pandas之groupby分组与pivot_table透视表
zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267
pandas之groupby分组与pivot_table透视表
在使用pandas进行数据分析时,避免不了使用groupby来对数据进行分组运算。
groupby的参数
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
by:mapping, function, str, or iterable。
用于确定groupby的组。如果by是一个函数,那么会调用对象索引的每个值。如果传递了一个dict或Series,则将使用Series或dict的值来确定组。一个str或者一个strs列表可以通过自己的列传递给group。
axis:轴,int值,默认为0
level:如果axis是一个MultiIndex(分层),则按特定的级别分组。int值,默认为None
as_index:对于聚合输出,返回带有组标签的对象作为索引。
as_index=False实际上是“SQL风格”分组输出,boolean值,默认为True。sort:排序。关闭此功能以获得更好的性能。boolean值,默认True。
group_keys:当调用apply时,添加group key来索引来识别片断。boolean值,默认True。
squeeze:尽可能减少返回类型的维度,否则返回一致的类型。boolean值,默认False。
groupby的聚合函数
groupby的聚合函数有:
| 函数名 | 说明 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的算术中位数 |
| std、var | 无偏(分母为n-1)标准差和方差 |
| min、max | 非NA值的最小值和最大值 |
| prod | 非NA值的积 |
| first、last | 第一个或最后一个非NA值 |
groupby示例
groupby的测试数据:
https://github.com/zhang3550545/resource/blob/master/raw/groupby_test.csv
- 读取groupby_test.csv文件中的数据,输处文件内容。
if __name__ == '__main__':
data = pd.read_csv('groupby_test.csv')
print(data[:10])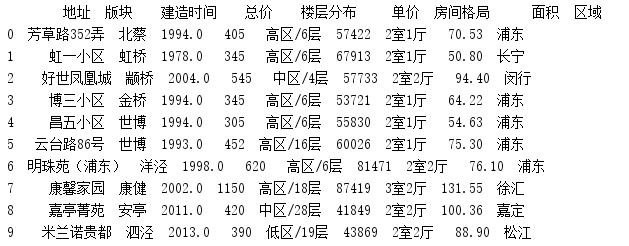
- groupby函数,对区域字段进行分组,对总价求平均值。
results = data.groupby(['区域'])['总价']
print(results) # 输出:<pandas.core.groupby.SeriesGroupBy object at 0x0000023D2AA02EF0>
print(results.mean())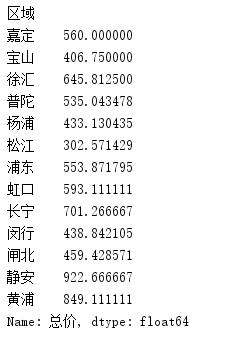
- groupby函数,对区域字段进行分组,对面积求和。
results = data.groupby(['区域'])['面积'].sum()
print(results)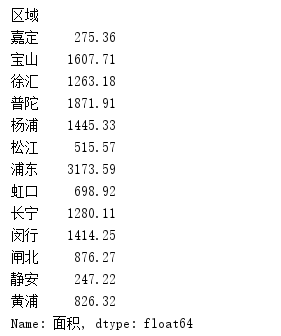
- groupby函数,对区域字段进行分组,对区域计算count。
results = data.groupby(data['区域'], sort=False)['区域'].count()
print(results)
- groupby函数,对区域字段进行分组,求总价,单价,面积的平均值。
results = data.groupby(['区域'])['总价', '单价', '面积'].mean()
print(results)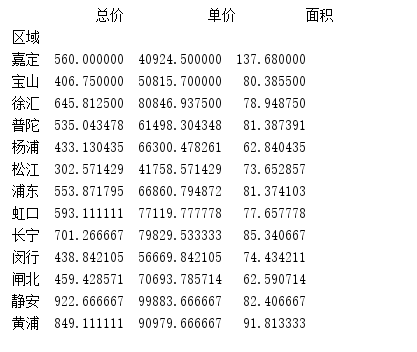
- groupby函数,对区域,版块2个字段进行分组,求单价的平均值。
results = data.groupby(['区域', '版块'])['单价'].mean()
print(results)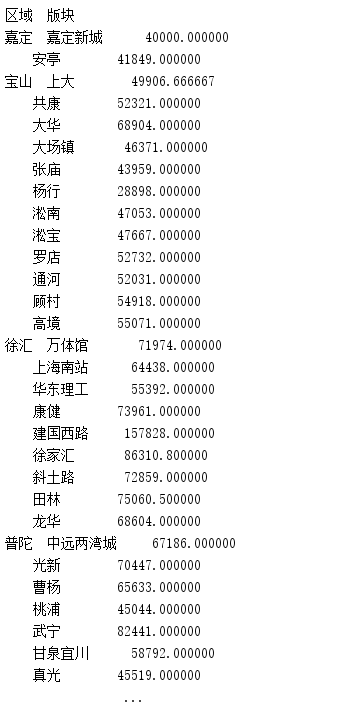
pivot_table透视表
使用pivot_table透视表实现groupby的功能
results = pd.pivot_table(data, index=['区域', '版块'], values=['单价'])
print(results)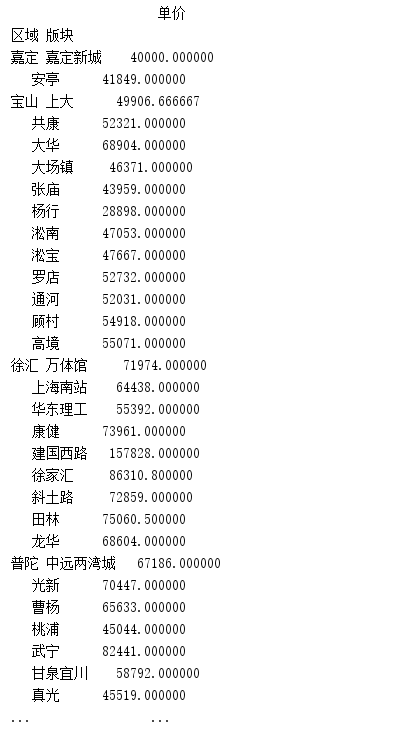
pandas之groupby分组与pivot_table透视表的更多相关文章
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- pandas实现excel中的数据透视表和Vlookup函数功能
在孩子王实习中做的一个小工作,方便整理数据. 目前这几行代码是实现了一个数据透视表和匹配的功能,但是将做好的结果写入了不同的excel中, 如何实现将结果连续保存到同一个Excel的同一个工作表中?还 ...
- pandas-10 pd.pivot_table()透视表功能
pandas-10 pd.pivot_table()透视表功能 和excel一样,pandas也有一个透视表的功能,具体demo如下: import numpy as np import pandas ...
- Pandas之groupby分组
释义 groupby用来分组,调用groupby 之后返回pandas.core.groupby.generic.DataFrameGroupBy,其实就是由一个个格式为(key, 分组后的dataf ...
- 04. Pandas 3| 数值计算与统计、合并连接去重分组透视表文件读取
1.数值计算和统计基础 常用数学.统计方法 数值计算和统计基础 基本参数:axis.skipna df.mean(axis=1,skipna=False) -->> axis=1是按行来 ...
- Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容 ...
- 小白学 Python 数据分析(12):Pandas (十一)数据透视表(pivot_table)
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- Python中pandas透视表pivot_table功能详解(非常简单易懂)
一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大 ...
随机推荐
- Vi/Vim查找替换使用方法【转】
原文地址:http://wzgyantai.blogbus.com/logs/28117977.html vi/vim 中可以使用 :s 命令来替换字符串.该命令有很多种不同细节使用方法,可以实现复杂 ...
- 解决oracle 表被锁住问题
想修改Oracle下的某一张表,提示 "资源正忙, 但指定以 NOWAIT 方式获取资源, 或者超时失效" 看上去是锁住了. 用系统管理员登录进数据库,然后 SELECT sid, ...
- 2016/04/29 ①cms分类 ② dede仿站制作 步骤 十个步骤 循环生成菜单 带子菜单的菜单 标签 栏目 栏目内容列表 内容图片列表
cms 系统还有: phpcms 企业站 Xiaocms 织梦 企业站 wordpress (博客) Ecshop 商城 Ecmall 多用户 Discms 记账 方维 订餐 团购 CMS ...
- SSH无密码验证可能出现的问题
雪影工作室版权所有,转载请注明[http://blog.csdn.net/lina791211] 一.安装和启动SSH协议 假设没有安装ssh和rsync,可以通过下面命令进行安装. sudo apt ...
- ubuntu字符界面下显示中文和调整分辨率
1.sudo apt-get install zhcon 2.vi /etc/zhcon.conf 修改下面两行 x_resolution 1024 y_resolution 768 完成这两步后在 ...
- lsblk df
df(1) - Linux manual page http://man7.org/linux/man-pages/man1/df.1.html report file system disk spa ...
- 简单的处理git add ,git commit,git push 脚本
创建脚本lazygit.sh #!/bin/bash # 一次性处理git提交 #branch_name=`git symbolic-ref --short -q HEAD` branch_name= ...
- I.MX6 i2c_data_write_byte ioctl error: I/O error
/************************************************************************* * I.MX6 i2c_data_write_by ...
- Python进程、线程、协程的对比
1. 执行过程 每个线程有一个程序运行的入口.顺序执行序列和程序的出口.但是线程不能够独立执行,必须依存在进程中,由进程提供多个线程执行控制.每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该 ...
- VMware虚拟机安装WinXP出现错误output error file to the following location A:\GHOSTERR.TXT
我们安装Ghost版WinXP系统的时候,可能会出现一个如下图这样的错误:output error file to the following location A:\GHOSTERR.TXT. 出现 ...