Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站

自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 WeDataSphere 的实践情况。

先来说下图数据库应用背景。

WeDataSphere 图数据库架构是基于 JanusGraph 搭建,正如邸帅在演讲《NebulaGraph - WeDataSphere 开源介绍》中提及的那样,主要用于解决微众银行数据治理中的数据血缘问题。在使用 JanusGraph 过程中,微众银行发现 JanusGraph 本身依赖组件较多,数据存储在 HBase 中,索引存储在 Eleasticsearch 中,而因为受分布式高可用和两地三中心架构规范要求,要搭建一套完整的图数据库系统涉及技术点较多,比如高可用问题,再加上三个组件串联,需要解决很多技术问题。而且,本身 JanusGraph 这块数据写入性能也存在问题,当然本身我们对 JanusGraph 的优化也较少,主要集中在参数调整和安全性能提升。
当时用这套系统处理的数据量大概是每天 60 万个点,百万级的边,差不多一天要花 5 个小时左右才能完成写入。这就导致业务方需要使用血缘数据时,大数据平台不能及时提供。

至于微众银行大数据平台为什么选用 Nebula Graph,微众银行早期调研过一些商用、开源的图数据库解决方案,测试部分这里不做赘述,可以参考下 Nebula Graph 社区 美团、腾讯云安全团队和 Boss 直聘 做的性能测评。
这里说下刚才 60 万个点、百万级别边这个场景的情况,在单节点低配机器部署情况下,微众银行导入数据基本上在 20 分钟内完成。Nebula Graph 的写入性能非常好,微众银行大数据平台这块业务对查询的性能要求并不高,Nebula Graph 也能满足大数据平台这块的查询要求。
微众银行的图数据库选择还有一个重量考核点,高可用和容灾的架构支持。这个考核项,Nebula Graph 本身的架构存在一定优势,符合微众银行行内硬性的架构要求和规范。加上大数据平台本身旨在构建一个完整的数据流生态,Nebula Graph 提供了一些大数据相关开源组件,比如:Connector,Exchange,这些工具能很好地同大数据平台进行结合。
最后一点,回归到人的问题——微众银行同开源社区的交流等同于跟其他技术人的交流。和 Nebula Graph 社区交流过程中发,微众银行发现不管是在 PoC 微信群,还是在 Nebula Graph 社区论坛上提问题,官方反馈非常及时。印象较深的一点是,有一天晚上 10 点多,大数据平台在 Nebula Graph 研发人员指导下优化了一个参数,我们在微信群里和 Nebula Graph 反馈,这个参数调整之后解决了生产问题,Nebula Graph 研发同学还给我们发了一个 666 的表情。[手动狗头] 哈哈哈哈挺好。

OK,下面来讲解下 WeDataSphere 架构,主要集中在架构设计中所考虑的点。
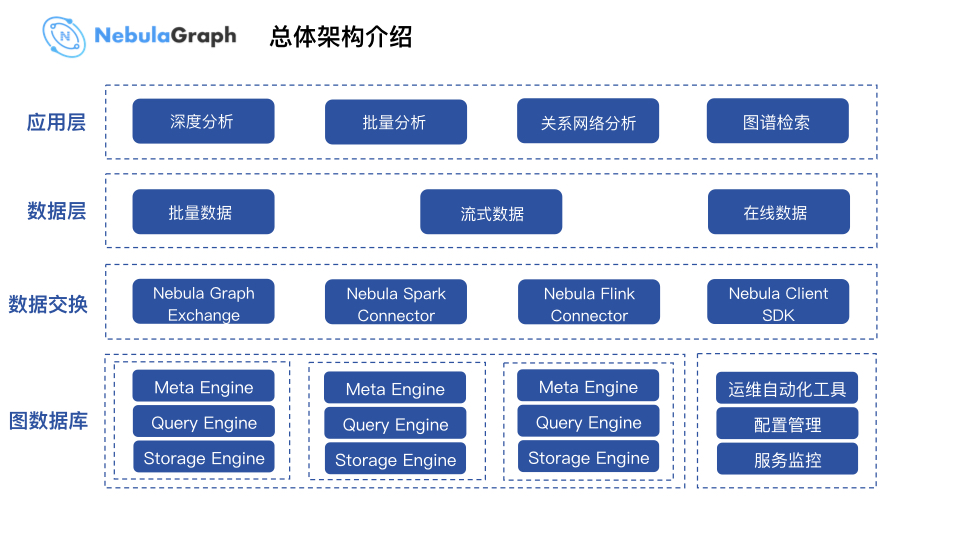
上图和大多数应用的层级划分类似,从上往下看,应用层产生数据,通过数据交换层的各种工具,同底层的图数据库系统交换数据。应用场景方面这里不作详细介绍,在本文后面会详细地讲解金融行业的应用情况。
从行业来看,中间的数据层一般分为三个部分:批量数据、流式数据和在线数据。而数据交换方面,微众银行大数据平台基于 Nebula 提供的开源方案做了接入优化,底层则使用 Nebula Graph 图数据库系统。此外,微众银行大数据平台还有一套运维自动化系统叫 Managis,基于 Managis 构建了自动化部署工具,Nebula 配置也是在类 CMDB 系统中管理。
服务监控模块,微众银行大数据平台内部使用 Zabbix 监控,通过写脚本调用 Metric HTTP 接口,将监控指标传输到 Managis Monitor (Zabbix) 系统中。
总体的架构如上图所示,从上至下的 4 层架构体系。
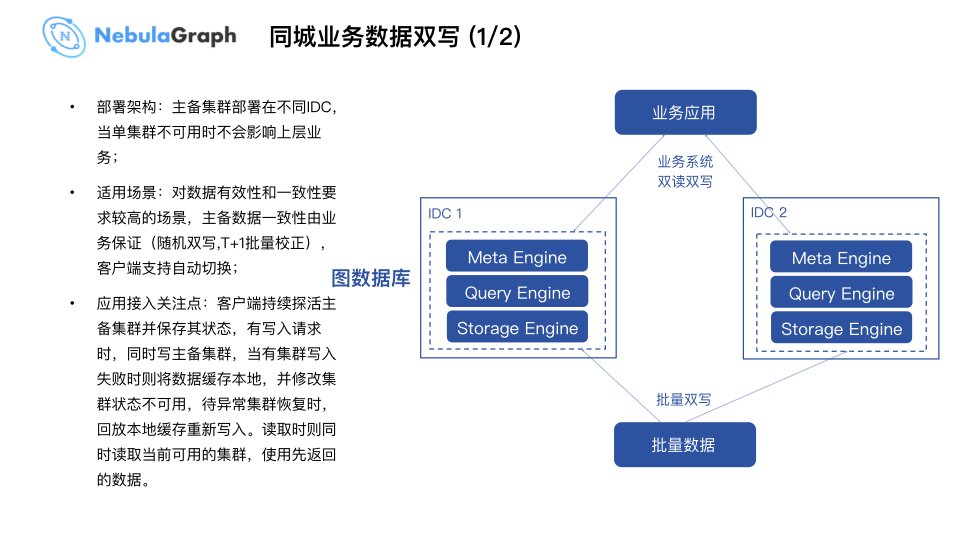
回到用户层面,搭建这套系统在银行架构规范下如何提供给用户使用,保证服务稳定性以及可用率,是大数据平台的首要考虑条件。通过借鉴 WeDataSphere 之前计算存储组件的成功经验,例如 HBase、ES 等组件,如果业务方的系统对稳定性和一致性有所要求,业务接入端需要实现双写功能;针对数据一致性方面,大数据平台做了 T+1 的数据写入校正。当然这种双写方式接入,业务端会存在改造和开发成本。
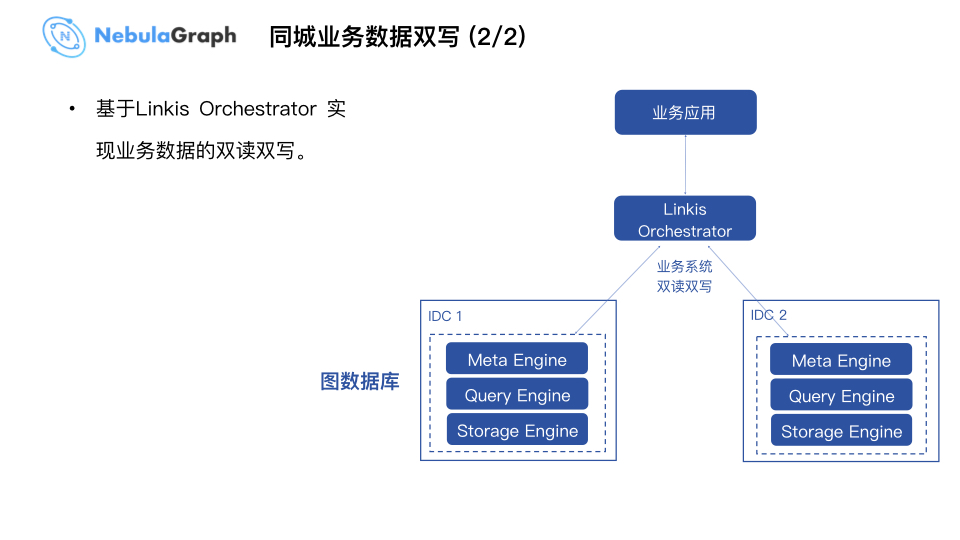
后期,基于大数据平台开源的解决方案 Linkis 提供的 Orchestrator 模块实现编排、回放、高可用。业务端无需了解具体的技术实现细节,通过调用大数据平台的 SDK 接入 Linkis 的 Orchestrator 解决方案实现高可用和数据的双读双写功能。目前这块功能尚在开发中,会在近期开源。
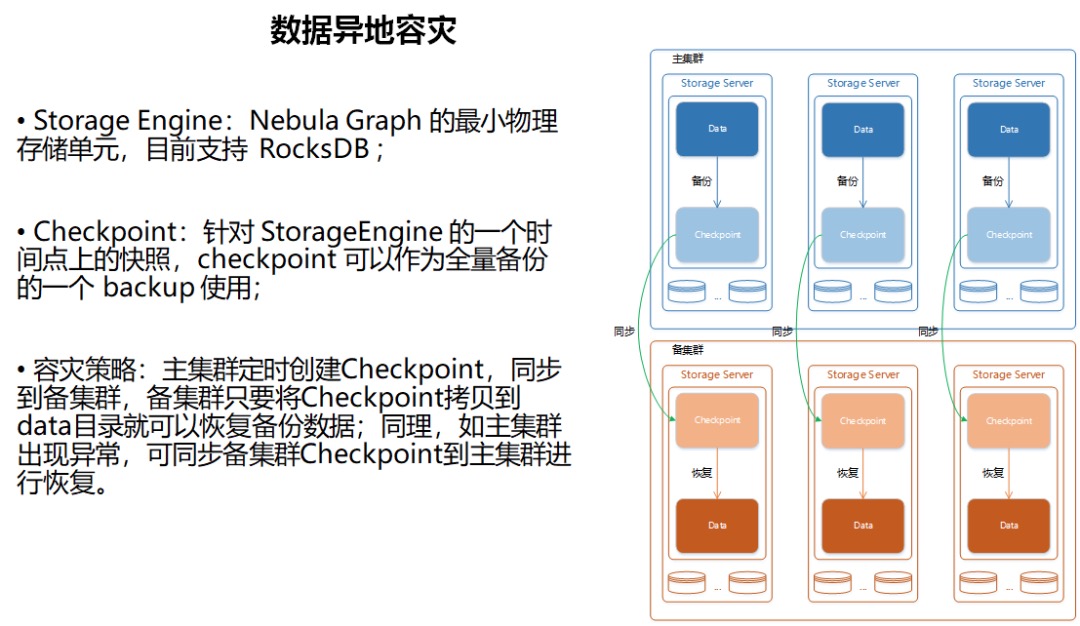
上图为异地容灾过程,主要依赖于 Nebula Graph 本身提供的容灾特性,比如:Checkpoint。目前,大数据平台的具体操作是每天将 Checkpoint 做数据备份同步到上海的容灾集群。一旦主集群出问题,即刻切换系统到上海灾备集群,等主集群恢复后,将数据同步到主集群。

下面来介绍下 Nebula Graph 在大数据平台 WeDataSphere 数据治理系统中的应用。
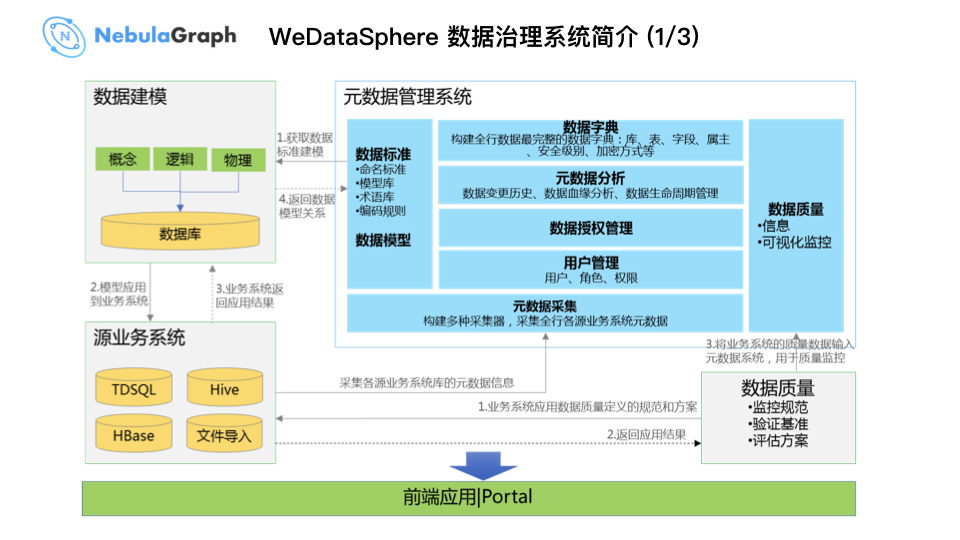
先简单地介绍一下 WeDataSphere 数据治理系统,它包括
数据建模工具
元数据管理系统
数据脱敏系统
数据质量管理系统
元数据管理系统会对接数据建模工具、数据质量管控系统、以及数据脱敏系统,最终提供给用户一套前端的操作界面。

当中比较关键的组件叫数据地图,主要为整个银行的数据资产目录,它采集各个数据源的数据,通过 WeDataSphere 对数据进行加工存储,最后返回一份全行完整的数据资产 / 数据字典。在这个过程中,大数据平台构建了数据治理的规范和要求。
这套数据系统降低了用户使用门槛,直观地告诉用户数据在哪,如果某个用户要审批数据,提交一个数据请求单便可提取他想要的数据,甚至在数据提取之前,系统告知用户数据源是谁,可以找到谁要数据。这也体现了这套数据治理系统中数据血缘的能力:数据源是哪里,下游又是哪里。
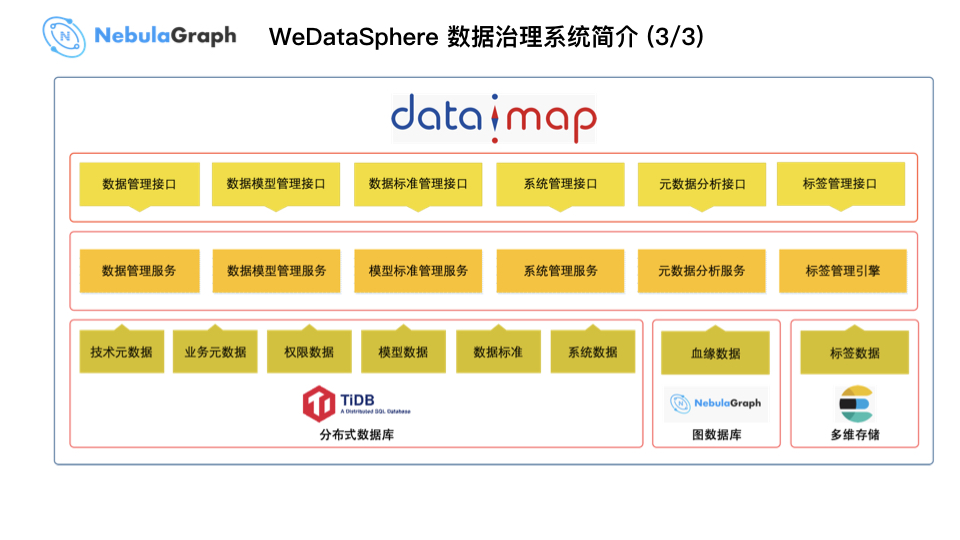
上图为数据治理系统的功能架构,最下层为系统需要采集的数据,以及它对应的数据存储地方。在这个架构中,大数据平台采用 3 个底层存储引擎:主要存储元数据的 TiDB、存储图数据的 Nebula Graph、存储索引数据的 ES。在底层存储的上面,数据地图提供了多个微服务提供给外部使用的请求接口。

下面讲解下 WeDataSphere 数据治理系统中血缘数据的处理过程。我们通过各种组件 Hook 从 Hive、Spark、Sqoop 等任务脚本中解析输入数据和输出数据构建血缘数据。例如:当中的 Hive Hook 主要处理大数据平台内部的表与表之间的关系,我们通过 Hive 本身提供的 Lineage SDK 包装了数据接口,构建一个 Hook 去解析 SQL 语句的输入数据和输出数据,从而建立血缘关系记录在 Log 中。Spark 类似,不过微众银行是自研 Spark 在 Drive 层的 Hook。Sqoop 这块实现是基于 Sqoop 的 Patch 解析数据在 importer 和 exporter job 过程中提供的 Public Data,最终构建关系型数据库(比如:MySQL、Oracle、DB2)和大数据平台 Hive 数据之间的流向关系。血缘数据生成之后写入执行节点,即 Driver 所在节点,从而形成 Lineage Log。
再用微众银行内部的自动化运维工具 AOMP 每日从各个节点导入数据存储到 Hive ODS DB。在这个过程中,大数据平台对 Hive 进行 ETL 加工同现有数据进行关联分析得到导入图数据库的 DM 表。最后使用 Nebula Graph 提供的 Spark Writer 从 Hive 中将点和边的数据写入图数据库对应 Schema 中。
以上便是数据加工过程。
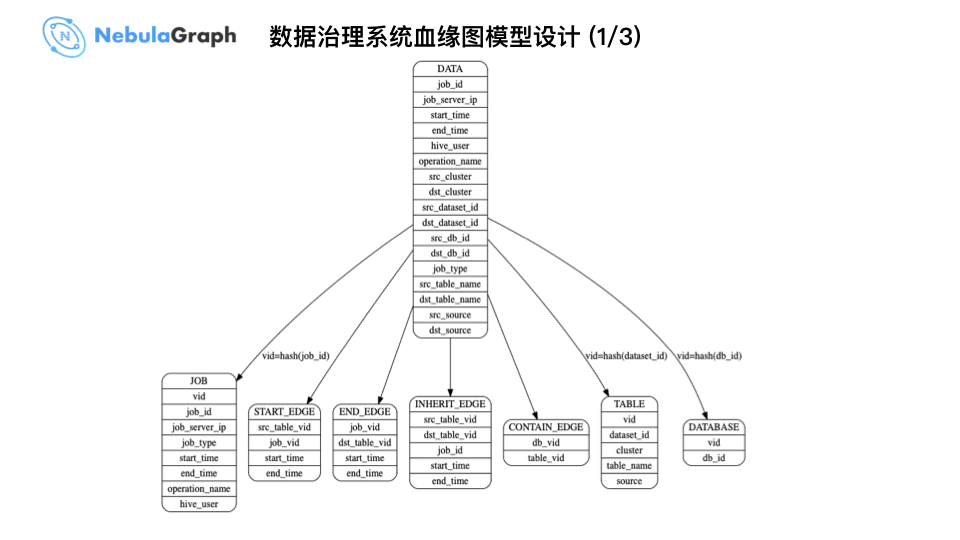
上图为大数据平台的整体数据模型,中间的 DATA 大表为 Hive 加工后的应用表,将上面的点、边信息写入 Nebula Graph Schema 中,包括处理某个 SQL 语句的 job_id,数据源 src_db_id,数据下游 dst_db_id 等等数据信息。
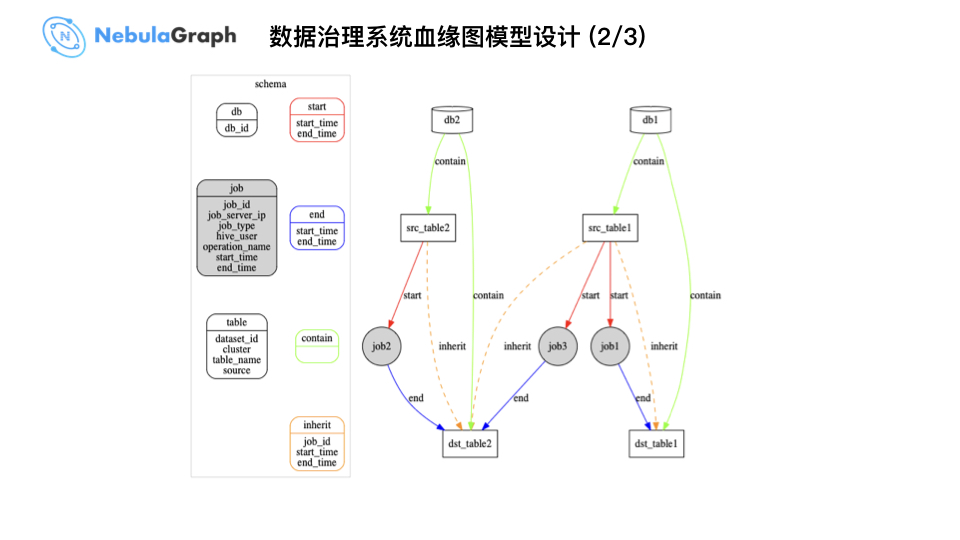
相对而言上图比「数据治理系统血缘图模型设计 1/3」图更直观,Schema 左侧为点,右侧为边,一个 job 对应某个 SQL 语句或 Sqoop 任务。举个例子,一个 SQL 语句会存在多个输入表,最终写入到一个输出表,在图结构中呈现便是 job 入边和 job 出边,对应 source table 和 destination table。表和 DB 本身存在 Contain 关系,而微众银行基于自己的业务增加了表和表的直接 Join 关系,可查询表和表之间关系,比如:一度关系。
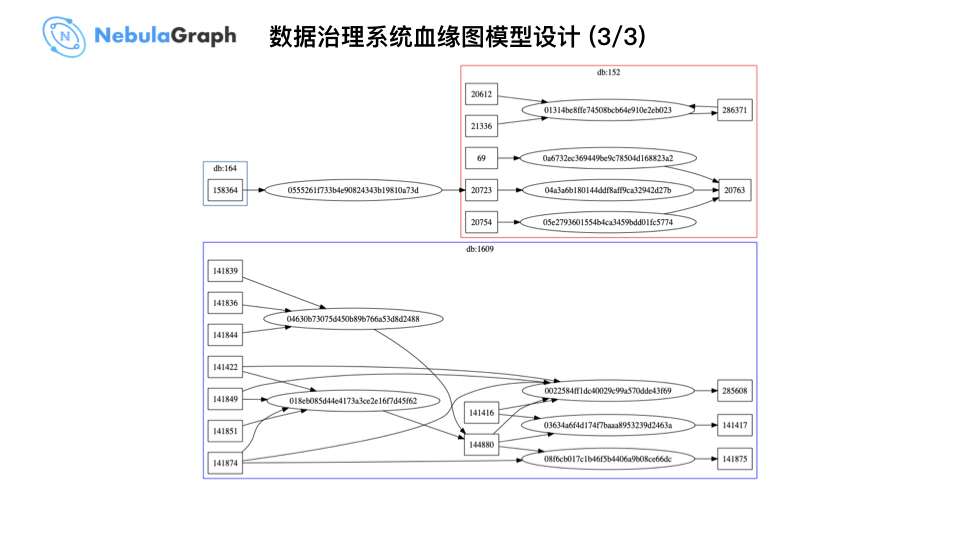
上图是一个数据过程,上面有个 db_id,比如:158364,通过一个 job_id,例如:0555261f733b4e90824343b19810a73d 构建起了一个图结构。
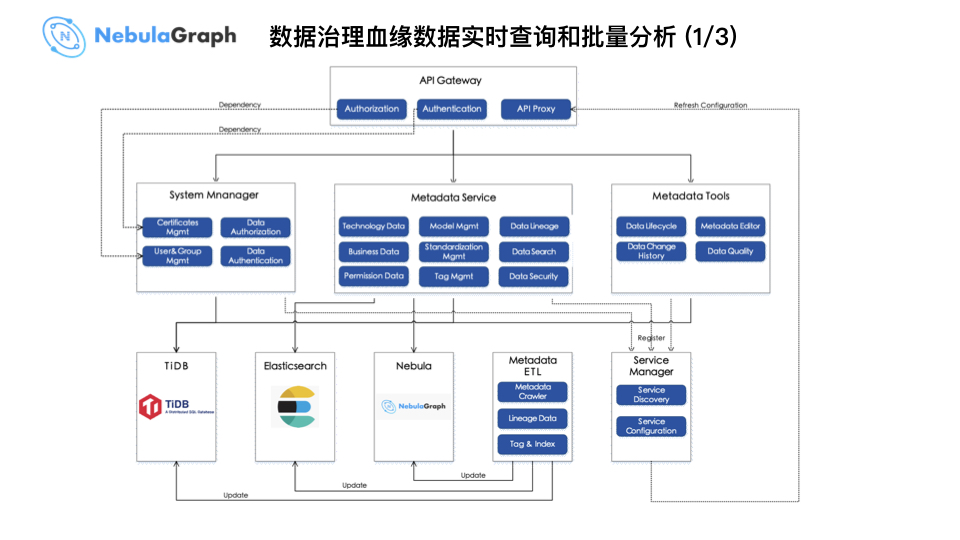
这是数据治理的实时查询和批量分析架构,主要通过 ETL 加工血缘数据再写入到数据存储系统中。而上图中的 Metadata Service 会根据实时分析需求通过 SDK 调用图数据库,将查询的返回结果传给前端做展示。

在应用场景这块,主要有两个场景,一是实时查询,以某个表为起始节点,遍历上游和下游表,遍历完成后在 UI 中展示。具体的技术实现是调用 Nebula Java Client 连接 Nebula Graph 查询得到血缘关系。二是批量查询,当然批量查询所需的血缘数据已构建好并存储在 Nebula Graph 中。针对批量查询,这里举个例子:有一个部门的表,在某个时刻处于出现异常,会影响一批表,要找到这个部门的表,首先我们得找到它到底影响了哪些下游表,把这个完整的链路追踪出来后挨个确认这些表是否修复。那么这时候就需要做批量查询。具体技术实现是通过 Nebula Spark Connector 连接 Nebula Graph 批量将点和边数据导入到 Spark 封装为 DataFrame,再通过 GraphX 等图算法批量分析得到完整的血缘链路。
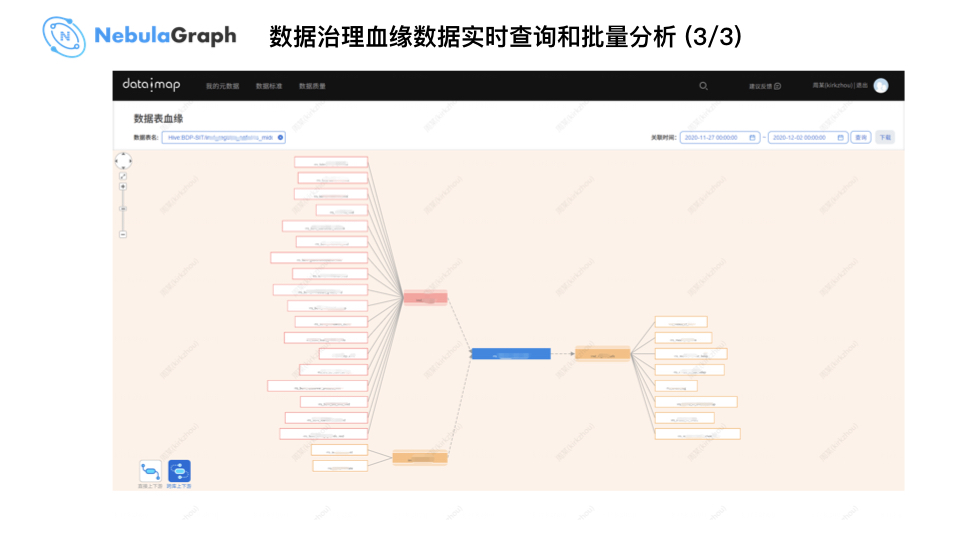
上图为 WeDataSphere 实时查询界面,因为涉及到敏感信息打了个马赛克,以上图的蓝色表为中心数据,查询下游的一度关系表和上游的一度关系表,大数据平台构建图数据库数据模型时加入了时间属性,可以查询特定时间,比如:某张表昨天到今天的血缘关系,可基于时间维度进行数据过滤和检索。
以上,Nebula Graph 在 WeDataSphere 数据治理过程中的应用情况介绍完毕。

在邸帅在演讲《NebulaGraph - WeDataSphere 开源介绍》中,WeDataSphere 提供两层数据连接和扩展能力,前者是一站式数据业务开发管理套件 WeDataSphere,后者是计算中间件 Linkis 用于连接底层的基础组件。而 Nebula Graph 也基于 WeDataSphere 这两层功能同现有数据业务进行结合,打通数据开发流程。
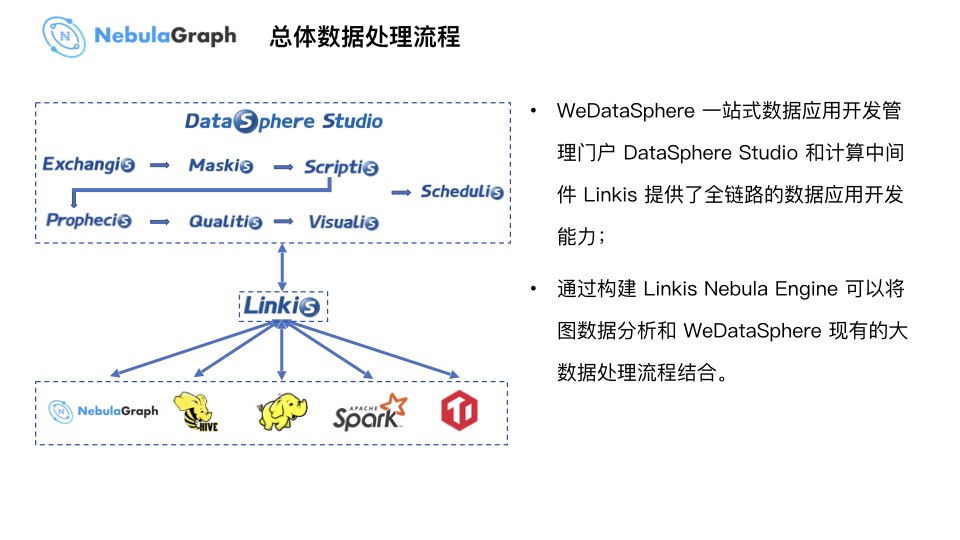
上图为 WeDataSphere 一站式数据应用开发管理门户 Studio 的数据处理流程。上图的 Exchangis 为数据交换系统,读取不同异构数据源的数据导到大数据平台,再通过 Maskis 系统做前置脱敏,遮挡敏感数据或进行 Hash 转换提供给业务分析人员使用。这个系统中有一个 Online 写 SQL 环境 Scriptis,相关研发人员可以写些 SQL 分析语句做前置数据处理,然后数据传输给系统中的机器学习工具 Prophecis 做建模处理。最后,数据处理完成后交付给 Qualitis 系统做数据质量校验,得到安全、可靠数据之后再由可视化系统 Visualis 进行结果展示和分析,最终发送邮件给报表接收方。
上图为用户可感知的一个流程,但整个处理流程会使用到底层技术组件,在 WeDataSphere 内部主要通过 Linkis 这个计算中间件去解决和底层组件连接、串联问题。除此之外,Linkis 还提供了通用的多租户隔离、分流、权限管控的能力。基于 Linkis 这个计算中间件,大数据平台实现了 Linkis Nebula Engine 图分析引擎,和 WeDataSphere 现有的大数据处理流程结合。
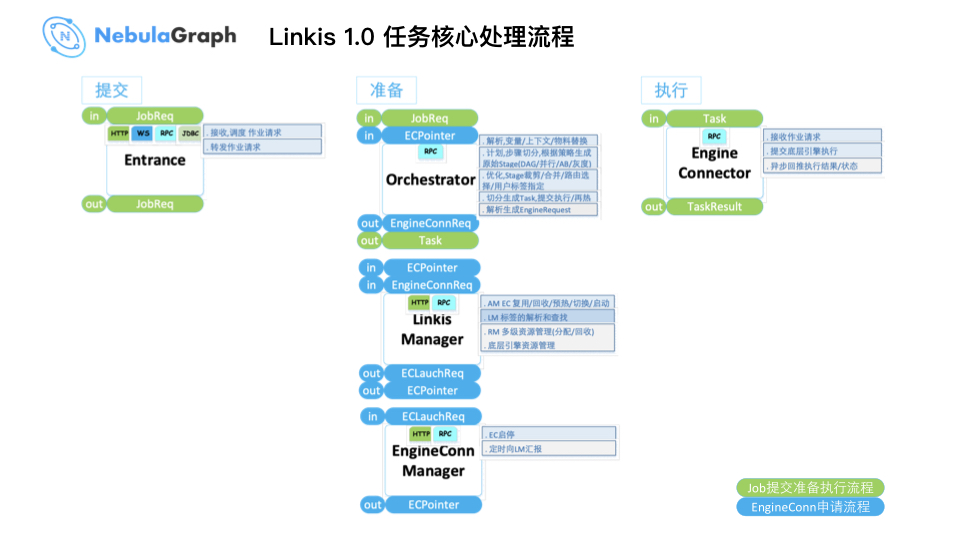
现在来介绍下 Linkis 数据处理流程:
第一阶段:一个任务在 DataSphere Studio 提交后,进入上图所示 Entrance,这个组件主要用于任务解析和参数接收。
第二个阶段:也是一个关键的准备阶段,进入 Orchestrator 模块,在上面 PPT 的「同城业务数据双写」章节说过 Orchestrator 模块实现编排、分流、回放、高可用。编排会将一个 Job 拆分成 N 个细小的 Task,而这些 Task 对应的资源申请需要连接底层 Linkis Manager,Linkis Manager 会把 Task 分发、映射到对应的执行引擎做数据处理,最后,通过 EngineConn Manger 连接到对应执行引擎,可见和 Nebula Graph 进行数据交互的主要是 EngineConn Manger。
第三个阶段:执行。
上面整个过程的实现逻辑是可复用的,做数据应用接入时,只需建立中间件同底层引擎的连接,数据经过 Orchestrator 模块会自动分发到对应的执行引擎做数据处理。
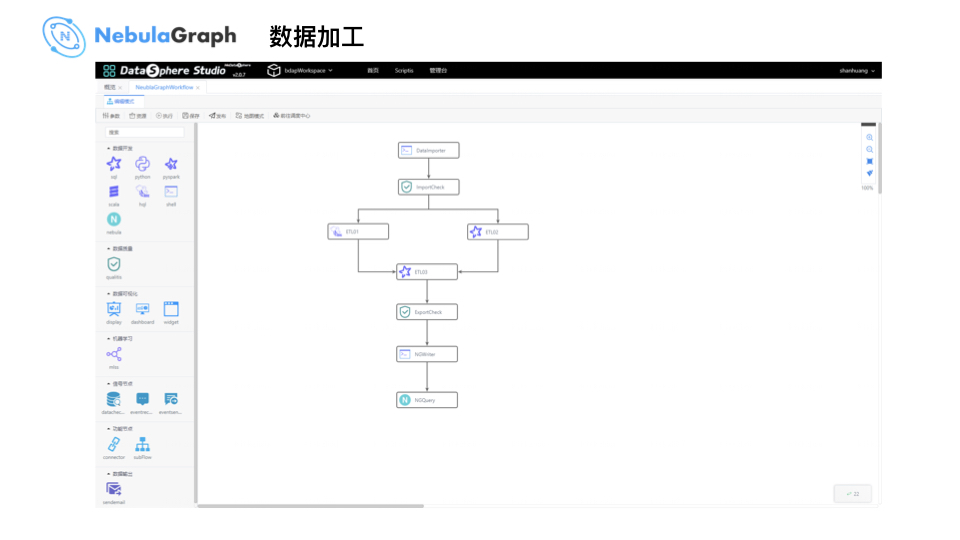
数据加工处理流程如上所示,和 WeDataSphere 一站式数据应用开发管理门户 Studio 的数据处理流程类似:捞数据 -> 大数据平台 -> Qualitis 数据质量校验 -> 写 SQL -> Hive / Spark 做复杂的数据加工处理,最终输出之前进行数据质量校验,通过 Nebula Graph 的 Spark Writer 写到 Nebula。
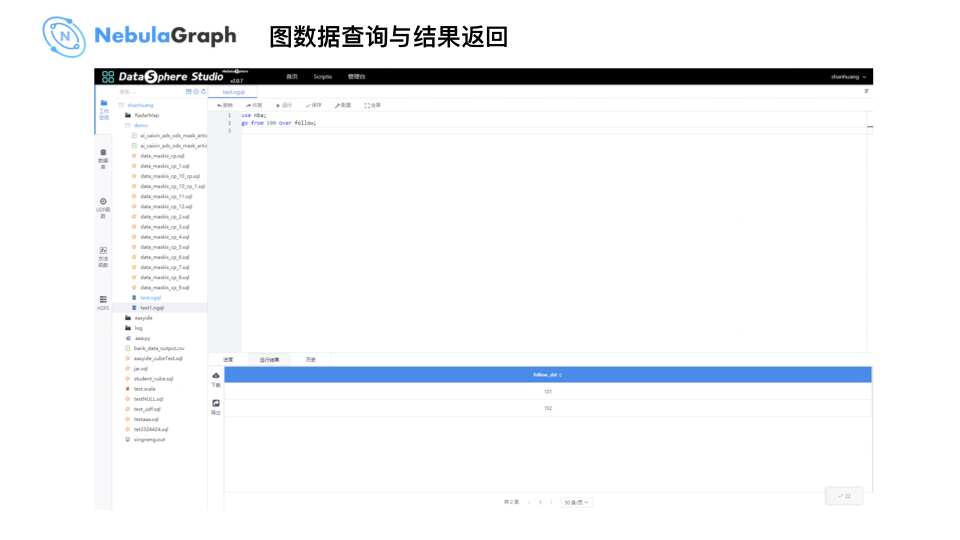
这里,大数据平台提供了一个 nGQL 编程界面,因为这时数据已写入 Nebula Graph,进入 nGQL 界面后执行如下查询语句:
USE nba;
GO FROM 100 OVER follow;
即可在界面返回图数据库 Nebula Graph 的查询结果,同 Nebula Graph 官方提供的可视化工具 Studio 不同,WeDataSphere 的 nGQL 界面主要是处理数据流程的串联问题,不涉及具体的可视化功能,后期微众银行大数据团队也会考虑和官方进行可视化方面的合作。

最后一部分是未来展望,先来讲下 WeDataSphere 这套图数据库系统在微众银行内部的应用,目前我们大数据平台内部主要是应用 Nebula Graph 做血缘数据存储和分析;其他业务部门也有实际应用,例如:资管系统处理企业关系时有用到 Nebula;我们的 AIOPS 系统目前也在做这块业务测试,主要是构建运维知识图谱去实现故障的根因分析和解决方案发现;此外,我们的审计系统也在基于图数据库做知识图谱构建,相关部门目前在尝试接入这套图数据库系统;我们风控场景业务也已接入 WeDataSphere 图数据库系统进行测试,接下来会有更多的业务方来做这一块的尝试。

未来的话,大数据平台这边会基于 Nebula Graph 2.0 开放的功能和架构搭建更加自动化、更加稳定的技术架构,服务好更加关键的业务。
还有同 Nebula Graph 一起拓展图分析这块能力,接入到整个大数据平台 WeDataSphere 这套数据处理流程中。
最后,最重要的,希望有更多合适的业务场景能够接入到 WeDataSphere 这套图数据处理的流程和系统中,以上是微众银行大数据平台——周可的技术分享,谢谢。

喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ ♂️♀️ [手动跪谢]
交流图数据库技术?欢迎报名参加 nMeetup 北京场,和 BOSS 直聘文洲大佬现场谈笑风生,更有美团 NLP 技术大佬和你分享美团的图数据库技术实践,以及知乎反作弊工程师和你聊 Nebula Graph 在知乎的应用。报名地址:nMeetup·北京场 | 图数据库经验之谈
推荐阅读
Nebula Graph 在微众银行数据治理业务的实践的更多相关文章
- “联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新”
“联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新” 从<第五元素>中的智能系统到<超体>中的信息操控,在科幻电影中人工智能已经发展到了极致.而在现实中,目前 ...
- 微众银行Java面试-社招-一面(2019/07)
个人情况 2017年毕业,普通本科,计算机科学与技术专业,毕业后在一个二三线小城市从事Java开发,2年Java开发经验.做过分布式开发,没有高并发的处理经验,平时做To G的项目居多.写下面经是希望 ...
- 微众银行FATE联邦学习框架
参考:https://github.com/webankfintech/fate https://www.fedai.org/#/ 一.Docker Standalone 安装 FATE $ sh b ...
- 微众银行c++选择题后记
一个类的成员可以有:另一个类的对象,类的自身指针,自身类对象的引用(私有的如何初始化呢,所以不行,换成静态的可以),自身类对象(构造时如何初始化呢?) class A{ public: A(){} A ...
- 鹅长微服务发现与治理巨作PolarisMesh实践-上
@ 目录 概述 定义 核心功能 组件和生态 特色亮点 解决哪些问题 官方性能数据 架构原理 资源模型 服务治理 基本原理 服务注册 服务发现 安装 部署架构 集群安装 SpringCloud应用接入 ...
- 图数据库 Nebula Graph 在 Boss 直聘的应用
本文首发于 Nebula Graph 官方博客:https://nebula-graph.com.cn/posts/nebula-graph-risk-control-boss-zhipin/ 摘要: ...
- Nebula Graph 的 Ansible 实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow & 看大厂图数据库技术实践 背景 在 Nebula-Graph 的日常测试中,我们会经常在 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- 一文读懂 Spring Boot、微服务架构和大数据治理三者之间的故事
微服务架构 微服务的诞生并非偶然,它是在互联网高速发展,技术日新月异的变化以及传统架构无法适应快速变化等多重因素的推动下诞生的产物.互联网时代的产品通常有两类特点:需求变化快和用户群体庞大,在这种情况 ...
随机推荐
- 左右声道音频怎么制作,用Vegas就对啦
一款优秀的视频剪辑软件,不仅有高水平的视频制作功能,它的音频编辑功能也是必不可少的.Vegas就是这么一款软件,同时具备视频制作特效制作的同时,还能帮助制作轨道音频效果. 下面,就让小编带大家去学习, ...
- Jmeter(一)发送http请求
Jmeter中发请求的步骤 1.添加线程组 2.添加http消息头管理器 3.添加http请求 一.线程组: 1.添加路径: 2.字段解释 ①线程数(Number of Threads): : 设置发 ...
- redlock分布式锁真的安全吗
此文是对http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html文章的个人归纳,如有问题请联系删除 什么是redlock redlo ...
- Java蓝桥杯——逻辑推理练习题
逻辑推理题 谁是贼? 公安人员审问四名窃贼嫌疑犯.已知,这四人当中仅有一名是窃贼,还知道这四人中每人要么是诚实的,要么总是说谎.在回答公安人员的问题中: 甲说:"乙没有偷,是丁偷的.&quo ...
- Java基础教程——注解
注解 JDK 5开始,Java支持注解. 注解,Annotation,是一种代码里的特殊标记,这些标记可以在编译.类加载.运行时被读取并执行,而且不改变原有的逻辑. 注解可以用于:生成文档.编译检查. ...
- 企业安全05-Fastjson <=1.2.47反序列化RCE漏洞(CNVD-2019-22238)
Fastjson <=1.2.47反序列化RCE漏洞(CNVD-2019-22238) 一.漏洞描述 Fastjson 是阿里巴巴的开源JSON解析库,它可以解析 JSON 格式的字符串,支持将 ...
- .NetCore项目Linux部署总结
Linux部署文档 1.常用指令 find [/根目录 .当前目录] -name [文件名] --查找文件路径ps aux | grep [程序名] --查询查询启动状态ps -ef | grep ...
- chrome浏览器查看当前页面cookie
方法一:点进去设置--高级--网站设置--权限cookie--查找所有cookie和网站数据,就可以看到所有的cookie信息了,举例: 方法二:键盘F12,找到network--点击Doc(如果没有 ...
- Django的静态文件的配置
静态文件配置 STATIC_URL = '/static/' # 静态文件配置 STATICFILES_DIRS = [ os.path.join(BASE_DIR,'static') ] # 暴露给 ...
- 网络拓扑实例09:VRRP组网下同网段内配置基于全局地址池的DHCP服务器
组网图形 DHCP服务器简介 见前面DHCP服务器文章,不再赘述. 组网需求 如图1所示,某企业内的一台主机通过Switch双归属到SwitchA和SwitchB,SwitchA为主设备,作为DHCP ...