CDH5.7Hadoop集群搭建(离线版)
用了一周多的时间终于把CDH版Hadoop部署在了测试环境(部分组件未安装成功),本文将就这个部署过程做个总结。
一、Hadoop版本选择。
Hadoop大致可分为Apache Hadoop和第三方发行第三方发行版Hadoop,考虑到Hadoop集群部署的高效,集群的稳定性,以及后期集中的配置管理,业界多使用Cloudera公司的发行版,简称为CDH。
下面是转载的Hadoop社区版本与第三方发行版本的比较:
Apache社区版本
优点:
- 完全开源免费。
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
- 复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
- 复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
- 复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。(可以通过技术解决)
转自:http://itindex.net/detail/51484-%E8%87%AA%E5%AD%A6-%E5%A4%A7%E6%95%B0%E6%8D%AE-%E7%94%9F%E4%BA%A7
更多内容请看原作者博客。
二、安装介质准备
安装介质准备和安装部分主要参考:http://blog.csdn.net/shawnhu007/article/details/52579204,对其内容进行少许补充以做到能傻瓜安装的目的。
我们采用离线安装的方式,需要下载CDH离线安装包和相关组件:
- 操作系统采用CentOS Minimal 7 :http://124.205.69.134/files/4128000005F9FCB3/mirrors.zju.edu.cn/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
- JDK环境 版本:jdk-8u101-linux-x64.rpm 下载地址:oracle官网mysql
- rpm包:http://dev.mysql.com/get/Downloads/MySQL-5.6/MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tarjdbc连接包mysql-connector-java-5.1.39-bin.jar: http://dev.mysql.com/downloads/connector/j/
- CDH安装相关的包
- cloudera manager包 :5.7.2 cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz
下载地址:http://archive.cloudera.com/cm5/cm/5/cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz - CDH-5.7.2-1.cdh5.7.2.p0.11-el7.parcel
- CDH-5.7.2-1.cdh5.7.2.p0.11-el7.parcel.sha1
- manifest.json
以上三个下载地址在http://archive.cloudera.com/cdh5/parcels/5.7.2/,注意centos要下载el7的,我就因为一开始不清楚下的el6,结果提示parcels不知道redhat7,搞了好久才还原到初始重新来过
- cloudera manager包 :5.7.2 cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz
介质下载和安装部分主要参考:http://blog.csdn.net/shawnhu007/article/details/52579204
在线安装请参考文章(对网速有较高要求):http://www.cnblogs.com/ee900222/p/hadoop_3.html
三、操作系统准备
准备好三台环境一样的centos7在本地虚拟机VMWare上,Cloudera发行版比起Apache社区版本安装对硬件的要求更高,内存至少10G,不然后面你会遇到各种问题,或许都找不到答案。
本人前2次安装失败就是因为节点分配内存太少,建议对于cloudera-scm-server就需要至少4G的内存,cloudera-scm-agent的内存至少也需要1.5G以上。
3台虚拟机环境如下:
| IP地址 | 主机名 | 说明 |
| 192.168.42.128 | CDH1 | 主节点master,datanode |
| 192.168.42.129 | CDH2 | datanode |
| 192.168.42.30 | CDH3 | datanode |
四、开始安装前配置和预装软件
可以在VM中先安装1台机器,做完相关配置后再克隆出另外2台机器,以避免在3台机器上的重复配置
因为Centos7的最小安装版,所以首先解决首次开机联网问题
[root@cdh1~]$ vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
将 ONBOOT=no 改为 ONBOOT=yes [root@cdh1~]$ systemct1 restart network
[root@cdh1~]$ yum install net-tools //为了使用ifconfig查看网络
- 安装jdk(每台机器都要) ,首先卸载原有的openJDK
[root@cdh1~]$ java -version
[root@cdh1~]$ rpm -qa | grep jdk
java-1.7.-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
java-1.7.-openjdk-headless-1.7.0.75-2.5.4.2.el7_0.x86_64
[root@cdh1~]# yum -y remove java-1.7.-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
[root@cdh1~]# yum -y remove java-1.7.-openjdk-headless-1.7.0.75-2.5.4.2.el7_0.x86_64
[root@cdh1~]# java -version
bash: /usr/bin/java: No such file or directory
[root@cdh1~]# rpm -ivh jdk-8u101-linux-x64.rpm
[root@cdh1~]# java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) -Bit Server VM (build 25.101-b13, mixed mode)
- 修改每台节点服务器的有关配置hostname、selinux关闭,防火墙关闭;hostname修改:分别对三台都进行更改,并且注意每台名称和ip,每台都要配上hosts。下面以cdh1为例
[root@cdh1~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=cdh1 [root@cdh1~]# vi /etc/hosts
127.0.0.1 localhost.cdh1
192.168.42.128 cdh1
192.168.42.129 cdh2
192.168.42.130 cdh3
- selinux关闭(所有节点官方文档要求),机器重启后生效。
[root@cdh1~]# vi /etc/sysconfig/selinux
SELINUX=disabled
[root@cdh1~]#sestatus -v
SELinux status: disabled
表示已经关闭了
- 关闭防火墙
[root@cdh1~]# systemctl stop firewalld
[root@cdh1~]# systemctl disable firewalld
rm '/etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service'
rm '/etc/systemd/system/basic.target.wants/firewalld.service'
[root@cdh1~]# systemctl status firewalld
firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled)
Active: inactive (dead)
- NTP服务器配置(用于3个节点间实现时间同步)
[root@cdh1~]#yum -y install ntp
更改master的节点
[root@cdh1~]## vi /etc/ntp.conf
注释掉所有server *.*.*的指向,新添加一条可连接的ntp服务器(我选的本公司的ntp测试服务器)
server 172.30.0.19 iburst
在其他节点上把ntp指向master服务器地址即可(/etc/ntp.conf下)
server 192.168.42.128 iburst
[root@cdh1~]## systemctl start ntpd //启动ntp服务
[root@cdh1~]## systemctl status ntpd //查看ntp服务状态
- SSH无密码登录配置,各个节点都需要设置免登录密码
下面以192.168.42.128到192.168.42.129的免密登录设置举例
[root@cdh1 /]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
1d:e9:b4:ed:1d:e5:c6:a7:f3::ac::2b:8c:fc:ca root@cdh1
The key's randomart image is:
+--[ RSA ]----+
| |
| . |
| + .|
| + + + |
| S + . . =|
| . . . +.|
| . o o o + |
| .o o . . o + |
| Eo.. ... . o|
+-----------------+
[root@cdh1 /]# ssh-copy-id 192.168.42.129
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.42.129's password: Number of key(s) added: Now try logging into the machine, with: "ssh '192.168.42.129'"
and check to make sure that only the key(s) you wanted were added.
安装mysql
centos7自带的是mariadb,需要先卸载掉
[root@cdh1 /]# rpm -qa | grep mariadb
mariadb-libs-5.5.-.el7_0.x86_64
[root@cdh1 /]# rpm -e --nodeps mariadb-libs-5.5.-.el7_0.x86_64
[root@cdh1 /]# tar -xvf MySQL-5.6.-.linux_glibc2..x86_64.rpm-bundle.tar //mysql rpm包拷贝到服务器上然后解压
[root@cdh1 /]# rpm -ivh MySQL-*.rpm //安装释出的全部rpm
[root@cdh1 /]# cp /usr/share/mysql/my-default.cnf /etc/my.cnf
[root@cdh1 /]# vi /etc/my.cnf //在配置文件中增加以下配置并保存
[mysqld]
default-storage-engine = innodb
innodb_file_per_table
collation-server = utf8_general_ci
init-connect = 'SET NAMES utf8'
character-set-server = utf8 [root@cdh1 /]# yum install -y perl-Module-Install.noarch
[root@cdh1 /]# /usr/bin/mysql_install_db //初始化mysql
[root@cdh1 /]# service mysql restart //启动mysql
ERROR! MySQL server PID file could not be found!
Starting MySQL... SUCCESS!
[root@cdh1 /]# cat /root/.mysql_secret //查看mysql root初始化密码
# The random password set for the root user at Fri Sep :: (local time): 9mp7uYFmgt6drdq3
[root@cdh1 /]# mysql -u root -p //登录进行去更改密码
mysql> SET PASSWORD=PASSWORD('');
mysql> update user set host='%' where user='root' and host='localhost'; //允许mysql远程访问
Query OK, row affected (0.05 sec)
Rows matched: Changed: Warnings:
mysql> flush privileges;
Query OK, rows affected (0.00 sec) [root@cdh1 /]# chkconfig mysql on //配置开机启动
[root@cdh1 /]# tar -zcvf mysql-connector-java-5.1.44.tar.gz // 解压mysql-connector-java-5.1.44.tar.gz得到mysql-connector-java-5.1.44-bin.jar
[root@cdh1 /]# mkdir /usr/share/java // 在各节点创建java文件夹
[root@cdh1 /]# cp mysql-connector-java-5.1.44-bin.jar /usr/share/java/mysql-connector-java.jar //将mysql-connector-java-5.1.44-bin.jar拷贝到/usr/share/java路径下并重命名为mysql-connector-java.jar
- 创建数据库
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, row affected (0.00 sec)
create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, row affected (0.00 sec)
create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, row affected (0.00 sec)
create database monitor DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, row affected (0.00 sec)
create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, row affected (0.00 sec)
grant all on *.* to root@"%" Identified by "";
五、安装Cloudera-Manager
//解压cm tar包到指定目录所有服务器都要(或者在主节点解压好,然后通过scp到各个节点同一目录下) [root@cdh1 ~]#mkdir /opt/cloudera-manager
[root@cdh1 ~]# tar -axvf cloudera-manager-centos7-cm5..2_x86_64.tar.gz -C /opt/cloudera-manager //创建cloudera-scm用户(所有节点)
[root@cdh1 ~]# useradd --system --home=/opt/cloudera-manager/cm-5.7./run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm //在主节点创建cloudera-manager-server的本地元数据保存目录
[root@cdh1 ~]# mkdir /var/cloudera-scm-server
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /var/cloudera-scm-server
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera-manager //配置从节点cloudera-manger-agent指向主节点服务器
[root@cdh1 ~]# vi /opt/cloudera-manager/cm-5.7./etc/cloudera-scm-agent/config.ini
将server_host改为CMS所在的主机名即cdh1 //主节点中创建parcel-repo仓库目录
[root@cdh1 ~]# mkdir -p /opt/cloudera/parcel-repo
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo
[root@cdh1 ~]# cp CDH-5.7.-.cdh5.7.2.p0.-el7.parcel CDH-5.7.-.cdh5.7.2.p0.-el7.parcel.sha manifest.json /opt/cloudera/parcel-repo
注意:其中CDH-5.7.-.cdh5.7.2.p0.-el5.parcel.sha1 后缀要把1去掉 //所有节点创建parcels目录
[root@cdh1 ~]# mkdir -p /opt/cloudera/parcels
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera/parcels
解释:Clouder-Manager将CDHs从主节点的/opt/cloudera/parcel-repo目录中抽取出来,分发解压激活到各个节点的/opt/cloudera/parcels目录中 //初始脚本配置数据库scm_prepare_database.sh(在主节点上)
[root@cdh1 ~]# /opt/cloudera-manager/cm-5.7./share/cmf/schema/scm_prepare_database.sh mysql -hcdh1 -uroot -p123456 --scm-host cdh1 scmdbn scmdbu scmdbp
说明:这个脚本就是用来创建和配置CMS需要的数据库的脚本。各参数是指:
mysql:数据库用的是mysql,如果安装过程中用的oracle,那么该参数就应该改为oracle。
-cdh1:数据库建立在cdh1主机上面,也就是主节点上面。
-uroot:root身份运行mysql。-:mysql的root密码是***。
--scm-host cdh1:CMS的主机,一般是和mysql安装的主机是在同一个主机上,最后三个参数是:数据库名,数据库用户名,数据库密码。 如果报错:
ERROR com.cloudera.enterprise.dbutil.DbProvisioner - Exception when creating/dropping database with user 'root' and jdbc url 'jdbc:mysql://localhost/?useUnicode=true&characterEncoding=UTF-8'
java.sql.SQLException: Access denied for user 'root'@'cdh1' (using password: YES) 则参考 http://forum.spring.io/forum/spring-projects/web/57254-java-sql-sqlexception-access-denied-for-user-root-localhost-using-password-yes 运行如下命令: update user set PASSWORD=PASSWORD('') where user='root'; GRANT ALL PRIVILEGES ON *.* TO 'root'@'cdh1' IDENTIFIED BY '' WITH GRANT OPTION; FLUSH PRIVILEGES; //启动主节点
[root@cdh1 ~]# cp /opt/cloudera-manager/cm-5.7./etc/init.d/cloudera-scm-server /etc/init.d/cloudera-scm-server
[root@cdh1 ~]# chkconfig cloudera-scm-server on
[root@cdh1 ~]# vi /etc/init.d/cloudera-scm-server
CMF_DEFAULTS=${CMF_DEFAULTS:-/etc/default}改为=/opt/cloudera-manager/cm-5.7./etc/default
[root@cdh1 ~]# service cloudera-scm-server start
//同时为了保证在每次服务器重启的时候都能启动cloudera-scm-server,应该在开机启动脚本/etc/rc.local中加入命令:service cloudera-scm-server restart //启动cloudera-scm-agent所有节点
[root@cdhX ~]# mkdir /opt/cloudera-manager/cm-5.7./run/cloudera-scm-agent
[root@cdhX ~]# cp /opt/cloudera-manager/cm-5.7./etc/init.d/cloudera-scm-agent /etc/init.d/cloudera-scm-agent
[root@cdhX ~]# chkconfig cloudera-scm-agent on
[root@cdhX ~]# vi /etc/init.d/cloudera-scm-agent
CMF_DEFAULTS=${CMF_DEFAULTS:-/etc/default}改为=/opt/cloudera-manager/cm-5.7./etc/default
[root@cdhX ~]# service cloudera-scm-agent start
//同时为了保证在每次服务器重启的时候都能启动cloudera-scm-agent,应该在开机启动脚本/etc/rc.local中加入命令:service cloudera-scm-agent restart
六、在浏览器安装CDH
等待主节点完成启动就在浏览器中进行操作了
进入192.168.42.128:7180 默认使用admin admin登录
以下在浏览器中使用操作安装


配置主机:由于我们在各个节点都安装启动了agent,并且在中各个节点都在配置文件中指向cdh1是server节点,所以这里我们可以在“当前管理的主机”中看到三个主机,全部勾选并继续.
注意:如果cloudera-scm-agent没有设为开机启动,如果以上有重启这里可能会检测不到其他服务器。
然后选择选择cdh
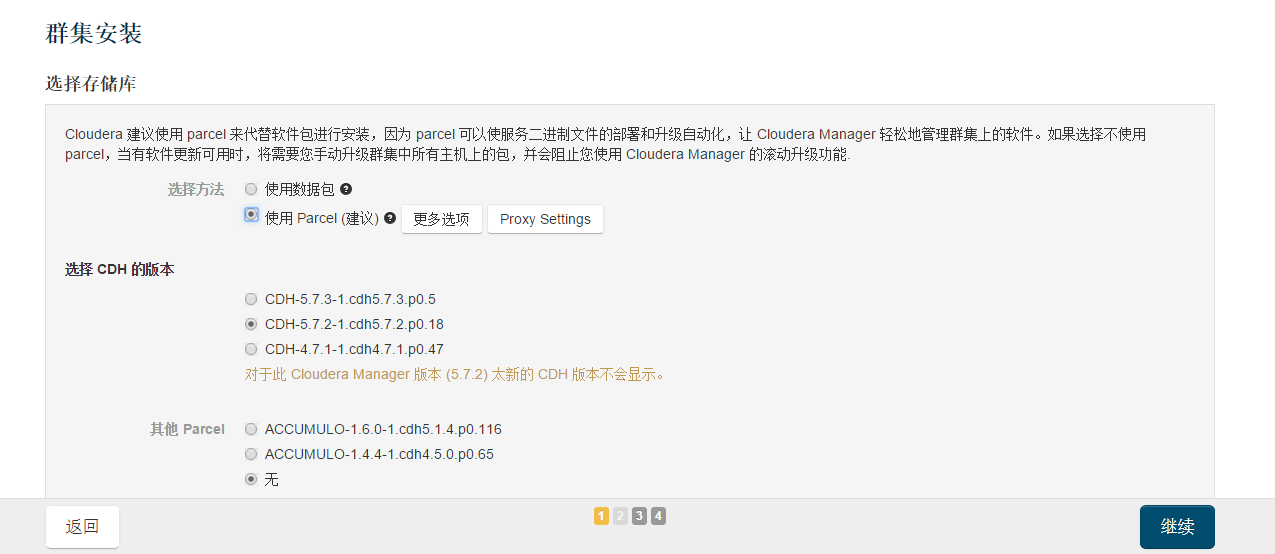
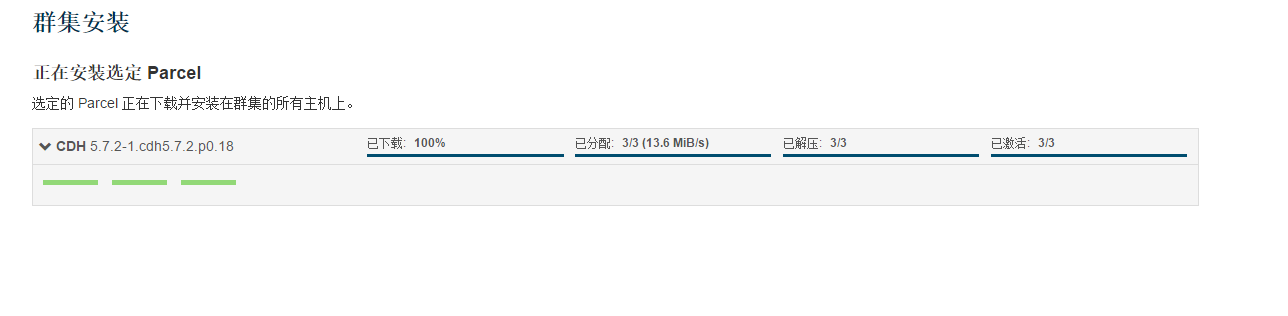
这个地方要注意这个地方有两项没有检查通过,
根据帖子 http://www.cnblogs.com/itboys/p/5955545.html 可以在集群中使用以下命令,然后再点击上面的重新运行会发现这次全部检查通过了,
但是我没有成功,还请高手告诉我原因。
echo > /proc/sys/vm/swappiness
echo never > /sys/kernel/mm/transparent_hugepage/defrag
根据需要选择要安装的服务,如果选择所有服务则对系统配置要求较高
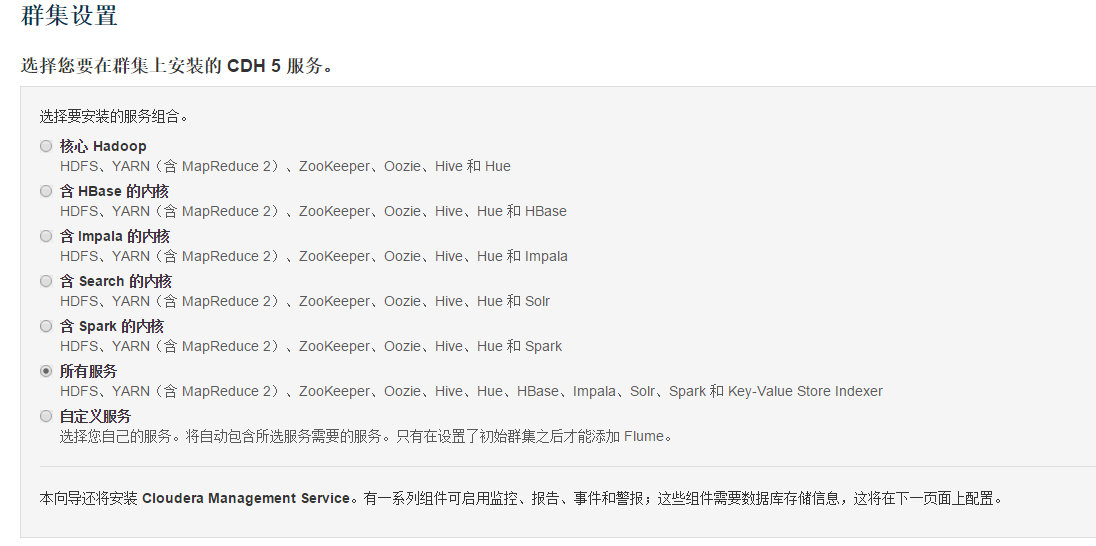
数据库设置选择
| 数据库设置 | 数据库类型 | 数据库名称 | 用户名 | 密码 |
| Hive | mysql | hive | root | 123456 |
| Oozie Server | mysql | oozie | root | 123456 |
然后直接下一步下一步开始安装
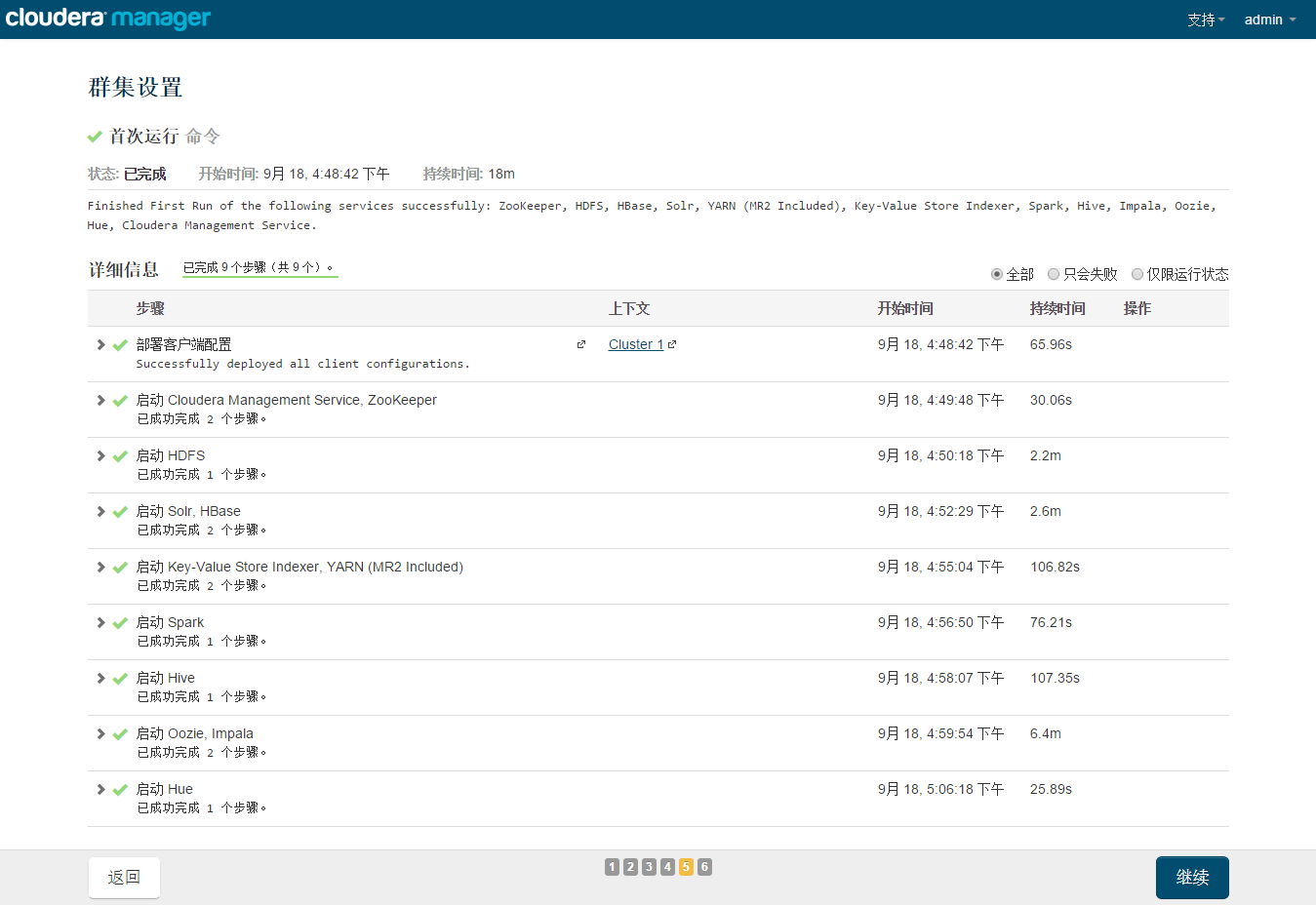

安装完成后可在浏览器中进入192.168.42.128:7180地址,查看集群情况:
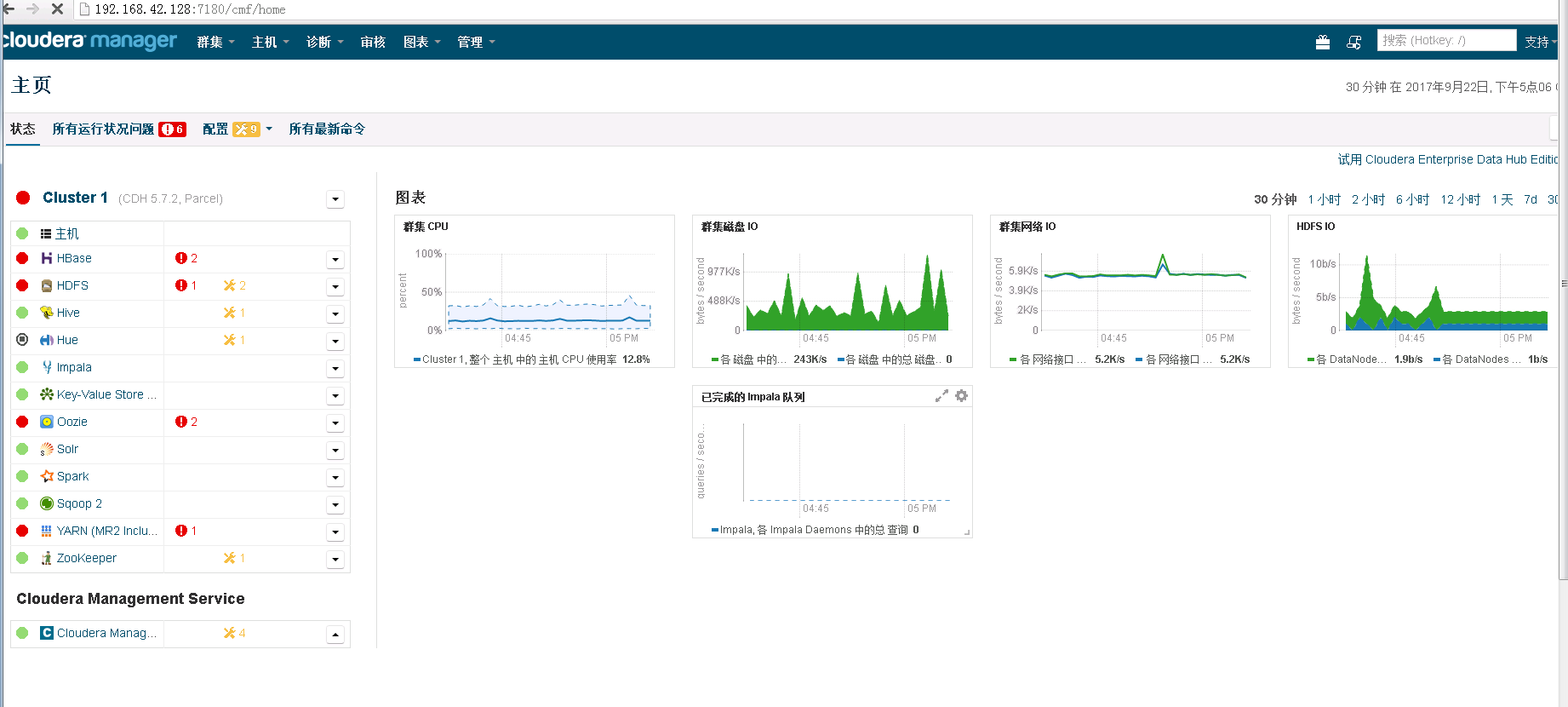
我这里有较多报警,大概是安装过程中部分组件存在错误所致,现在还没有能力排除这些错误,先看基本功能。
七、测试
在集群的一台机器上执行以下模拟Pi的示例程序:
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi
通过YARN的Web管理界面也可以看到MapReduce的执行状态:

MapReduce执行过程中终端的输出如下:
Number of Maps =
Samples per Map =
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Starting Job
// :: INFO client.RMProxy: Connecting to ResourceManager at cdh1/192.168.42.128:
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1505892176617_0002
// :: INFO impl.YarnClientImpl: Submitted application application_1505892176617_0002
// :: INFO mapreduce.Job: The url to track the job: http://cdh1:8088/proxy/application_1505892176617_0002/
// :: INFO mapreduce.Job: Running job: job_1505892176617_0002
// :: INFO mapreduce.Job: Job job_1505892176617_0002 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1505892176617_0002 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total vcore-seconds taken by all reduce tasks=
Total megabyte-seconds taken by all map tasks=
Total megabyte-seconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
Job Finished in 102.286 seconds
Estimated value of Pi is 3.14800000000000000000
遇到的问题:
1、在Windows Server2008 r2服务器使用VM安装Centos7时,报错:
此主机不支持64位客户机操作系统,此系统无法运行
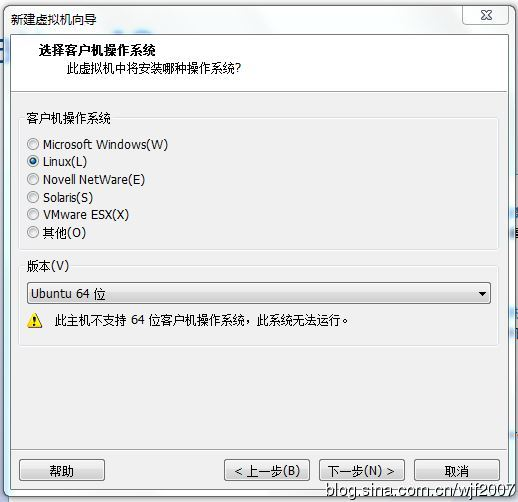
这个需要分别在VM的虚拟机编辑中添加VT-X虚拟化功能,并且在Windows Server服务器的虚拟机服务器管理Web界面同步设置。
2、在集群设置时,好几个组件安装失败。
首次,
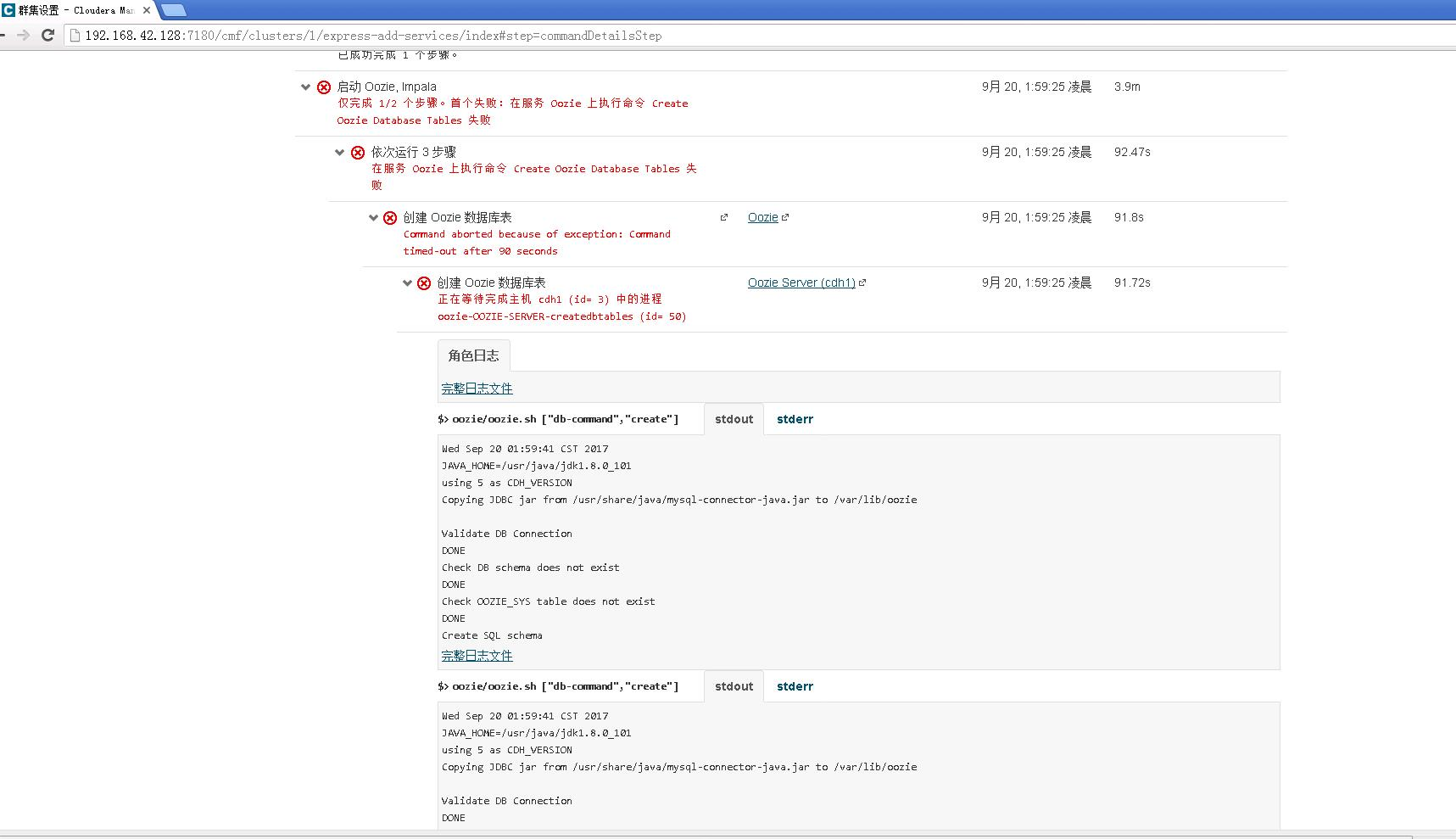
重试后
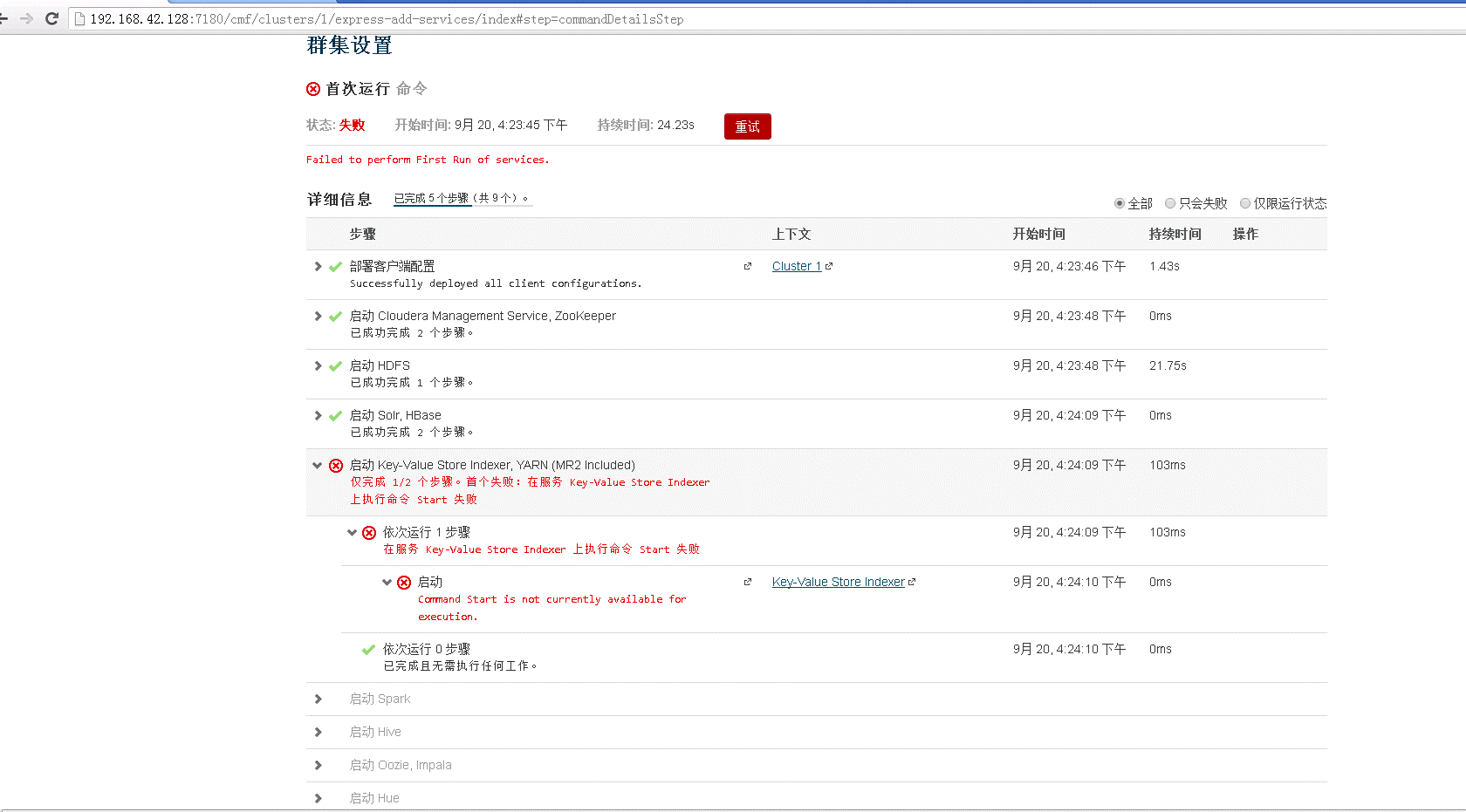
如上问题至今未解决,欢迎高手指教。
铸剑团队签名:
【总监】十二春秋之,3483099@qq.com;
【Master】戈稻不苍,han169@126.com;
【Java开发】雨鸶,343691194@qq.com;思齐骏惠,qiangzhang1227@163.com;小王子,545106057@qq.com;巡山小钻风,840260821@qq.com;
【VS开发】豆点,2268800211@qq.com;
【系统测试】土镜问道,847071279@qq.com;尘子与自由,695187655@qq.com;
【大数据】沙漠绿洲,caozhipan@126.com;张三省,570417591@qq.com;
【网络】夜孤星,11297761@qq.com;
【系统运营】三石头,261453882@qq.com;平凡怪咖,591169003@qq.com;
【容灾备份】秋天的雨,18568921@qq.com;
【安全】保密,你懂的。
原创作者:张三省
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CDH5.7Hadoop集群搭建(离线版)的更多相关文章
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
- JAVAEE——宜立方商城08:Zookeeper+SolrCloud集群搭建、搜索功能切换到集群版、Activemq消息队列搭建与使用
1. 学习计划 1.solr集群搭建 2.使用solrj管理solr集群 3.把搜索功能切换到集群版 4.添加商品同步索引库. a) Activemq b) 发送消息 c) 接收消息 2. 什么是So ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- fastdfs集群版搭建(一)- storage集群搭建与统一入口访问
前言 接着上篇博客:详细的最新版fastdfs单机版搭建,今天来讲讲fastdfs的集群搭建,限于篇幅,今天先搭建stoarge集群,并实现统一的http访问方式: 没看我上篇博客的小伙伴,最好先去瞅 ...
- Redis Cluster集群搭建与应用
1.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper,但从redis 3.0之后版本支持redis-cluster集群,redis-cluster采用无中心结 ...
- Hadoop3集群搭建之——虚拟机安装
现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化 ...
- hadoop2.8 ha 集群搭建
简介: 最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop ...
- HBase完全分布式集群搭建
HBase完全分布式集群搭建 hbase和hadoop一样也分为单机版,伪分布式版和完全分布式集群版,此文介绍如何搭建完全分布式集群环境搭建.hbase依赖于hadoop环境,搭建habase之前首先 ...
随机推荐
- 腾讯云,搭建Git服务器
下载安装 git 任务时间:5min ~ 10min Git 是一款免费.开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. 此实验以 CentOS 7.2 x64 的系统为环境,搭建 ...
- Tree(树的还原以及树的dfs遍历)
紫书:P155 uva 548 You are to determine the value of the leaf node in a given binary tree that is th ...
- List lambda 排序
Comparator<PromotionRule> comparator = Comparator.comparing(PromotionRule::getCreatedTime); pr ...
- cmd界面中断一个程序快捷键 ctrl+c
cmd界面中断一个程序快捷键 ctrl+c
- 在JQuery中$(document.body)和这个$("body") 这两的区别在哪里?
两种写法代表的是同一个对象 $("body") 是一个选择器,jQuery 会从 DOM 顶端开始搜索,直到找到标签为 body 的元素. 而 $(document.body) 中 ...
- objective-c 通告
1. 通告和委托的区别 通告也能传递与事件相关的数据.通告不同于委托的地方在于,通告是在对象执行完成动作之后产生,而不是之前.受到通告的对象没有机会建议是否要执行动作,而且对象的通告可以有多个监听者( ...
- codevs—— 1077 多源最短路
1077 多源最短路 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description 已知n个点(n<=100),给你 ...
- Spring Cloud简介/版本选择/ZooKeeper例子搭建简单说明
一.什么是Spring Cloud 官方的说法就是Spring Cloud 给开发者提供一套按照一定套路快速开发分布式系统的工具. 具体点就是Spring Boot实现的微服务架构开发工具.它为微服务 ...
- nodejs fs.open
fs.open(path, flags, [mode], [callback(err, fd)])是 POSIX open 函数的封装,与 C 语言标准库中的 fopen 函数类似.它接受两个必选参数 ...
- MVC中路由的一些内容详解
使用路由的好处:1.能够根据系统需求,灵活的划分请求规则(不同模块请求的URL是不一样的)2.屏蔽物理路径,提高系统的安全性,以上情况是无法根据URL分析视图文件在站点目录中的位置3.有利于搜索引擎优 ...