ssd训练自己的数据集
1.在ssd/caffe/data下创建VOC2007的目录,将ssd/caffe/data/VOC0712里的create_data.sh、create_list.sh和labelmap_voc.prototxt拷贝到VOC2007下,得如下图:

2.在/home/bnrc下创建data目录,在data目录下创建VOCdevkit2007目录,直接把VOC2007整个数据的文件夹放在VOCdevkit2007目录下,结构如图:

VOC2007文件夹所包含的目录:

3.在ssd/caffe/examples目录下,创建VOC2007文件夹,这个文件夹之后要存储生成的lmdb数据
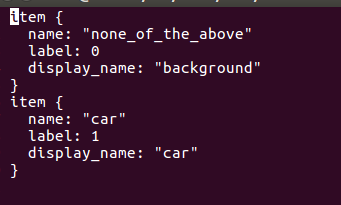
4.修改labelmap_voc.prototxt成你自己的格式:
运行create_list.sh:./create_list.sh,报以下错误:

因为我的data目录下是VOCdevkit2007,所以需要修改create_list.sh中的root_dir=$HOME/data/VOCdevkit/为root_dir=$HOME/data/VOCdevkit2007/
修改之后依旧报以下错:

这是因为/data/VOCdevkit2007下只有VOC2007,没有2012,所以需要把for name in VOC2007 VOC2012中的VOC2012删除
修改之后报以下错误:

这是还没有编译ssd这个目录的原因
之后再运行create_data.sh :./create_data.sh,报以下错误:

需要将create_data.sh中的data_root_dir="$HOME/data/VOCdevkit"改为data_root_dir="$HOME/data/VOCdevkit2007",将dataset_name="VOC0712"改为dataset_name="VOC2007"
再运行报以下错误:

用export PYTHONPATH=/home/bnrc/ssd/caffe/python修改PYTHONPATH
修改之后又报错:
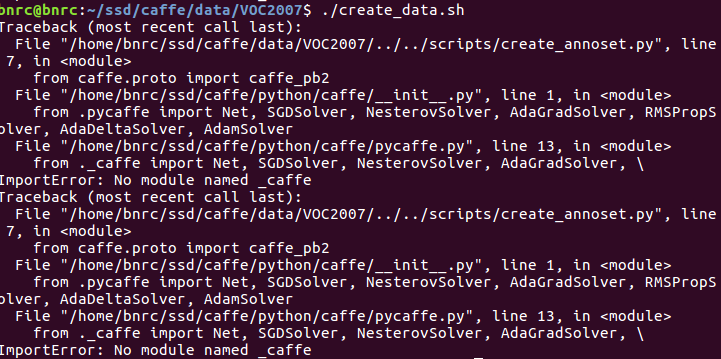
这是因为我之前只在ssd/caffe进行make,没有make pycaffe
make pycaffe的显示:

可以看到,生成了_caffe
再运行就能正确在./examples/VOC2007下生成lmdb数据了
5.修改ssd_pascal.py代码:

自己的是VOC2007

model_name修改为VOC2007
save_dir修改为VOC2007
snapshot_dir修改为VOC2007
job_dir修改为VOC2007
output_result_dir在/data前加/home/bnrc
name_size_file修改为VOC2007
label_map_file修改为VOC2007
num_classes修改为2

gpu可以根据需要选择

6.训练数据:python ./examples/ssd/ssd_pascal.py
ssd训练自己的数据集的更多相关文章
- SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证.本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注2 数据集的转换3 使用SSD如 ...
- 目标检测算法SSD之训练自己的数据集
目标检测算法SSD之训练自己的数据集 prerequesties 预备知识/前提条件 下载和配置了最新SSD代码 git clone https://github.com/weiliu89/caffe ...
- 目标检测算法SSD在window环境下GPU配置训练自己的数据集
由于最近想试一下牛掰的目标检测算法SSD.于是乎,自己做了几千张数据(实际只有几百张,利用数据扩充算法比如镜像,噪声,切割,旋转等扩充到了几千张,其实还是很不够).于是在网上找了相关的介绍,自己处理数 ...
- 【Tensorflow系列】使用Inception_resnet_v2训练自己的数据集并用Tensorboard监控
[写在前面] 用Tensorflow(TF)已实现好的卷积神经网络(CNN)模型来训练自己的数据集,验证目前较成熟模型在不同数据集上的准确度,如Inception_V3, VGG16,Inceptio ...
- 可变卷积Deforable ConvNet 迁移训练自己的数据集 MXNet框架 GPU版
[引言] 最近在用可变卷积的rfcn 模型迁移训练自己的数据集, MSRA官方使用的MXNet框架 环境搭建及配置:http://www.cnblogs.com/andre-ma/p/8867031. ...
- caffe训练自己的数据集
默认caffe已经编译好了,并且编译好了pycaffe 1 数据准备 首先准备训练和测试数据集,这里准备两类数据,分别放在文件夹0和文件夹1中(之所以使用0和1命名数据类别,是因为方便标注数据类别,直 ...
- 使用yolo3模型训练自己的数据集
使用yolo3模型训练自己的数据集 本项目地址:https://github.com/Cw-zero/Retrain-yolo3 一.运行环境 1. Ubuntu16.04. 2. TensorFlo ...
- Win10中用yolov3训练自己的数据集全过程(VS、CUDA、CUDNN、OpenCV配置,训练和测试)
在Windows系统的Linux系统中用yolo训练自己的数据集的配置差异很大,今天总结在win10中配置yolo并进行训练和测试的全过程. 提纲: 1.下载适用于Windows的darknet 2. ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
随机推荐
- HubbleDotNet引擎查询技术
系统简介 HubbleDotNet 是一个基于.net framework 的开源免费的全文搜索数据库组件.开源协议是 Apache 2.0.HubbleDotNet提供了基于SQL的全文检索接口,使 ...
- Java 内部类理解
为什么使用内部类? 答:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响. 内部类有哪些? 答:内部类一般来说包括这四种:成员内部类.局 ...
- 3.jeesite主从表开发
1. 2 3. 4. 5. 6. 7. 8. 9. 10.
- nginx中查看关于php的配置和php-fpm的重启等操作
1.查看当前使用的php的配置信息 在php项目的根目录下新建findini.php文件,内容如下: <?php phpinfo(); ?> 然后在页面上访问就可以看到如下页面: 搜索Lo ...
- UVa 12718 Dromicpalin Substrings (暴力)
题意:给定一个序列,问你它有多少上连续的子串,能够重排后是一个回文串. 析:直接暴力,n 比较小不会超时. 代码如下: #pragma comment(linker, "/STACK:102 ...
- E20170523-hm
parse vt. 从语法上描述或分析(词句等); escape character エスケープ文字 转义符 arity [计] 数量; analyzevt. <美>分析; 分解; ...
- vue按需加载组件,异步组件
说实话,我一开始也不知道什么叫按需加载组件,组件还可以按需加载???后来知道了 学不完啊...没关系,看我的 按需加载组件,或者异步组件,主要是应用了component的 is 属性 template ...
- hibernate简单实现连接数据库,并实现数据的操作
1:创建实体类 package com.yinfu.entity; public class User { private int id; private String username; priva ...
- 洛谷 P2312 解方程
题目 首先,可以确定的是这题的做法就是暴力枚举x,然后去计算方程左边与右边是否相等. 但是noip的D2T3怎么会真的这么简单呢?卡常卡的真是熟练 你需要一些优化方法. 首先可以用秦九韶公式优化一下方 ...
- mac下 netbeans 8.02中文版设置代码自动补齐 + eclipse自动补齐
netbeans自带的自动补齐快捷键是commad+\ 我想要的是在输入的时候,有自动提示,找了半天也没找到怎么搞. 因为我是用的mac系统 后来参考其他的设置,找到了设置的方法,把这个方法记录一下. ...