第三章 文件 I/O
3.1 引言
先说明可用的文件 I/O 函数:open、read、write、close,然后说明不同缓冲区长度对read和write函数的影响。
本章所说的函数经常被称为不带缓冲的 I/O (unbuffered I/O),与将在第5章中说明的标准 I/O相对照。术语不带缓冲指每个read和write都调用内核中的一个系统调用。
只要涉及在多个进程间共享资源,原子操作的概念就变得非常重要。我们将通过文件 I/O 和 open 函数的参数来讨论此概念。然后本章将进一步讨论在多个进程间如何共享文件,以及所涉及的内核数据结构。在讨论了这些特征后,将说明 dup、fcntl、sync、fsync和 ioctl函数。
3.2 文件描述符
对于内核而言,所有 打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读写一个文件时,使用open或creat返回文件描述符标识该文件,将其作为参数传送给 read 或 write。
按照惯例,UNIX系统shell使用文件描述符0与进程的标准输入相关联,文件描述符1与标准输出关联,文件描述符2与标准出错关联,这是shell以及应用程序的使用惯例,与UNIX内核无关,尽管如此,如果不遵照这种惯例,那么很多UNIX系统应用程序就不能正常工作。
在依从POSIX的应用程序中,幻数0、1、2应当替换成符号常量 STDIN_FILENO、STDOUT_FILENO和STDERR_FILENO。这些常量定义在 <unistd.h>。
文件描述符的变化范围是0~OPEN_MAX。
3.3 open函数
调用open函数可以打开或创建一个文件。
#include <fcntl.h> int open(const char *pathname, int oflag, ... /* mode_t mode */ );
oflag参数可用来说明多个选项,用下列一个或多个常量进行或运算构成oflag参数(这些常量定义在<fcntl.h>):
O_RDONLY 只读打开
O_WRONLY 只写打开
O_RDWR 读写打开
上面三个常量中必须指定一个且只能指定一个,下面常量则是可选择的:
O_APPEND 每次写时都追加到文件尾端。
O_CREAT 若文件不存在,则创建。使用此选项时,需要使用第三个参数mode,用其指定该新文件的访问权限(4.5节将说明文件的访问权限,那时就能了解如何指定mode,以及如何使用进程的umask值修改它)。
O_EXCL 如果同时指定了 O_CREAT,而文件已经存在,则会出错。用此可以测试一个文件是否存在,如果不存在,则创建此文件,这是测试和创建两者成为一个原子操作。3.11节将更详细的说明原子操作。
O_TRUNC 如果此文件存在,而且为只写或读写成功打开,则其长度截短为0。
O_NOCTTY 如果pathname指的是终端设备,则不将该设备分配作为此进程的控制终端。9.6节将说明控制终端。
O_NONBLOCK 如果pathname指的是一个FIFO、一个块特殊文件或一个字符特殊文件、则此选项为文件的本次打开操作和后续的 I/O 操作设置非阻塞模式。14.2节将说明此工作模式。
下面三个标志也是可选的。它们是 Single UNIX Specification(已经POSIX.1)中同步输入和输出选项的一部分。
O_DSYNC 使每次 write 等待物理 I/O 操作完成,但是如果写操作并不影响读取刚写入的数据,则不等待文件属性被更新。
O_RSYNC 使每一个以文件描述符作为参数的read操作等待,直至任何对文件同一部分进行未 决写操作都完成。
O_SYNC 使每次 write 都等待物理 I/O 操作完成,包括由 write 操作引起的文件属性更新所需的 I/O。3.14节将使用此选项。
O_DSYNC 和 O_SYNC 标志有微妙的区别。仅当文件属性需要更新以反映文件数据变化(例如,更新文件大小以反映文件包含了更多数据)时,O_DSYNC 标志才影响文件属性。而设置 O_SYNC 标志后,数据和属性总是同步更新,当文件用 O_DSYNC 标志打开,在重写其现有部分内容时,文件时间属性不会同步更新 。与此相反,如果文件是用 O_SYNC 标志打开,那么对该文件的每一次 write 操作都将在 write 返回前更新文件时间,这与是否改写现有字节或增写文件无关。
(个人理解是 O_DSYNC 和 O_SYNC 都会确保内存中的数据写入到磁盘,但使用 O_DSYNC 会比较文件操作前后的内容,如果内容没有变化,那么不会更新文件时间,而使用 O_SYNC ,只要调用了write,无论是否真正修改文件内容,文件时间属性都会更新)
由 open 返回的文件描述符一定是最小未用文件描述符数值。这一点被某些应用程序用来标志输入、标志输出或标志出错重定向。在 3.12节说明 dup2 函数时,可以了解到有更好的方法来保证在一个给定的描述符上打开一个文件。
文件名和路径名截短
如果NAME_MAX是14,而试图创建一个文件名包含15个字符的新文件,会发生什么呢?
Linux总是返回出错。
3.4 creat函数
也可调用 creat 函数创建一个新文件。
#include <fcntl.h> int creat(const char *pathname, mode_t mode);
注意,此函数等效于:
open(pathname, O_WRONLY | O_CREAT | O_TRUNC, mode);
在早期的UNIX系统中,open第二个参数只能是0、1、2,没法打开一个未存在的文件,因此需要另一个系统调用 creat 创建新文件。现在,open 函数提供了 O_CREAT 和 O_TRUNC 于是也就不需要 creat 函数。
creat的一个不足之处是它以只写方式打开所创建文件,在提供open的新版本之前,如果要创建一个临时文件,并要先写该文件,然后又读该文件,则必须要先调用 creat、close,然后再调用 open。现在则可用下列方式调用 open:
open(pathname, O_RDWR | O_CREAT | O_TRUNC, mode);
3.5 close函数
关闭一个打开的文件:
#include <unistd.h> int close(int filedes);
关闭一个文件时还会释放该进程在该文件上的所有记录锁。14.3节将讨论这一点。
当一个进程终止时,内核自动关闭它所有打开的文件。很多程序都利用了这一功能而不显示地用close关闭打开文件。
3.6 lseek函数
每个打开地文件都有一个与其相关联地“当前文件偏移量(current file offset)”。
它通常是一个非负整数,用以度量从文件开始处计算字节数(本节稍后将对“非负”这一修饰词地某些例外进行说明)。
通常,读、写操作都从当前文件偏移量 处开始,并使偏移量增加所读写地字节数。按照系统默认地情况,打开一个文件时,除非指定 O_APPEND 选项,否则偏移量被设置为0。
可以调用lseek显式地为一个打开文件设置其偏移量。
#include <unistd.h> off_t lseek(int fileds, off_t offset, int whence);
对于参数 offset 的解释与参数 whence 的值有关。
若 lseek成功执行,则返回新的文件偏移量,为此可用下列方式确定打开文件的当前偏移量:
off_t currpos; currops = lseek(fd, , SEEK_CUR);
这种方法也可用来确定所涉及文件是否可以设置偏移量。如果文件描述符引用的是一个管道、FIFO或网络套接字,则lseek返回-1,并将errno设置为 ESPIPE。
// 测试能否对标志输入设置偏移量
#include "apue.h"
int main(void)
{
, SEEK_CUR) == -)
printf("cannot seek\n");
else
printf("seek OK\n");
exit();
}
通常,文件的当前偏移量应当是一个非负整数,但是某些设备也可能允许负的偏移量。但对于普通文件,则其偏移量必须是非负值。因为偏移量可能是负值,所以在比较lseek的返回值时应当谨慎,不要测试它是否小于0,而要测试它是否等于-1。
lseek仅将当前文件偏移量记录在内核中,它并不引起任何 I/O 操作。然后,该偏移量用于下一个读或写操作。
文件偏移量可以大于文件的当前长度,在这种情况下,对该文件的下一次写将加长该文件,并在文件中构成一个空洞,这一点是允许的。位于文件中但没有写过的字节都会被读为0。
文件中的空洞并不要求在磁盘上占用存储区。具体处理方式与文件系统的实现有关,当定位到超出文件尾端之后写时,对于新写的数据需要分配磁盘块,但是对于原文件尾端和新开始写位置之间的部分则不需要分配磁盘块。
// 创建一个具有空洞的文件
#include "apue.h"
#include <fcntl.h>
char buf1[] = "aaaaaaaaaa";
char buf2[] = "bbbbbbbbbb";
int main(void)
{
int fd;
)
err_sys("creat error");
) != )
err_sys("buf1 write error");
/* offset now = 10 */
, SEEK_SET) == -)
err_sys("lseek error");
/* offset now = 16384 */
) != )
err_sys("buf2 write error");
/* offset now = 16394 */
exit();
}
使用 od(1)命令观察该文件实际内容。命令行中 -c 标志标识以字符方式打印文件内容。从中可以看出,设置为空洞的部分,即未被使用的字节,被以0的方式读出。

观察相同字节长度的空洞文件和非空洞文件的磁盘块大小:

虽然两个文件长度相同,但无空洞的文件占用了20个磁盘块,而具有空洞的文件只占用了8个磁盘块。4.12节将对具有空洞的文件进行更多说明。
lseek使用偏移量使用 off_t 类型表示,所以允许具体实现根据各自特定的平台自行选择大小合适的数据类型。
3.7 read函数
#include <unistd.h> ssize_t read(int filedes, void *buf, size_t nbytes);
如read成功,则返回读到的字节数。如已到文件结尾,则返回0。
有多种情况可使实际读到的字节数少于要求读的字节数:
(1)读普通文件时,在读到要求字节数之前已到达了文件尾端。例如,若在到达文件尾端之前还有30个字节,而要求读100个字节,则read返回30,下一次再调用read时,它将返回0(文件尾端)。
(2)当从终端设备读时,通常一次最多读一行(第18章将介绍如何改变这一点)。
(3)从网络读时,网络中的缓冲机构可能造成返回值小于所要求读的字节数。
(4)当从管道或FIFO读时,如若管道包含的字节少于所需的数量,那么read将只返回实际可用的字节数。
(5)当从某些面向记录的设备(如磁带)读时,一次最多返回一个记录。
(6)当某一信号造成中断,而已经读了部分数据量时。我们将在10.5节进一步讨论此种情况。
读操作从文件当前偏移量处开始,再成功返回之前,该偏移量将增加实际读到的字节数。
3.8 write函数
ssize_t write(int filedes, const void *buf, size_t nbytes);
其返回值通常与参数 nbytes 的值相同,否则表示出错。write出错的一个常见原因是:磁盘已写满,或者超过了一个给定进程的文件长度限制。
对于普通文件,写操作从文件的当前偏移量处开始。如果在打开该文件时,指定了 O_APPEND 选项,则在每次写操作之前,将文件偏移量设置在文件当前结尾处。在一次成功写之后,该文件偏移量增加实际写的字节数。
3.9 I/O 的效率
#include "apue.h"
#define BUFFSIZE 4096
int main(void)
{
int n;
char buf[BUFFSIZE];
)
if (write(STDOUT_FILENO, buf, n) != n)
sys_err("write error");
)
err_sys("read error");
exit();
}
测试选取 BUFFSIZE 值对效率的影响
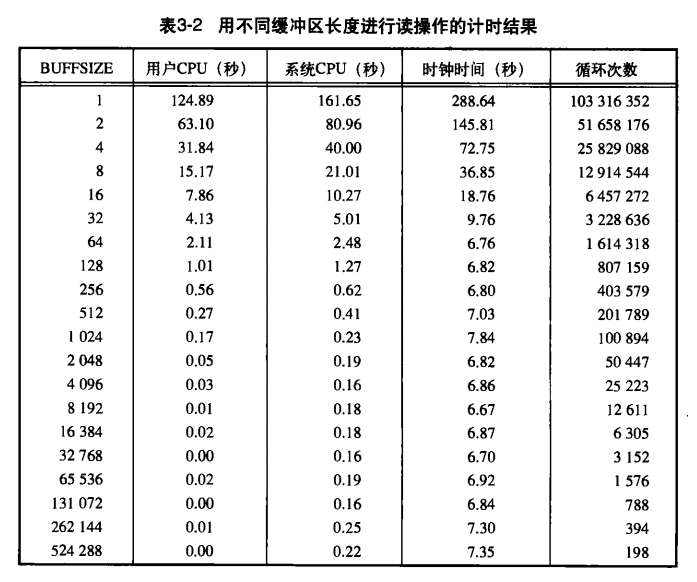
可见在测试环境的文件系统下,buffer大小为4096是最佳的。
最后几个记录项,可以观察到影响,是由于当 BUFFERSIZE为128KB之后,预读技术停止了。预读技术是系统检测到在进行顺序读取时,就试图读入比应用程序所要求更多的数据,并假想应用程序很快会读这些数据。
3.10 文件共享
UNIX系统支持在不同进程间共享打开的文件。在介绍dup函数之前,先要说明这种共享。为此先介绍内核用于所有 I/O 的数据结构。
下面的说明时概念性的,与特定实现可能不匹配,也可能匹配。
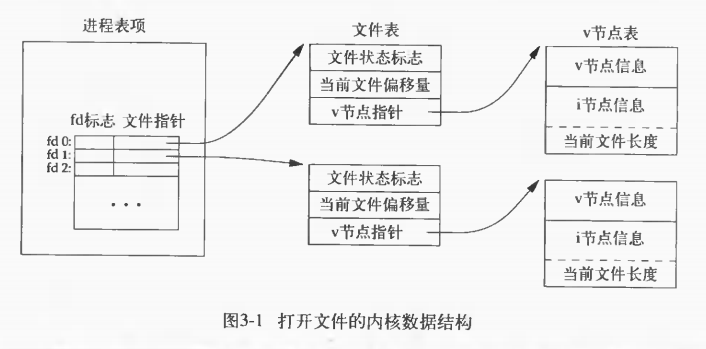
内核使用三种数据结构表示打开的文件,它们之间的关系决定了在文件共享方面一个进程对另一个进程可能产生的影响。
(1)每个进程在进程表中都有一个记录项,记录项中包含有一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
(a)文件描述符标志(close_on_exec)
(b)指向一个文件表项的指针。
(2)内核为所有打开文件维持一张文件表。每个文件表项包含:
(a)文件状态标志(读、写、添加、同步和阻塞等,关于这些标志的更多信息参见3.14节)。
(b)当前文件偏移量。
(c)指向该文件v节点表现的指针。
(3)每个打开文件(或设备)都有一个v节点(v-node)结构。v节点包含了文件类型和对此文件进行各种操作的函数指针。对于大多数文件,v节点还包含了该文件的 i 节点(i-node,索引节点)。这些信息是在打开文件时从磁盘上读入内存的。所以所有关于文件的信息都是快速可供使用的。例如,i 节点包含了文件的所有者、文件长度、文件所在的设备、指向文件实际数据块在磁盘上所在位置的指针等等(4.14节较详细地说明了典型UNIX系统文件系统,并将更多地介绍 i 节点)。
Linux没有使用 v 节点,而是使用了通用 i 节点结构。虽然两种实现有所不同,但在概念上,v 节点与 i 节点是一样地。两者都指向文件系统特有的 i 节点结构。
Linux没有将相关数据结构分为 i 节点和 v 节点,而是采用了一个独立于文件系统的 i 节点和一个依赖于文件系统的 i 节点。
我们忽略了某些实现细节,但这并不影响我们的讨论。例如,打开文件描述符表可存放在用户空间,而非进程表中。这些表也可以用多用方式实现,数组、链表。
下图显示了一个进程的三张表之间的关系。该进程有两个不同的打开文件:一个文件打开为标志输入(文件描述符0),另一个打开的标志输出(文件描述符为 1 )。
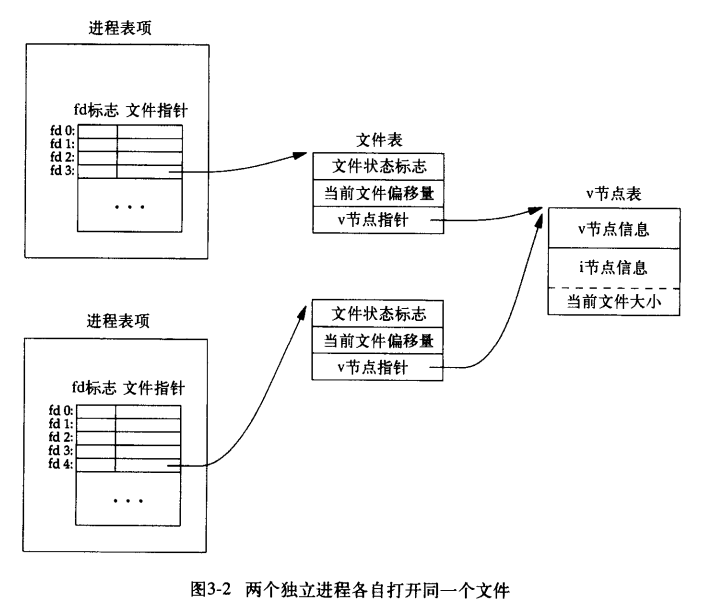
如果两个独立进程各种打开了同一个文件,如下图,我们假定第一个进程在文件描述符3上打开该文件,而另一个进程则在文件描述符4上打开该文件。打开该文件的每个进程都得到一个文件表项,但对一个给定的文件只有一个 v 节点表项。每个进程都有自己的文件表项的一个理由是:这种安排使每个进程都有它自己的对该文件的当前偏移量。
给出这些数据结构后,现在对前面所述的操作进一步说明。
(1)在完成每个 write 后,在文件表项中的当前文件偏移量即增加所写的字节数。如果这使当前文件偏移量超过了当前文件长度,则在 i 节点表项中的当前长度被设置为当前文件偏移量(也就是该文件加长了)。
(2)如果用 O_APPEND 标志打开一个文件,则相应标志也被设置到文件项的文件状态标志中。每次对这种具有添写标志的文件执行写操作时,在文件表项中的当前文件偏移量首先被设置为 i 节点表项中的文件长度。这就使得每次写的数据都添加到文件的当前尾端处。
(3)若一个文件用 lseek 定位到文件当前的尾端,则文件表项中的当前文件偏移量被设置为 i 节点表项中的当前文件长度(注意,这与用O_APPEND标志打开的文件是不同的)。
(4)lseek 函数只修改文件表项中的当前文件偏移量,没有进行任何 I/O操作。
可能有多个文件描述符项指向同一个文件表项。在3.12节中讨论dup函数时,能看到这一点。这fork后也会发生同样的情况,此时父、子进程对于每一个打开文件描述符共享同一个文件表项。(见8.3节)
注意,文件描述符标志和文件状态标志在作用域方面的区别,前者只用于一个进程的一个描述符,而后者则适用于该给定文件表项的任何进程中的所有描述符。
本节上面所述的一切对于多个进程读同一文件都能正确工作。每个进程都有自己的文件表项,其中也有它自己的当前文件偏移量。但是,当多个进程写同一个文件时,则可能阐述预想不到的结果。为了说明如何避免这种情况,需要理解原子操作的概念。
3.11 原子操作
(1)添写至一个文件
考虑一个进程,它要将数据添加到一个文件尾端。早期UNIX系统不支持Open的O_APPEND选项,所以程序被编写成下列形式:
) < )
err_sys("lseek error");
) != )
err_sys("write error");
对于单个进程,这段程序能正常工作,但是若有多个进程,则会有问题。
问题出在逻辑操作“定位到文件尾端,然后写”,它使用了两个分开的函数调用,解决方法是使这两个操作对其他进程而言成为一个原子操作。UNIX系统提供了一种方法使这种操作成为原子操作,该方法就是在打开文件时设置 O_APPEND标志。
(2)pread和pwrite函数
原子性的定位搜索(seek)和进行 I/O。
ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset); ssize_t pwrite(int filedes, void *buf, size_t nbytes, off_t offset);
调用pread 相当于顺序调用 lseek 和read,但是 pread 又与这种顺序调用有下列重要区别:
(a)调用 pread 时,无法中断其定位和读操作。
(b)不更新文件指针。
调用pwrite 相当于顺序调用 lseek 和write,但也与他们有类似的区别。
(3)创建一个文件
) {
if (errno == ENOENT) {
)
err_sys("creat error");
} else {
err_sys("open error");
}
}
这段代码也有问题。应该使用 O_CREAT 和 O_EXCL 完成原子操作。
如果一组操作是原子的,那么要么执行完整个操作,要么不执行。
3.12 dup和dup2函数
下面两个函数都可用来复制一个现存的文件描述符:
#include <unistd.h> int dup(int filedes); int dup2(int filedes, int filedes2);
由dup返回的新文件描述符一定是当前可用文件描述符中最小数值。用dup2则可用filedes2参数指定新描述符的数值。如果filedes2已经打开,则先将其关闭,如若filedes等于filedes2,则dup2返回filedes2,而不关闭它。
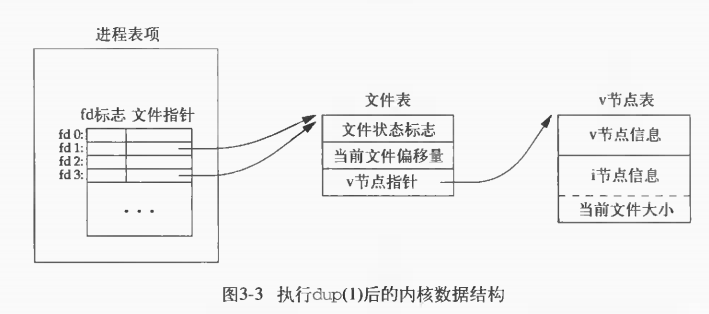
这些函数返回的新文件描述符与参数filedes共享一个文件表项,如下图
newfd = dup(1);
复制一个描述符的另一种方法是使用 fcntl 函数,3.14节将对该函数进行说明。实际上,
调用
dup(filedes);
等效于
fcntl(filedes, F_DUPFD, 0);
而调用
dup2(filedes, filedes2);
等效于
close(filedes2);
fcntl(filedes, F_DUPFD, filedes2);
后一种情况下,dup2并不完全等同于 close 加上 fcntl。它们之间的区别是:
(a)dup2是一个原子操作,而close及fcntl则包括两个函数调用。有可能在close和fcntl之间插入执行吸纳后捕获函数,他可能修改文件描述符
(b)dup2和fcntl有某些不同的errno
3.13 sync、fsync和fdatasync函数
传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘 I/O都是通过缓存进行。当数据写入文件时,内核通常先将数据复制到一个缓冲区中,如果该缓冲区尚未写满,则并不会将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲排入输出队列,然后待其到达队首时,才进行实际的 I/O 操作。这种输出方式被称为延迟写(delayed write).
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新 速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能会造成更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性。UNIX系统提供了 sync、fsyn和fdatasync。
#include <unistd.h> int fsync(int filedes); int fdatasync(int filedes); void sync(void);
sync函数只是将所有修改过的块缓冲区排入写入队列,然后就返回,它并不等的实际写磁盘操作结束。
通常称为update的系统守护进程会周期性地(一般间隔30秒)调用sync函数。这就保证了定期冲洗内核的块缓存区。命令sync(1)也调用sync函数。
fsync函数只对由文件描述符 fildes指定的单一文件起作用,并且等待磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,而这种应用程序需要确保将修改过的块立即写到磁盘上。
fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
3.14 fcntl函数
用于改变已打开文件的性质
#include <unistd.h> int fcntl(int filedes, int cmd, ... /* int arg */);
在本节的各个实例中,第三个参数总是一个整数,与上面所示函数原型中的注释部分相对应。但是14.3节说明记录锁时,第三个参数则是指向一个结构的指针。
fcntl函数有5种功能:
(1)复制一个现有描述符(cmd = F_DUPFD)
(2)获得/设置文件描述符标记(cmd = F_GETFD 或 F_SETFD)
(3)获得/设置文件状态标记(cmd = F_GETFL 或 F_SETFL)
(4)获得/设置异步 I/O所有权(cmd = F_GETOWN 或 F_SETOWN)
(5)获得/设置记录锁 (cmd = F_GETLK、F_SETLK 或 F_SETLKW)
fcntl的返回值与命令有关。如果出错,所有命令都返回-1,如果成功则返回某个其他值。下列四个命令有特定返回值:F_DUPFD、F_GETFD、F_GETFL和F_GETOWN。第一个返回新的文件描述符,接下来的两个返回相应标志,最后一个返回一个正的进程ID或负的进程组ID。
#include "apue.h"
#include <fcntl.h>
int main(int argc, char **argv)
{
int val;
!= argc)
err_quit("usage: a.out <descriptor#>");
]), F_GETFL, )) < )
err_sys(]));
switch (val & O_ACCMODE) {
case O_RDONLY:
printf("read only");
break;
case O_WRONLY:
printf("write only");
break;
case O_RDWR:
printf("read write");
break;
default:
err_dump("unknown access mode");
}
if (val & O_APPEND)
printf(", append");
if (val & O_NONBLOCK)
printf(", nonblocking");
if (val & O_SYNC)
printf(", synchronous writes");
putchar('\n');
exit();
}
在修改文件描述符标志 或文件状态标志时必须谨慎,先要取得现有的标志值,然后根据需要修改它,最后设置新标志值。不能只是执行F_SETFD或F_SETFL命令,这样会关闭以前设置的标志位。
void set_fl(int fd, int flags)
{
int val;
)) < )
err_sys("fcntl F_GETFL error");
val |= flags; /* turn on flags */
)
err_sys("fcntl F_SETFL error");
}
如果将中间一条语句改为:
val &= ~falgs; /* turn off flags */
就构成另一个函数,我们称其为clr_fl。
如果:
set_fl(STDOUT_FILENO, O_SYNC)
这就使每次write都要等待,直至数据已写到磁盘上再返回。在UNIX系统中,通常write只是将数据排入队列,而实际的写磁盘操作则可能在以后某个时刻进行。
程序运行时,设置 O_SYNC 标志会增加时钟时间。
3.15 ioctl函数
ioctl函数时 I/O 操作的杂物箱。不能用本章中其他函数表示的 I/O 操作通常都能用 ioctl 表示。终端 I/O 是 ioctl 的最大使用方面。
#include <sys/ioctl.h> int ioctl(int filedes, int reques, ...);
3.16 /dev/fd
较新的系统都提供名为 /dev/fd 的目录,其目录项是名为 0,1,2等的文件。打开文件 /dev/fd/n等效于复制描述符 n
在下列函数调用中
fd = open("/dev/fd/0", mode);
等效于
fd = dup();
描述符0和fd共享同一文件表项。
例如,若描述符0先前被打开为只读,那么我们也只能对fd进行读操作。即使系统忽略打开模式,并且下列调用成功:
fd = open("/dev/fd/0", O_RDWR);
我们仍然不能对fd进行写操作。
/dev/fd 文件主要由 shell 使用,它允许使用路径名作为调用参数的程序,能用处理其他路径名相同方式处理标准输入和输出。
如:
filter file2 | cat file1 - file3 | lpr filter file2 | cat file1 /dev/fd/ file3 | lpr
3.17 小结
本章说明了 UNIX 系统提供的基本 I/O 函数。 read 和write都在内核执行,所以称这些函数为不带缓冲的 I/O 函数。在只使用 read 和 write 情况下,观察了不同 I/O 长度对读文件所需时间的影响。也观察了许多将写入的数据冲洗到磁盘的方法,说明了它们对应用程序性能的影响。
在说明多个进程对同一个文件进行添写操作以及多个进程创建同一文件时,本章介绍了原子操作。也介绍了内核用来共享打开文件信息的数据结构。
我们还介绍了 ioctl和 fcntl 函数。
第三章 文件 I/O的更多相关文章
- apue学习笔记(第三章 文件I/O)
本章开始讨论UNIX系统,先说明可用的文件I/O函数---打开文件.读写文件等 UNIX系统中的大多数文件I/O只需用到5个函数:open.read.write.lseek以及close open函数 ...
- 2 python第三章文件操作
1.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成立 els ...
- 《UNIX环境高级编程》(APUE) 笔记第三章 - 文件I/O
3 - 文件I/O Github 地址 1. 文件描述符 对于内核而言,所有打开的文件都通过 文件描述符 (file descriptor) 引用.当打开一个现有文件或创建一个新文件时,内核向进程返回 ...
- 第三章 文件IO复习
open(const char * path, int flag.../*mode_t*/) #include <fcntl.h> path:绝对路径 flag:O_RDONL ...
- 第三章:文件I/O
本章开始讨论UNIX系统的文件I/O函数,包括打开文件.读文件.写文件等. UNIX系统中的大多数文件I/O只需要用到5个函数:open.read.write.lseek和close.它们每执行一次都 ...
- Windows Pe 第三章 PE头文件(上)
第三章 PE头文件 本章是全书重点,所以要好好理解,概念比较多,但是非常重要. PE头文件记录了PE文件中所有的数据的组织方式,它类似于一本书的目录,通过目录我们可以快速定位到某个具体的章节:通过P ...
- 《Django By Example》第三章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第三章滚烫出炉,大家请不要吐槽文中 ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- 精通Web Analytics 2.0 (5) 第三章:点击流分析的奇妙世界:指标
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第三章:点击流分析的奇妙世界:指标 新的Web Analytics 2.0心态:搞定它.新的闪亮系列工具:是的.准备好了吗?当然 ...
随机推荐
- 用IDEA创建一个SpringBoot项目
next后等待项目构建完成 运行方法一: 方法二:
- Mysql慢查询 [第一篇]
一.简介 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能. 二.参数说明 slow_query_log 慢查询开启状态slow_q ...
- 【起航计划 009】2015 起航计划 Android APIDemo的魔鬼步伐 08 App->Activity->QuickContactsDemo 联系人 ResourceCursorAdapter使用 QuickContactBadge使用
QuickContactsDemo示例介绍了如何使用Content Provider来访问Android系统的Contacts 数据库. Content Provider为不同应用之间共享数据提供了统 ...
- [SVN]TortoiseSVN工具培训3─使用基本流程和图标说明
1.SVN的使用基本流程 注意:对于文件编辑方面,上图的编辑副本操作前建议进行Get lock操作,以防出现后续的冲突等异常报错. 2.SVN的基本图标说明
- VtigerCRM-6.4.0-zh_CN (OpenLogic CentOS 7.2)
平台: CentOS 类型: 虚拟机镜像 软件包: vtigercrm6.4.0 commercial crm mysql open source php vtiger 简体中文版 服务优惠价: 按服 ...
- ubuntu & sublime字体设置
ubuntu # yahei http://pan.baidu.com/share/link?shareid=972621198&uk=1243888096&fid=333591974 ...
- 理解python yield
python源代码中经常会有使用yield,带有yield的函数是generator(生成器),它返回是一个迭代值,下面我们分析yield是什么原理,有什么好处? 首先,我们写一个简单的斐波那契数列前 ...
- ES7的Async/Await的简单理解
Async/Await 的个人见解 正文: async,顾名思义,一个异步执行的功能,而 await 则是配合 async 使用的另一个关键字,也是闻字识其意,就是叫你等待啦! 二者配合食用效果更佳哦 ...
- Typora使用
Typora使用 1.介绍 typora是一款不错的软件. 1.1 基本使用 html js css python java vb 1.2 无序列表 a b c d e f 1.3 java代码 pu ...
- percona-toolkit 工具集安装
下载地址: www.percona.com/downloads/percona-toolkit 安装方法一,源码安装: perl Makefile.PL make:make install ...