COMET —— 常识Transformer用于自动知识图构建
《COMET:Commonsense Transformers for Automatic Knowledge Graph Construction》
任务
- 目的层面 —— 根据两个当前最常用的常识知识图ATOMIC和ConceptNet构建一个用于开发常识知识的自适应生成模型COMET,以协助完成常识知识的自我补充。
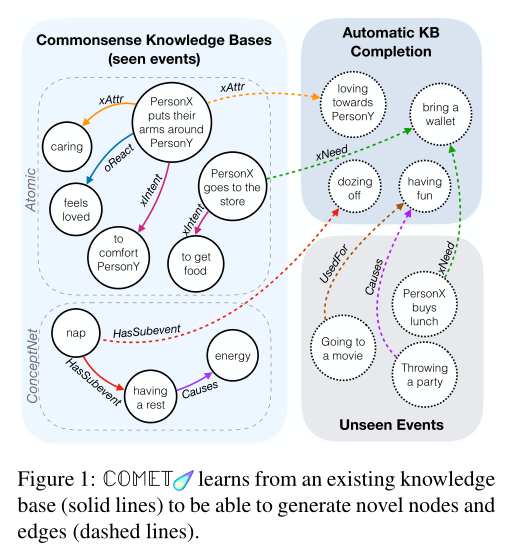
COMET是一个自适应框架,用于通过在知识元组的种子集上训练语言模型来从语言模型构建常识知识库。这些知识元组为COMET提供了必须学习的知识库结构和关系,COMET学习调整从预处理中学习的语言模型表示,以向种子知识图添加新的节点和边。
- 实验层面
- 训练知识库 —— 格式为 \(\{s ,r, o\}\)的自然语言元组, 其中 \(s\) 为元组的短语主语, \(r\) 为元组的关系, \(o\) 为元组的短语宾语。例如 \(\left(s="take \space a \space nap", r=Causes, o="have \space energy" \right)\)。
- 任务 —— 给定 \(s\) 和 \(r\) 作为输入, 要求生成 \(o\)。
Transformer语言模型
采用GPT的语言模型架构构建COMET。
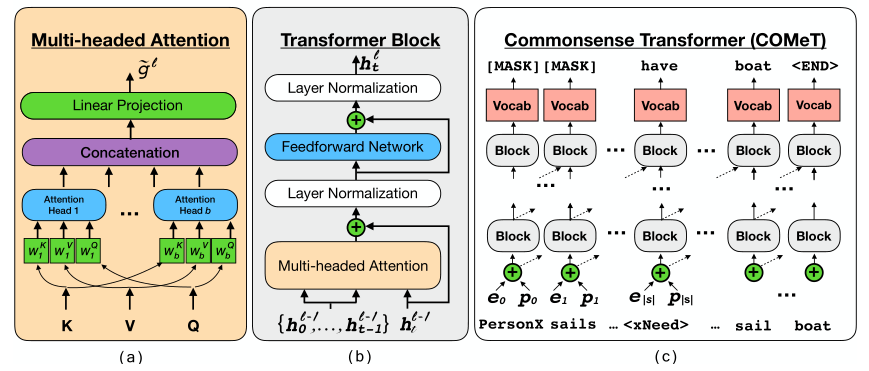
多头注意力
多头注意力机制 —— 顾名思义, 注意力由多个头部组成,每个头部使用查询 \(Q\) 和键 \(K\) 来计算一个唯一的点积注意力分布。
\]
其中,\(d_{k}\) 为 $ Q, \space K, \space V $ 的输入向量的维度。对于每个注意力头来说,在计算注意力之前, $ Q, \space K, \space V $ 被一组矩阵唯一映射。(对应a图蓝色部分)
\]
\(H_{i}\) 为单个注意力头的输出, \(W_{i}^{Q}, \space W_{i}^{K}, \space W_{i}^{V}\) 为特定头的关于 \(Q, \space K, \space V\) 的映射矩阵。
同时,多个注意力头的输出将被连接在一起。(对应a图紫色部分)
\]
其中 \(W^{O}\) 为输出的映射矩阵。
多头注意力的输入
如b图所示,当前层多头注意力的输入来源于上一层Transformer Block的输出。其中,输入的 \(Q\) 对应于上一层Block的输出 $ h_{t}^{l-1}$,而 \(K\) 和 \(V\) 对应于所有先前时间步长的前一层块的输出 \(\mathbf{h}_{t}^{l-1} = \left\{h^{l-1}\right\}_{<t}\) 。
\]
Transformer块
如b图所示,每个Transformer层包含一个架构上相同的Transformer Block块(尽管具有唯一的可训练参数),该Transformer Block对该块的输入应用以下变换:
\tilde{g}^{l} &=\mathrm{MULTIATTN}\left(h^{l-1}\right) \\
g^{l} &=\mathrm{LAYERNORM}\left(\tilde{g}^{l}+h^{l-1}\right) \\
\tilde{h}^{l} &=\mathrm{FFN}\left(g^{l}\right) \\
h^{l} &=\text { LAYERNORM }\left(\tilde{h}^{l}+g^{l}\right)
\end{aligned}
\]
其中,\(\tilde{g}^{l}\) 为多头注意力的输出,\(FFN\) 是一个两层的前馈神经网络(Feedforward Network), 而 \(LAYERNORM\)层是对多头注意力层输出以及前馈层输出的正则化操作,操作的输入包含一个残差连接,该连接将前一个操作的输出和输入相加。
输入编码器
文本嵌入 —— $ \mathbf{X}= { X^{s}, \space X^{r}, \space X^{o} } $, 其中 \(X^{s}, \space X^{r}, \space X^{o}\) 分别代表知识元组 \(\{s ,r, o\}\) 中每一项的单词序列,$ \mathbf{X}$ 为三者的串联。对于任意 \(x_{t} \in \mathbf{X}\) ,单词 \(x_{t}\) 的单词嵌入为 \(e_{t} = \sum x_{t}^{i}\) ,这里的 \(\sum\) 为向量和。
为何单词嵌入是一种向量和的形式?
这是因为GPT采用字节对编码(BPE)的方式构建字词,准确来说,GPT以子词表中子词作为词嵌入的基本单位的,这里输入的文本中的完整单词在字词表中可能是好几个字词之和,所以在表示完整单词的文本嵌入时,用的是子词嵌入向量的和。关于字节对编码的具体步骤,我之前的一篇文章中有提到,这里不再赘述。
位置嵌入 —— 因为transformer是一种自注意力模型,没有token顺序的概念,所以引入位置编码 \(p_{t}\) 来指示模型各个token在文本序列中所处的绝对位置。
最终输入 —— $ h_{t}^{l} = e_{t} + p_{t} $, 其中 \(l\) 表示transformer层数, \(t\) 代表第 \(t\) 个时间步。如c图所示,第一层的输入为: \(h^{0} = e_{0} + p_{0}\),
训练
- 训练任务 —— 给定知识元组 \(\{ s, \space r, \space o \}\),要求以 \(s\) 和 \(r\) 对应token的串接 \(\left[ X^{s}, X^{r} \right]\) 作为输入,模型需要学会生成 \(o\) 对应的那些tokens,即 $ X^{o}$ 。
- 损失函数 —— 标准的语言模型的损失函数,即对数似然函数。
\]
已知前 \(t-1\) 个生成的token \(x_{<t}\) ,当前第 \(t\) 个位置生成token \(x_{t}\)的概率为:
\]
其中,$ |s|, \space |r|, \space |o|$ 分别为短句主语、关系、宾语对应的token数目。 这里 \(h_{t}\) 表示在解码时GPT对\(x_{t}\) 的最终表示,\(\mathbf{W}_{\text {vocab}}\)是GPT使用的词汇表的嵌入矩阵。
实验数据集 —— ATOMIC 和 ConceptNet
输入构造
- ATOMIC —— 关系token只有一个

- ConceptNet —— 关系token可能有多个,引入第二组mask来分隔关系token和宾语token。

模型参数初始化 —— 使用GPT的预训练模型权重初始化模型,为了微调,往词汇表中加入了一些特殊的token。例如,关系嵌入(如oReact for ATOMIC和IsA for ConceptNet)是通过从标准正态分布中采样来初始化的。
超参设置
- 12 layers
- 768-dimensional hidden states
- 12 attention heads
- dropout 0.1
- activation fuction GeLU
- batch size 64
- lr 6.25e-5 (with a warmup period of 100 minibatches)
- decay method linear
实验细节
ATOMIC
数据集
- 877K 知识元组,涵盖围绕特定事件的社会常识知识
- 九个关系维度提炼事件中的常识知识
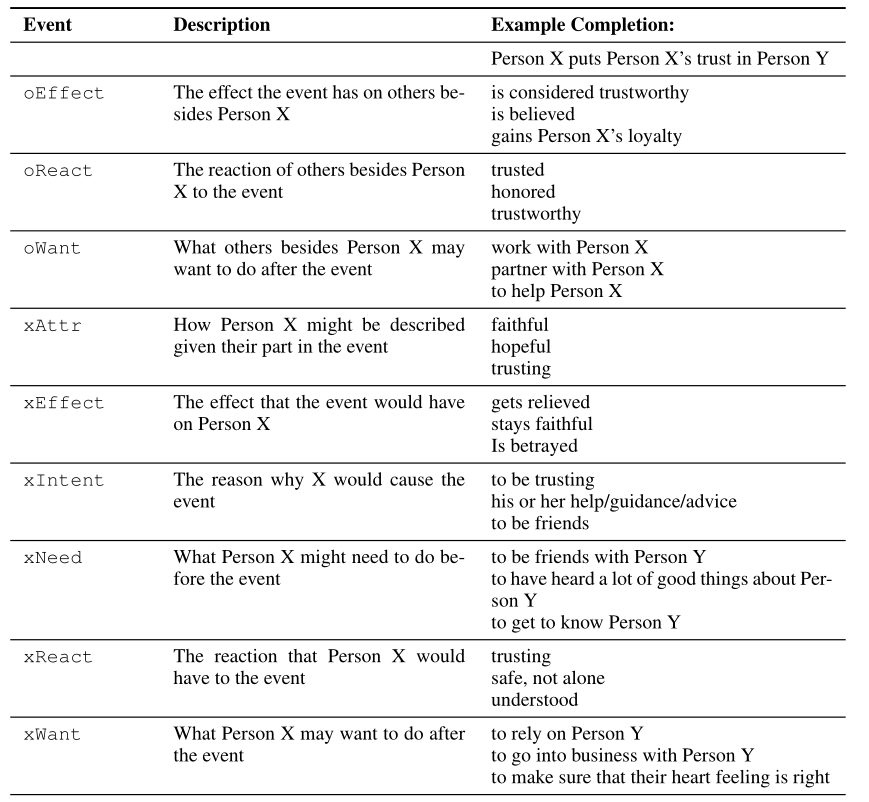
对应到实验中,ATOMIC事件(例如,“X goes to the store”)是短语主体 \(s\) ,xIntent是短语关系 \(r\) ,causes/effects(例如,“to get food”)是短语客体 \(o\)。训练集/开发集/测试集的数目分别为:710k/80k/87k
模型评估
- 自动评估
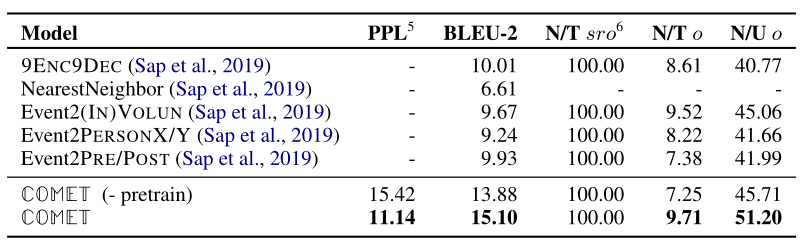
上图为采用自动评估标准的评估结果(评估的是生成 \(o\) 的质量和新颖性,第一列对比的模型为ATOMIC提出文章中的baseline,后面两个是论文提出的COMET模型。从第二列开始都是评估的指标,第二列是困惑度PPL,第三列是BLEU-2,第三列是模型生成元组所占的比例,第四列是模型生成的未出现在训练集元组中 \(o\) 所占的比例(元组新颖性),为了证明模型生成的元组新客体不是唯一的,把产生的新客体的数目作为测试集事件产生的唯一客体集合的函数,就是第五列。
- 人工评估

BLEU-2的评估结果表明,COMET模型超越了所有baseline的表现,比表现最好的baseline实现了51%的相对表现提升。对于人工评估的结果,COMET报告了统计上显著的相对Avg性能,比最高基线提高了18%。
为了评估在大型语料库上的预训练如何帮助模型学习产生知识,训练了一个没有用预训练权重初始化的COMET版本(COMET(- pretrain))。通过在不同比例的训练数据上训练模型来评估方法的数据效率。
最后,因为最终目标是能够执行高质量、多样化的知识库构建,所以探索了各种解码方案如何影响候选知识元组的质量,采用了不同生成策略进行了实验,这些策略包括:argmax贪婪解码、波束大小的波束搜索、b=2、5、10和k = 5、10的top-k采样。对于每种解码方法,对每种方法产生的最终候选数进行人工评估,结果如下:
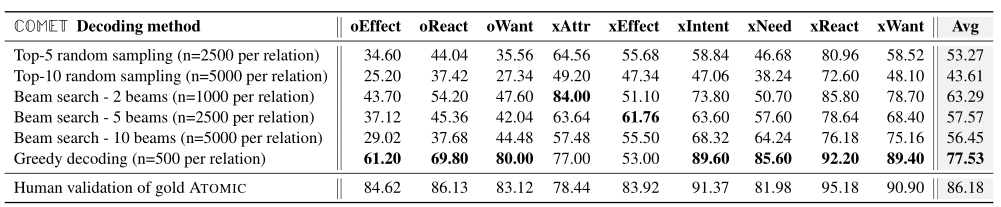
上述结果表明,使用贪婪解码来产生知识元组,与人工评估ATOMIC测试集相比,仅存在10%的相对性能差距,表明由模型产生的知识接近人工性能。
ConceptNet
数据集
- 标准的SRO三元组格式,涵盖大量关系三元组,例如(take a nap, Causes, have energy)
对应到实验中,各选取了1200个三元组作为测试集和开发集,包含34个关系类型的100k版本的训练集用于训练模型。
模型评估
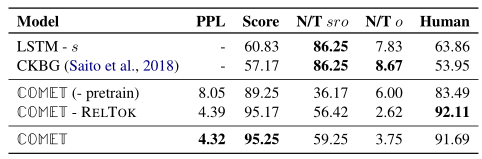
生成质量评估
为了评估生成知识的质量,给出在测试集中生成的正面示例的数量,这些正面示例被评为正确。对于给定的 \(s \space r \space o \space\)元组,考虑该模型产生元组是否正确的概率,以50%的概率对分数进行阈值化,以识别正确的预测。
结果表明,该模型可以生成高质量的知识:上表中的低困惑度(PPL)分数表明其预测的高模型置信度,而高分类器得分Score(95.25%)表明知识库补全模型在大多数情况下将生成的元组评分为正确。在人工评估(遵循与ATOMIC相同的设计)中,贪婪解码得到的元组的91.7%被评为正确。
生成新颖度评估
\(N/T \space sro\) 达到了59.25%,说明有接近6成的生成元组未出现在训练集中,显示该模型能够在节点之间生成新的边,甚至创建新的节点(\(N/T \space o = 3.75\) ,即3.75%的节点是新的)来扩展知识图的大小。但是需要注意的是,有一些新产生的元组仅仅是训练集中元组的简化形式。为此论文进行了研究,这些简化形式的新元组到底有多少。结论是大多数产生的新元组与训练集中它们最接近的元组具有明显不同的单词序列。
结论
本文引入常识转换器(COMET)来自动构建常识知识库。COMET是一个框架,用于调整语言模型的权重,以学习生成新颖和多样的常识知识元组。在两个常识知识库ATOMIC和ConceptNet上的实验结果表明,COMET经常产生人类评估者认为是正确的新常识知识。这些积极的结果表明未来可以寻求将该方法扩展到各种其他类型的知识库上,以及研究COMET是否可以学习为任意知识种子产生OpenIE风格的知识元组。
COMET —— 常识Transformer用于自动知识图构建的更多相关文章
- 知识图谱-生物信息学-医学顶刊论文(Bioinformatics-2021)-KG4SL:用于人类癌症综合致死率预测的知识图神经网络
5.(2021.7.12)Bioinformatics-KG4SL:用于人类癌症综合致死率预测的知识图神经网络 论文标题:KG4SL: knowledge graph neural network f ...
- 14 张思维导图构建 Python 核心知识体系
ZOE是一名医学生,在自己博客分享了很多高质量的思维导图.本文中所列的 14 张思维导图(高清图见文末),是 17 年作者开始学习 Python 时所记录的,希望对大家有所帮助.原文:https:// ...
- 知识图谱顶会论文(SIGIR-2022) MorsE:归纳知识图嵌入的元知识迁移
MorsE:归纳知识图嵌入的元知识迁移 论文题目: Meta-Knowledge Transfer for Inductive Knowledge Graph Embedding 论文地址: http ...
- Atitti 知识图谱构建方法attilax 总结
Atitti 知识图谱构建方法attilax 总结 1.1. 知识图谱schema构建(体系化)1 1.2. 纵向垂直拓展(向上抽象,向下属性拓展)2 1.3. 横向拓展2 1.4. 网拓展2 1 ...
- ROS(indigo) 用于机器人控制的图形化编程工具--code_it robot_blockly
0 简介: 编程语言有汇编,高级语言,解释语言等,现在图形化编程也越来越流行.图形化编程简单易学.8年前,微软推出了VPL用于机器人程序设计,如Python和JavaScript都可以用图形化框图实现 ...
- 配置GitLab Push 自动触发Jenkins构建
配置GitLab Push 自动触发Jenkins构建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客是对之前的笔记:https://www.cnblogs.com/yin ...
- 我收藏的技术知识图(每张都是大图)关于XX背后的知识、技术图,例如:Linux、Nginx架构、PHP知识卡、机会、HTML5移动、Android系统架构、YII架构的典型流程、Css知识表
我收藏的技术知识图(每张都是大图) HTML5Linux/Unix系统设计思想读书笔记 LinuxMVCJava线程MVCSpring MVCCSS3Nginx架构VimCliCommandsPHP知 ...
- GitLab 自动触发 Jenkins 构建
GitLab 是当前应用非常广泛的 Git Hosting 工具,Jenkins 是非常牛逼的持续集成工具.尽管 GitLab 有内建的 GitLab CI,但它远没有 Jenkins 那么强大好用. ...
- Spark GraphX图计算核心源码分析【图构建器、顶点、边】
一.图构建器 GraphX提供了几种从RDD或磁盘上的顶点和边的集合构建图形的方法.默认情况下,没有图构建器会重新划分图的边:相反,边保留在默认分区中.Graph.groupEdges要求对图进行重新 ...
随机推荐
- [Binder深入学习二]Binder驱动——基础数据结构二
Userspace和KernelSpace进行交互时,大部分命令是通过 ioctl 实现的,在这个过程中,最重要的一个便是 BINDER_WRITE_READ 命令了. #define BINDER_ ...
- 数据库:drop、truncate、delete的区别
近日在删除数据时,发现除了常用的Delete & Drop语句之外,还有Truncate也是与删除数据相关的,针对上述三种有进行简单的比较与整理 用法 drop 用法:drop table 表 ...
- redis之哨兵部署运行日志解读
转载自http://www.run-debug.com/?p=674 192.168.110.21 主 192.168.110.31 从 #两台服务器都安装redis #下载最新稳定版本:http:/ ...
- golang interface 类型学习
接口类型变量的内存结构 动态类型 动态值 对于动态类型指的是当其他非接口类型变量赋值给接口类型变量时,接口类型变量中的动态类型就是当前非接口类型 对于动态值指的就是当其他非接口类型变量赋值给接口类型变 ...
- 记一次"截图"功能的项目调研过程!
目录 项目需求 功能调研 AWT Swing Html2Image PhantomJS Headless Chrome 实现方案 结论 项目需求 最近,项目接到了一个新需求,要求对指定URL进行后端模 ...
- 《Java并发编程的艺术》笔记
第1章 并发编程的挑战 1.1 上下文切换 CPU通过时间片分配算法来循环执行任务,任务从保存到再加载的过程就是一次上下文切换. 减少上下文切换的方法有4种:无锁并发编程.CAS算法.使用最少线程.使 ...
- textarea输入框回车加大高度
JavaScript var agt = navigator.userAgent.toLowerCase(); var is_op = (agt.indexOf("opera") ...
- Actor:人生如戏全靠演技--“三维度”逻辑编程语言的设计(3)
在上一篇介绍了逻辑编程的作用,介绍了逻辑编程中的一些概念,包括逻辑程序的结构:事实.规则和问题:知识的表达方式:谓词演算.产生式规则,以及这些概念与三维度(角色+场景+时间)理论的契合关系,正式提出了 ...
- Centos-将文件内容输出到标准输出-cat
cat 将文件内容输出到标准输出 相关选项 -n 显示行号,包括空行 -b 显示行号,不包括空行 -A 显示制表符为 ^I ,结尾符为 $ 应用 1. 清空文件 cat /dev/null > ...
- IDEA配置jQuery,$符号不再显示黄色波浪线
在使用IDEA搭建Maven的Web环境时,编写的JQuery入口函数时,遇到了未知符号的提示,并且在前端页面js的console里报错. 以下是错误信息: 解决方案: 继续看图: 配置成功生效: ...