solr 文档二
SOLR 5.5.5文档
参考博文:
http://blog.csdn.net/matthewei6/article/details/50620600
作者:毛平
时间:2018年1月15日 17:36:22
环境搭建
solr版本5.5.5,可以独立部署,使用默认的Jetty启动。
1. 准备条件
环境:JDK需要1.7以上,最好是1.8
下载软件包:
使用清华大学的镜像包:
https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/5.5.5/solr-5.5.5.tgz
命令:curl https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/5.5.5/solr-5.5.5.tgz
或者wget https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/5.5.5/solr-5.5.5.tgz
2. 解压
tar -zxvf solr-5.5.5.tgz
3. 启动服务器
bin/solr start
SOLR初级
1. 创建core
说明:本文是基于容器jetty,创建core相当于创建容器中的新项目。一个独立的搜索引擎项目。
bin/solr create -c maopcore
bin/solr delete -c maopcore -------删除已创建的core
2. 添加中文分次器
说明:基于刚才新建的core,添加ik分词器。使core具备中文分词的功能。
1. 修改配置文件
managed-schema(相对路径为:${PATH}\server\solr\mycore\conf\managed-schema) 添加下面的内容:
<!-- 中文分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
2. 添加ik分词器的jar
需要确保jar和solr的版本一致
安装路径为${PATH}\server\solr-webapp\webapp\WEB-INF\lib。

3. 验证ik安装正确
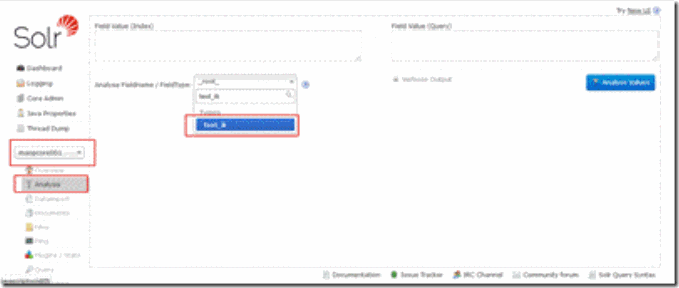
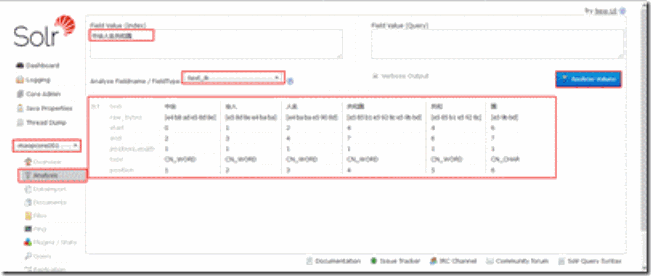
4. 查看分词效果
(可以看到,新建的core已经具备分词功能)。
3. 添加数据库连接
说明:参考http://blog.csdn.net/u011518678/article/details/51871925
1. 创建连接配置data-config
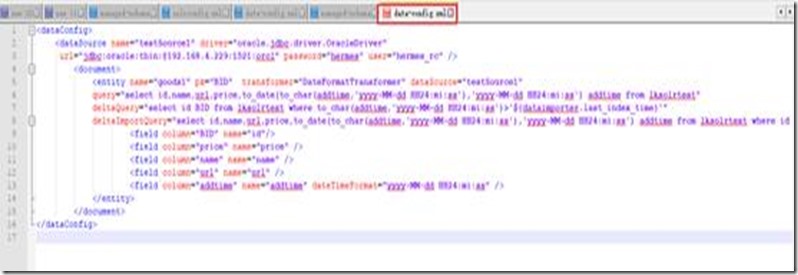
配置当前core的数据连接的配置文件。在路径{当前core}/conf 下创建data-config.xml文件。内容为
<dataConfig>
<dataSource name="testSource1" driver="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@192.168.4.229:1521:orcl" password="hermes" user="hermes_rc" />
<document>
<entity name="goods1" pk="BID" transformer="DateFormatTransformer" dataSource="testSource1"
query="select id,name,url,price,to_date(to_char(addtime,'yyyy-MM-dd HH24:mi:ss'),'yyyy-MM-dd HH24:mi:ss') addtime from lksolrtest"
deltaQuery="select id BID from lksolrtest where to_char(addtime,'yyyy-MM-dd HH24:mi:ss')>'${dataimporter.last_index_time}'"
deltaImportQuery="select id,name,url,price,to_date(to_char(addtime,'yyyy-MM-dd HH24:mi:ss'),'yyyy-MM-dd HH24:mi:ss') addtime from lksolrtest where id = '${dataimporter.delta.BID}'">
<field column="BID" name="id"/>
<field column="price" name="price" />
<field column="name" name="name" />
<field column="url" name="url" />
<field column="addtime" name="addtime" dateTimeFormat="yyyy-MM-dd HH24:mi:ss" />
</entity>
</document>
</dataConfig>
文本如下图:
2. 添加数据库连接jar
本例子使用的oracle数据库,路径{solr绝对路径}\server\solr-webapp\webapp\WEB-INF\lib
3. 关联data-config
在{solr绝对路径}\server\solr\{#core}\conf\solrconfig.xml对应位置添加
<lib dir="./lib" regex=".*\.jar" />
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
接着注释掉下面的内容,防止id默认为String类型
<!--
<searchComponent name="elevator" class="solr.QueryElevationComponent" >
<str name="queryFieldType">string</str>
<str name="config-file">elevate.xml</str>
</searchComponent>
-->
4. 域和数据库字段对应关系
配置文件的路径{core绝对路径}\conf\managed-schema
<field name="id" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type = "text_ik" indexed="true" stored="true" />
<field name="price" type = "float" indexed="true" stored="true" />
<field name="url" type = "text_ik" indexed="true" stored="true" />
<field name="addtime" type = "date" indexed="true" stored="true" />
<uniqueKey>id</uniqueKey>
5. 索引数据导入jar
添加依赖jar(solr-dataimporthandler-5.5.5.jar、solr-dataimporthandler-extras-5.5.5.jar、mydataimportscheduler.jar,其中前两个jar在solr的\dist,my….jar在需要单独找) {相对路径}\solr-5.5.5\server\solr-webapp\webapp\WEB-INF\lib下
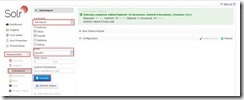
6. 手动验证导入索引
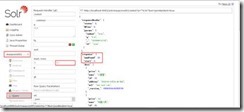
1. 如下选中core(项目),dataImport(索引导入),索引更新方式(此处为全量更新),选择实体,点击执行。
2. 界面查询
选择core,query菜单,点击查询,得到刚才导入的索引数据
7. 配置entry详解
4. 动态索引导入
说明:solr是一个web项目,在webapp下的web.xml文件中添加监控器,启动定时周期任务。调用增量的索引生成函数。索引动态的添加入库。
1. 调整时区为北京
说明:Solr默认时区为世界时区UTC,需要修改为GMT+08:00(北京时区)
在{solr}/bin/solr.in.cmd文件中,找到SOLR_TIMEZONE的设置行,修改为
set SOLR_TIMEZONE=GMT+08:00
2. 添加监控器配置
说明:添加监听器,ApplicationListener为mydataimportscheduler.jar中的类。他会自动调用配置文件{solr}\server\solr\ conf\ dataimport.properties。会启动两个定时任务。Timer-0和timer-1.其中timer-0负责增量定时任务的调用。Timer-1负责定时全量数据的调用。
在{solr绝对路径}\server\solr-webapp\webapp\WEB-INF\web.xml文件中添加监听器
<listener>
<listener-class>
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
</listener-class>
</listener>
3. 创建定时任务配置文件
说明:文件中有定时的全量更新配置,也有定时增量配置。真正使用选取其中一种即可。监控器调用当前配置文件。
在\server\solr\下创建文件夹conf,并创建dataimport.properties,内容如下:
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
#syncCores=liukuncore,liukuncore1
syncCores=maopcore001
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
port=8983
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
#params=/deltaimport?command=delta-import&clean=false&commit=true
params=/dataimport?command=delta-import&clean=false&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
interval=1
# 重做索引的时间间隔,单位分钟,默认1440,即1天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=1440
# 重做索引的参数
#reBuildIndexParams=/deltaimport?command=full-import&clean=true&commit=true
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间#=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=2018-01-14 15:14:00
4. 配置文件参数详解
syncCores:调用的currentCore,如果是多个core,使用逗号隔开
server: 服务ip或者名称,例如:localhost
port: 服务端口
增量配置参数:
Params: 增量url
Interval: 增量时间间隔(单位:分钟)
全量配置参数:
reBuildIndexParams: 全量url
reBuildIndexInterval:全量时间间隔(单位:分钟)
reBuildIndexBeginTime:全量第一次执行开始时间
5. 数据节点详解
说明:数据索引导入需要配置数据节点。
比如:
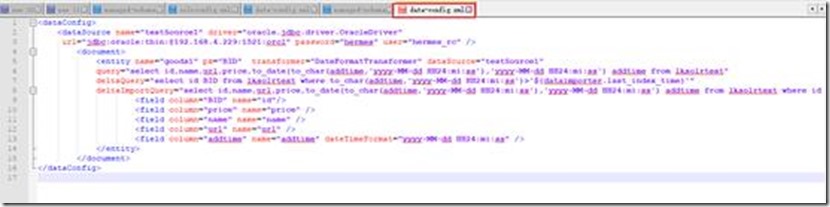
配置节点包含dataSource和document节点。
dataSource是数据库的配置。关注的主要有url,user,password。
1. query是获取全部数据的SQL(全量更新的sql)
2. deltaImportQuery是获取增量数据时使用的SQL
3. deltaQuery是获取增量pk的SQL
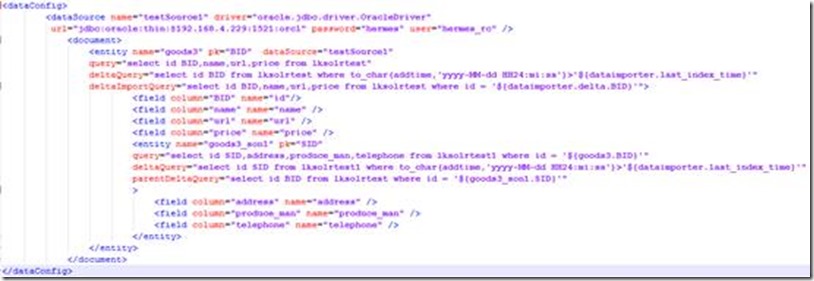
4. parentDeltaQuery是获取父Entity的pk的SQL
SOLR 中级
多表关联
Full Import工作原理:
执行本Entity的Query,获取所有数据;
针对每个行数据Row,获取pk,组装子Entity的Query;
执行子Entity的Query,获取子Entity的数据。
Delta Import工作原理:
查找子Entity,直到没有为止;
执行Entity的deltaQuery,获取变化数据的pk;
合并子Entity parentDeltaQuery得到的pk;
针对每一个pk Row,组装父Entity的parentDeltaQuery;
执行parentDeltaQuery,获取父Entity的pk;
执行deltaImportQuery,获取自身的数据;
如果没有deltaImportQuery,就组装Query
限制:
子Entity的query必须引用父Entity的pk
子Entity的parentDeltaQuery必须引用自己的pk
子Entity的parentDeltaQuery必须返回父Entity的pk
deltaImportQuery引用的必须是自己的pk
文件索引
solr 文档二的更多相关文章
- solr 文档一
[在此处输入文章标题] 参考博客: http://blog.csdn.net/matthewei6/article/details/50620600 基础环境搭建 solr版本5.5.5: 一.sol ...
- Solr记录-solr文档xml
Solr添加文档(XML) 在上一章中,我们学习解释了如何向Solr中添加JSON和.CSV文件格式的数据.在本章中,将演示如何使用XML文档格式在Apache Solr索引中添加数据. 示例数据 假 ...
- 基于Zabbix API文档二次开发与java接口封装
(继续贴一篇之前工作期间写的经验案例) 一. 案例背景 我负责开发过一个平台的监控报警模块,基于zabbix实现,需要对zabbix进行二次开发. Zabbix官方提供了Rest ...
- MongoDB文档(二)--查询
(一)查询文档 查询文档可以使用以下方法 # 以非结构化的方式显示所有的文档 db.<collectionName>.find(document) # 以结构化的方式显示所有文档 db.& ...
- 翻译qmake文档(二) Getting Started
翻译qmake文档 目录 原英文文档: http://qt-project.org/doc/qt-5/qmake-tutorial.html 本教程教讲授qmake基础知识.这个手册里 ...
- 通过VuePress管理项目文档(二)
通过vue组件实现跟:Element相似的效果.需要在VuePress网站中将自己的项目中的Vue组件运行结果展示在页面中. 至于如何将组件在VuePress网站中展示请参考:https://segm ...
- ZooKeeper文档(二)
ZooKeeper:因为协调的分布式系统是一个动物园 ZooKeeper对分布式应用来说是一个高性能的协调服务.它暴露通常的服务-比如命名,配置管理,同步,和组服务-用一种简单的接口,所以你不用从头开 ...
- 【swupdate文档 二】许可证
许可证 SWUpdate是免费软件.它的版权属于Stefano Babic和其他许多贡献代码的人(详情请参阅实际源代码和git提交信息). 您可以根据自由软件基金会发布的GNU通用公共许可证第2版的条 ...
- web开发规范文档二
头部 header\hd 内容块 content\con\bd text txt title 尾部 footer 导航 nav\menu sub-n ...
随机推荐
- 024 01 Android 零基础入门 01 Java基础语法 03 Java运算符 04 关系运算符
024 01 Android 零基础入门 01 Java基础语法 03 Java运算符 04 关系运算符 本文知识点:Java中的关系运算符 关系运算符
- 01 C语言基本介绍
C语言特点 容易上手学习 结构化语言 执行效率高 处理的工作和活动偏底层 可以在多种计算机平台上编译(类似Java的跨平台) C语言历史 目前,C 语言是最广泛使用的系统程序设计语言之一 C 语言是最 ...
- python-格式化(%,format,f-string)输出+输入
1-格式化输出: % 1.print('我的姓名是%s,身高%s cm'%(name,height)) 2.%s -str() ; %d–十进制3.传入值的时候一定是个元组,不是列表4.当指定长度时: ...
- Trie树【字典树】浅谈
最近随洛谷日报看了一下Trie树,来写一篇学习笔记. Trie树:支持字符串前缀查询等(目前我就学了这些qwq) 一般题型就是给定一个模式串,几个文本串,询问能够匹配前缀的文本串数量. 首先,来定义下 ...
- TP5本地运行正常,线上运行某页面出现【模板文件不存在】问题的解决办法
相信许多小伙伴和我一样,明明在本地运行页面一切正常,而到线上(本人是用的虚拟主机)出现了如下图的问题: 其实这个问题出现的原因很简单,就是我们开发是在windows 系统下,windows系统对大小写 ...
- MySQL 复制表(表结构、表结构和数据)
MySQL 中使用 命令行 复制表结构及数据的方法主要有以下几种: 1.只复制表结构 CREATE TABLE new_table SELECT * FROM old_table WHERE 1=2: ...
- 访问 LNMP 报 502 Bad Gateway 错误的解决办法
LNMP : Linux + Nginx + MySQL + PHP Nginx 出现502有很多原因,但大部分原因可以归结为资源数量不够用,也就是说后端 PHP-FPM 处理有问题,Nginx 将正 ...
- 拜托,别再问我怎么自学 Java 了!和盘托出
假如有那么残酷的一天,我不小心喝错了一瓶药,一下子抹掉了我这十多年的编程经验,把我变成了一只小白.我想自学 Java,并且想要找到一份工作,我预计需要 6 个月的时间,前提条件是每天都处于高效率的学习 ...
- 多测师讲解python_oo1基本操作
1.什么是Python? Python是一门面向对象,解释型的动态类型的编程语言,有Guido van Rossunm于1989年发明,第一个公开发行版发行于1991年: Guido van Ross ...
- day20 Pyhton学习 面向对象-成员
一.类的成员 class 类名: # 方法 def __init__(self, 参数1, 参数2....): # 属性变量 self.属性1 = 参数1 self.属性2 = 参数2 .... # ...