硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析
背景
Apache Pulsar 是下一代分布式消息流平台,采用计算存储分层架构,具备多租户、高一致、高性能、百万 topic、数据平滑迁移等诸多优势。越来越多的企业正在使用 Pulsar 或者尝试将 Pulsar 应用到生产环境中。
腾讯把 Pulsar 作为计费系统的消息总线来支撑千亿级在线交易。腾讯计费体量庞大,要解决的核心问题就是必须确保钱货一致。首先,保证每一笔支付交易不出现错账,做到高一致、高可靠。其次,保证计费承载的所有业务 7*24 可用,做到高可用、高性能。计费消息总线必须具备这些能力。
Pulsar 架构解析
在一致性方面,Pulsar 采用 Quorum 算法,通过 write quorum 和 ack quorum 来保证分布式消息队列的副本数和强一致写入的应答数(A>W/2)。在性能方面,Pulsar 采用 Pipeline 方式生产消息,通过顺序写和条带化写入降低磁盘 IO 压力,多种缓存减少网络请求加快消费效率。

Pulsar 性能高主要体现在网络模型、通信协议、队列模型、磁盘 IO 和条带化写入。下面我会一一详细讲解。
网络模型
Pulsar Broker 是一个典型的 Reactor 模型,主要包含一个网络线程池,负责处理网络请求,进行网络的收发以及编解码,接着把请求通过请求队列推送给核心线程池进行处理。首先,Pulsar 采用多线程方式,充分利用现代系统的多核优势,把同一任务请求分配给同一个线程处理,尽量避免线程之间切换带来的开销。其次,Pulsar 采用队列方式实现了网络处理模块及核心处理模块的异步解耦,实现了网络处理和文件 I/O 并行处理,极大地提高了整个系统的效率。
通信协议
信息(message)采用二进制编码,格式简单;客户端生成二进制数据直接发送给 Pulsar 后端 broker,broker 端不解码直接发送给 bookie 存储,存储格式也是二进制,所以消息生产消费过程没有任何编解码操作。消息的压缩以及批量发送都是在客户端完成,这能进一步提升 broker 处理消息的能力。
队列模型
Pulsar 对主题(topic)进行分区(partition),并尽量将不同的分区分配到不同的 Broker,实现水平扩展。Pulsar 支持在线调整分区数量,理论上支持无限吞吐量。虽然 ZooKeeper 的容量和性能会影响 broker 个数和分区数量,但该限制上限非常大,可以认为没有上限。
磁盘 IO
消息队列属于磁盘 IO 密集型系统,所以优化磁盘 IO 至关重要。Pulsar 中的磁盘相关操作主要分为操作日志和数据日志两类。操作日志用于数据恢复,采用完全顺序写的模式,写入成功即可认为生产成功,因此 Pulsar 可以支持百万主题,不会因为随机写而导致性能急剧下降。
操作日志也可以是乱序的,这样可以让操作日志写入保持最佳写入速率,数据日志会进行排序和去重,虽然出现写放大的情况,但是这种收益是值得的:通过将操作日志和数据日志挂在到不同的磁盘上,将读写 IO 分离,进一步提升整个系统 IO 相关的处理能力。
条带化写入
条带化写入能够利用更多的 bookie 节点来进行 IO 分担;Bookie 设置了写缓存和读缓存。最新的消息放在写缓存,其他消息会批量从文件读取加入到读缓存中,提升读取效率。
从架构来看,Pulsar 在处理消息的各个流程中没有明显的卡点。操作日志持久化只有一个线程来负责刷盘,可能会造成卡顿。根据磁盘特性,可以设置多块盘,多个目录,提升磁盘读写性能,这完全能够满足我们的需求。
测试
在腾讯计费场景中,我们设置相同的场景,分别对 Pulsar 和 Kafka 进行了压测对比,具体的测试场景如下。

压测数据如下:
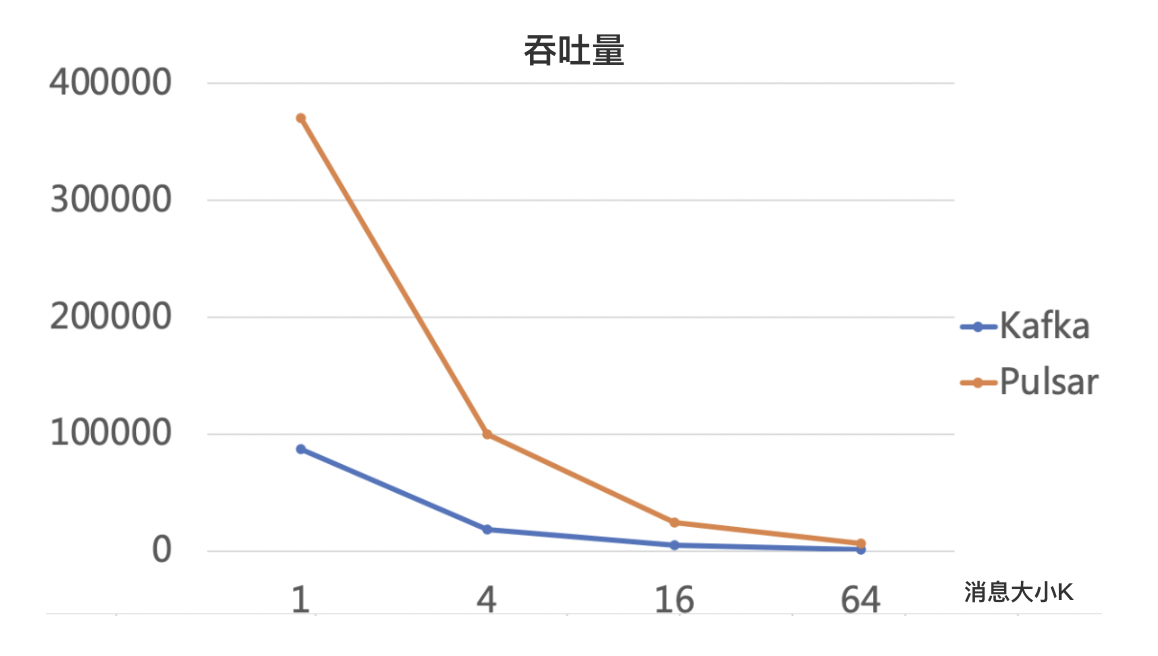

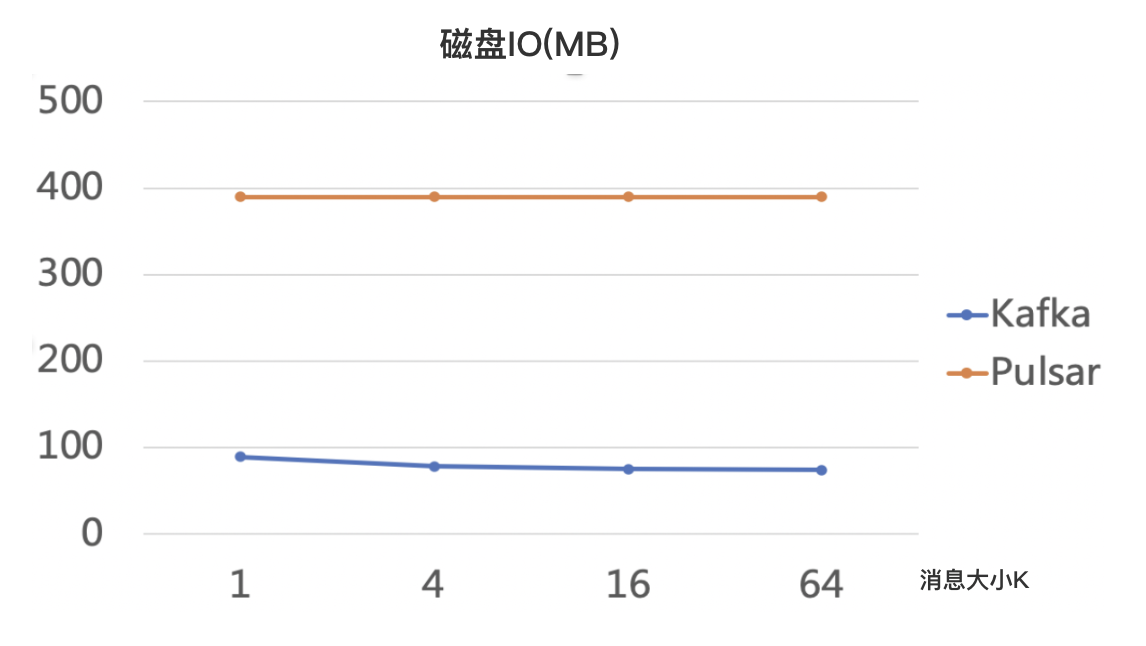
以上数据可以看到,网络 IO 方面,3 个副本多分区的情况下,Pulsar 几乎要把 broker 网卡出流量跑满,因为一份数据需要在 broker 端分发 3 次,这是计算存储分离的代价。
Kafka 的性能数据有点让人失望,整体性能没有上去,这应该和 Kafka 本身的副本同步机制有关:Kafka 采用的是 follow 同步拉取的策略,导致整体效率并不高。
延迟方面,Pulsar 在生产端表现更优越些,当资源没有到达瓶颈时,整个时耗 99% 在 10 毫秒以内,在垃圾回收(Garbage Collection,GC)和创建操作日志文件时会出现波动。
从压测的结果来看,在高一致的场景下,Pulsar 性能优于 Kafka。如果设置 log.flush.interval.messages=1 的情况,Kafka 性能表现更差,kafka 在设计之初就是为高吞吐,并没有类似直接同步刷盘这些参数。
此外,我们还测试了其他场景,比如百万 Topic 和跨地域复制等。在百万 Topic 场景的生产和消费场景测试中,Pulsar 没有因为 Topic 数量增长而出现性能急剧下降的情况,而 Kafka 因为大量的随机写导致系统快速变慢。
Pulsar 原生支持跨地域复制,并支持同步和异步两种方式。Kafka 在同城跨地域复制中,吞吐量不高,复制速度很慢,所以在跨地域复制场景中,我们测试了 Pulsar 同步复制方式,存储集群采用跨城部署,等待 ACK 时必须包含多地应答,测试使用的相关参数和同城一致。测试结果证明,在跨城情况下,Pulsar 吞吐量可以达到 28万QPS。当然,跨城跨地域复制的性能很大程度依赖于当前的网络质量。
可用性分析
作为新型分布式消息流平台,Pulsar 有很多优势。得益于 bookie 的分片处理以及 ledger 选择存储节点的策略,运维 Pulsar 非常简单,可以摆脱类似 Kafka 手动平衡数据烦扰。但 Pulsar 也不是十全十美,本身也存在一些问题,社区仍在改进中。
Pulsar 对 ZooKeeper 的强依赖
Pulsar 对 ZooKeeper 有很强的依赖。在极限情况下,ZooKeeper 集群出现宕机或者阻塞,会导致整个服务宕机。ZooKeeper 集群奔溃的概率相对小,毕竟 ZooKeeper 经过了大量线上系统的考验,使用还是相对广泛的。但 ZooKeeper 堵塞的概率相对较高,比如在百万 Topic 场景下,会产生百万级的 ledger 元数据信息,这些数据都需要与 ZooKeeper 进行交互。
例如,创建一次主题(topic),需要创建主题分区元数据、Topic 名、Topic 存储 ledger 节点;而创建一次 ledger 又需要创建和删除唯一的 ledgerid 和 ledger 元数据信息节点,一共需要 5 次 ZooKeeper 写入操作,一次订阅也需要类似的 4 次 ZooKeeper 写入操作,所以总共需要 9 次写入操作。如果同时集中创建百万级的主题,势必会对 ZooKeeper 造成很大的压力。
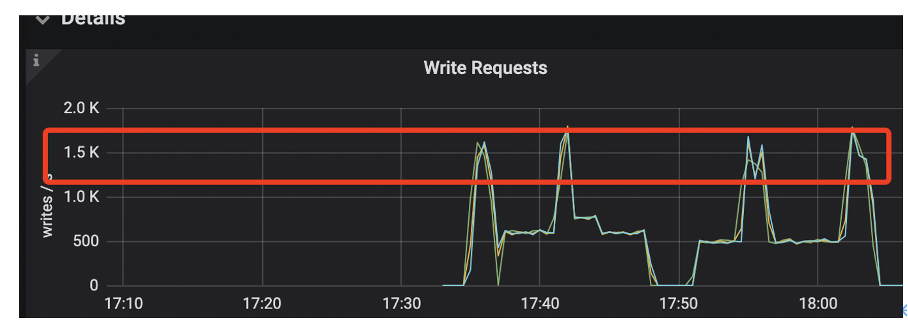
Pulsar 具有分散 ZooKeeper 部署的能力,能够在一定程度上缓解 ZooKeeper 的压力,依赖最大的是 zookeeperServer 这个 ZooKeeper 集群。从之前的分析来看,写操作相对可控,可以通过控制台创建 Topic。bookie 依赖的 ZooKeeper 操作频率最高,如果该 ZooKeeper 出现阻塞,当前写入并不会造成影响。
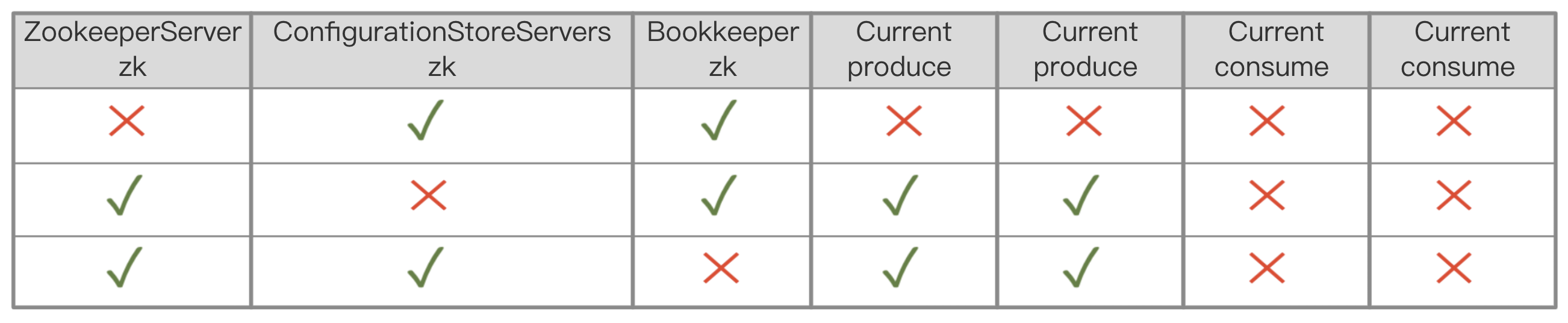
可以按照同样的思路优化对 zookeeperServerzk 的依赖。至少对于当前的服务可以持续一段时间,给 ZooKeeper 足够的时间进行恢复;其次减少 ZooKeeper 的写入次数,只用于必要的操作,比如 broker 选举等。像 broker 的负载信息,可以寻求其他存储介质,尤其是当一个 broker 服务大量主题时,这个信息会达到兆(M)级别。我们正在和 Pulsar 社区携手优化 broker 负载功能。
Pulsar 内存管理稍复杂
Pulsar 的内存由 JVM 的堆内存和堆外存构成,消息的发送和缓存通过堆外内存来存储,减少 IO 造成的垃圾回收(GC);堆内存主要缓存 ZooKeeper 相关数据,比如 ledger 的元数据信息和订阅者重推的消息 ID 缓存信息,通过 dump 内存分析发现,一个 ledger 元数据信息需要占用约 10K,一个订阅者者重推消息 ID 缓存初始为 16K,且会持续增长。当 broker 的内存持续增长时,最终频繁进行整体垃圾回收(full GC),直到最终退出。
要解决这个问题,首先要找到可以减少内存占用的字段,比如 ledger 元数据信息里面的 bookie 地址信息。每个 ledger 都会创建对象,而 bookie 节点非常有限,可以通过全局变量来减少创建不必要的对象;订阅者重推消息 ID 缓存可以把初始化控制在 1K 内,定期进行缩容等。这些操作可以大大提升 Broker 的可用性。
和 Kafka 相比,Pulsar broker 的优点比较多,Pulsar 能够自动进行负载均衡,不会因为某个 broker 负载过高导致服务不稳定,可以快速扩容,降低整个集群的负载。
总结
总体来说,Pulsar 在高一致场景中,性能表现优异,目前已在腾讯内部广泛使用,比如腾讯金融和大数据场景。大数据场景主要基于 KOP 模式,目前其性能已经非常接近 Kafka,某些场景甚至已经超越 Kafka。我们深信,在社区和广大开发爱好者的共同努力下,Pulsar 会越来越好,开启下一代云原生消息流的新篇章。
本文作者:刘德志
腾讯专家工程师、TEG 技术工程事业群和计费系统开发者
硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析的更多相关文章
- 决策树算法的Python实现—基于金融场景实操
决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界 基本概念 决策树(Decision Tree) 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数 ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- Colder框架硬核更新(Sharding+IOC)
目录 引言 控制反转 读写分离分库分表 理论基础 设计目标 现状调研 设计思路 实现之过五关斩六将 动态对象 动态模型缓存 数据源移植 查询表达式树深度移植 数据合并算法 事务支持 实际使用 展望未来 ...
- 硬核数据结构,让你从B树理解到B+树
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是周五分布式系统的第八篇文章,核心内容是B+树的原理. 今天的文章是上周B树的延伸,所以新关注的或者是有所遗忘的同学建议先从下方链接回顾 ...
- 「持续集成实践系列」Jenkins 2.x 搭建CI需要掌握的硬核要点
1. 前言 随着互联网软件行业快速发展,为了抢占市场先机,企业不得不持续提高软件的交付效率.特别是现在国内越来越多企业已经在逐步引入DevOps研发模式的变迁,在这些背景催促之下,对于企业研发团队所需 ...
- Pulsar vs Kafka,CTO 如何抉择?
本文作者为 jesse-anderson.内容由 StreamNative 翻译并整理. 以三个实际使用场景为例,从 CTO 的视角出发,在技术等方面对比 Kafka 和 Pulsar. 阅读本文需要 ...
- 开发测试时给 Kafka 发消息的 UI 发送器――Mikasa
开发测试时给 Kafka 发消息的 UI 发送器――Mikasa 说来话长,自从入了花瓣,整个人就掉进连环坑了. 后端元数据采集是用 Storm 来走拓扑流程的,又因为 @Zola 不是很喜欢 Jav ...
- FPGA的软核与硬核
硬核 zynq和pynq系列的fpga都是双ARM/Cortex-A9构成,这里的ARM处理器为硬核,Cortex-A9部分为FPGA部分.即整体分为两部分:PS/PL.PS部分为A9处理器部分,PL ...
- 嵌入ARM硬核的FPGA
目前,在FPGA上嵌入ARM硬核的包括Xilinx的zynq系列以及Intel 的CYCLONEV系列. Zynq出来有一定市场,但是这个市场不是传统FPGA的主流市场,而是为了和微处理抢一些控制领域 ...
随机推荐
- 手写迷你Tomcat
手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat手写迷你Tomcat ...
- [PyTorch 学习笔记] 3.3 池化层、线性层和激活函数层
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_others.py 这篇文章主要介绍 ...
- 网络请求以及网络请求下载图片的工具类 android开发java工具类
package cc.jiusan.www.utils; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; ...
- IOS 打包相关
Unity 导出的Xcode工程 http://gad.qq.com/article/detail/29330 [Unity3D]Unity 生成的XCode工程结构 http://blog.163. ...
- Linux常用命令--不断更新
Linux命令: !. 1.[root@loc8lhost/root]# 表示登陆进去系统,其中#是超级⽤用户也即root⽤用 户的系统提示符 #. 2.reboot命令可以重启系统 $. 3.关闭系 ...
- uniapp 获取元素高度 距离顶部高度等
let _this=this let height="" const query = uni.createSelectorQuery() query.select('#u-drop ...
- MyBatis-Plus分页——PageHelper和IPage介绍
两个都用于分页,常用的应该是PageHelper了,理解了一下源码后发现IPage比PageHelper好用. 使用方法是 PageHelper.startPage()然后后边写sql就可以. 紧接着 ...
- 想要使用GPU进行加速?那你必须事先了解CUDA和cuDNN
这一期我们来介绍如何在Windows上安装CUDA,使得对图像数据处理的速度大大加快,在正式的下载与安装之前,首先一起学习一下预导知识,让大家知道为什么使用GPU可以加速对图像的处理和计算,以及自己的 ...
- python3之print()函数
print语法格式 print()函数具有丰富的功能,详细语法格式如下: print(value, -, sep=' ', end='\n', file=sys.stdout, flush=False ...
- Tomcat源码分析(类加载与类加载器)
Tomcat的挑战 Tomcat上可以部署多个项目 Tomcat的一般部署,可以通过多种方式启动一个Tomcat部署多个项目,那么Tomcat在设计时会遇到什么挑战呢? Tomcat运行时需要加载哪些 ...