大规模数据爬取 -- Python
Python书写爬虫,目的是爬取所有的个人商家商品信息及详情,并进行数据归类分析
整个工作流程图:
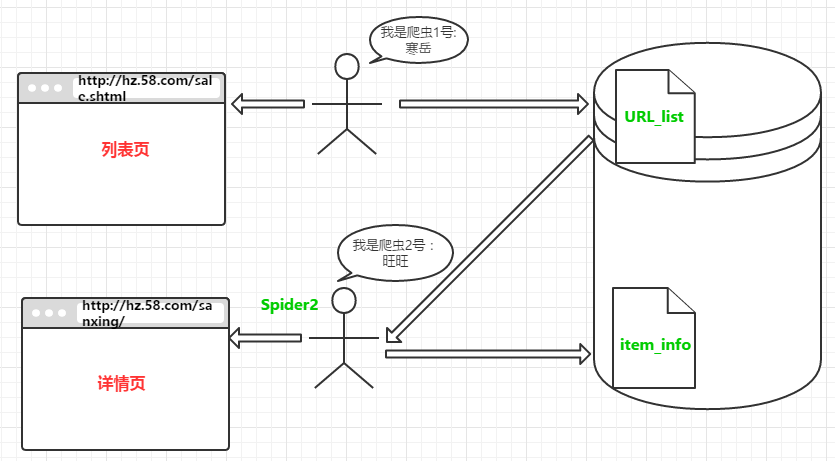
第一步:采用自动化的方式从前台页面获取所有的频道
from bs4 import BeautifulSoup
import requests #1、找到左侧边栏所有频道的链接
start_url = 'http://hz.58.com/sale.shtml'
url_host = 'http://hz.58.com' def get_channel_urls(url):
wb_data = requests.get(start_url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('ul.ym-mainmnu > li > span > a["href"]')
for link in links:
page_url = url_host + link.get('href')
print(page_url)
#print(links) get_channel_urls(start_url) channel_list = '''
http://hz.58.com/shouji/
http://hz.58.com/tongxunyw/
http://hz.58.com/danche/
http://hz.58.com/diandongche/
http://hz.58.com/diannao/
http://hz.58.com/shuma/
http://hz.58.com/jiadian/
http://hz.58.com/ershoujiaju/
http://hz.58.com/yingyou/
http://hz.58.com/fushi/
http://hz.58.com/meirong/
http://hz.58.com/yishu/
http://hz.58.com/tushu/
http://hz.58.com/wenti/
http://hz.58.com/bangong/
http://hz.58.com/shebei.shtml
http://hz.58.com/chengren/
'''
第二步:通过第一步获取的所有频道去获取所有的列表详情,并存入URL_list表中,同时获取商品详情信息
from bs4 import BeautifulSoup
import requests
import time
import pymongo client = pymongo.MongoClient('localhost',27017)
ceshi = client['ceshi']
url_list = ceshi['url_list']
item_info = ceshi['item_info'] def get_links_from(channel,pages,who_sells=0):
#http://hz.58.com/shouji/0/pn7/
list_view = '{}{}/pn{}/'.format(channel,str(who_sells),str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('td.t > a[onclick]')
if soup.find('td','t'):
for link in links:
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})
print(item_link)
else:
pass
# Nothing def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
no_longer_exist = '商品已下架' in soup
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price_now > i')[0].text
area = soup.select('div.palce_li > span > i')[0].text
#url_list.insert_one({'title':title,'price':price,'area':area})
print({'title':title,'price':price,'area':area}) #get_links_from('http://hz.58.com/pbdn/',7)
#get_item_info('http://zhuanzhuan.58.com/detail/840577950118920199z.shtml')
第三步:采用多进程的方式的main主函数入口
from multiprocessing import Pool
from channel_extract import channel_list
from page_parsing import get_links_from def get_all_links_from(channel):
for num in range(1,31):
get_links_from(channel,num) if __name__ == '__main__':
pool = Pool()
pool.map(get_all_links_from,channel_list.split())
第四步:实时对获取到的数据进行监控
from time import sleep
from page_parsing import url_list while True:
print(url_list.find().count())
sleep(5)
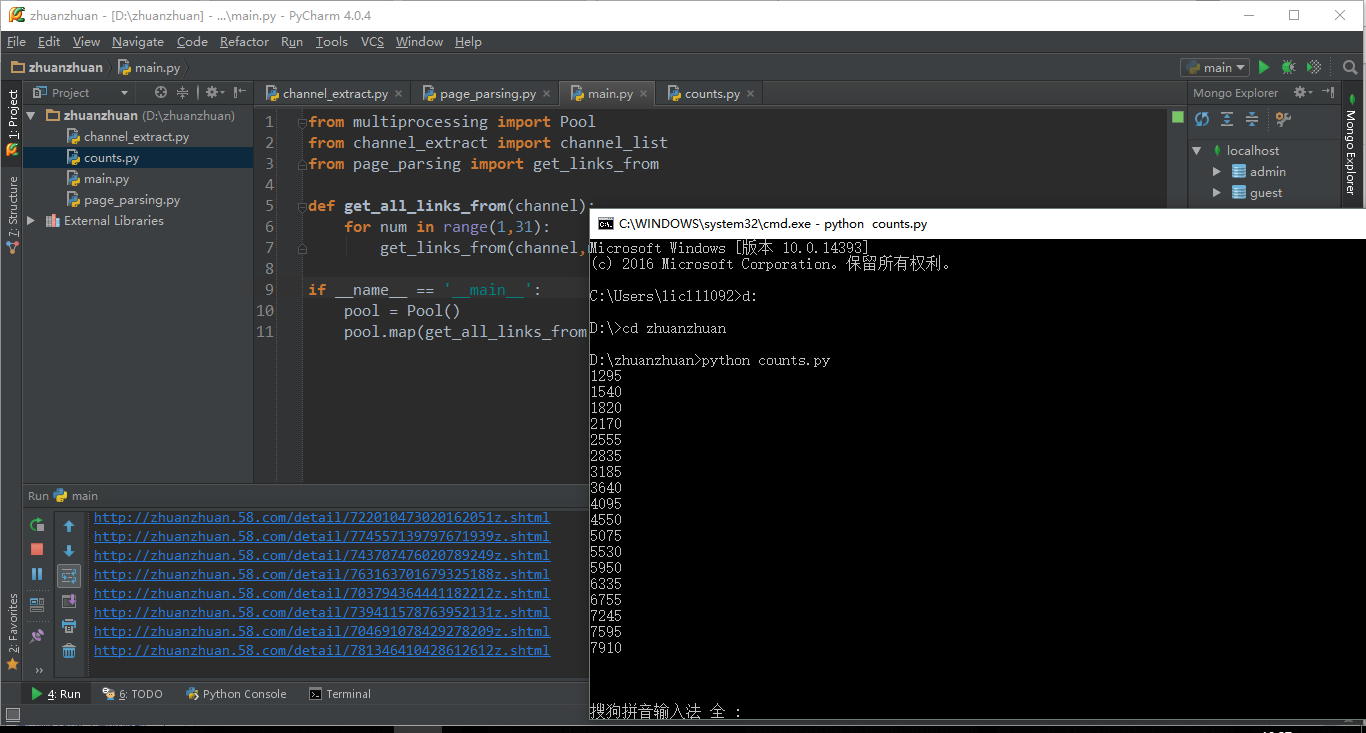
具体运行效果:
大规模数据爬取 -- Python的更多相关文章
- 模拟登陆+数据爬取 (python+selenuim)
以下代码是用来爬取LinkedIn网站一些学者的经历的,仅供参考,注意:不要一次性大量爬取会被封号,不要问我为什么知道 #-*- coding:utf-8 -*- from selenium impo ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- 人人贷网的数据爬取(利用python包selenium)
记得之前应同学之情,帮忙爬取人人贷网的借贷人信息,综合网上各种相关资料,改善一下别人代码,并能实现数据代码爬取,具体请看我之前的博客:http://www.cnblogs.com/Yiutto/p/5 ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
随机推荐
- yum -y install gnuplot
[root@test~]# yum -y install gnuplotLoaded plugins: fastestmirrorLoading mirror speeds from cached h ...
- pandas 读写excel 操作(按索引和关键字读取行和列,写入csv文件)
pandas读写excel和csv操作总结 按索引读取某一列的值 按关键字读取某一列的值 按关键字查询某一行的值 保存成字典并写入新的csv import pandas as pd grades=pd ...
- pod管理调度约束、与健康状态检查
pod的管理 [root@k8s-master ~]# vim pod.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: ...
- oracle rac搭建单实例DG步骤(阅读全篇后再做)
环境介绍 主库: 主机名 rac01 rac02 实体IP 10.206.132.232 10.206.132.233 私有IP 192.168.56.12 192.168.56.13 虚拟IP 10 ...
- oracle_fdw的安装和使用
1.下载instant oracle client 下载网址:https://www.oracle.com/technetwork/topics/linuxx86-64soft-092277.html ...
- 07--Docker安装Redis
1.拉取redis:3.2 docker pull redis:3.2 2.创建redis容器 docker run -p 6379:6379 -v /zhengcj/myredis/data:/da ...
- Go 和 Syscall
曹春晖:谈一谈 Go 和 Syscall https://juejin.im/post/6844903845475139597
- nginx http模块开发入门
导语 本文对nginx http模块开发需要掌握的一些关键点进行了提炼,同时以开发一个简单的日志模块进行讲解,让nginx的初学者也能看完之后做到心里有谱.本文只是一个用作入门的概述. 目录 背景 主 ...
- (十一)整合 FastDFS 中间件,实现文件分布式管理
整合 FastDFS 中间件,实现文件分布式管理 1.FastDFS简介 1.1 核心角色 1.2 运转流程 2.SpringBoot整合FastDFS 2.1 核心步骤 2.2 核心依赖 2.3 配 ...
- Centos7安装成功后,网卡配置及更改镜像地址为国内镜像
Centos7安装成功后,网卡配置及更改镜像地址为国内镜像 一.网卡配置 二.修改网络配置 踩坑一:IPADDR 踩坑二:网关,DNS与本地不一致 重启网络服务 三.镜像修改为aliyun 四.相关知 ...