利用sklearn实现k-means
基于上面的一篇博客k-means利用sklearn实现k-means
#!/usr/bin/env python
# coding: utf-8 # In[1]: import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans # In[4]: # 加载数据
dataset = []
for line in open("data_kmeans.csv"):
x, y = line.split(",")
dataset.append([int(x), int(y)])
print(dataset) # In[13]: k=3
# 训练模型
model = KMeans(n_clusters=k)
model.fit(dataset)
# 分类中心点坐标
centers = model.cluster_centers_
print(center) # In[15]: # 预测结果
result = model.predict(dataset)
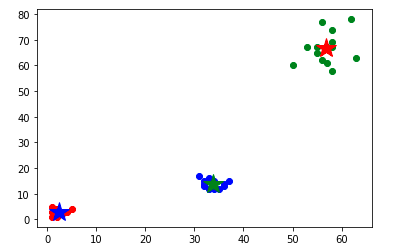
print(result) # In[42]: # 用不同的颜色绘制数据点
mark = ['or', 'og', 'ob']
for i,d in enumerate(dataset):
plt.plot(d[0], d[1], mark[result[i]])
# 画出各分类点的中心点
mark = ['*b', '*r', '*g'] # 为了凸显质心,把每个簇的质心颜色换成其他的
for i, center in enumerate(centers):
plt.plot(center[0], center[1], mark[i], markersize=20) # In[ ]:
利用sklearn实现k-means的更多相关文章
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 利用Sklearn实现加州房产价格预测,学习运用机器学习的整个流程(包含很多细节注解)
Chapter1_housing_price_predict .caret, .dropup > .btn > .caret { border-top-color: #000 !impor ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- 利用sklearn实现knn
基于上面一篇博客k-近邻利用sklearns实现knn #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np import ...
- sklearn的K折交叉验证函数KFold使用
K折交叉验证时使用: KFold(n_split, shuffle, random_state) 参数:n_split:要划分的折数 shuffle: 每次都进行shuffle,测试集中折数的总和就是 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
代码详解: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split fr ...
- 利用sklearn进行tfidf计算
转自:http://blog.csdn.net/liuxuejiang158blog/article/details/31360765?utm_source=tuicool 在文本处理中,TF-IDF ...
- TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu
import tensorflow as tf from sklearn.datasets import load_digits #from sklearn.cross_validation impo ...
随机推荐
- 跟我一起学Redis之五种基本类型及其应用场景举例(干了6个小时)
前言 来啦,老弟?来啦,上一篇就当唠唠嗑,接下来就开始进行实操撸命令,计划是先整体单纯说说Redis的各种用法和应用,最后再结合代码归纳总结. Redis默认有16个数据库(编号为0~15),默认使用 ...
- python框架day01
一.注意事项 # 如何让你的计算机能够正常的启动django项目 1.计算机的名称不能有中文 2.一个pycharm窗口只开一个项目 3.项目里面所有的文件也尽量不要出现中文 4.python解释器尽 ...
- 2440启动流程 <转载>
韦东山 博客园 首页 订阅 管理 2440启动过程分析 2440启动过程分析 2440启动过程算是一个难点,不太容易理解,而对于2440启动过程的理解,影响了后面裸机代码执行流程的分析,从而看出2 ...
- 用redis当作LRU缓存
原文地址:https://redis.io/topics/lru-cache Redis可以用来作缓存,他可以很方便的淘汰(删除)旧数据添加新数据,类似memcached.LRU只是其中的一种置换算法 ...
- LR Optimization-Based Estimator Design for Vision-Aided Inertial Navigation
Abstract 我们设计了一个 hybrid 估计器, 组合了两种算法, sliding-window EKF 和 EKF-SLAM. 我们的结果表示, hybrid算法比单一的好. 1. Intr ...
- day60 Pyhton 框架Django 03
day61 内容回顾 1.安装 1. 命令行: pip install django==1.11.18 pip install django==1.11.18 -i 源 2. pycharm sett ...
- day39 Pyhton 并发编程02
一.内容回顾 并发和并行的区别 并发 宏观上是在同时运行的 微观上是一个一个顺序执行 同一时刻只有一个cpu在工作 并行 微观上就是同时执行的 同一时刻不止有一个cpu在工作 什么是进程 一个运行中的 ...
- day16 Pyhton学习
1.range(起始位置) range(终止位置) range(起始,终止位置) range(起始,终止,步长) 2.next(迭代器) 是内置函数 __next__是迭代器的方法 g.__next_ ...
- 界面酷炫,功能强大!这款 Linux 性能实时监控工具超好用!
对于维护.管理Linux系统来说,它的性能监控非常重要,特别是实时监控数据,这个数据有利于我们判断服务器的负载压力,及时调整资源调配,也有助于更好的服务于业务.所以,今天民工哥给大家安利一款 Linu ...
- xuexi0.2
1.数据结构就是研究数据如何排布和如何加工. 2.数组的目的是为了管理程序中类型相同,意义相关的变量. 3.数组的优势是比较简单,可以通过访问下标来进行随机访问.数组的限制:元素类型必须相同,数组的大 ...