how to avoid over-fitting?(机器学习中防止过拟合的方法,重要)
methods to avoid overfitting:
- Cross-Validation : Cross Validation in its simplest form is a one round validation, where we leave one sample as in-time validation and rest for training the model. But for keeping lower variance a higher fold cross validation is preferred.
- Early Stopping : Early stopping rules provide guidance as to how many iterations can be run before the learner begins to over-fit.
- Pruning : Pruning is used extensively while building CART models. It simply removes the nodes which add little predictive power for the problem in hand.
- Regularization : This is the technique we are going to discuss in more details. Simply put, it introduces a cost term for bringing in more features with the objective function. Hence, it tries to push the coefficients for many variables to zero and hence reduce cost term.
参考:
https://www.analyticsvidhya.com/blog/2015/02/avoid-over-fitting-regularization/
1、获取更多数据:解决过拟合最有效的方法
从数据源头获取更多数据
根据当前数据集估计数据分布参数,使用该分布产生更多数据
数据增强(Data Augmentation):通过一定规则扩充数据,比如图像平移、翻转、缩放、切割等
2、改变模型网络结构Architecture
减少网络的层数、神经元个数等均可以限制网络的拟合能力
3、Early stopping
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
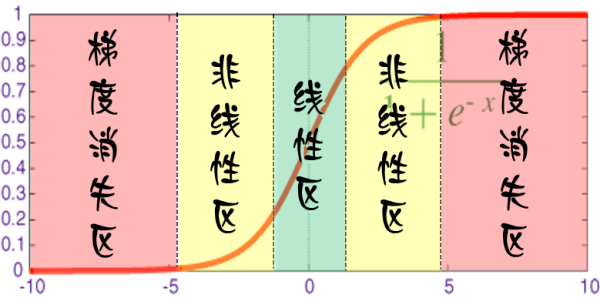
当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。因为我们在初始化网络的时候一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
3、正则化
4、增加噪声
1)在输入中增加噪声
2)在权值上增加噪声:在初始化网络的时候,用0均值的高斯分布作为初始化。
5、bagging:以随机森林(Rand Forests)为例,就是训练了一堆互不关联的决策树。但由于训练神经网络本身就需要耗费较多自由,所以一般不单独使用神经网络做Bagging。
6、boosting:既然训练复杂神经网络比较慢,那我们就可以只使用简单的神经网络(层数、神经元数限制等)。通过训练一系列简单的神经网络,加权平均其输出。
7、dropout
https://www.zhihu.com/question/59201590
how to avoid over-fitting?(机器学习中防止过拟合的方法,重要)的更多相关文章
- 机器学习中jupyter lab的安装方法以及使用的命令
安装JupyterLab使用pip安装: pip install jupyterlab# 必须将用户级目录添加 到环境变量才能启动pip install --userbinPATHjupyter la ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- MIT一牛人对数学在机器学习中的作用给的评述
MIT一牛人对数学在机器学习中的作用给的评述 转载自http://my.oschina.net/feedao/blog/52252,不过这个链接也是转载的,出处已经无从考证了. 感觉数学似乎总是不 ...
- 机器学习中的相似性度量(Similarity Measurement)
机器学习中的相似性度量(Similarity Measurement) 在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间 ...
- paper 127:机器学习中的范数规则化之(二)核范数与规则项参数选择
机器学习中的范数规则化之(二)核范数与规则项参数选择 zouxy09@qq.com http://blog.csdn.net/zouxy09 上一篇博文,我们聊到了L0,L1和L2范数,这篇我们絮叨絮 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数
L1正则会产生稀疏解,让很多无用的特征的系数变为0,只留下一些有用的特征 L2正则不让某些特征的系数变为0,即不产生稀疏解,只让他们接近于0.即L2正则倾向于让权重w变小.见第二篇的推导. 所以,样本 ...
随机推荐
- redis:高可用分析
https://www.cnblogs.com/xuning/p/8464625.html 基于内存的Redis应该是目前各种web开发业务中最为常用的key-value数据库了,我们经常在业务中用其 ...
- nginx目录结构和配置文件
nginx软件功能模块说明 Nginx软件之所以强大,是因为它具有众多的功能模块,下面列出了企业常用的重要模块. (1) Nginx核心功能模块(Core functionality)nginx核心功 ...
- Vue—事件修饰符
Vue事件修饰符 Vue.js 为 v-on 提供了事件修饰符来处理 DOM 事件细节,如:event.preventDefault() 或 event.stopPropagation(). Vue. ...
- 【xdebug】 windows xdebug 配置
[xdebug] zend_extension = C:\phpStudy\php53n\ext\php_xdebug-2.6.1-7.0-vc14-nts-x86_64.dllxdebug.idek ...
- Spring,Mybatis,Springmvc框架整合项目(第二部分)
一.创建数据库表 打开Navicat Premium,点击左上角连接,选择mysql 输入你的数据库用户名和密码信息,可以先点击下测试连接,如果显示连接成功,说明能连接到数据库,然后点击确定.如果 ...
- Java web 服务启动时Xss溢出异常处理笔记
本文来自网易云社区 作者:王飞 错误日志 错误日志要仔细看,第一行不一定就是关键点,这个错误出现的时候,比较靠后,其中关键行就是下面这句. Caused by: java.lang.IllegalSt ...
- 大数据学习——sqoop安装
1上传 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 2解压 .bin__hadoop--alpha.tar.gz 3重命名 .bin__hadoop--al ...
- wordpress无法登录的解决方法
使用wordpress建站的朋友可能会遇到wordpress管理密码,有时甚至是正确的密码,但是多次尝试输入都无法登录,并且输入用户名和输入电子邮件都无法获取密码,遇到这种情况怎么办,本文教你如何处理 ...
- z作业二总结
这是我的第二次作业,之前在课上所学的我发现已经忘得差不多了,这次的作业让我做的非常累,感觉整个人生都不太好了. 作业中的知识点:int(整型) float(单精度) double(双精度) char( ...
- tab栏切换效果
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...