Flume是什么

分布式流式实时收集日志文件系统,便于实时在线的流式计算,常配合 Storm 和 spark streming 使用。
Flume is a distributed分布式的, reliable可靠的, and available可用的 service for efficiently高效 collecting收集, aggregating聚合, and moving移动 large amounts of log data.
It has a simple简单 and flexible灵活 architecture结构 based on streaming流式 data flows. It is robust健壮 and fault tolerant容错 with tunable可调 reliability mechanisms机制 and many failover and recovery mechanisms. It uses a simple extensible可拓展 data model that allows for online analytic application.
架构图如下
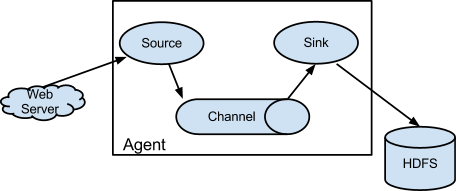

| 角色 | 作用 |
|---|---|
| Agent | Flume的客户端 |
| Event | Flume 数据传输的基本单元,由 [Header] 和 数据的 byte Array 构成,载有数据对Flume不透明;Header 是容纳了KEY_VALUE对的无序集合(Key是唯一的);Header 可以在上下文路由中使用拓展 |
| Source | 用于收集数据,产生数据源的地方,并主动推送数据到 Channel 中 |
| Channel | 数据管道,用于连接 sources 和 sinks ,可以连接多个Source(所谓的分布式),在管道前后增加过滤器可以清洗数据 |
| Sink | 主动到 Channel 拉取数据,向目标源写数据,目标源可以使HDFS、HBase 也可以是下一个Source |
Flume 配置
编辑配置文件的 $JAVA_PATH 就可以使用了
Flume是什么的更多相关文章
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
随机推荐
- jquery-ui sortable 排序
https://blog.csdn.net/u013066244/article/details/51954198 <link ref="stylesheet" href ...
- 当你的域名是数字开头时如何命名java包路径
例如:域名是1001y.net 理想的包路径是net.1001y,但由于java命名规范的问题,首字母不能为数字,这时我们只有两种选择: 1,net.$1001y 使用$符号作为首字母. 2,net. ...
- jquery.dad.js实现table的垂直拖拽(并取到当前拖拽对象)
http://sc.chinaz.com/jiaoben/161202572210.htm 1.首先官网实例,实现的都是div为容器的元素拖拽,示例如下: 2.最近的项目,要实现tbody的每一行tr ...
- 小程序里打开app的实现过程
之前开发过类似得需求,也踩了一些小坑,在这里和大家分享下,毕竟这样的需求也不在少数,基本上产品后期都会有这样的需求: 官方说明 因为需要用户主动触发才能打开 APP,所以该功能不由 API 来调用,需 ...
- 03、IDEA下Spark API编程
03.IDEA下Spark API编程 3.1 编程实现Word Count 3.1.1 创建Scala模块 3.1.2 添加maven支持,并引入spark依赖 <?xml version=& ...
- php之判断点在多边形内的api
1.判断点在多边形内的数学思想:以那个点为顶点,作任意单向射线,如果它与多边形交点个数为奇数个,那么那个点在多边形内,相关公式: <?php class AreaApi{ //$area是一个多 ...
- CORS跨域请求的限制和解决
我们模拟一个跨域的请求,一个是8888,一个是8887 //server.js const http = require('http'); const fs = require('fs'); http ...
- 如何不安装SQLite让程序可以正常使用
System.Data.SQLite.dll和System.Data.SQLite.Linq.dll不必在GAC里面,关键在于Machine.config的DBProviderFactories没有正 ...
- Thread 创建线程
1.该线程变量 无参数 我们可以把线程的变量 理解为一个 委托.可以指向一个方法.有点像c语言中的指向函数的指针. 第1步我们创建了 Thread变量t1 ,第2步创建了一个方法threadChild ...
- ES6 extends继承及super使用读书笔记
extends 继承 extends 实现子类的继承 super() 表示父类的构造函数, 子类必须在 constructor中调用父类的方法,负责会报错. 子类的 this 是父类构造出来的, 再在 ...