大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
小提示:这里,使用axure(原型制作工具),来画图十分方便,个人认为比viso或者是processon等流程图制作工具简单多了。
点击链接,看取axure画完以后生成的html网页。
spark的axure原型
效果图:
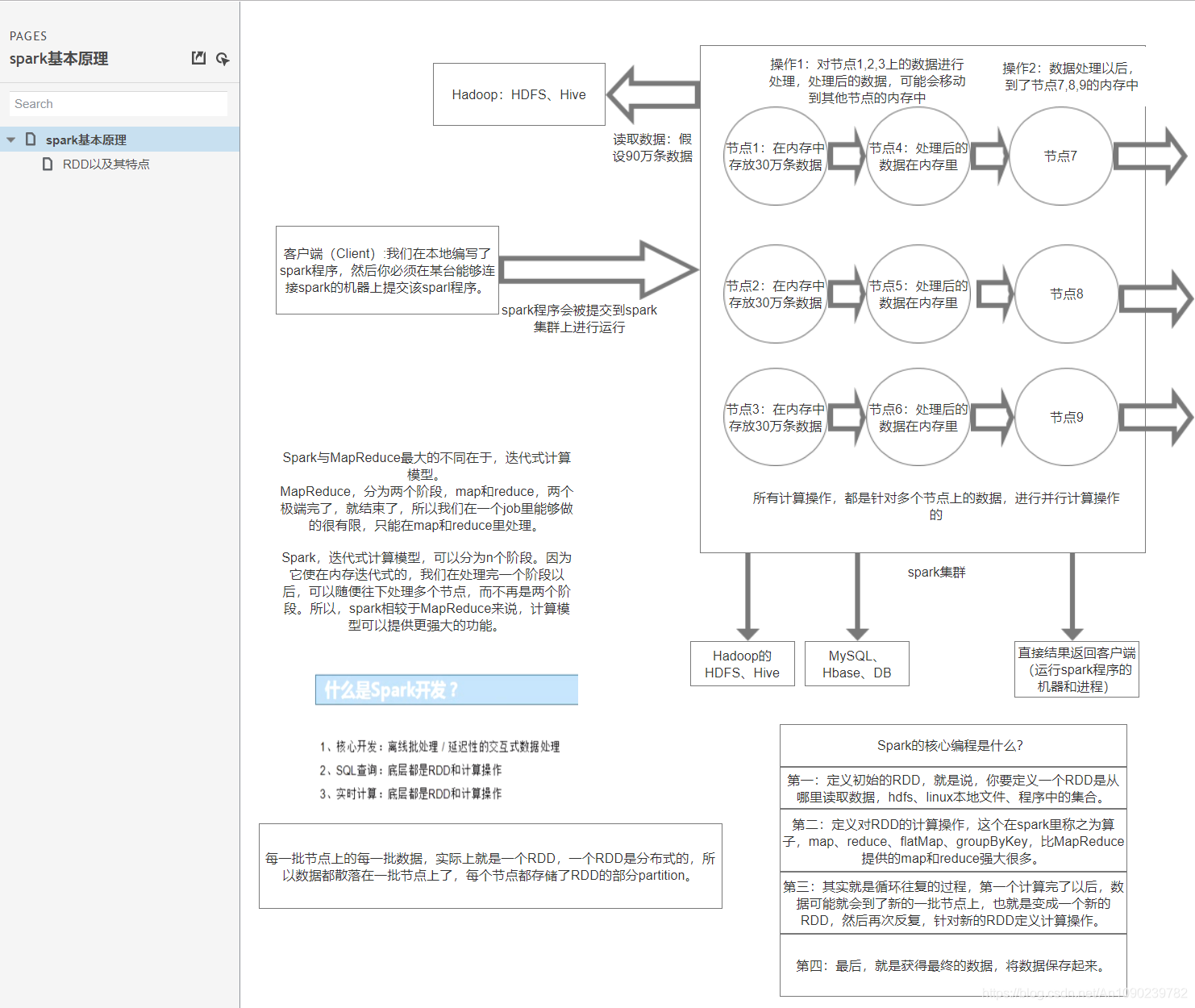
大数据体系概览(Spark的地位)
Hadoop生态圈重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
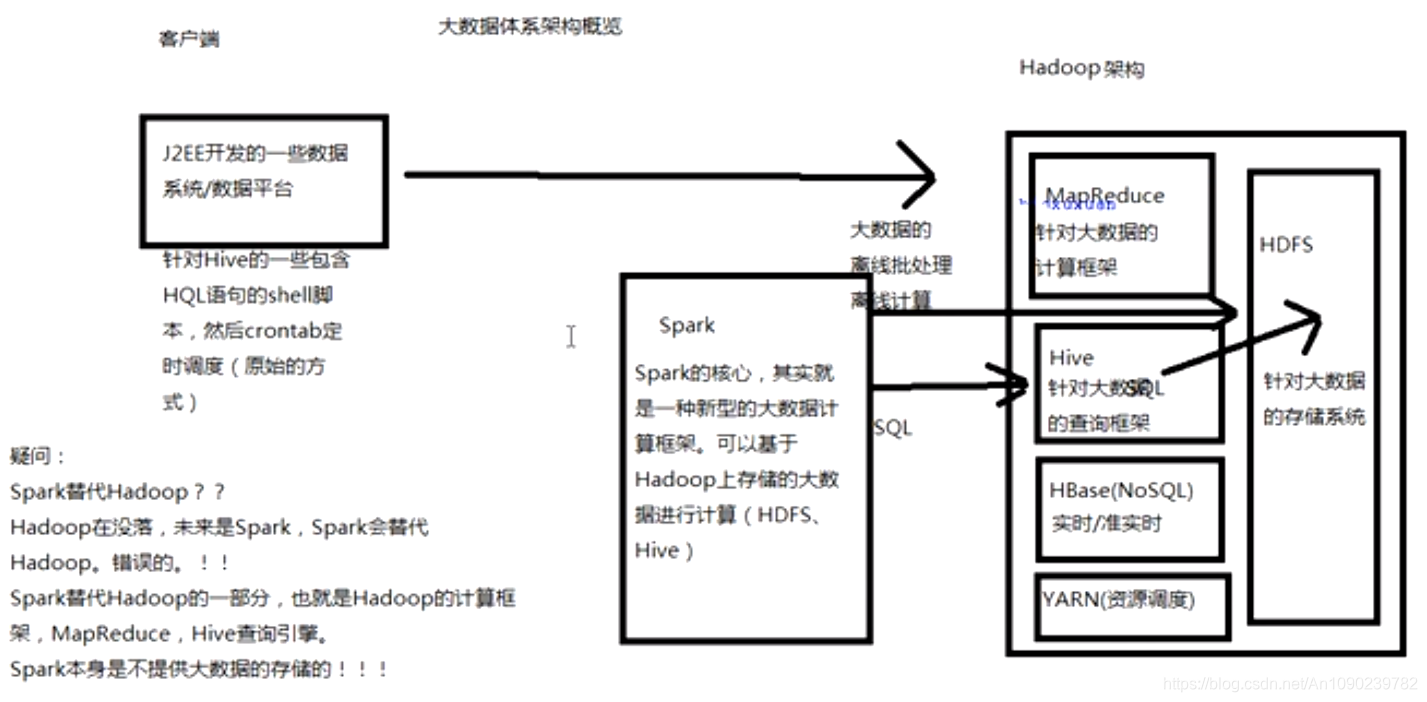
什么是Spark?
Spark,是一种通用的大数据计算框架,如Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark Graphx用于图计算。
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、Hive、HBase),以及资源调度(Yarn)。
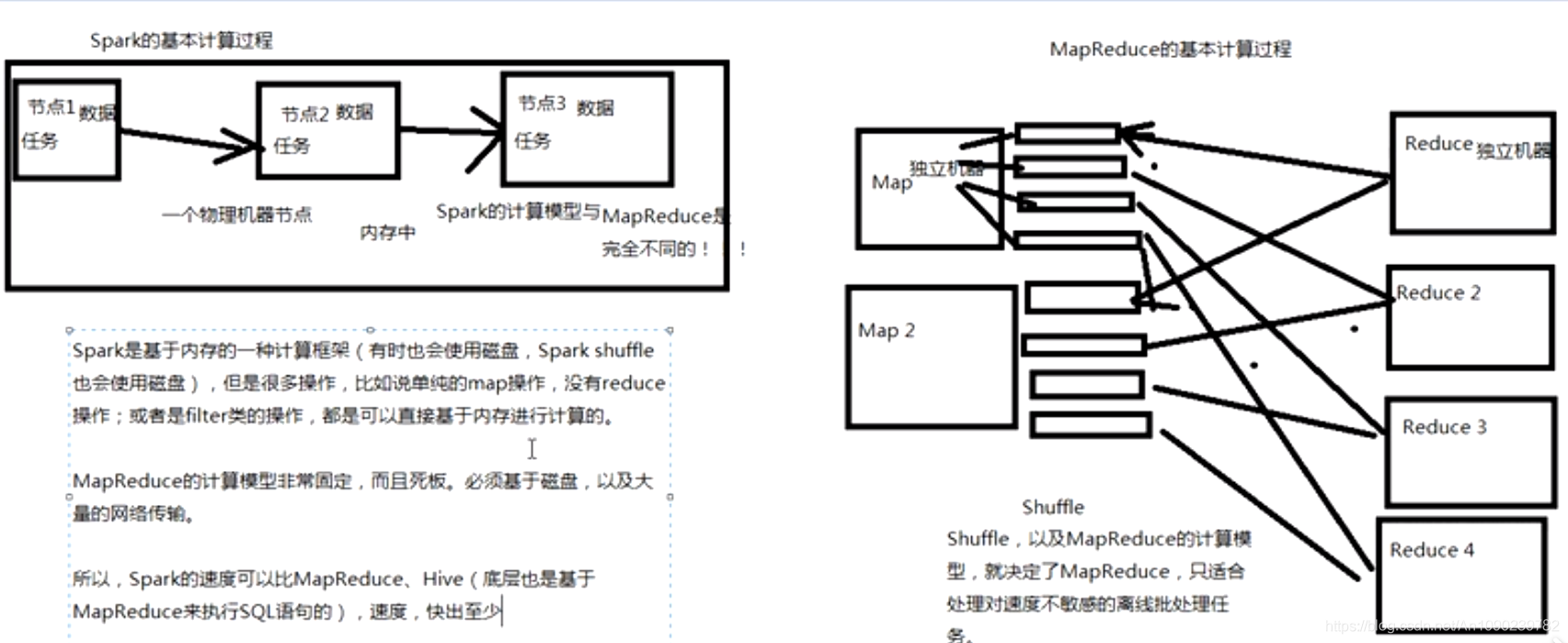
Spark除了一站式的特点之外,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至十倍!
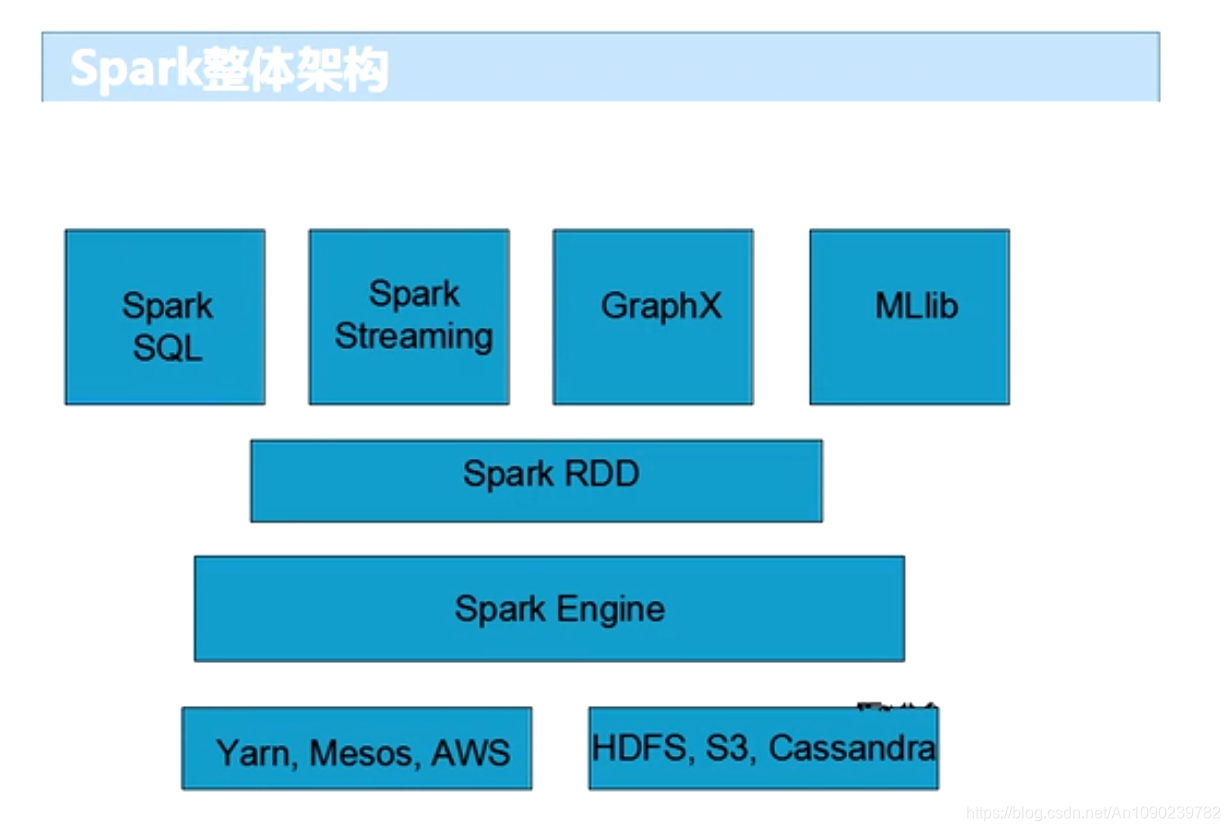
Spark整体架构
Spark的特点
- 速度快:Spark基于内存计算(部分基于磁盘,如shuffle)
- 超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark Graphx等组件,可以一站式完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图形计算等常见的任务。
- 集成Hadoop:与Hadoop进行了高度的集成,Hadoop的HDFS、Hive、HBase负责存储,Yarn负责资源调度,Spark负责大数据计算。
Spark核心原理
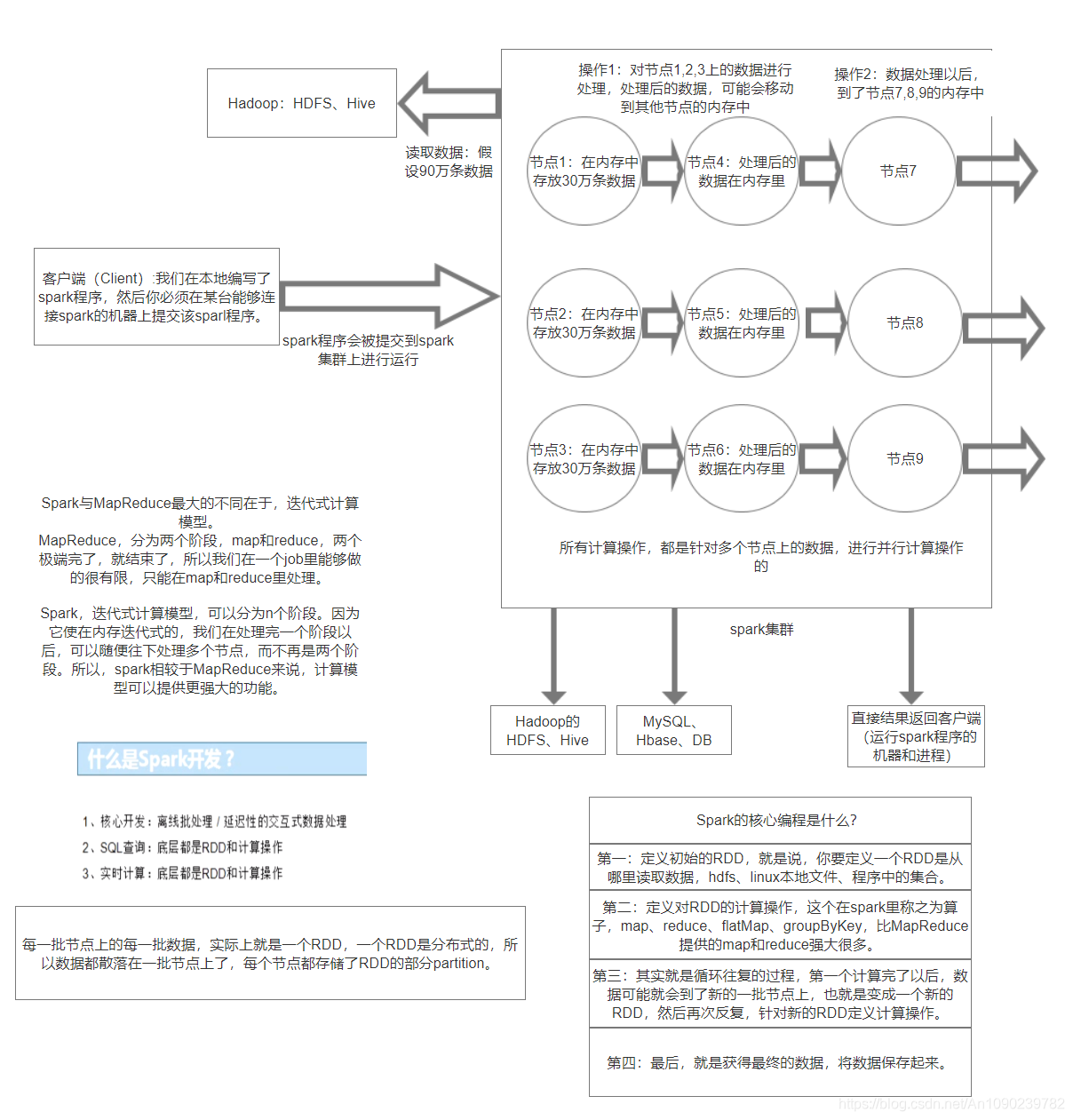
Spark架构原理
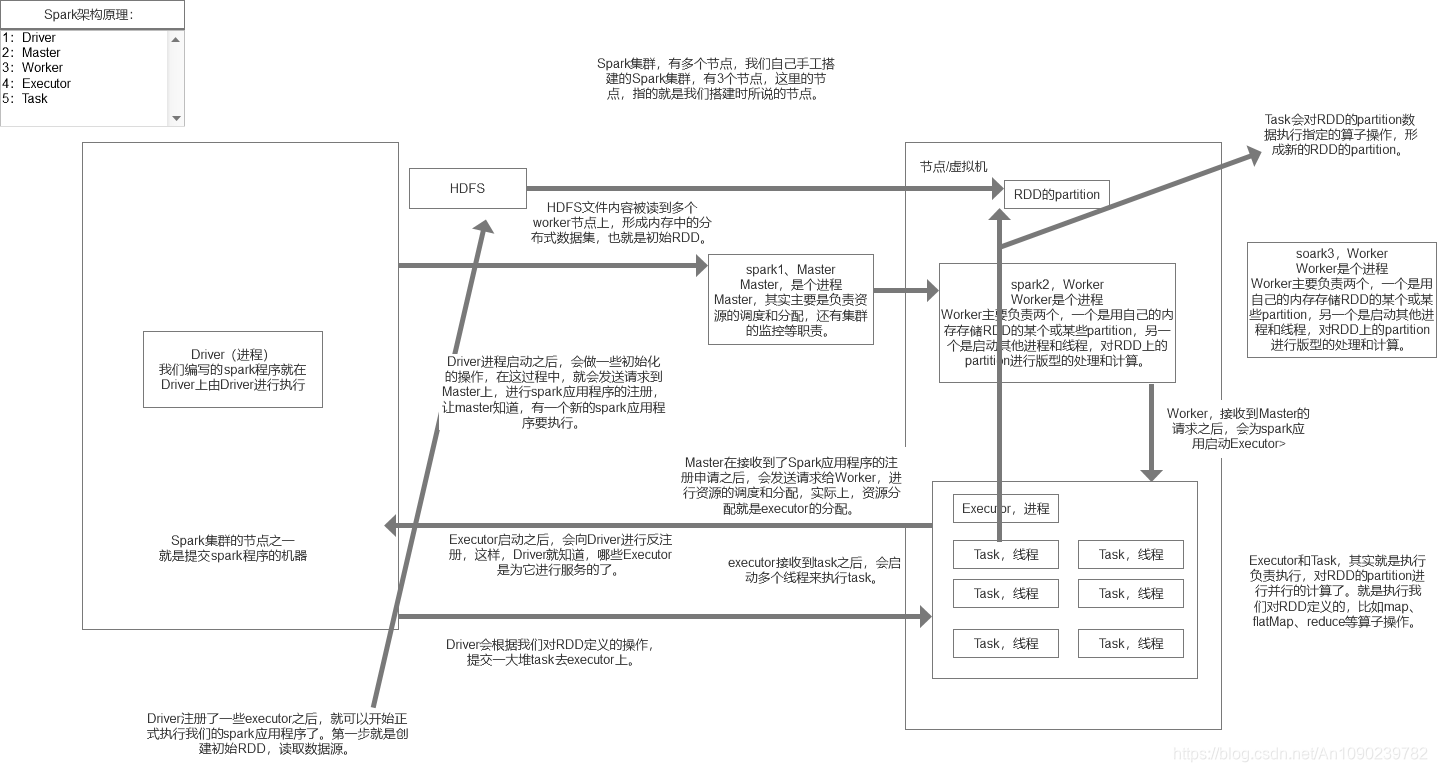
spark内核架构
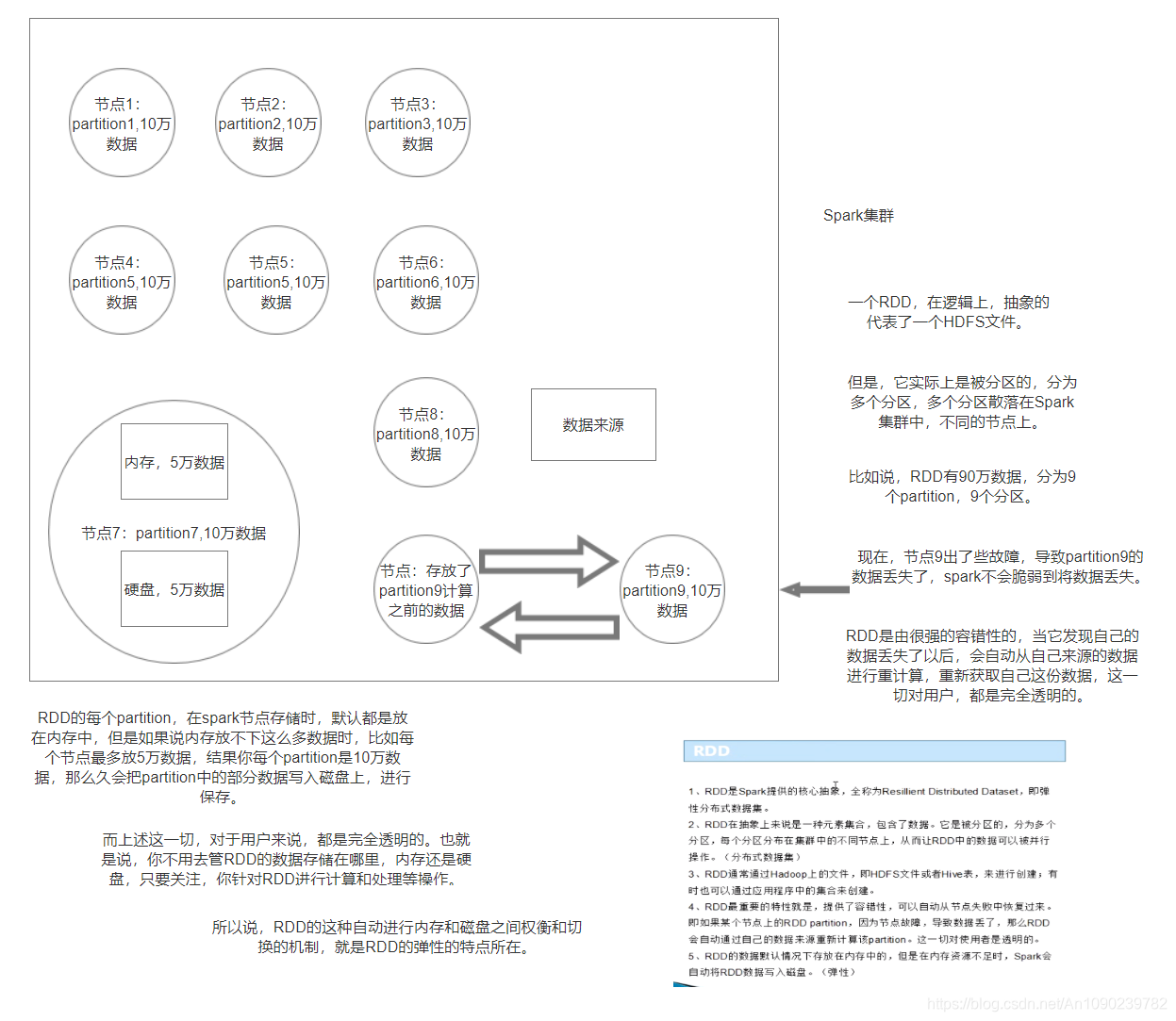
RDD及其特点
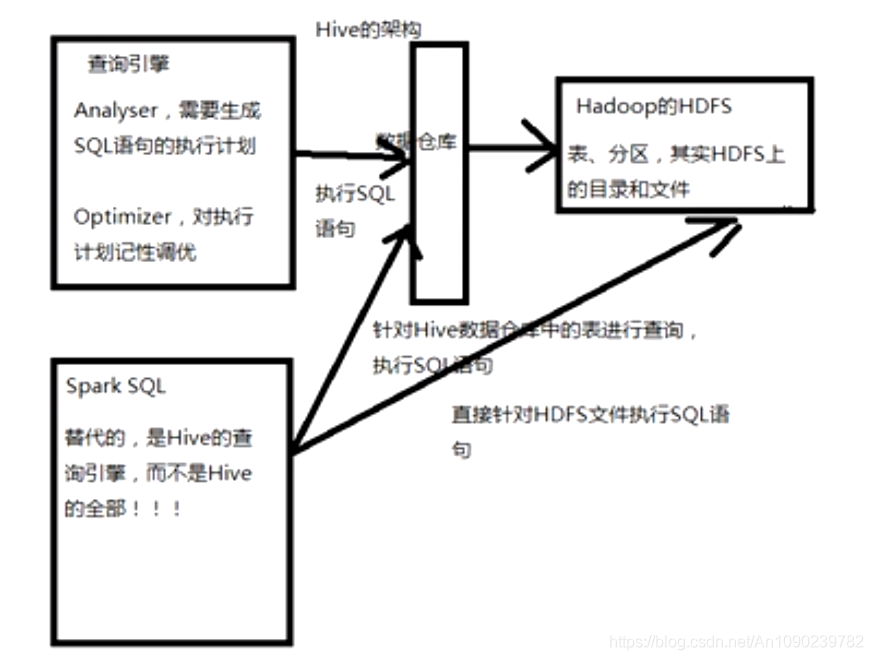
Spark SQL VS Hive
Hive基于HDFS的数据仓库,并提供了SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。
Spark SQL是针对Hive数据仓库中的数据进行查询,Spark本身自己不提供存储。
Spark SQL支持大量不同的数据源,包括hive、json、parquet、jdbc等。
Spark Streaming VS Storm
Spark Streaming与Storm都可以进行实时流计算,但是二者区别很大。
Spark Streaming和Storm计算模型完全不一样,Spark Streaming是基于RDD的,因此需要将一小段时间内的,比如1s的数据,收集起来,作为一个RDD,然后再针对这个batch得数据进行处理。
而Storm却可以做到每来一条数据,都可以立即进行处理和计算。
Storm支持在分布式流式计算程序运行过程中,可以动态地调整并行度,从而动态提供并发处理能力,而Spark Streaming是无法动态调整并行度的。
Spark Streaming由于是基于batch进行处理的,因此相较于Storm基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。

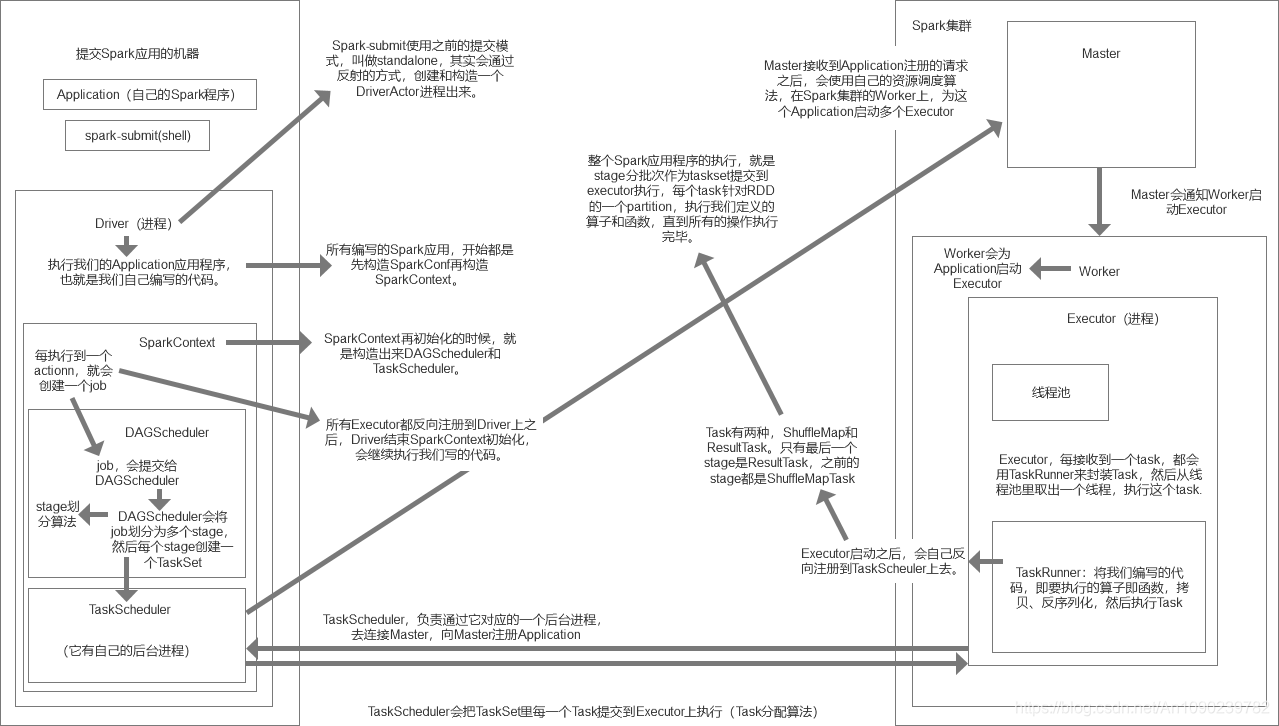
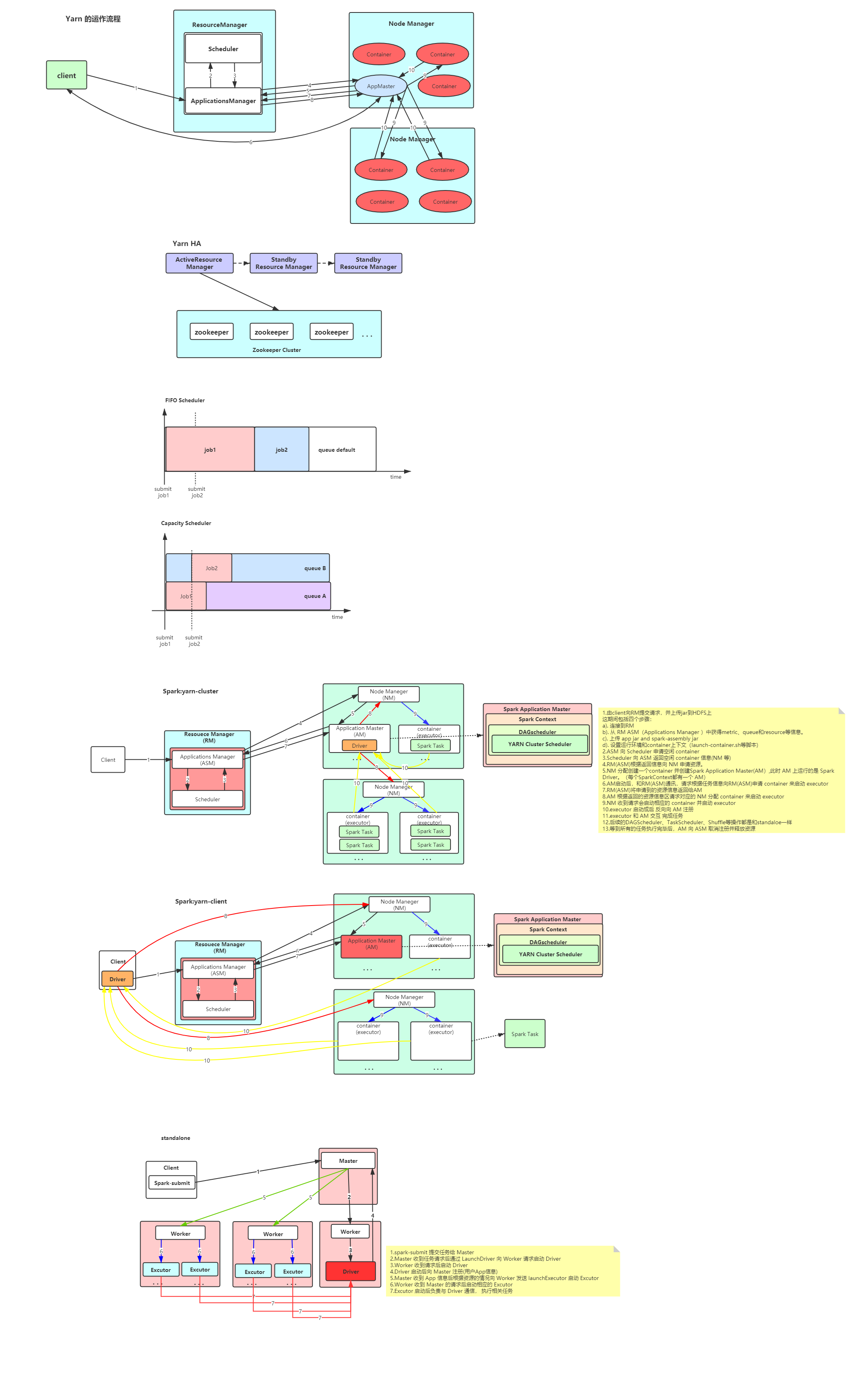
spark 任务提交流程
大数据体系概览Spark、Spark核心原理、架构原理、Spark特点的更多相关文章
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- [大数据从入门到放弃系列教程]第一个spark分析程序
[大数据从入门到放弃系列教程]第一个spark分析程序 原文链接:http://www.cnblogs.com/blog5277/p/8580007.html 原文作者:博客园--曲高终和寡 **** ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 【原创】大数据基础之Hive(5)hive on spark
hive 2.3.4 on spark 2.4.0 Hive on Spark provides Hive with the ability to utilize Apache Spark as it ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- 大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了.它包含这么几个角色: Client 多数情况下Client的作用就是向服务 ...
随机推荐
- java普通io(stream)处理文件读写的过程
场景:使用java的stream,从文件a读取内容,然后写进文件b,整个过程如下图所示(以linux系统为例) 步骤解析: 1.用户空间向内核空间发出指令--我要读取文件a 2.系统切换上下文,从用户 ...
- Ubuntu 18.04 使用docker 部署gitlab并且使用自定义端口号
搭建原因 两个月前我搭建了公司的docker(无法自定义端口,),当初只想着把托管在GitHub的项目代码放在公司的服务器上面,后来忙着修改人脸服务器代码,忘记了,这个月由于领导提的需求比较多,还是托 ...
- introJs用法及在webkit内核浏览器的一个报错
1.用法 很简单的用法,引入js,引入css,再执行introJs().start();就可以了(备注:introJs会自动去抓取含有data-intro的dom在introJs源码中_introFo ...
- JavaScript正则表达式详解
在JavaScript中,正则表达式由RegExp对象表示.RegExp对象呢,又可以通过直接量和构造函数RegExp两种方式创建,分别如下: //直接量 var re = /pattern/[g | ...
- 风炫安全Web安全学习第十节课 数字型的Sql注入
数字型的Sql注入 风炫安全Web安全学习第十一节课 字符型和搜索型的sql注入 风炫安全Web安全学习第十二节课 mysql报错函数注入 风炫安全Web安全学习第十三节课 CUD类型的sql注入 风 ...
- Lesson_strange_words4
mount on 安装 arc 弧 actuator 马达,致动器:调节器 roughly 大致,大约 radially 径向,放射状 stepper 步进机 motor 电机,发动机 sequent ...
- Lock锁 精讲
1.为什么需要Lock 为什么synchronized不够用,还需要Lock Lock和synchronized这两个最常见的锁都可以达到线程安全的目的,但是功能上有很大不同. Lock并不是用来代替 ...
- 【Java基础】面向对象中
面向对象中 这一章主要涉及面向对象的三大特征,包括封装.继承.多态.(抽象). 封装 程序设计追求"高内聚,低耦合": 高内聚 :类的内部数据操作细节自己完成,不允许外部干涉: 低 ...
- LeetCode144 二叉树的前序遍历
给定一个二叉树,返回它的 前序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,2,3] 进阶: 递归算法很简单,你可以通过迭代算法完成吗? /** * Defin ...
- LRU(Least Recently Used)最近未使用置换算法--c实现
在OS中,一些程序的大小超过内存的大小(比如好几十G的游戏要在16G的内存上跑),便产生了虚拟内存的概念 我们通过给每个进程适当的物理块(内存),只让经常被调用的页面常驻在物理块上,不常用的页面就放在 ...