15天玩转redis —— 第四篇 哈希对象类型
redis中的hash也是我们使用中的高频数据结构,它的构造基本上和编程语言中的HashTable,Dictionary大同小异,如果大家往后有什么逻辑需要用
Dictionary存放的话,可以根据场景优先考虑下redis哦,起码可以装装逼嘛,现在我默认你已经有装逼的冲动了,打开redis手册,看看有哪些我们用得到
的装逼方法。
一:常用方法
只要是一个数据结构,最基础的永远是CURD,redis中的insert和update,永远只需要set来替代,比如下面的Hset,如下图:

前面几篇文章我都没有挑选一个方法仔细讲解,其实也没什么好讲解的,就好似C#中的一个类的一个方法而已,知道传递一些啥参数就OK了,就比如要
说的HSet,它的格式如下:

接下来我在CentOS里面操作一下,
[administrator@localhost redis-3.0.]$ src/redis-cli
127.0.0.1:> clear 127.0.0.1:> hset person name jack
(integer)
127.0.0.1:> hset person age
(integer)
127.0.0.1:> hset person sex famale
(integer)
127.0.0.1:> hgetall person
) "name"
) "jack"
) "age"
) ""
) "sex"
) "famale"
127.0.0.1:> hkeys person
) "name"
) "age"
) "sex"
127.0.0.1:> hvals person
) "jack"
) ""
) "famale"
127.0.0.1:>
或许有人看了上面的console有一点疑惑,那就是前面有几个参数,比如person,name啦,然后才是value,如果你看了第一篇的话,你大概就明白了,
其实在redis的这个层面,它永远只有一个键,一个值,这个键永远都是字符串对象,也就是SDS对象,而值的种类就多了,有字符串对象,有队列对象,
还有这篇的hash对象,往后的有序集合对象等等,如果你还不明白的话,转化为C#语言就是。
var person=new Dictionary<string,string>();
person.Add("name","jack");
....
调用方法就是这么的简单,关键在于时不时的需要你看一看手册,其实最重要的是了解下它在redis源码中的原理就好了。
二:探索原理
hash的源代码是在dict.h源代码里面,枚举如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new 0. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
上面就是我们使用hash的源代码数据结构,接下来我来撸一撸其中的逻辑关系。
1. dict结构
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
这个结构是hash的真正的底层数据结构,可以看到其中有5个属性。
<1> dictType *type
可以看到它的类型是dictType,从上面你也可以看到,它是有枚举结构定义的,如下:
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
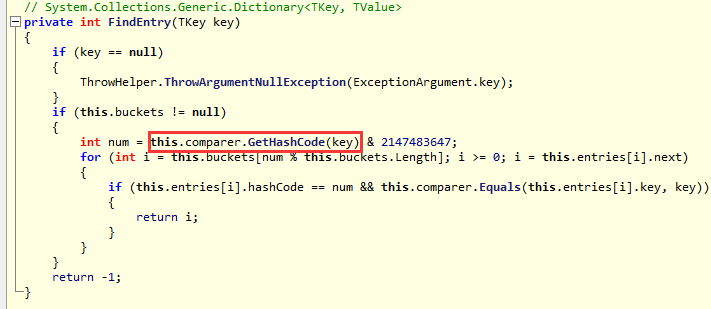
从上面这个数据结构中你可以看到里面都是一些方法,但是有一个非常重要的方法,那就是第一个hashFunction,可以看到它就是计算hash值的,
跟C#中的dictionary中求hash值一样一样的。
<2> dictht ht[2]
你可能会疑问,为什么这个属性是2个大小的数组呢,其实正真使用的是ht[0],而ht[1]是用于扩容hash表时的暂存数组,这一点也很奇葩,
同时也很精妙,redis为什么会这么做呢???仔细想想你可能会明白,扩容有两种方法,要么一次性扩容,要么渐进性扩容,后面这种扩容是什
么意思呢?就是我在扩容的同时不影响前端的CURD,我慢慢的把数据从ht[0]转移到ht[1]中,同时rehashindex来记录转移的情况,当全部转移
完成之后,将ht[1]改成ht[0]使用,就这么简单。
2. dicth结构
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
<1> dictEntry **table;
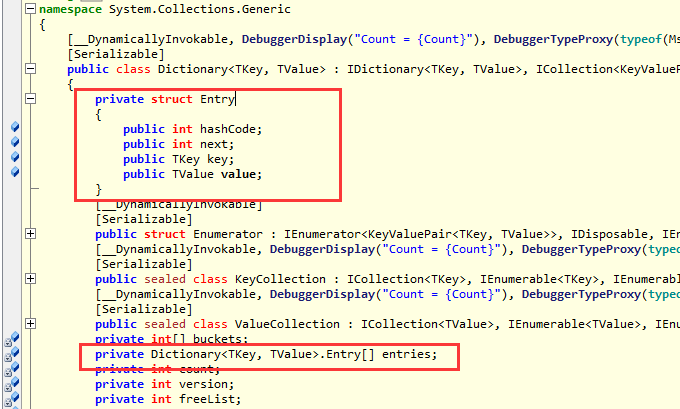
从上面这个结构体中,你可以看到一个非常重要的属性: dictEntry **table, 其中table是一个数组,数组类型是dictEntry,既然是一个数组,
那后面的三个属性就好理解了,size是数组的大小,sizemask和数组求模有关,used记录数组中已使用的大小,现在我们把注意力放在dictEntry这
个数组实体类型上面。
3. dictEntry结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
从这个数据结构上面你可以看到有三个大属性。
第一个就是: *key:它就是hash表中的key。
第二个就是: union的*val 就是hash的value。
第三个就是: *next就是为了防止hash冲突采用的挂链手段。
这个原理和C#中的Dictionary还是一样一样的。
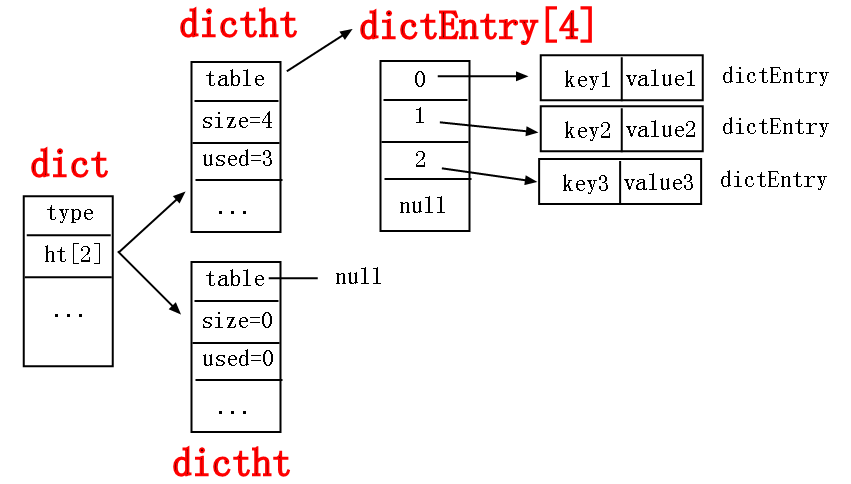
不知道你看懂了没有,如果总结上面描述的话,我可以画出如下的hash结构图。
好了,就此打住,去公司了。
15天玩转redis —— 第四篇 哈希对象类型的更多相关文章
- 15天玩转redis —— 第三篇 无敌的列表类型
据说60%的人使用redis看重的是redis中的list类型,那这个list有什么用呢???不用我说大家都明白,做队列使用呗,为什么用它呢,很简单呗, 因为有了它我就不需要专门的MQ产品啦,比如说 ...
- 15天玩转redis —— 第六篇 有序集合类型
今天我们说一下Redis中最后一个数据类型 “有序集合类型”,回首之前学过的几个数据结构,不知道你会不会由衷感叹,开源的世界真好,写这 些代码的好心人真的要一生平安哈,不管我们想没想的到的东西,在这个 ...
- 15天玩转redis —— 第五篇 集合对象类型
这篇我们来看看Redis五大类型中的第四大类型:“集合类型”,集合类型还是蛮有意思的,第一个是因为它算是只使用key的Dictionary简易版, 这样说来的话,它就比Dictionary节省很多内存 ...
- 15天玩转redis —— 第十篇 对快照模式的深入分析
我们知道redis是带有持久化这个能力了,那到底持久化成到哪里,持久化成啥样呢???这篇我们一起来寻求答案. 一:快照模式 或许在用Redis之初的时候,就听说过redis有两种持久化模式,第一种是S ...
- 15天玩转redis —— 第十一篇 让你彻底了解RDB存储结构
接着上一篇说,这里我们来继续分析一下RDB文件存储结构,首先大家都知道RDB文件是在redis的“快照”的模式下才会产生,那么如果 我们理解了RDB文件的结构,是不是让我们对“快照”模式能做到一个心中 ...
- 15天玩转redis —— 第八篇 你不得不会的事务玩法
我们都知道redis追求的是简单,快速,高效,在这种情况下也就拒绝了支持window平台,学sqlserver的时候,我们知道事务还算是个比较复杂的东西, 所以这吊毛要是照搬到redis中去,理所当然 ...
- 15天玩转redis —— 第七篇 同事的一次缓存操作引起对慢查询的认识
上个星期同事做一个业务模块,需要将一个80M的数据存入到redis缓存中,想法总是好的,真操作的时候遇到了HSet超时,我们使用的是C#的 StackExchange.Redis驱动. <red ...
- 15天玩转redis —— 第二篇 基础的字符串类型
我们都知道redis是采用C语言开发,那么在C语言中表示string都是采用char[]数组的,然后你可能会想,那还不简单,当我执行如下命令,肯定是直 接塞给char[]数组的. 如果你真的这么想的话 ...
- 15天玩转redis —— 第九篇 发布/订阅模式
本系列已经过半了,这一篇我们来看看redis好玩的发布订阅模式,其实在很多的MQ产品中都存在这样的一个模式,我们常听到的一个例子 就是邮件订阅的场景,什么意思呢,也就是说100个人订阅了你的博客,如果 ...
随机推荐
- 依据BOM和已经存在的文件生成其他种类的文件
在BOM中记录中有物料编码,物料名称,物料规格等,而且依据BOM已经生成了一些的文件,如采购规格书,这个时候需要生成相应的检验规格书模板,可以使用下面的VBA代码,具体代码如下: Function I ...
- [翻译]AKKA笔记 - ACTOR MESSAGING - REQUEST AND RESPONSE -3
上次我们看Actor消息机制,我们看到开火-忘记型消息发出(意思是我们只要发个消息给Actor但是不期望有响应). 技术上来讲, 我们发消息给Actors就是要它的副作用. 这就是这么设计的.除了不响 ...
- Redis集群~StackExchange.Redis(10月6号版1.1.608.0)连接Twemproxy支持Auth指令了
回到目录 对于StackExchange.Redis这个驱动来说,之前的版本在使用Proxy为Twemproxy代理时,它是不支持Password属性的,即不支持原始的Auth指令,而我也修改过源代码 ...
- Oracle VM VirtualBox配置文件
Linux 虚拟机配置文件分为两处. windows下: 1.用户名/.VirtualBox/ 这里面有2个配置文件: VirtualBox.xml 和 VirtualBox.xml-prev. 后面 ...
- 学习ASP.NET MVC(七)——我的第一个ASP.NET MVC 查询页面
在本篇文章中,我将添加一个新的查询页面(SearchIndex),可以按书籍的种类或名称来进行查询.这个新页面的网址是http://localhost:36878/Book/ SearchIndex. ...
- 快速入门系列--MVC--01概述
虽然使用MVC已经不少年,相关技术的学习进行了多次,但是很多技术思路的理解其实都不够深入.其实就在MVC框架中有很多设计模式和设计思路的体现,例如DependencyResolver类就包含我们常见的 ...
- 专为设计师而写的GitHub快速入门教程
专为设计师而写的GitHub快速入门教程 来源: 伯乐在线 作者:Kevin Li 原文出处: Kevin Li 在互联网行业工作的想必都多多少少听说过GitHub的大名,除了是最大的开源项目 ...
- javascript严格模式下的8点规则
[作用] [1]消除js语法的一些不合理.不严谨.不安全问题,减少怪异行为并保证代码运行安全 [2]提高编译器效率,增加运行速度 [使用] [1]整个脚本启用严格模式,在顶部执行:"use ...
- LeetCode:Find the Difference_389
LeetCode:Find the Difference [问题再现] Given two strings s and t which consist of only lowercase letter ...
- 【小型系统】抽奖系统-使用Java Swing完成
一.需求分析 1. 显示候选人照片和姓名. 2. 可以使用多种模式进行抽奖,包括一人单独抽奖.两人同时抽奖.三人同时抽奖. 3. 一个人可以在不同的批次的抽奖中获取一.二.三等奖,但是不能在同一批次抽 ...