给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货!
参考博客
基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
但是,要注意的是,因为在amabri集群里啊,10000端口默认是给了oozie的。
然而,我上述的博客,是当时手动临时给的10000端口给kafka-manager,所以,对此,我这里改变端口,具体如下。
一、给基于Ubuntu14.04的ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager
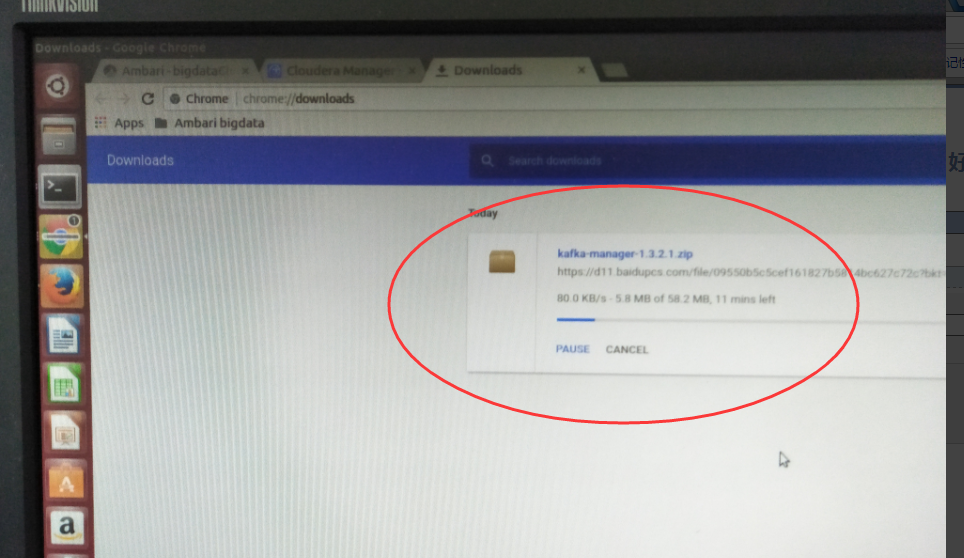
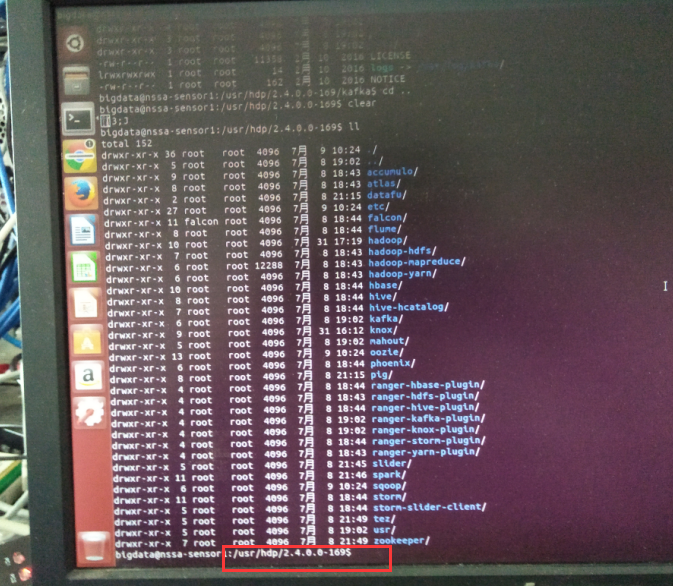
我这里,打算为了目录管理方便起见,安装Kafka-manager在/usr/hdp/2/4.0.0-169目录下。
具体过程见基于centos6.5,我这里就不贴图了,过程是完全一样的。
二、给基于CentOS6.5的ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager
下载
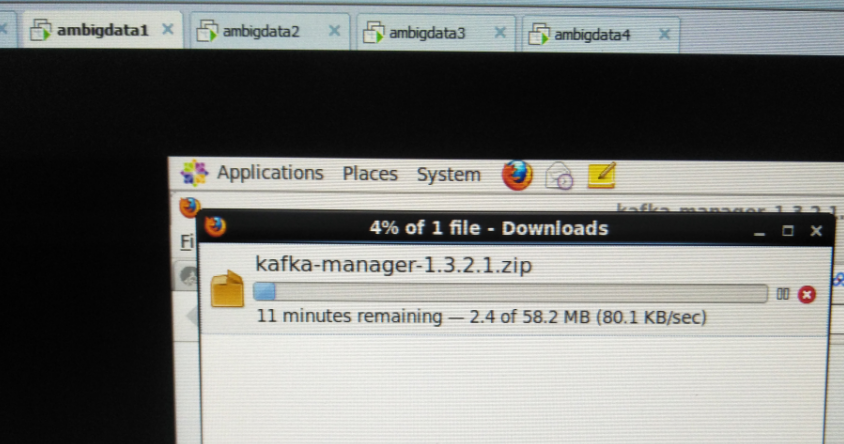

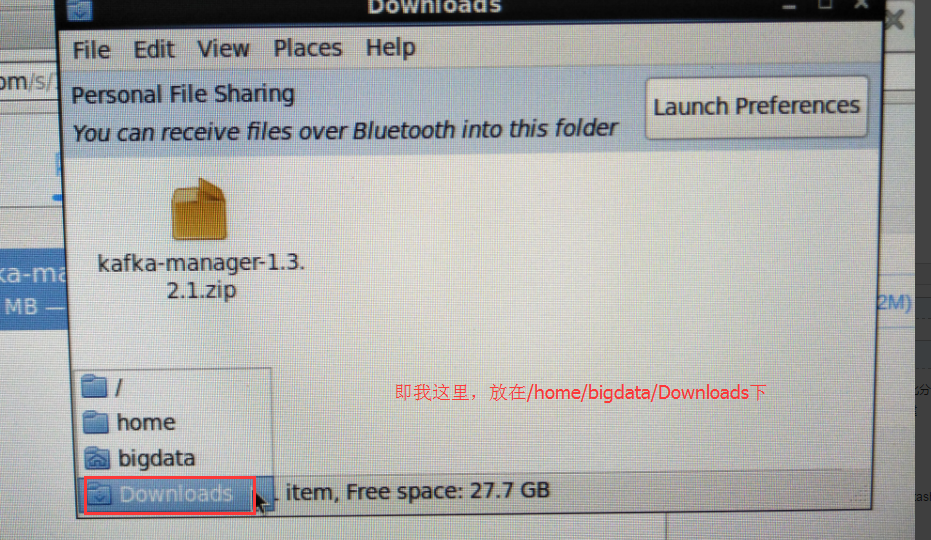

我这里,打算为了目录管理方便起见,安装Kafka-manager在/usr/hdp/2/4.0.0-169目录下。

[hadoop@ambigdata1 2.4.0.0.-]$ unzip kafka-manager-1.3.2.1.zip

[hadoop@ambigdata1 2.4.0.0-169]$ rm kafka-manager-1.3.2.1.zip
[hadoop@ambigdata1 2.4.0.0-169]$ cd kafka-manager-1.3.2.1/
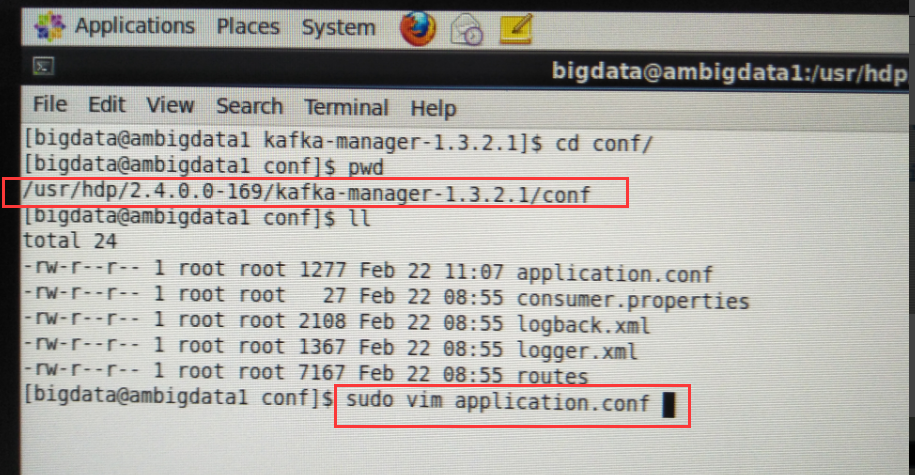
[hadoop@ambigdata1 conf]$ pwd
/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1/conf
[hadoop@ambigdata1 conf]$ ll
total
-rw-r--r-- hadoop hadoop Feb : application.conf
-rw-r--r-- hadoop hadoop Feb : consumer.properties
-rw-r--r-- hadoop hadoop Feb : logback.xml
-rw-r--r-- hadoop hadoop Feb : logger.xml
-rw-r--r-- hadoop hadoop Feb : routes
[hadoop@ambigdata1 conf]$ vim application.conf
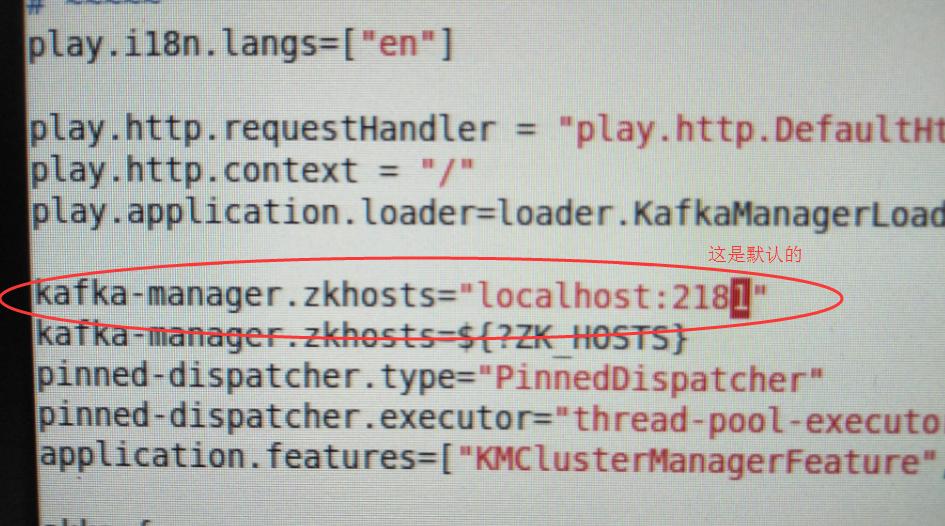
这是默认的
# Copyright Yahoo Inc. Licensed under the Apache License, Version 2.0
# See accompanying LICENSE file. # This is the main configuration file for the application.
# ~~~~~ # Secret key
# ~~~~~
# The secret key is used to secure cryptographics functions.
# If you deploy your application to several instances be sure to use the same key!
play.crypto.secret="^<csmm5Fx4d=r2HEX8pelM3iBkFVv?k[mc;IZE<_Qoq8EkX_/7@Zt6dP05Pzea3U"
play.crypto.secret=${?APPLICATION_SECRET} # The application languages
# ~~~~~
play.i18n.langs=["en"] play.http.requestHandler = "play.http.DefaultHttpRequestHandler"
play.http.context = "/"
play.application.loader=loader.KafkaManagerLoader kafka-manager.zkhosts="localhost:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
pinned-dispatcher.type="PinnedDispatcher"
pinned-dispatcher.executor="thread-pool-executor"
application.features=["KMClusterManagerFeature","KMTopicManagerFeature","KMPreferredReplicaElectionFeature","KMReassignPartitionsFeature"] akka {
loggers = ["akka.event.slf4j.Slf4jLogger"]
loglevel = "INFO"
} basicAuthentication.enabled=false
basicAuthentication.username="admin"
basicAuthentication.password="password"
basicAuthentication.realm="Kafka-Manager" kafka-manager.consumer.properties.file=${?CONSUMER_PROPERTIES_FILE}

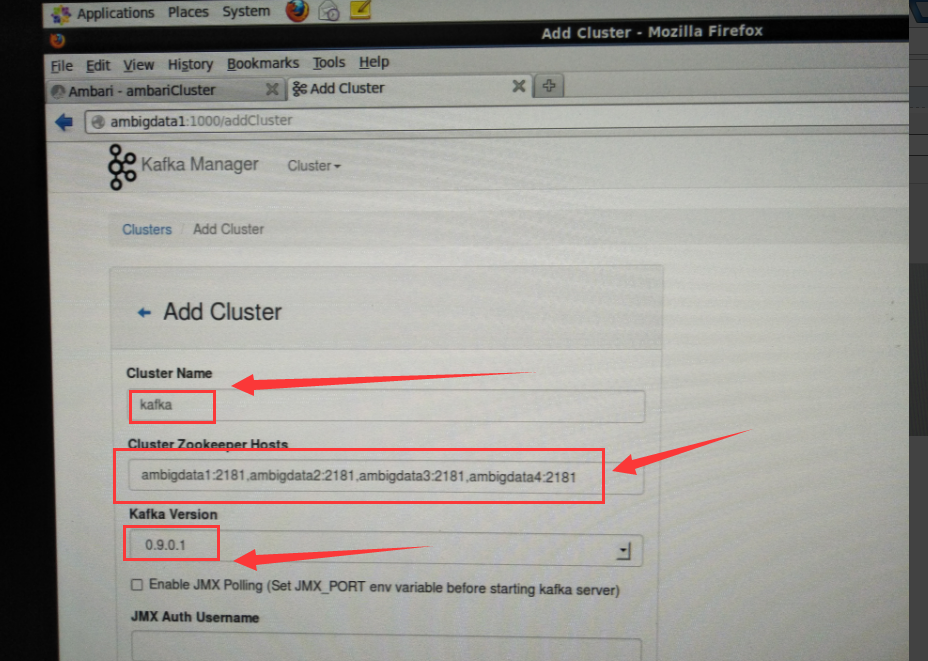
kafka-manager.zkhosts="ambigdata1:2181,ambigdata2:2181,ambigdata3:2181,ambigdata4:2181"

运行kafka manager
注意:默认启动端口为9000。
要到大家kafka-manager的安装目录下来执行。
如我这里是在/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1
bin/kafka-manager -Dconfig.file=conf/application.conf
或者
nohup bin/kafka-manager -Dconfig.file=conf/application.conf & (后台运行)
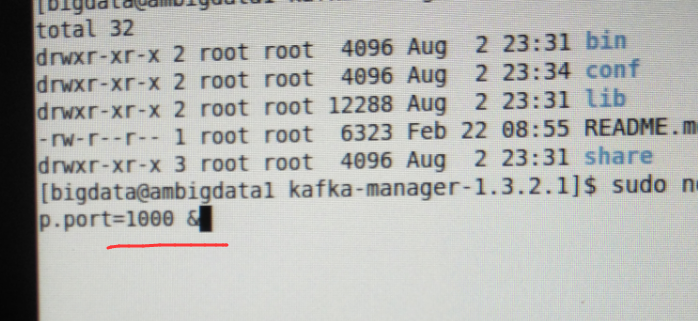
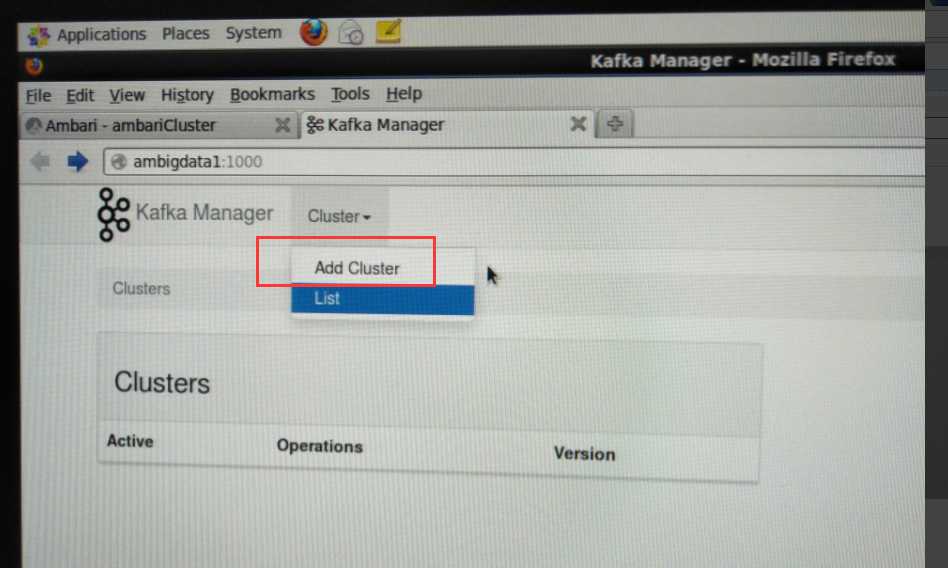
当然,大家可以以这个端口为所用,大家也可以在启动的时候,开启另一个端口,比如我这里开启1000端口。
最好使用绝对路径。
要到大家kafka-manager的安装目录下来执行。
如我这里是在/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1
nohup bin/kafka-manager -Dconfig.file=/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1/conf/application.conf -Dhttp.port=1000 &
我这里, 为了避免跟ambari集群里默认的oozie端口为10000。所以特地开启1000端口。

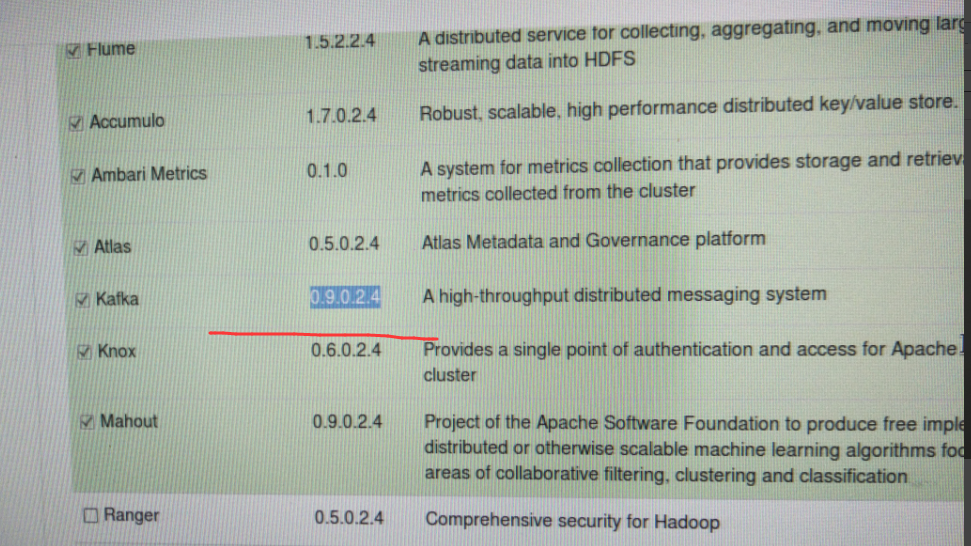
它会自动识别出,当前,你所用的kafka版本




点击【Go to cluster view.】打开当前的集群界面。

成功!
更详细见,
基于Web的Kafka管理器工具之Kafka-manager安装之后第一次进入web UI的初步配置(图文详解)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)的更多相关文章
- 安装Cloudera Manager集群时首次运行命令部署客户端设置失败的解决办法(图文详解)
不多说,直接上干货! 问题详情 解决办法 (1) 时间同步检查下(尤其是这个) (2) 防火墙是否关闭 (3) cloudera-scm-server 和 cloudera-scm-agent 是否启 ...
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)
不多说,直接上干货! 问题详情 明明put该有的文件在,可是怎么提示的是文件找不到的错误呢? 我就纳闷了put: `/home/bigdata/1.txt': No such file or dire ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
- 全网最详细的Windows系统里Oracle 11g R2 Database(64bit)的完全卸载(图文详解)
不多说,直接上干货! 前期博客 全网最详细的Windows系统里Oracle 11g R2 Database(64bit)的下载与安装(图文详解) 若你不想用了,则可安全卸载. 完全卸载Oracle ...
- 【适合公司业务】全网最详细的IDEA里如何正确新建【普通或者Maven】的Java web项目并发布到Tomcat上运行成功【博主强烈推荐】(类似eclipse里同一个workspace下【多个子项目】并存)(图文详解)
不多说,直接上干货! 首先,大家要明确,IDEA.Eclipse和MyEclipse等编辑器之间的新建和运行手法是不一样的. 如果是在Myeclipse里,则是File -> new -> ...
- ambari集群里如何正确删除历史修改记录(图文详解)
不多说,直接上干货! 答:这些你想删除的话得得去数据库里删除,最好别删除 . 现在默认就是使用好的配置 欢迎大家,加入我的微信公众号:大数据躺过的坑 人工智 ...
- 安装cloudermanager时出现Acquiring installation lock问题(图文详解)
不多说,直接上干货! 问题详情 解决办法 哪一个节点被锁就删除哪一个. 解决办法:进入/tmp 目录,ls -a查看,删除scm_prepare_node.*的文件,以及.scm_prepare_no ...
随机推荐
- coco2d-js demo程序之滚动的小球
近期有一个游戏叫围住神经猫,报道说是使用html5技术来做的. html5的跨平台的优良特性非常不错.对于人手不足,技术不足,选用html5技术实现跨平台的梦想真是不错. 近期在看coco2d-js这 ...
- C#使用SharpZipLib压缩解压文件
#region 加压解压方法 /// <summary> /// 功能:压缩文件(暂时只压缩文件夹下一级目录中的文件,文件夹及其子级被忽略) /// </summary> // ...
- eclispe pydev tab改回 空格找到方法了,这个链接:http://stackoverflow.com/questions/23570925/eclipse-indents-new-line-with-tabs-instead-of-spaces
看这个链接: 3down votefavorite 1 I've followed all the suggestions here. When I press return, I get a new ...
- YTU 2418: C语言习题 矩阵元素变换
2418: C语言习题 矩阵元素变换 时间限制: 1 Sec 内存限制: 128 MB 提交: 293 解决: 155 题目描述 将一个n×n(2<n<10,n为奇数)的矩阵中最大的元 ...
- BZOJ_2099_[Usaco2010 Dec]Letter 恐吓信_后缀自动机+贪心
BZOJ_2099_[Usaco2010 Dec]Letter 恐吓信_后缀自动机 Description FJ刚刚和邻居发生了一场可怕的争吵,他咽不下这口气,决定佚名发给他的邻居 一封脏话连篇的信. ...
- linux下libpcap抓包分析
一.首先下载libpcap包http://www.tcpdump.org/#latest-release 然后安装,安装完成后进入安装根目录的tests文件夹,编译运行findalldevstest. ...
- codeforces round#432 div2
C:这道题没做出来...写了个类似极角排序的东西被卡掉了...事实上暴力就行了,因为如果在二维平面内那么最多只能有4个点,因为每个象限只能有一个点,然后这里拓展一下就是最多只能有2*k个点,k是维数, ...
- Python解压缩ZIP格式
转自:http://blog.csdn.net/linux__kernel/article/details/8271326 很多人在Google上不停的找合适自己的压缩,殊不知Py的压缩很不错.可以试 ...
- E20170514-ts
yield n. 产量,产额; moldule n. 模块; 组件; exception n 例外 except prep. 除…外; vt. 把…除外; 不计 accessor 存取器; ...
- 小程序 获取地理位置-- wx.getLocation
话不多说直接上栗子 //首先声明变量data:{ showLocationAuth:fasle } //这是第一种逻辑实现方式 点击按钮//当第一次点击授权按钮,用户取消授权之后,就会显示 授权当前定 ...