高速缓冲存储器Cache
概述
问题的提出
避免CPU“空等”的现象
CPU和主存的速度差异
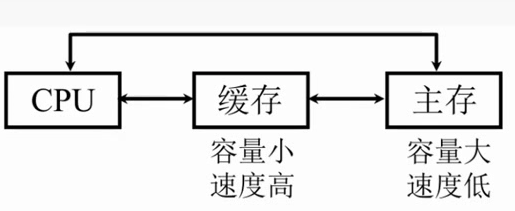
容量非常小,但是速度非常高,他就能提高CPU的访存速率了。
为了充分发挥cache的作用,切实提高CPU的访存速率,所以CPU的访问数据和指令要求能大多数都能在cache中能够取到,这样就不需要到主存中去取了。这需要依靠局部性原理。
局部性原理
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是临近的。
顺序存放。
所以我们未来要用的信息很可能和我们现在使用的信息的存储空间上是临近的
交换的单位是以块为单位的。
主存分成大小相同的块,Cache也分成了大小相同的块
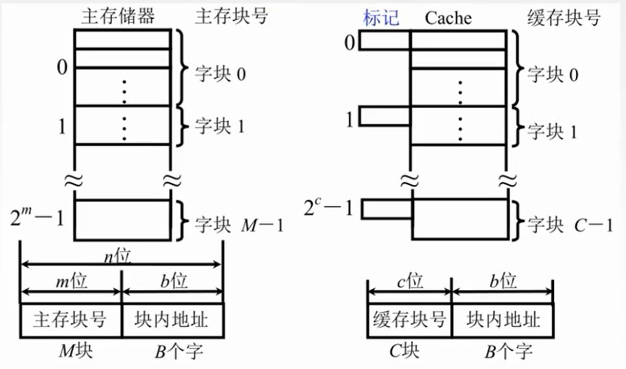
主存和缓存按块存储,块的大小相同,B为块长。
M要远远大于C
块内地址的位数决定了块的大小。假如有16个字节,块内地址就有4位???
主存和缓存的块内地址是完全相同
标记是用来说明主存块和cache的对应关系。
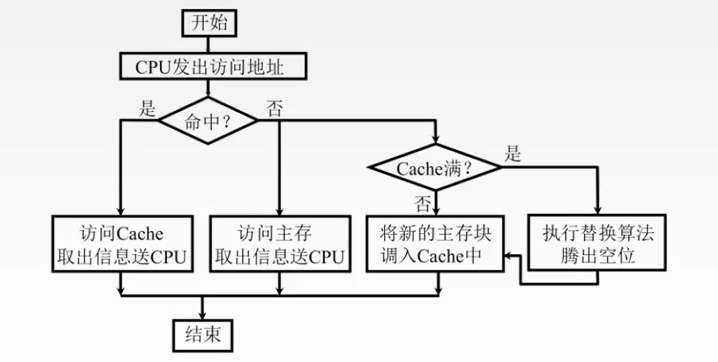
命中与未命中
缓存中有C块
主存中有M块M>>C
命中:主存块已经调入缓存,主存块与缓存块建立了对应关系,用标记记录与某缓存块建立了对应关系的主存块号。
未命中:主存块未调入缓存,主存块与缓存块未建立对应关系。
Cache的命中率
CPU欲访问的信息在Cache中的比率
设一个程序在执行期间,Cache的总命中次数为Nc,访问主存的总次数为Nm,则命中率
\]
命中率和Cache的容量和块长有关
一般每块可取4~8个字
块长取一个存取周期内从主存调出的信息长度
失效率=1-H
Cache-主存系统的效率
效率e与 命中率 有关
\]
如何计算平均访问时间?命中时访问Cache的时间加上不命中在主存的时间
设Cache命中率为h,访问Cache的时间为tc,访问主存的时间为tm
\]
最小值是命中率为0的时候,最大值是命中率为1的时候
例题

设Cache的存储周期是t,则主存的存储周期是5t
Cache和主存同时访问,不命中时访问时间为5t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 5t=1.2t
设每个周期可存取的数据量为S,
则存储系统带宽为S/1.2t
不采用Cache时带宽为S/5t
故性能为原来的
\]
提高了3.17倍
若改为先访问Cache再访问主存的方式:
不命中时,访问Cache耗时t
发现不命中后在访问主存,耗时5t
总耗时6t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 6t = 1.25t
故性能为原来的5t/1.25t=4倍,提高了3倍
工作原理
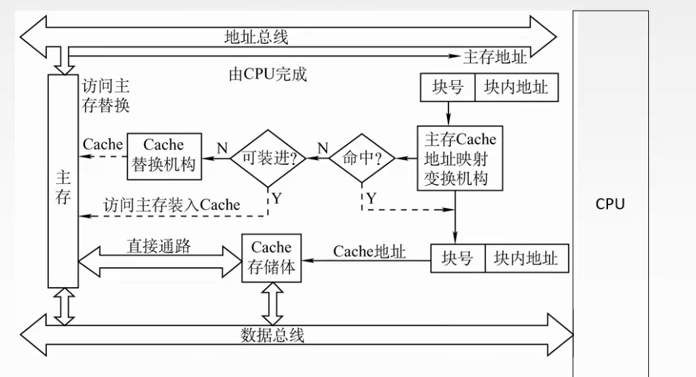
当Cache要读的时候
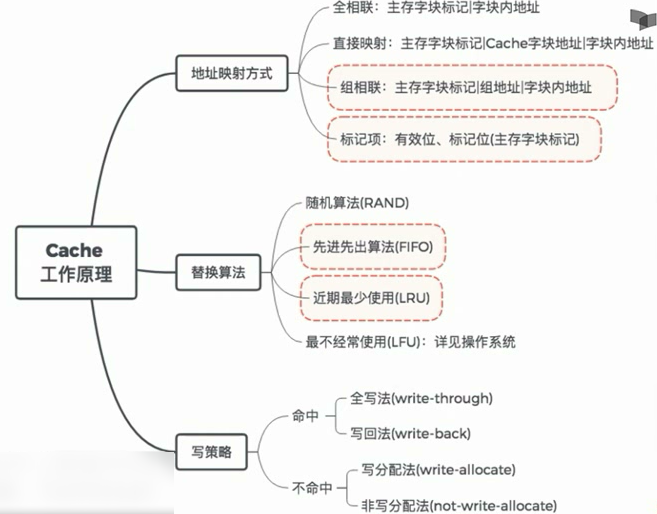
地址映射方式(本节最重要)
1.主存中的块放到Cache中哪个位置?
(1)空位随意放:全相联映射
(2)对号入座:直接映射
(3)按号分组,组内随意放:组相联映射
2.对于(1),Cache满了如何处理?对于(2)(3),对应位置被占用如何处理?
随机(RAND)算法
先进先出(FIFO)算法
近期最少使用(LRU)算法
最不经常使用(LFU)算法
3.修改Cache中的内容后,如何保持主存中相应内容的一致性?
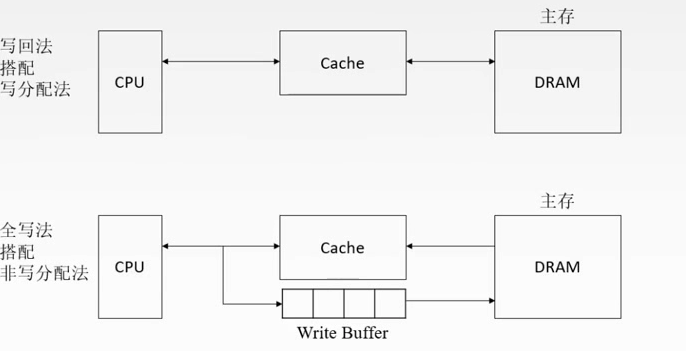
命中:全写法(write-through)、写回法(write-back)
不命中:写分配法(write-allocate)、非写分配法(not-write-allocate)
直接映射
主存当中的数据块只能够装入到Cache的唯一位置。
把主存划分为若干个区,每个区大小和Cache是相等的,每个去的子块数也是相等的。
每个区的对应单元只能对应Cache对应的单元。
主存地址的高m位就被划分为两个部分——主存子块标记,Cache子块地址
记录建立对应关系的缓存位的标记位当中
当缓存接到CPU接来的一个主存地址之后,根据中间的c位(Cache子块地址)找到cache字块,然后根据这个子块的标记,判断****是否与主存的高t位相符,如果相符,并且有效位**是有效(1)的,那么就表示Cache块已经和主存的某一块地址建立了对应关系。
如果不符合的话,就要从主存中读入新的子块。
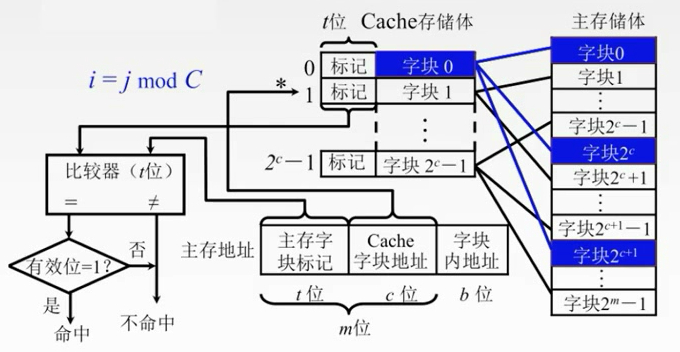
每个缓存块i 可以和若干个主存块对应
每个主存块j 只能和一个缓存块对应
直接映射主存地址被划分为三个部分

j是Cache的块号。i是主存的块号
特点简单,但是不够灵活,容易发生冲突。
即使Cache有很多空位置,但是我还是要找到对应位置的来换
全相联映射
大大提高了利用率,只要有位置就放。但是速度很慢。对比子块标记很麻烦,每块都要比较。
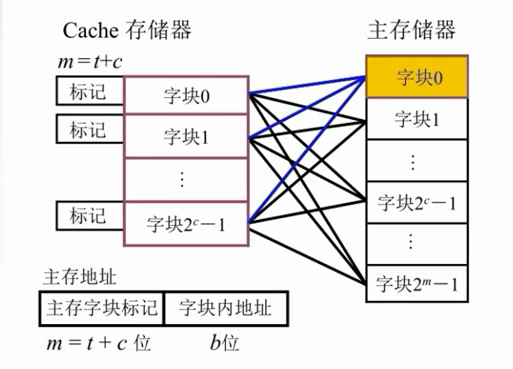
主存中的任一块可以映射到缓存中的任一块
组相联映射
折中。
先把主存储器划分为块,在把每个块划分为组。
先把Cache地址分成大小相同的组,每一个主存的数据块可以装入到一个组内的任何位置。
组间采用直接映射,组内全相联映射。
01,23,45,67,。。。
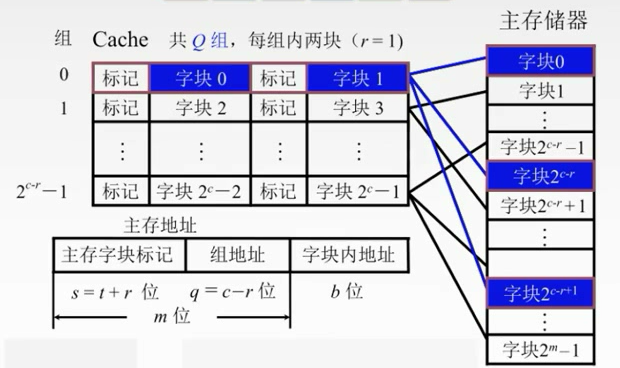

二路组相联映射。
速度快:直接映射
一般:组相联
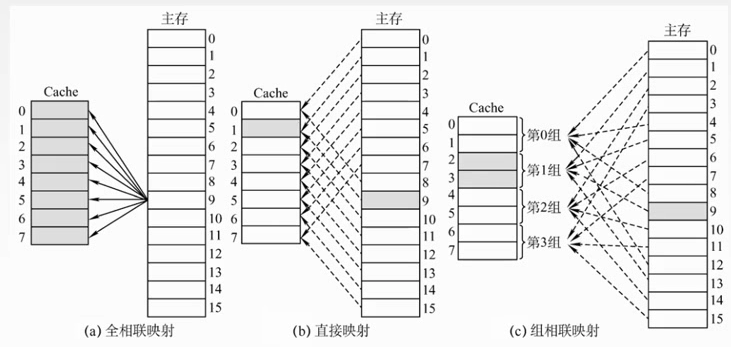
例子

全相联
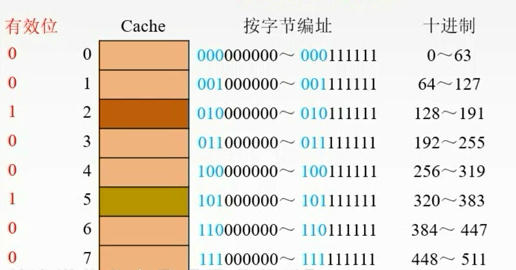

直接映射

组相联

替换策略
- 随机算法(RAND):随机地确定替换的Cache块。实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低。(基本不考)
- 先进先出算法(FIFO): 选择最早调入的行进行替换。容易实现,但也没有依据程序访问的局部性原理,可能会把一些经常使用的程序块(如循环程序)也作为最早进入的Cache的块替换掉。
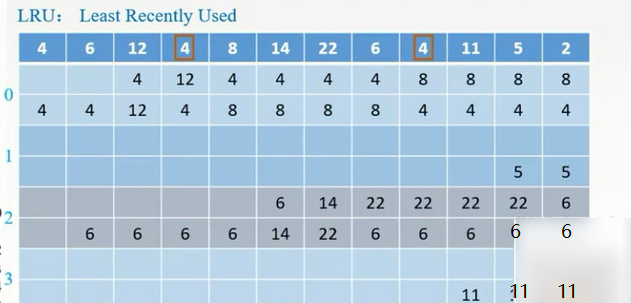
- 近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,平均命中率要比FIFO高,是堆栈类算法。LRU算法对每行设置一个计数器,Cache每命中一次,命中行计数器清零,而其他各行计数器均加1,需要替换时比较各特定行的计数值,将计数值最大的行换出。
- 最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从0开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。
例题

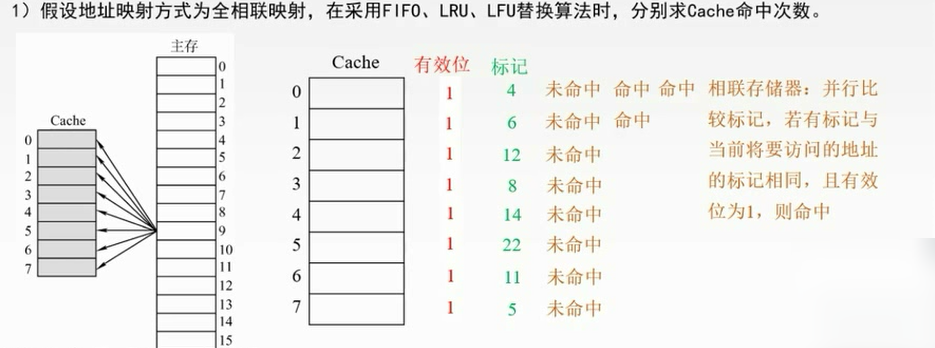
FIFO:把4替换掉
LRU:最近最少使用的是12,替换掉。从后往前数,最后那个就是最不常用的

LFU:4号块用了3次,6号块用了2次,其他均用了1次,需要更多的判断依据。换12

只命中了1次。
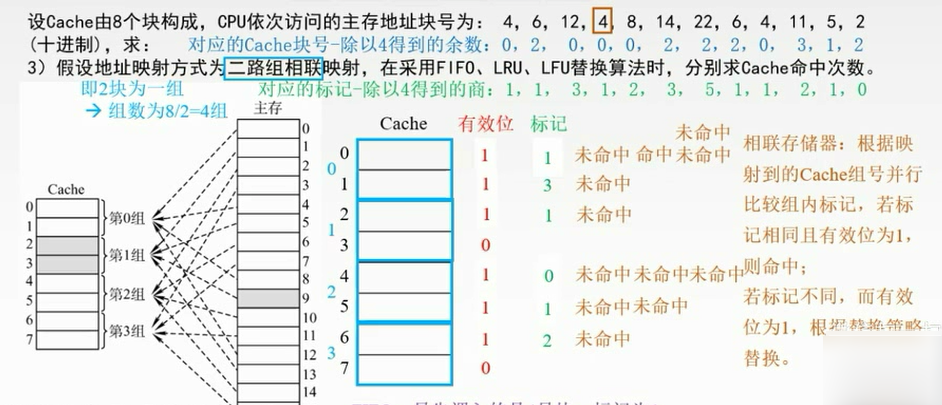
在组内是用不同的替换算法的。
FIFO:在第0组中,最先调入的是4号块,标记为1,命中0次
列表的方法。
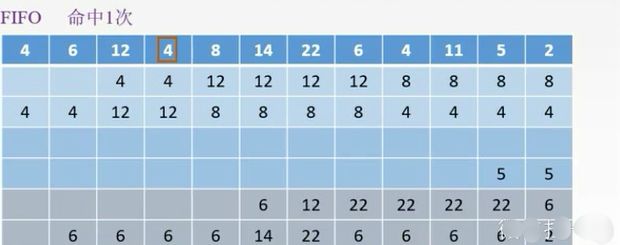
每次都放到每组的最下面,然后出去的就是先进先出的。
如果用了就把它移上去。
LFU:操作系统。
写策略
命中

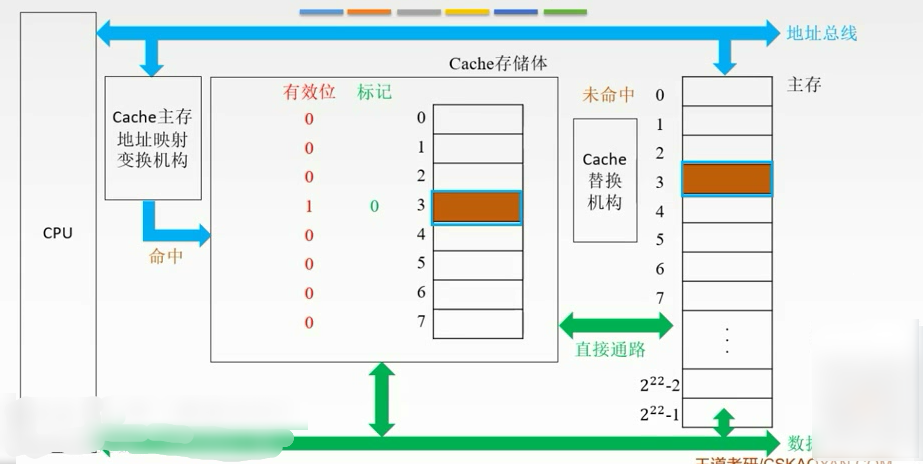
如果对Cache的内容进行修改,就要修改主存中对应的块。
命中:要访问的主存内容已经在Cache当中。
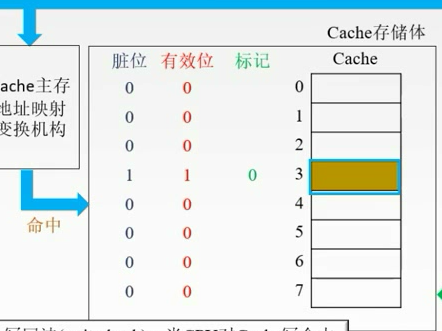
这块要被换掉之后才把主存的修改掉。写回法。加多一个脏位
写回法(write-back):当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
每次有修改就改,不用脏位了,但是增加访存次数。
全写法(write-through):当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
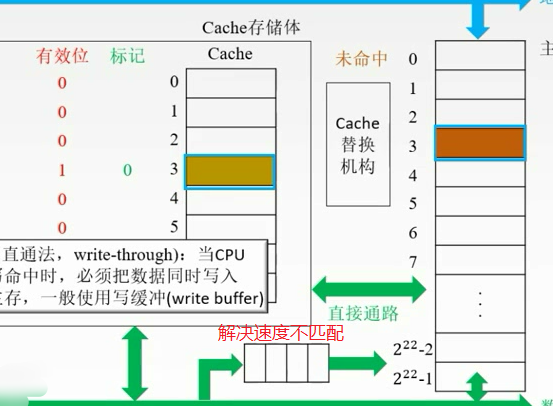
写的太频繁,会有队列的溢出。
未命中
写分配法(write-allocate):把主存中的块调入Cache,在Cache中修改,搭配写回法使用。
缺点:每次不命中都要从主存中读取块。
非写分配法(not-write-allocate):只写入主存,不调入Cache,搭配全写法使用。
小结
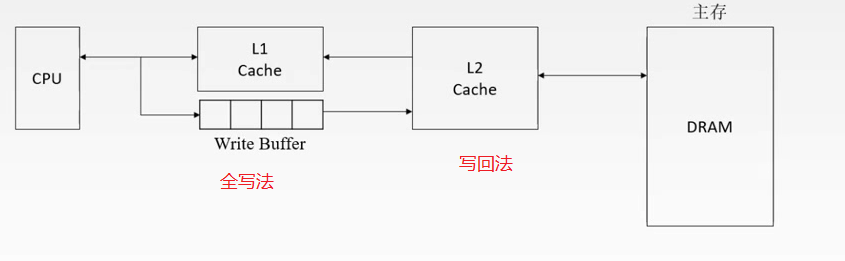
多级Cache
本节小结
高速缓冲存储器Cache的更多相关文章
- 7.2 高速缓冲存储器-Cache
高速缓冲存储器:Cache.Cache的功能是提高CPU数据的输入和输出的速率.CPU的速度与主存的速度之间有巨大的差异.主存的存取时间.存取速度要比CPU的速度要慢了很多倍.为了调和它们之间的巨大速 ...
- Cache高速缓冲存储器
Cache的命中率:命中Cache的次数比总访问次数 平均访问时间:t(Cache)X命中次数+t(未命中)X未命中次数 Cache与主存的映射方式: 直接映射 全相联映射 组相联映射 图片来源:ht ...
- Cache的原理、设计及实现
Cache的原理.设计及实现 前言 虽然CPU主频的提升会带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构.指令结构.信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特 ...
- 转:Cache相关
声明:本文截取自http://blog.163.com/ac_victory/blog/static/1033187262010325113928577/ (1)“Cache”是什么 Cache(即高 ...
- 存储器结构、cache、DMA架构分析--【原创】
存储器的层次结构 高速缓冲存储器 cache 读cache操作 cache如果包含数据就直接从cache中读出来,因为cache速度要比内存快 如果没有包含的话,就从内存中找 ...
- [z]计算机架构中Cache的原理、设计及实现
前言 虽然CPU主频的提升会带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构.指令结构.信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特别是与CPU/内存之间的存取速 ...
- Something about cache
http://www.tyut.edu.cn/kecheng1/2008/site04/courseware/chapter5/5.5.htm 5.5 高速缓冲存储器cache 随着CPU时钟速率的不 ...
- 操作系统-存储管理(3)高速缓存Cache
存储器的组织形式: 数据总是在相邻两层之间复制传送,最小传送单位是定长块,互为副本(不删除) ️指令和数据有时间局部性和空间局部性. 高速缓冲存储器Cache 介于CPU和主存储器间的高速小容量存 ...
- linux系统meminfo详解(待补充)
========================================================================================== MemTotal: ...
随机推荐
- 软链接mongo
ln -s /usr/local/mongodb/bin/mongo /usr/bin/mongo
- 面试腾讯,字节跳动,华为90%会被问到的HashMap!你会了吗?
简介 HashMap是平常使用的非常多的,内部结构是 数组+链表/红黑树 构成,很多时候都是多种数据结构组合. 我们先看一下HashMap的基本操作: new HashMap(n); 第一个知识点 ...
- 面试官:小伙子,给我说一下mysql 乐观锁和悲观锁吧
悲观锁介绍 悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中, 将数据处于锁定状态.悲观锁的实现,往往依靠数据库 ...
- 「LOJ 541」「LibreOJ NOIP Round #1」七曜圣贤
description 题面很长,这里给出题目链接 solution 用队列维护扔掉的红茶,同时若后扔出的红茶比先扔出的红茶编号更小,那么先扔出的红茶不可能成为答案,所以可以用单调队列维护 故每次询问 ...
- 对于final修饰的类型运算时的表现
我们知道,对于byte,char,这些数据类型加减时都会转化成int在运算,然而,对于final修饰过的数据是不会发生转换的. 比如说 byte b1=1; byte b2=2; byte b3=b1 ...
- Python变量引用
>>>a=3 >>>b=a >>>a=4 >>>b >>>3 >>>List1=[1,2,3 ...
- VM15 Ubuntu18.04 安装c/c++
输入"su"再输入密码即进入根用户,(gcc是默认安装的,但刚安装完成的系统中的gcc并不能用来开发,还缺少常用的头文件和库文件,还组要安装build-essential 软件包) ...
- 使用Docker部署MSSQL
部署MSSQL需要2G内存 1.下载镜像 docker pull microsoft/mssql-server-linux 使用该命令就可以把数据库的docker镜像下载下来. 2.创建并运行容器 d ...
- Java 虚拟机垃圾收集机制详解
本文摘自深入理解 Java 虚拟机第三版 垃圾收集发生的区域 之前我们介绍过 Java 内存运行时区域的各个部分,其中程序计数器.虚拟机栈.本地方法栈三个区域随线程共存亡.栈中的每一个栈帧分配多少内存 ...
- 基于gin的golang web开发:Gin技术拾遗
本文是对前几篇文章的一些补充,主要包含两部分:单元测试和实际项目中使用路由的小问题. 拾遗1:单元测试 Golang单元测试要求代码文件以_test结尾,单元测试方法以Test开头,参数为*testi ...