为什么需要消息队列MQ?
主要原因:是在高并发情况下,由于来不及同步处理,请求往往会发生堵塞,比如诸多的insert、update之类的请求同时到达mysql,直接导致无数的行锁表锁,甚至最后请求会堆积很多,从而触发大量的too mang connnections错误。通过消息队列,我们可以异步处理请求,从而缓解系统的压力。
MQ(message queue)是一种跨进程的通信机制,用于上下游传递消息。
mq的特点:
1、先进先出
不能先进先出,都不能说是队列了,消息队列的顺序在入队时基本已经确定,一般是不需要人工干预的。而且最重要的是,数据是只有一条数据在使用中,这也是mq在众多场景中被使用的原因。
2、发布订阅
发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当做是同步操作。这种处理方式能非常有效的提升服务器利用率,这样的应用场景非常广泛。
3、持久化
持久化确保MQ的使用不只是一个部分场景的辅助工具,而是让MQ能像数据库一样存储核心的数据。
4、分布式
在现在大流量、大数据的使用场景下,只支持单体应用的服务器软件基本是无法使用的,支持分布式的部署,才能被广泛使用。而且,MQ的定位就是一个高性能的中间件。
应用场景
基于上文所述的特点,那么MQ就衍生出了很多的使用场景,在大型的系统中,应用非常广泛,这里我们就列举一下常见的应用场景。
应用解耦(异步)
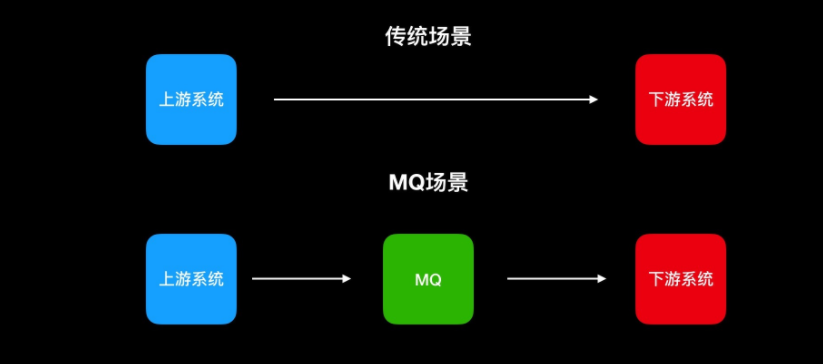
系统之间进行数据交互时,在时效性和稳定性之间我们都要进行选择;基于线程的异步处理,能确保用户体验,但在极端情况下,可能会出现异常,影响系统的稳定性,而同步调用很多时候无法保证理想的性能,那么我们就可以用mq来进行处理,上游系统将数据投递到mq,下游系统取mq的数据进行消费,投递和消费可以用同步的方式处理,因为mq接收数据的性能是非常高的,不会影响上游系统的性能,那么下游系统的及时率能保证吗?当然可以,不然就不会有下面的一个应用场景。
通知
这里就用到了前文一个重要的特点,发布订阅,下游系统一直在监听MQ的数据,如果MQ有数据,下游系统则会按照 先进先出 这样的规则, 逐条进行消费 ,而上游系统只需要将数据存入MQ里,这样既降低了不同系统之间的耦合度,同时也确保了消息通知的及时性,而且也不影响上游系统的性能。
限流
上文有说了一个非常重要的特性,MQ 数据是只有一条数据在使用中。 在很多存在并发,而又对数据一致性要求高,而且对性能要求也高的场景,如何保证,那么MQ就能起这个作用了。不管多少流量进来,MQ都会让你遵守规则,排除处理,不会因为其他原因,导致并发的问题,而出现很多意想不到脏数据。
数据分发
MQ的发布订阅肯定不是只是简单的一对一,一个上游和一个下游的关系,MQ中间件基本都是支持一对多或者广播的模式,而且都可以根据规则选择分发的对象。这样上游的一份数据,众多下游系统中,可以根据规则选择是否接收这些数据,这样扩展性就很强了。
PS:上文中的上游和下游,在MQ更多的是叫做生产者(producer)和消费者(consumer)
分布式事务
分布式事务是我们开发中一直尽量避免的一个技术点,但是,现在越来越多的系统是基于微服务架构开发,那么分布式事务成为必须要面对的难题,解决分布式事务有一个比较容易理解的方案,就是二次提交。基于MQ的特点,MQ作为二次提交的中间节点,负责存储请求数据,在失败的情况可以进行多次尝试,或者基于MQ中的队列数据进行回滚操作,是一个既能保证性能,又能保证业务一致性的方案,当然,这个方案的主要问题就是定制化较多,有一定的开发工作量。
应用示例
为了更加直观的展示MQ的应用场景,这里我们就用一个常见的电商系统中的几个业务,来具体说明下MQ在实际开发中应用场景。
我们的实际场景大概是一个基于微服务架构的电商系统,分为用户微服务、商品微服务、订单微服务、促销微服务等。基于微服务模式开发的系统,MQ的使用场景更多,下面我们逐一说明:
1、注册后我们可能需要做很多初始化的操作,如:调用邮件服务器发送邮件、调用促销服务赠送优惠劵、下发用户数据到客户关系系统等。那么这时候我们将这些操作去监听MQ,当用户注册成功过后,通过MQ通知其他业务进行操作。确保注册用户的性能。
2、后台发布商品的时候,商品数据需要从数据库中转换成搜索引擎数据(基于elasticsearch),那么我们应该将商品写入数据库后,再写入到MQ,然后通过监听MQ来生成elasticsearch对应的数据。
3、用户下单后,24小时未支付,需要取消订单。以前我们可能是定时任务循环查询,然后取消订单。实际上,我更推荐类似延迟MQ的方式,避免了很多无效的数据库查询,将一个MQ设置为24小时后才让消费者消费掉,这样很大程度上能减轻服务器压力。
4、支付完成后,需要及时的通知子系统(进销存系统发货,用户服务积分,发送短信)进行下一步操作,但是,支付回调我们都是需要保证高性能的,所以,我应该直接修改数据库状态,存入MQ,让MQ通知子系统做其他非实时的业务操作。这样能保证核心业务的高效及时。
注意事项
其实,还有非常多的业务场景,是可以考虑用MQ方式的,但是很多时候,也会存在滥用的情况,我们需要清楚认识我们的业务场景:
发验证码短信、邮件,这种过分依赖外部,而且时效性可以接收几十秒延迟的,其实更好的方式是多线程异步处理,而不是过多依赖MQ。
秒杀抢购确保库存不为负数,更多的依赖高性能缓存(如redis),以及强制加锁,千万不要依赖消费者最终的返回结果。(实际工作中已经看到好几个这样的案例了)上游-下游 这种直接的处理方式效率肯定是比 上游-MQ-下游 方式要高,MQ效率高,是因为,我只是上游-MQ 这个阶段就当做已经成功了。
转自:https://www.cnblogs.com/pdd-666888/p/9447164.html
为什么需要消息队列MQ?的更多相关文章
- 为什么会需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 消息队列一:为什么需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 详解RPC远程调用和消息队列MQ的区别
PC(Remote Procedure Call)远程过程调用,主要解决远程通信间的问题,不需要了解底层网络的通信机制. RPC框架 知名度较高的有Thrift(FB的).dubbo(阿里的). RP ...
- 消息队列 MQ 入门理解
功能特性: 应用场景: 消息队列 MQ 可应用于如下几个场景: 分布式事务 在传统的事务处理中,多个系统之间的交互耦合到一个事务中,响应时间长,影响系统可用性.引入分布式事务消息,交易系统和消息队列之 ...
- 消息队列MQ简介
项目中要用到RabbitMQ,领导让我先了解一下.在之前的公司中,用到过消息队列MQ,阿里的那款RocketMQ,当时公司也做了简单的技术分享,自己也看了一些博客.自己在有道云笔记上,做了一些整理,但 ...
- 消息队列MQ集合
消息队列MQ集合 消息队列简介 kafka简介 Centos7部署zookeeper和Kafka集群 .
- 高并发系统:消息队列MQ
注:前提是知道什么是消息队列.不懂的去搜索各种消息队列入门(activeMQ.rabbitMQ.rocketMQ.kafka) 1.为什么要使用MQ?(MQ的好处:解耦.异步.削峰) (1)解耦:主要 ...
- java面试记录三:hashmap、hashtable、concurrentHashmap、ArrayList、linkedList、linkedHashmap、Object类的12个成员方法、消息队列MQ的种类
口述题 1.HashMap的原理?(数组+单向链表.put.get.size方法) 非线程安全:(1)hash冲突:多线程某一时刻同时操作hashmap并执行put操作时,可能会产两个key的hash ...
- 【消息队列MQ】各类MQ比较
目录(?)[-] RabbitMQ Redis ZeroMQ ActiveMQ JafkaKafka 目前业界有很多MQ产品,我们作如下对比: RabbitMQ 是使用Erlang编写的一个开源的消息 ...
- 消息队列mq的原理及实现方法
消息队列技术是分布式应用间交换信息的一种技术.消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走.通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置.或在继续执行前不需要等待 ...
随机推荐
- [Gradle] 发布构件到本地仓库
配置 需要发布构件的模块 build.gradle 加入如下配置 apply plugin: 'maven-publish' publishing { publications { mavenJava ...
- asp.net SessionState模式的配置及使用
由于项目dll文件变动比较频繁,而保存登陆的状态又保存在Session中,所以导致用户经常无故掉线(PS:dll变动的时候导致Session).有一种方法可以长期保存session,那就是sessio ...
- HI3518E用J-link烧写裸板fastboot u-boot流程
Hi3518E的裸板烧写fastboot是不能像HI3531那样,可以通过FB直接烧写.遵循ARM9的烧写流程.其中一般u-boot的烧写流程可分为几类:第一:通过编程器芯片直接烧写:第二通过RVDS ...
- Scanline Fill Algorithm
https://www.sccs.swarthmore.edu/users/02/jill/graphics/hw3/hw3.html http://web.cs.ucdavis.edu/~ma/EC ...
- 自动化工具构建vue项目
其实之前对vue的话也有过一段时间的学习,博客园也是写了5篇vue的学习笔记.但是一直是通过CDN的方式在html文件头部引入vue.js,然后实例化vue对象绑定Dom,写组件写方法.就算是在实际项 ...
- SQL Server 复制(Replication) ——事务复制搭建
本文演示如何搭建最基本的事务复制. 环境准备: 虚拟机2台: 服务器名分别为RepA和RepB,RepA为发布服务器,RepB为订阅服务器.均安装WindowsServer 2008R2英文版(在外企 ...
- 有关Oracle统计信息的知识点
一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如,表的行数,块数,平均每行的大小,索引的leaf blocks,索引字段的行数,不同值的大小等,都属于 ...
- postman设置环境变量,字段值经过json转换后数值字节长度超过上限的问题
在使用Tests进行环境变量的设置时,遇到这么一种情况,在返回的responseBody中的userId字段,字段返回的是数值类型,再经过json转换之后,发现保存的值跟接口返回的值不一致:如下图: ...
- java基础语法 List
List:元素是有序的(怎么存的就怎么取出来,顺序不会乱),元素可以重复(角标1上有个3,角标2上也可以有个3)因为该集合体系有索引, ArrayList:底层的数据结构使用的是数组结构(数组长度是可 ...
- spring-data-jpa 介绍 复杂查询,包括多表关联,分页,排序等
本篇进行Spring-data-jpa的介绍,几乎涵盖该框架的所有方面,在日常的开发当中,基本上能满足所有需求.这里不讲解JPA和Spring-data-jpa单独使用,所有的内容都是在和Spring ...