spark core (二)
一、Spark-Shell交互式工具
1、Spark-Shell交互式工具
Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具。
在Scala语言环境下或Python语言环境下均可使用。
启动Spark-Shell
./bin/spark-shell 本地模式,线程数为1(1个CPU)
./bin/spark-shell --master
./bin/spark-shell --master local[2] //使用2个CPU核运行
./bin/spark-shell --master local[2] --jar testcode.jar //指定Jar包路径
./bin/spark-shell --master spark://liuwei3:7077
在Spark-Shell中已经创建了一个名为sc的SparkContext对象
--master用来设置context将要连接并使用的资源主节点, master的值可以是Standalone模式 的Spark集群地址、 Mesos或Yarn集群的URL, 或者是一个local地址。
使用--jar可以添加Jar包的路径, 使用逗号分隔可以添加多个包
Spark-Shell的本质是在后台调用了spark-submit脚本来启动应用程序。
2、Spark-Shell操作案例
收集到数据后, 需要对数据进行各种数据处理, 包括数据的抽取-转换-装载( Extract-Transform-Load, ETL) 、 数据统计、 数据挖掘, 以 及为后续的数据呈现和为决策而提供的数据持久化。
本案例数据处理过程, 包含了对外部文件的加载, 对文件数据的转换、 过滤、 各种数据统计, 以及处理结果的存储。
加载文件 :
Spark创建sc之后, 可以加载本地文件创建RDD, 返回一个MapPartitionsRDD
val textFile=sc.textFile(“file:///*****/README.md”)
加载HDFS文件和本地文件都是使用textFile( ), 区别是添加前缀进行标识, hdfs://或file:///
从本地读取的文件返回MapPartitionsRDD
从HDFS读取的文件先转成HadoopRDD, 然后隐式转换成MapPartitonsRDD
MapPartitionsRDD和HadoopRDD都是基于Spark的弹性分布式数据集RDD
执行Transformation操作返回新RDD:
texfFile.first() //获取RDD文件的第一行
textFile.count() //获取RDD文件的行数
val textRDD=textFile.filter(line=>line.contains(“Spark”)) //过滤出包含Spark的行, 并返回新RDD
textFile.filter(line=>line.contains(“Spark”)).count() //链接多个Transformation和Action操作
找出文本中每行最多的单词数
textFile.map(line=>line.split(“ ”).size).reduce((a,b)=>if(a>b) a else b)
首先将textFile的每一行文本使用split(“ ”)进行分词, 并统计分词后的单词数, 然后执行reduce操作, 使 用(a,b)=>if(a>b) a else b 进行比较, 返回最大值
词频统计
val wordCount=textFile.flatMap(line=>line.split(“ ”)).map(word=>(word,1)).reduceByKey((x,y)=>x+y)
wordCount.collect()
结合flatMap、 Map和reduceByKey来计算文件中每个单词的词频, 并返回(String,Int)类型的 键值对ShuffleRDD, 最后使用collect()聚合单词计数结果。
如果想让代码更简洁, 可以使用占位符”_”。
当每个参数在函数文本中最多出现一次的时候, 可以使用下划线_+_扩展成带两个参数的函数文本。
多个下划线指代多个参数, 而不是单个参数的重复使用。 第一个下划线代表第一个参数, 第二个下划线 代表第二个参数。
val wordCount=textFile.flatMap(_.split(“ ”)).map((_,1)).reduceByKey(_+_)
Spark默认是不进行排序的, 可以使用sortByKey按照Key进行排序, false为降序, true为升序。
val wordCount=textFile.flatMap(_.split(“ ”)).map((_,1)).reduceByKey(_+_).map(m=>(m._2,m._1)).sortByKey(false).map(m=>(m._2,m._1))
其中, m=>(m._2,m._1)实现key和value互换。
wordCount.saveAsTextFile(“hdfs://tgmaster:9000/out/wordcount”) //保存文件
RDD缓存(内存持久化)
Spark支持将数据集存进内存缓存中, 当数据被反复访问时, 是非常有用的。
textFile.cache() //通过cache缓存数据可用于非常大的数据集, 支持跨越几十或几百个节点。 或者textFile.persist() 清除缓存:textFile.unpersist()
textFile.count()
.collect()作用:将计算结果从集群中获取到本地内存来显示,容易发生OOM(内存溢出)所以collect只适合结果数据量较小的情况,如果计算结果数据量很大,此时要用foreach()输出
2、操作案例
//加载文件
val lines=sc.textFile("file:///home/tg/datas/ws")
val lines2=sc.textFile("hdfs://tgmaster:9000/in/ws")
//统计文件的行数
lines.count
//查询文件第一行的数据
lines.first
//过滤出包含"spark"的行
val result1=lines.filter(line=>line.contains("spark"))
//包含"spark"关键词的行数
result1.count
//统计出每行最多的单词数
lines.map(line=>line.split(" ").size)
.reduce((x,y)=> if (x>y) x else y) //单词统计计数(WordCount),根据次数进行降序排列
vla result=lines.flatMap(x=>x.split(" ")) //对单词进行分隔
.map(x=>(x,1)) //将分隔后的单词进行统计,形成键值对(word,1)
.reduceByKey((x,y)=>x+y) //对key进行分组,然后统计Value值
====方法二=======
.sortBy(_._2,false) ====方法一=====
.map(x=>(x._2,x._1)) //(次数,单词)
.sortByKey(false) //默认true升序,false降序
.map(x=>(x._2,x._1)) //(单词,次数) //将计算结果从集群中获取到本地内存来显示,
//容易发生OOM(内存溢出),所以collect只适合结果数据量较小的情况,
//如果计算结果数据量很大,此时要用foreach()输出
.collect
//将最终的单词统计结果保存到HDFS上
result.saveAsTextFile("hdfs://tgmaster:9000/out/wsresult") 3、RDD缓存(内存持久化)
result.cache() //缓存到内存
result.persist()//同上
result.unpersist()//清除缓存
二、SparkContext与部署模式
1、 SparkContext
SparkContext, Spark上下文
独立应用程序需要初始化一个SparkContext作为程序的一部分, 然后将一个包含应 用程序信息的SparkConf对象传递给SparkContext构造函数。
创建SparkContext对象:
scala方式:
def main(args: Array[String]): Unit = {
//第一步:创建SparkConf对象
val conf=new SparkConf().setAppName("WordCount")
.setMaster("local")
//第二步:创建SparkContext对象
val sc=new SparkContext(conf)
//第三步:可以从linux或者HDFS中获取数据
val lines=sc.textFile("hdfs://tgmaster:9000/in/resws")
//第四大步:进行单词统计计数
val result=lines.flatMap(_.split(" "))
.map((_,1)).reduceByKey(_+_)
.sortBy(_._2,false)
//第五步:将计算结果保存到HDFS中
// result.saveAsTextFile("hdfs://liuwei1:9000/out/res2")
// result.collect()
//通过foreach算子输出单词与次数
result.foreach(x=>println(x._1+" "+x._2))
}
JAVA方式:
setMaster()用于设置运行的master上的URL,如果程序在本地运行,需要设置为local或local[N](N>2),如果程序需要打包运行在集群中,那么在代码中就不需要设置setMaster()
SparkContext,即为Spark上下文,它包含在Driver驱动程序中,Spark程序的运行离不开SparkContext
Scala开发spark对应的是sparkcontext;Java开发spark对应的是Javasparkcontext
创建sparkcontext对象,需要sparkConf对象作为参数
package day1; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2;
/**
* 用Java开发Spark的WordCount
* @author Administrator
*
*/
public class WordCount {
public static void main(String[] args) {
//第一步:创建SparkConf对象
SparkConf conf=new SparkConf().setAppName("WordCount")
.setMaster("local");
//第二步:创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
//第三步:从HDFS中加载数据,生成JavaRDD<String>
从HDFS等外部数据源创建程序中第一个RDD,即为初始RDD。
创建初始RDD有两种方式:通过HDFS等外部数据源中创建;通过并行集合的方式创建(例:val )
JavaRDD<String> lines = sc.textFile("hdfs://tgmaster:9000/in/resws");
//第四步:分隔单词
flatmap:先map,后flatten
flatMap算子中,通常有一个String类型的参数,同时具有集合Iterable<T>类型的返回值
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L; public Iterable<String> call(String line) throws Exception {
// TODO Auto-generated method stub
return Arrays.asList(line.split(" "));
}
});
//第五步:将分隔后的每个单词出现次数记录为1,形成键值对<单词,1>
用JAVA开发Spark,如果需要通过映射的方式产生键值对,此时要用到mapToPair算子,这一点与scala开发spark不一样,在scala中只有map算子,没有maoToPair算子。
mapToPair 算子中有一个String类型
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception {
// TODO Auto-generated method stub
return new Tuple2<String, Integer>(word, 1);
}
});
//第六步:通过reduceByKey()算子统计每个单词出现的次数
reduceBykey 这个算子很重要,它有两个Integer类型的参数,返回值是Integer
它的运行过程是,先在本地按照key值进行聚合,然后再全局范围再按照key值进行聚合,他的性能比groupBykey强很多
JavaPairRDD<String, Integer> result = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L; public Integer call(Integer num1, Integer num2) throws Exception {
// TODO Auto-generated method stub
return num1+num2;
}
});
//第七步:通过foreach()算子输出最终结果
result.foreach(new VoidFunction<Tuple2<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L; public void call(Tuple2<String, Integer> info) throws Exception {
// TODO Auto-generated method stub
System.out.println(info._1+"出现了"+info._2);
}
});
}
}
2、Spark部署模式
查看本地电脑cpu是几核,通过任务管理器,性能,CPU使用记录有几个框就是几核
Local本地模式: 运行于本地
spark-shell --master local[2]
local[2]是说, 执行Application需要用到CPU的2个核
Standalone独立模式: Spark自带的一种集群模式
Spark自己管理集群资源, 此时只需要将Hadoop的HDFS启动,(不需要启动yarn)
Master节点有master,Slave节点上有worker
启动 ./bin/spark-shell --master spark://master:7077
YARN模式
Spark自己不管理资源, 向YARN申请资源, 所以必须保证YARN是启动起来的
操作步骤:
启动Hadoop:到Hadoop目录执行start-all.sh
到Spark目录, ./bin/spark-shell --master yarn-client( yarn-cluster)
yarn-client运行在测试环境 yarn-cluster运行在真实环境
以上三种都是集群模式
IDEA中生成Jar包, 使用IDEA编译class文件, 同时将class打包成Jar文件。
File——Project Structure, 弹性“Project Structure”的设置对话框
选择左边的Artifacts, 点击上方的“+”按钮
在弹出的对话框中选择“Jar”——“from moduls with dependencies”
选择要启动的类, 然后确定 (删除SparkApps.jar下的所有jar包)
应用之后选择菜单“Build”——“Build Artifacts”, 选择“Build”或“Rebuild”即可生成
如果重新打包的话,删除src下的META-INF
Spark提交Job:
./spark-submit \
--class newScala.Test \
--master yarn-cluster \
/home/hadoop/Test.jar (剩下的可以写,也可以不写)

3、Spark部署模式—Master URL格式及说明
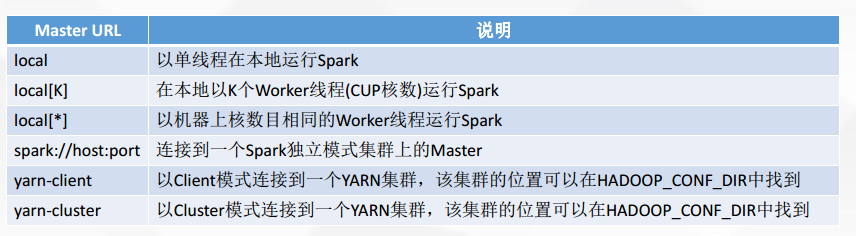
yarn-client运行在客户端本地,yarn-cluster运行在ApplicationMaster所在的集群节点中
三、RDD弹性分布式数据集
1、RDD弹性分布式数据集 (RDD既可以放在内存中,也可以放在磁盘中,优先放在内存中,内存放不下,再考虑放在磁盘中;分区分布在很多节点上;partition真正存放数据的地方,partition在内存中)(默认情况下,文件在HDFS上有几个block块,初始RDD就有几个分区)
RDD是Spark提供的核心抽象, 全称为Resillient Distributed Dataset, 即弹性分布式数 据集。
RDD在抽象上来说是一种元素集合, 包含了数据。 它是被分区的, 分为多个分区。 每个分区分布在集群中的不同节点上, 从而让RDD中的数据可以被并行操作。 ( 分布 式数据集)
RDD通常通过Hadoop上的文件, 即HDFS文件或者Hive表, 来进行创建, 也可以通过 应用程序中的集合来创建。
RDD最重要的特性就是, 提供了容错性, 可以自动从节点失败中恢复过来。 如果某个 节点上的RDD partition, 因为节点故障, 导致数据丢了, 那么RDD会自动通过 数据来源重新计算该partition。
Spark的容错机制:1、lineage(血统) 2、checkpoint(检查点)
RDD的数据默认情况下存放在内存中的, 但是在内存资源不足时, Spark会自动将 RDD数据写入磁盘。 ( 弹性)
2、RDD的定义
一个RDD对象, 包含如下5个核心属性:
一个分区列表, 每个分区里是RDD的一部分数据( 或称数据块) ;(每个分区保持相对均衡,不是绝地均衡)
一个依赖列表, 存储依赖的其他RDD;(RDDA经过算子产生RDDB,RDDB依赖RDDA)
一个名为computer的计算函数, 用于计算RDD各分区的值;
分区器( 可选) , 用于键/值类型的RDD, 比如某个RDD是按散列来分区;
计算各分区时优先的位置列表( 可选) , 比如从HDFS上的文件生成RDD时, RDD分区的位置优先选择数据所在的节点, 这样可以避免数据移动带来的开销。
前三个是必须 ,后两个是可选的
四、创建RDD
1、创建RDD
进行Spark核心编程时, 首先要做的第一件事, 就是创建一个初始的RDD。
该RDD中, 通常包含了Spark应用程序的输入源数据。
在创建了初始的RDD之后, 才可以通过Spark Core提供的transformation算子, 对该RDD进 行转换获取其他的RDD。
Spark Core提供了三种创建RDD的方式, 包括:
使用程序中的集合创建RDD
使用本地文件创建RDD或使用HDFS文件创建RDD
RDD通过算子形成新的RDD
(前两种创建初始RDD)
经验总结:
使用程序中的集合创建RDD, 主要用于进行测试, 可以在实际部署到集群运行之前, 自 己使用集合构造测试数据, 来测试后面的Spark应用的流程。
使用本地文件创建RDD, 主要用于临时性地处理一些存储了大量数据的文件。
使用HDFS文件创建RDD, 应该是最常用的生产环境处理方式, 主要可以针对HDFS上 存储的大数据, 进行离线批处理操作。
2、并行化集合创建RDD
如果要通过并行化集合来创建RDD, 需要针对程序中的集合, 调用SparkContext的parallelize()方法。 Spark会将集合中的数据拷贝到集群上去, 形成一个分布式的数据集合, 也就是一个RDD。
相当于集合中的一部分数据会到一个节点上, 而另一部分数据会到其他节点上, 然后就可以用并行的方 式来操作这个分布式数据集合, 即RDD。
案例: 1到10累加求和
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val rdd = sc.parallelize(arr)
val sum = rdd.reduce(_ + _)
调用parallelize()时, 有一个重要的参数可以指定, 就是要将集合切分成多少个partition。 Spark会为每一个partition运行一个task来进行处理。
Spark默认会根据集群的情况来设置partition的数量, 但是也可以在调用parallelize()方法时, 传入第二个 参数, 来设置RDD的partition数量。 比如parallelize(arr, 10)
3、使用本地文件和HDFS创建RDD
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的, 比如说 HDFS、 Cassandra、 HBase以及本地文件。
通过调用SparkContext的textFile()方法, 可以针对本地文件或HDFS文件创建 RDD。
注意:
Spark的textFile()方法支持针对目录、 压缩文件以及通配符进行RDD创建。
Spark默认会为hdfs文件的每一个block创建一个partition, 但是也可以通过textFile() 的第二个参数手动设置分区数量, 只能比block数量多, 不能比block数量少。
案例: 文件字数统计
val rdd = sc.textFile("data.txt")
val wordCount = rdd.map(line => line.length).reduce(_ + _)
Spark的textFile()除了可以针对上述几种普通的文件创建RDD之外, 还有一些特列 的方法来创建RDD:
SparkContext.wholeTextFiles()方法, 可以针对一个目录中的大量小文件, 返 回<filename, fileContent>组成的pair, 作为一个PairRDD, 而不是普通的RDD。
普通的textFile()返回的RDD中, 每个元素就是文件中的一行文本。
SparkContext.sequenceFile[K, V]()方法, 可以针对SequenceFile创建RDD, K和V泛型类型就是SequenceFile的key和value的类型。 K和V要求必须是
Hadoop的序列化类型, 比如IntWritable、 Text等。
SparkContext.hadoopRDD()方法, 对于Hadoop的自定义输入类型, 可以创建 RDD。 该方法接收JobConf、 InputFormatClass、 Key和Value的Class。
SparkContext.objectFile()方法, 可以针对之前调用RDD.saveAsObjectFile() 创建的对象序列化的文件, 反序列化文件中的数据, 并创建一个RDD。
1、并行化集合创建RDD
val array=Array(1,2,3,4,5,6)
//没有指定rdd的分区,此时默认为程序所分配的资源的CPU核数
val rdd=sc.parallelize(array)
//指定rdd2中有3个分区
val rdd2=sc.parallelize(array,3)
2、从外部数据源创建RDD
//此时没有指定分区,
//那么分区数就等于文件在HDFS上存储的Block数。
val lines=sc.textFile("hdfs路径")
//指定了lines中有2个分区
//设置的分区数,只能比Block多,不能比它少。
val lines=sc.textFile("hdfs路径",2)
3、通过Transformation(转换)类型的算子产生新的RDD
val result=lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
但是下面两个算子是Action(行动)类型。
result.collect
result.foreach(println)
五、RDD操作
RDD操作:创建操作、 转换操作(transformation)、 行动操作 (Action)、 控制操作(缓存到内存,也称内存持久化)
在spark中transformation类型的算子,系统只是记录下了这个操作行为,但这个行为并没有被执行。当程序遇到一个action类型的算子时,会触发Job的提交运行, 此时Action算子之前所有
transformation类型的算子就会被执行。 (saveAsTextFile、reduce是Action,reduceByKey是transformation,之前的textfile map sortBy等等都是transformation)
1、transformation和action介绍
Spark支持两种RDD操作: transformation和action。
transformation操作会针对已有的RDD创建一个新的RDD;
action则主要是对RDD进行最后的操作, 比如遍历、 reduce、 保存到文件等, 并可以返回结果给Driver程序。
例如:
map就是一种transformation操作, 它用于将已有RDD的每个元素传入一个自定义的函数, 并获取一个新的元素, 然后将所有的新元素组成一个新的RDD。
reduce就是一种action操作, 它用于对RDD中的所有元素进行聚合操作, 并获取一个最终的结果, 然后返回给Driver 程序。
transformation的特点就是lazy特性。
lazy特性指的是, 如果一个spark应用中只定义了transformation操作, transformation是不会触发Spark程序的执行的,它们只是记录了对RDD所做的操作, 但是不会自发的执行。
只有当执行了一个action操作之后, 所有的transformation才会执行。
Spark通过这种lazy特性来进行底层的Spark应用执行的优化, 避免产生过多中间结果。
action操作执行, 会触发一个spark job的运行, 从而触发这个action之前所有的transformation的执行。
这是action的特性。
2、案例:统计文件字数
// 这里通过textFile()方法, 针对外部文件创建了一个RDD lines, 但是实际上, 程序执行到这里为止, spark.txt文件的数据是不会加载到内存中的。 lines, 只是代表了一个指向
spark.txt文件的引用。 val lines = sc.textFile("spark.txt")
// 这里对lines RDD进行了map算子, 获取了一个转换后的lineLengths RDD, 但是这里连数据都没有, 当然
也不会做任何操作。 lineLengths RDD也只是一个概念上的东西而已。
val lineLengths = lines.map(line => line.length)
// 之后, 执行了一个action操作, reduce。 此时就会触发之前所有transformation操作的执行, Spark会将操 作拆分成多个task到多个机器上并行执行, 每个task会在本地执行map操作,
并且进行本地的reduce聚合。 最后会进行一个全局的reduce聚合, 然后将结果返回给Driver程序。 val totalLength = lineLengths.reduce(_ + _)
3、常用transformation介绍

reduceByKey:现在本地进行聚合,再全局聚合,性能比 groupBykey好
groupByKey:全局聚合
4、常用action介绍

Spark运行原理(初级版):
DAG有向无环图——DAGScheduler,Stage阶段(stage划分算法)
——TaskSet——TaskScheduler,
把task任务(task分配算法)发送到Work节点中的Executor去执行
---Executor接收到task之后,会从线程池中取出相应的线程去执行接收到的task任务
补充:
1、hadoop 1.x:
HDFS:namenode(1个) 、datanode(多个)
MapReduce:
JobTracker(1个):与用户通信,接收用户提交的Application;将Application划分为很多的任务(Task),分配多个TaskTracker去执行;管理调度集群中的资源
TaskTracker(多个):执行JobTracker分配的任务
hadoop1.x缺陷:单点故障、
hadoop 2.x:
HDFS:提出HA高可靠概念 (两个namenode,一个负责读,一个负责写)
MapReduce
Yarn:管理调度集群中的资源
spark core (二)的更多相关文章
- 大数据笔记(二十七)——Spark Core简介及安装配置
1.Spark Core: 类似MapReduce 核心:RDD 2.Spark SQL: 类似Hive,支持SQL 3.Spark Streaming:类似Storm =============== ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- 上万字详解Spark Core(建议收藏)
先来一个问题,也是面试中常问的: Spark为什么会流行? 原因1:优秀的数据模型和丰富计算抽象 Spark 产生之前,已经有MapReduce这类非常成熟的计算系统存在了,并提供了高层次的API(m ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
随机推荐
- TensorFlow深度学习实战---MNIST数字识别问题
1.滑动平均模型: 用途:用于控制变量的更新幅度,使得模型在训练初期参数更新较快,在接近最优值处参数更新较慢,幅度较小 方式:主要通过不断更新衰减率来控制变量的更新幅度. 衰减率计算公式 : deca ...
- perf + 火焰图用法 小结
要对新服务做性能测试,分析代码热点,初识perf,做下总结 perf + 火焰图用法 perf简介 Perf (Performance Event), Linux 系统原生提供的性能分析工具, 会返回 ...
- kubeadm构建k8s之Prometheus-operated监控(0.18.1)
介绍: 大家好,k8s的搭建有许多方式,也有许多快速部署的,为了简化部署的复杂度,官方也提供了开源的kubeadm快速部署,最新1.10.x版本已经可以实现部署集群, 如果你对k8s的原理已经非常了解 ...
- dede 后台登录以后一片空白
网上说的是 找到:include/common.inc.php文件,打开,查找程序代码: //error_reporting(E_ALL); error_reporting(E_ALL || ~E_ ...
- 微软职位内部推荐-Software Engineer II_HPC
微软近期Open的职位: Job Title: Software Engineer II_HPC Location: Shanghai, China Are you passionate about ...
- VisualSVN Server的迁移
VisualSVN Server迁移涉及到两种情况: 第一种情况:VisualSVN Server没有更换电脑或者服务器,只是修改Server name. 第二种情况:当VisualSVN Serve ...
- sqoop 常用命令集
sqoop是一个介于分布式数据系统与关系型系统之间数据转换的一个数据转换工具 常用命令集sqoop2中sqoop-shell 创建link.job sqoop:001> show link 显示 ...
- CS小分队第一阶段冲刺站立会议(5月13日)
昨日成果:昨日由于课程满课,未进行项目的制作 遇到困难:/ 今天计划:为2048和扫雷添加游戏音效,和组员一起合作对扫雷进行外观美化,学习程序生成时渐隐等特效
- IT小小鸟 读书笔记
讲真的,整本书我并没有看完,翻阅了一下,然后小小的借鉴了一下! 首先设计你自己的进度条 进度条的设计是一个很多人都知道的故事:同样的耗时,如果不给任何进度提示,只是在完成之后才弹出一个完成消息,中间没 ...
- (转)ActiveMQ的重连机制
花了一天的时间,终于搞明白了我的疑问. failover://(tcp://localhost:6168)?randomize=false&initialReconnectDelay=100& ...