Failed to create Spark client for Spark session
最近在hive里将mr换成spark引擎后,执行插入和一些复杂的hql会触发下面的异常:
org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session c5924990-6187-4a15-a760-ec3b1afbc199
未能创建spark客户端的原因有这几个:
1,spark没有打卡
2,spark和hive版本不匹配
3,hive连接spark客户端时长过短
解决方案:
1,在进入hive之前,需要依次启动hadoop,spark,hiveservice,这样才能确保hive在启动spark引擎时能成功
spark启动:
cd /opt/spark
./sbin/start-all.sh
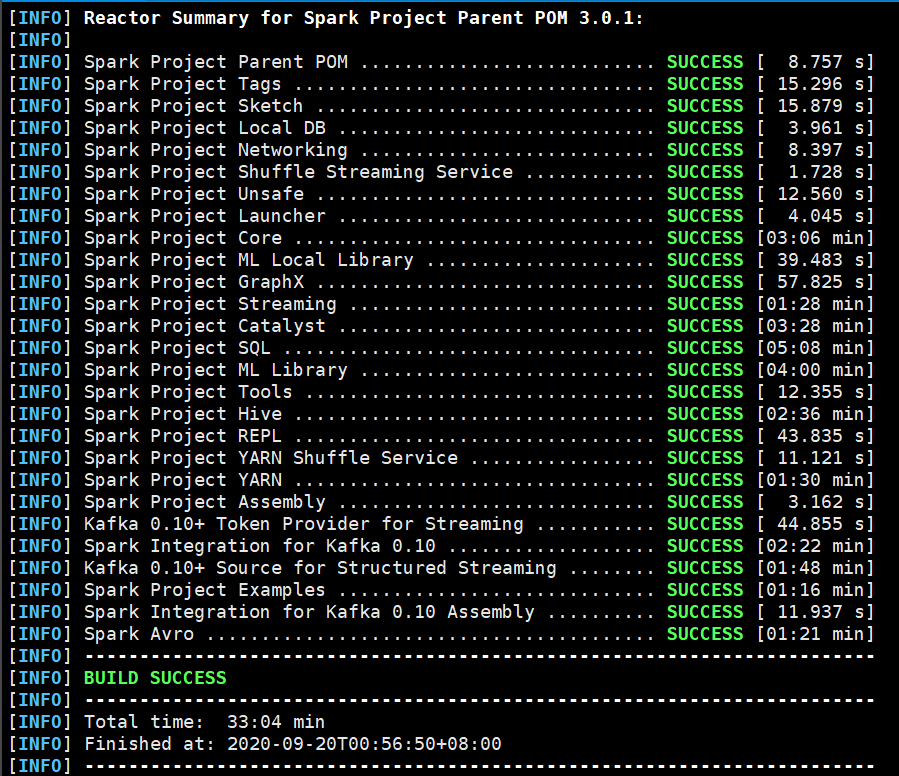
2,版本问题是最常见也是出现最多的问题,我用的版本依次为hadoop3.3.0,hive3.1.2,spark2.4.7,之前测试过spark3.0.1,发现和hive不兼容
这里还需要注意Apache官网的提供了如图所示的几个spark包版本:

但在集成hive时spark本身不能自带hive配置,所以只有第三个是可以用的,但是我测试了一下在我的电脑上还是报错,所以我选择了自己编译,下载最后一个源码包,解压后进入spark目录
输入命令:
./dev/make-distribution.sh --name without-hive --tgz -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.0 -Pparquet-provided -Porc-provided -Phadoop-provided
但是发现编译卡住了,原来编译会自动下载maven,scala,zinc,存放在build目录下,如图:
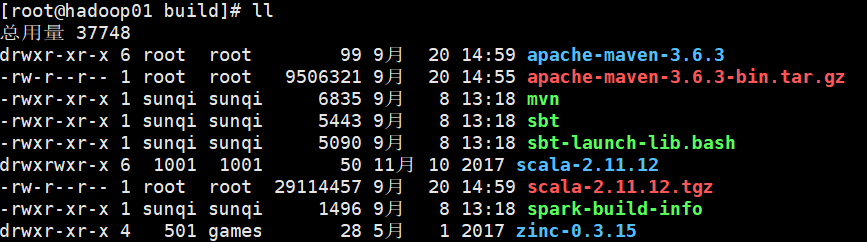
由于下载过于缓慢,这里直接将这三个包放在build目录下,解压好,编译时会自动识别,可以省去很多时间,快速进入编译,需要压缩包的可以关注公众号:Tspeaker97 给我发消息找我要
编译过程比较慢,我花了30分钟才将spark编译好,中间还网络断流卡住失败了一次,如果不能访问外网的,建议将maven镜像改为阿里云。
编译完成后在spark目录下就可以看到编译出的tgz包,解压到对应目录:
vim spark-env.sh
插入如下代码:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
接下来就是hive的设置,这里我用的是公司编译好的版本,大小比Apache官网大一点,想要可以微信扣我
进入hive/conf目录:
vim spark-defaults.conf
插入如下代码:
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9820/spark-history
spark.executor.memory 2g
在hdfs创建对应目录并拷贝jar包:
hadoop fs -mkdir /spark-history
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/spark/jars/* /spark-jars
在hive/conf/hive-site.xml中增加:(这里特地延长了hive和spark连接的时间,可以有效避免超时报错)
<!--Spark依赖位置-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop01:9820/spark-jars/*</value>
</property> <!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property> <!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>100000ms</value>
</property>
然后启动spark服务,hive服务,并进入hive客户端,执行hql:
set hive.exec.mode.local.auto=true; create table visit(user_id string,shop string) row format delimited fields terminated by '\t'; load data local inpath '/opt/hive/datas/user_id' into table visit; SELECT t1.shop,
t1.user_id,
t1.count,
t1.rank
FROM
(SELECT shop,
user_id,
count(user_id) COUNT,
rank() over(partition BY shop ORDER BY count(user_id) DESC) rank
FROM visit
GROUP BY user_id,
shop
ORDER BY shop ASC, COUNT DESC ) t1
WHERE rank <4;
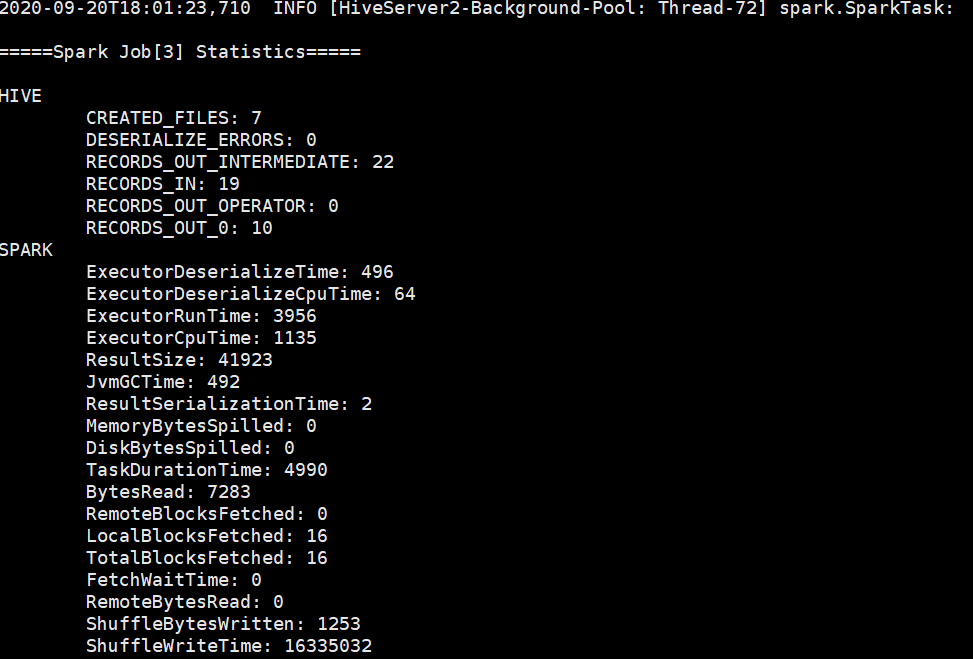
spark引擎成功启动:
如果有其他问题,欢迎叨扰:
Failed to create Spark client for Spark session的更多相关文章
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- AX2012 R3 Data upgrade checklist sync database step, failed to create a session;
最近在做AX2012 R3 CU9 到CU11的upgrade时 (用的Admin帐号), 在Date upgrade 的 synchronize database 这步 跑了一半,报出错误 说“fa ...
- Tensorflow 报错:tensorflow.python.framework.errors_impl.InternalError: Failed to create session.
问题描述 IDE:pycharm,环境中安装tensorflow-gpu 1.8.0 ,Cuda9 ,cudnn 7,等,运行代码 报错如下 tensorflow.python.framework.e ...
- Spark On Yarn报警告信息 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
1 贴出完整日志信息 // :: INFO client.RMProxy: Connecting to ResourceManager at hdp1/ // :: INFO yarn.Client: ...
- Spark Client启动原理探索
经过几天闲暇时间的学习,终于又理解的深入了一些,关于Spark Client如何提交作业也更清晰了点. 在整体的流程图上是这样的: 大体的思路就是应用程序通过SparkSubmit提交程序后,自动在当 ...
- 用NFS挂载root出现:NFS: failed to create MNT RPC client, status=-101(-110)
2014-02-18 08:06:17 By Ly #Linux 阅读(78) 评论(0) 错误信息如下: Root-NFS: nfsroot=/home/zenki/nfs/rootfs NFS ...
- spark client + yarn计算
前提:完成hadoop + kerberos安全环境搭建. 安装配置spark client: 1. wget https://d3kbcqa49mib13.cloudfront.net/spark- ...
- 【原创】大数据基础之Spark(1)Spark Submit即Spark任务提交过程
Spark2.1.1 一 Spark Submit本地解析 1.1 现象 提交命令: spark-submit --master local[10] --driver-memory 30g --cla ...
- Docker 搭建Spark 依赖sequenceiq/spark:1.6镜像
使用Docker-Hub中Spark排行最高的sequenceiq/spark:1.6.0. 操作: 拉取镜像: [root@localhost home]# docker pull sequence ...
随机推荐
- PyQt(Python+Qt)学习随笔:QListView的itemAlignment属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListView的itemAlignment属性用于控制每个数据项的对齐方式,其类型为枚举类Qt. ...
- PyQt(Python+Qt)学习随笔:Designer中的QDialogButtonBox的StandardButtons标准按钮
在Qt Designer中,可以在界面中使用QDialogButtonBox来配置一组按钮进行操作,Qt中为QDialogButtonBox定义了一组常用的标准按钮,可以在Designer中直接在St ...
- js- 对象的连续调用
var jack = { somke : function (){ console.log('I was in the somkeing...cool..'); return this; }, dri ...
- 2. Spring早期类型转换,基于PropertyEditor实现
青年时种下什么,老年时就收获什么.关注公众号[BAT的乌托邦],有Spring技术栈.MyBatis.JVM.中间件等小而美的原创专栏供以免费学习.分享.成长,拒绝浅尝辄止.本文已被 https:// ...
- js监测页面是否切换到后台
最近做个弹幕,用的是第三方的插件,在浏览器页面切换到后台,返回后发现数据有堆叠卡死的情况,如何解决这个问题?网上参考了些demo,大致可以实现 1.document.hidden( Boolean值, ...
- 【NOI2018】你的名字(SAM & 线段树合并)
Description Hint Solution 不妨先讨论一下无区间限制的做法. 首先"子串"可以理解为"前缀的后缀",因此我们定义一个 \(\lim(i) ...
- Python搭建调用本地dll的Windows服务(浏览器可以访问,附测试dll64位和32位文件)
一.前言说明 博客声明:此文链接地址https://www.cnblogs.com/Vrapile/p/14113683.html,请尊重原创,未经允许禁止转载!!! 1. 功能简述 (1)本文提供生 ...
- Android原子操作——android_atomic_cmpxchg
网络给我们带来了很多方便,查阅我们目前认知范围外的道理.但是,凡事也要学会分辨,不然可能会误导你. 话说,最近的一个项目(Mercury-Project),接近尾声中.然而,在调试一个demo时,却遇 ...
- 基于menu小插件探索工程实践
目录 一.准备工作 1.C/C++环境搭建 2.VSCode的配置 (1) 安装插件: (2) 设置配置文件: 二.工程化编程实战 1.模块化设计 2.可重用设计:进一步抽象 menu的进一步优化 可 ...
- react第十三单元(react路由-react路由的跳转以及路由信息) #课程目标
第十三单元(react路由-react路由的跳转以及路由信息) #课程目标 熟悉掌握路由的配置 熟悉掌握跳转路由的方式 熟悉掌握路由跳转传参的方式 可以根据对其的理解封装一个类似Vue的router- ...