接口方,和外部打交道通过TCPServer交互,而业务逻辑处理将回调函数传入到底层,这种传递函数的方式犹如数据的传递一样自然和方便;
- 作用Acceptor和TcpConnection的粘合剂,调用Acceptor开始监听连接并设置回调,连接请求到来后,在回调中新建TcpConnection连接,设置TcpConnection的回调(将用户的业务处理回调函数传入,包括:连接建立后,读请求处理、写完后的处理,连接关闭后的处理),从这里可以看到,业务逻辑的传递就跟数据传递一样,多么漂亮;
示例对比
通过一个示例来体会这两种实现中回调实现的差别;
示例:分析读事件到来时,底层如何将消息传递给用户逻辑层函数来处理的?
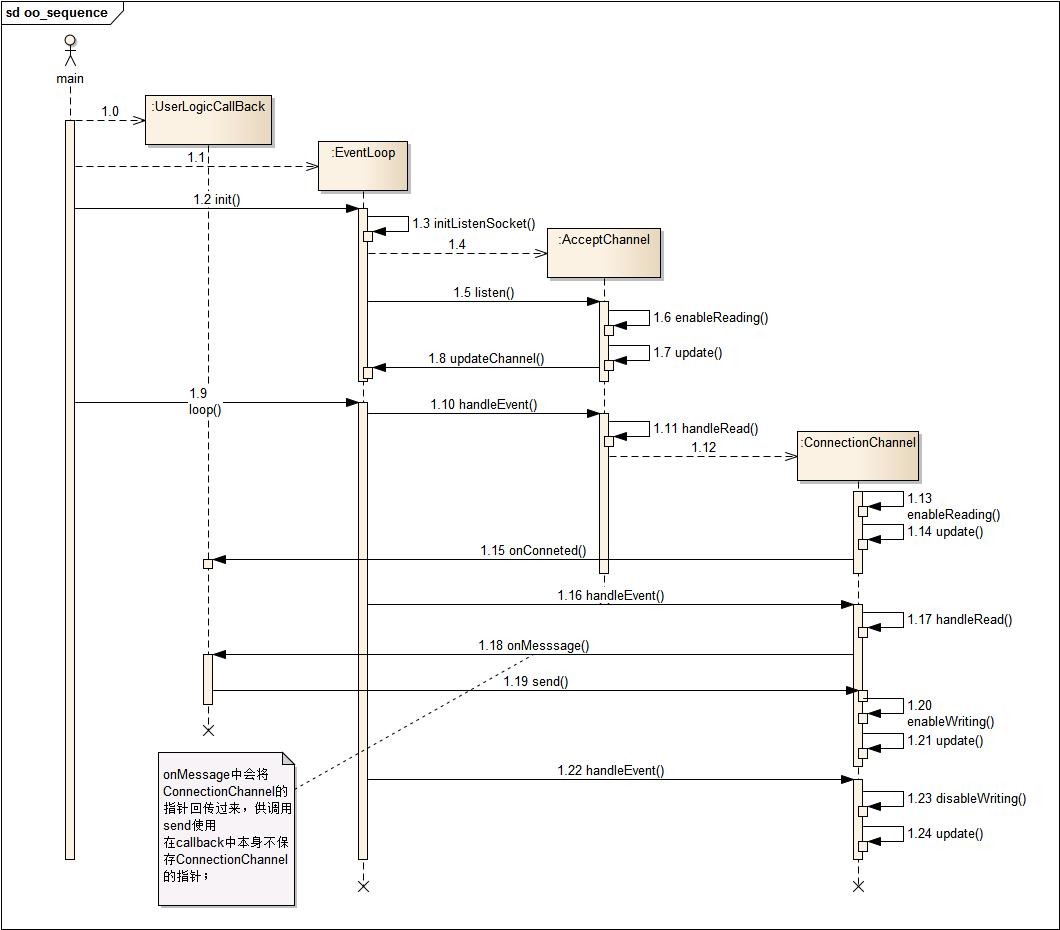
OO实现
channel作为事件的监听接口,加入到事件循环中,当读事件到来时,需要调用
ConnetionChannel上的handleEvent();而异步数据的读请求最终需要业务逻辑层来判断是否读到相应的数据,这就需要从ConnetionChannel中调用用户逻辑层上的OnMessage();
看看这段逻辑的OO实现序列图:

代码层面的实现:
定义用户逻辑处理类UserLogicCallBack,接收消息的处理函数为onMessage();
我们关注最终底层是如何调用到业务逻辑层的onMessage()的;
int main()
{
UserLogicCallBack urlLogic;
EventLoop loop(urlLogic);//将用户逻辑对象与事件循环对象关联起来
loop.loop();
}callback_用户逻辑层的对象在EventLoop初始化时传入:
class EventLoop{
EventLoop(CallBack & callback):
callback_(callback)
{
}
CallBack* getCallBack()
{
return &callback_;
}
CallBack& callback_; //回调方法基类
}当读事件到来,在ConnectionChannel中通过eventloop对象作为桥梁,回调消息业务处理onMesssage();
void ConnectionChannel::handleRead(){
int savedErrno = 0;
//返回缓存区可读的位置,返回所有读到的字节,具体到是否收全,
//是否达到业务需要的数据字节数,由业务层来判断处理
ssize_t n = inputBuffer_.readFd(fd_, &savedErrno);
if (n > 0)
{
//通过eventloop作为中介,调用业务层的回调逻辑
loop_->getCallBack()->onMesssage(this,&inputBuffer_);
}
else if (n == 0)
{
handleClose();
}
else
{
errno = savedErrno;
handleError();
}
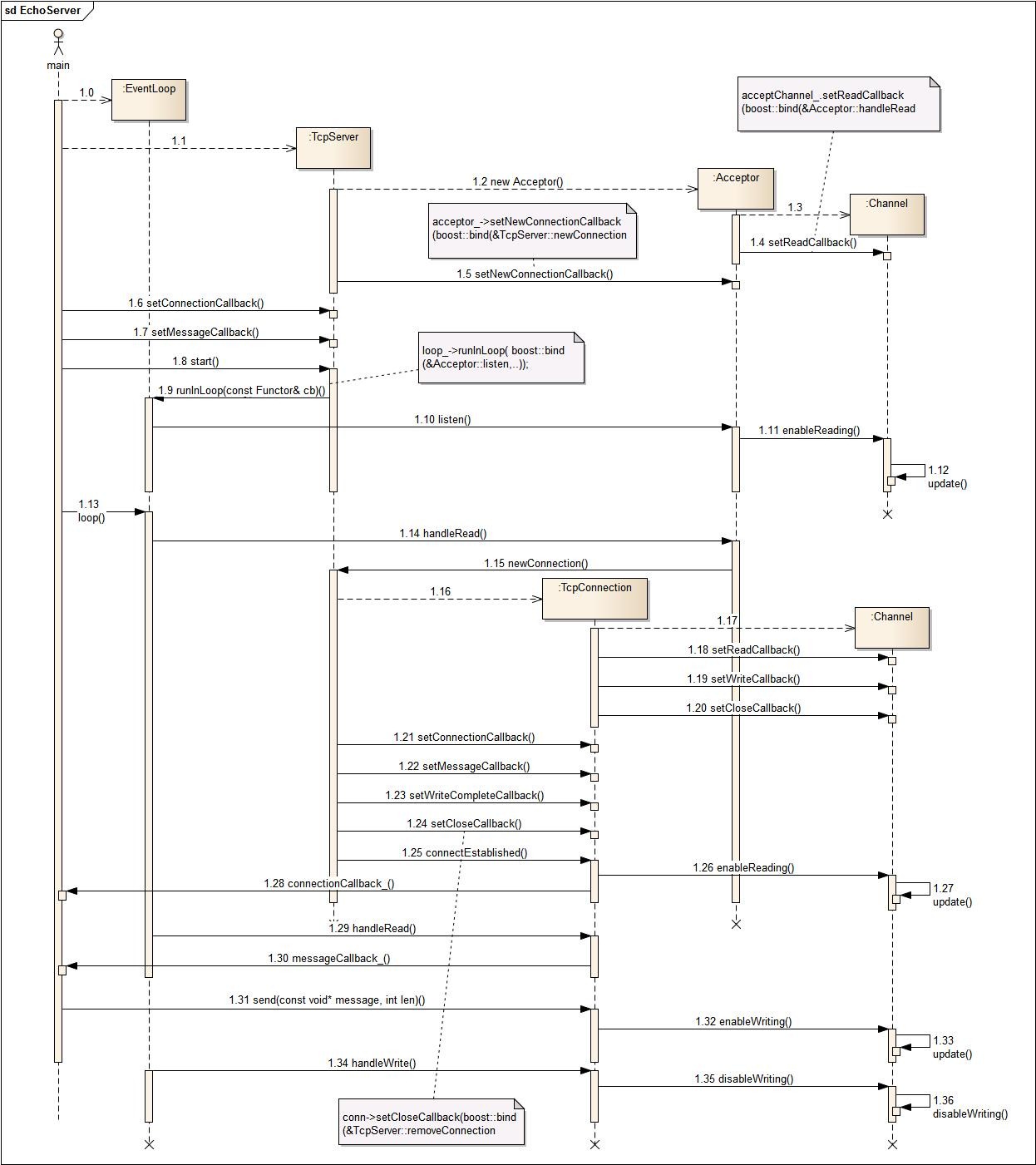
}函数式编程实现
而muduo的回调,使用boost::function()+boost::bind()实现,通过这两个神器,将使用者和实现者解耦;
通过TcpServer,将用户逻辑层的函数传递到底层;读事件到来,回调用户逻辑;
以下是时序

代码层面,我们看看用户逻辑层的代码是如何传入的:
UserLogicCallBack中包含TcpServer的对象;
TcpServer server_;在构造函数中,将onMessage传递给TcpServer,这是第一次传递:
UserLogicCallBack::UserLogicCallBack(muduo::net::EventLoop* loop,
const muduo::net::InetAddress& listenAddr)
: server_(loop, listenAddr, "UserLogicCallBack")
{
server_.setConnectionCallback(
boost::bind(&UserLogicCallBack::onConnection, this, _1));
//这里将onMessage传递给TcpServer
server_.setMessageCallback(
boost::bind(&UserLogicCallBack::onMessage, this, _1, _2, _3));
}TcpServer中的相关细节:
class TcpServer{
void setMessageCallback(const MessageCallback& cb)
{ messageCallback_ = cb; }
typedef boost::function<void (const TcpConnectionPtr&,
Buffer*,
Timestamp)> MessageCallback;
MessageCallback messageCallback_;
};TcpServer新建连接时,将用户层的回调函数继续往底层传递,这是第二次传递:
void TcpServer::newConnection(int sockfd, const InetAddress& peerAddr)
{
TcpConnectionPtr conn(new TcpConnection(ioLoop,
connName,
sockfd,
localAddr,
peerAddr));
conn->setConnectionCallback(connectionCallback_);
// 这里将onMessage()传递给TcpConnection
conn->setMessageCallback(messageCallback_);
conn->setWriteCompleteCallback(writeCompleteCallback_);
conn->setCloseCallback(boost::bind(&TcpServer::removeConnection, this, _1));
ioLoop->runInLoop(boost::bind(&TcpConnection::connectEstablished, conn));
}通过这两次传递,messageCallback_作为成员变量保存在TcpConnection中;
当读事件到来时,TcpConnection中就可以直接调用业务层的回调逻辑:
void TcpConnection::handleRead(Timestamp receiveTime)
{
//返回缓存区可读的位置,返回所有读到的字节,具体到是否收全,
//是否达到业务需要的数据字节数,由业务层来判断处理
ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno);
if (n > 0)
{
//回调业务层的逻辑
messageCallback_(shared_from_this(), &inputBuffer_, receiveTime);
}
else if (n == 0)
{
handleClose();
}
else
{
errno = savedErrno;
handleError();
}
}完整时序详见最后一节;源代码来自muduo库;
两者的时序图对比
Reactor的面向对象编程时序:
Reacotr的函数式编程时序:
结论
在面向对象的设计中,事件底层回调上层逻辑,本来和loop这个发动机没有任何关系的一件事,却需要使用它来作为中转;EventLoop作为回调的中间桥梁,实在是迫不得已的实现;
而muduo的设计中加入了TcpServer这一胶水层,整个架构就清晰多了;
boost::function()+boost::bind()让我们在回调的实现上有了更大的自由度,不用再依赖于基于虚函数的多态继承结构;但更大的自由度,也更容易带来糟糕的设计,使用boost::function()+boost::bind()基于对象的设计,还需要多多体会,多加应用;
Posted by: 大CC | 30DEC,2015
博客:blog.me115.com [订阅]
Github:大CC
Reactor事件驱动的两种设计实现:面向对象 VS 函数式编程的更多相关文章
- javascript消除字符串两边空格的两种方式,面向对象和函数式编程。python oop在调用时候的优点
主要是javascript中消除字符串空格,比较两种方式的不同 //面向对象,消除字符串两边空格 String.prototype.trim = function() { return this.re ...
- 【转】Reactor与Proactor两种模式区别
转自:http://www.cnblogs.com/cbscan/articles/2107494.html 两种IO多路复用方案:Reactor and Proactor 一般情况下,I/O 复用机 ...
- ACE_linux:Reactor与Proactor两种模式的区别
一.概念: Reactor与Proactor两种模式的区别.这里我们只关注read操作,因为write操作也是差不多的.下面是Reactor的做法: 某个事件处理器宣称它对某个socket上的读事件很 ...
- 测试和恢复性的争论:面向对象vs.函数式编程
Michael Feathers最近的博文在博客社区引发了一场异常激烈的论战.Feathers发表言论说一些面向对象编程语言的内嵌特性有助于测试的进行,并且使用面向对象编程语言编写的代码更容易恢复. ...
- 【JavaScript】两种常见JS面向对象写法
基于构造函数 function Circle(r) { this.r = r; } Circle.PI = 3.14159; Circle.prototype.area = function() { ...
- Python学习一(面向对象和函数式编程)
学习了一周的Python,虽然一本书还没看完但是也收获颇多,作为一个老码农竟然想起了曾经荒废好久的园子,写点东西当做是学习笔记吧 对Python的语法看的七七八八了,比较让我关注的还是他编程的思想,那 ...
- 两种高性能I/O设计模式(Reactor/Proactor)的比较
原文出处: Alex Libman 译文出处:潘孙友 欢迎分享原创到伯乐头条 综述 这篇文章探讨并比较两种用于TCP服务器的高性能设计模式. 除了介绍现有的解决方案,还提出了一种更具伸缩性,只 ...
- [转]两种高性能I/O设计模式(Reactor/Proactor)的比较
[原文地址:http://www.cppblog.com/pansunyou/archive/2011/01/26/io_design_patterns.html] 综述 这篇文章探讨并比较两种用于T ...
- Perl 面向对象编程的两种实现和比较:
<pre name="code" class="html">https://www.ibm.com/developerworks/cn/linux/ ...
随机推荐
- lua table integer index 特性
table.maxn (table) Returns the largest positive numerical index of the given table, or zero if the t ...
- http缓存之304 last-modified,cache-control:max-age,Etag等
因最近客户端慢的问题,系统分析了下http协议缓存问题.本文主要记录总结http缓存相关知识. 1. 讨论涉及的要点 访问返回类 > 访问返回200 OK > 访问返回200 (from ...
- VS快速生成JSON数据格式对应的实体
有固定好的Json数据格式,你还在手动敲对应的实体吗?有点low了!步入正题,这是一个json字符串,先去验证JSON数据格式(http://www.bejson.com/)如下: { & ...
- Linux上 .vimrc文件
在Linux上面对VIM编辑器的格式的设置通常可以提升工作效率,下面对工作机器上的.vimrc文件的内容进行一总结,以备后续的查询 set smarttab set tabstop=4 set shi ...
- Ext.Net_1 配置ext.net所需的环境
一.配置ext.net有两种方法,一是通过自动配置,即:工具--->Nuget包管理器--->管理解决方案的Nuget程序包--->搜索EXT.NET--->安装,安装完后,环 ...
- eclipse中Maven创建WEB项目
刚刚学到Maven的时候总是容易忽视到一些创建Maven项目是的步骤, 这里记录笔者熟悉一种,直接创建Maven Project 下面开始吧--- 选择web-app,没得说,然后那些groupID ...
- Android驱动开发前的准备
最近看了一些Android驱动开发前需要知道的资料,收获很多,接下来就谈谈我自己的一些心得体会. Android在近几年时间发展迅速,已经成为智能手机操作系统的老大.不过,因为Android原生的代码 ...
- Python对时间的转换
1.将字符串的时间转换为时间戳 方法: a = "2013-10-10 23:40:00" 将其转换为时间数组 import time timeArray = time.strpt ...
- Java多线程开发系列之四:玩转多线程(线程的控制2)
在上节的线程控制(详情点击这里)中,我们讲解了线程的等待join().守护线程.本节我们将会把剩下的线程控制内容一并讲完,主要内容有线程的睡眠.让步.优先级.挂起和恢复.停止等. 废话不多说,我们直接 ...
- SQL语句处理一些修改、新增、删除、修改属性操作(MySql)
方法一: 直接(手动)去修改数据库名称,数据库表名称,数据库列名称.列属性 方法二: 使用SQL语句去修改 -- 修改表名 ALTER TABLE tableName RENAME newTableN ...