Hadoop1.1.2伪分布式安装
设置Linux的静态IP
修改VirtualBox的虚拟网卡地址
修改主机名
把hostname和ip绑定
关闭防火墙:service iptables stop
二、SSH免密码登陆
生成秘钥文件
测试免密码登陆是否成功
三、安装JDK
1. 授予执行权限
2. 解压缩
3. 配置环境变量
4. 测试安装
四、安装Hadoop
1、解压缩hadoop-1.1.2.tar.gz
2、添加到环境变量中
3、使设置立即生效
4、修改hadoop的配置文件
配置hadoop-env.sh
配置core-site.xml
配置hdfs-site.xml
配置mapred-site.xml
配置masters
配置slaves
5、格式化NameNode
五、测试Hadoop安装是否成功
启动Hadoop
消除start-all.sh时候的警告信息
通过jps命令查看Hadoop的5个守护进程
登陆WEB管理页面
HDFS的管理页面
MapReduce的管理页面
一、安装前准备
本次安装所使用软件:
虚拟机:VirtualBox-4.3.8-92456-Win.exe
JDK:jdk-6u24-linux-i586.bin
Hadoop:hadoop-1.1.2.tar.gz
Linux版本:CentOS-5.5-i386-bin-DVD.iso
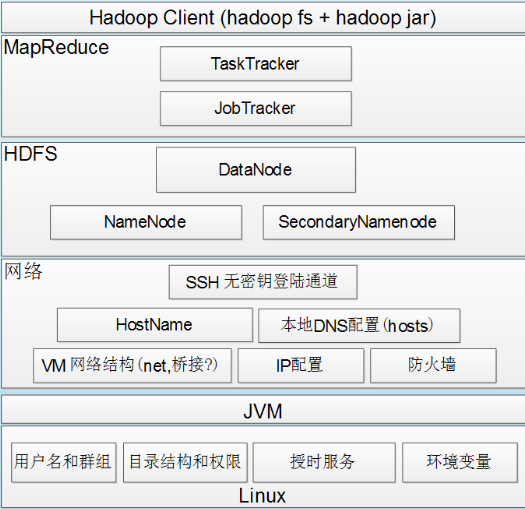
Hadoop组件依赖关系
Linux系统的安装就不介绍了,下面默认为已经安装好Linux系统了。
设置Linux的静态IP
编辑/etc/sysconfig/network-scripts/ifcfg-eth0文件,修改为如下内容:
DEVICE=eth0BOOTPROTO="static"HWADDR=08:00:27:22:13:54IPV6INIT="no"ONBOOT=yesDNS=192.168.1.1IPADDR=192.168.1.150NETMASK=255.255.255.0GATEWAY=192.168.1.1
然后执行网络重启命令:
service network restart
最后执行ifconfig命令查看是否修改成功
[root@hadoop-master software]# ifconfigeth0 Link encap:Ethernet HWaddr 08:00:27:22:13:54inet addr:192.168.1.150 Bcast:192.168.1.255 Mask:255.255.255.0inet6 addr: fe80::a00:27ff:fe22:1354/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:3078 errors:0 dropped:0 overruns:0 frame:0TX packets:423 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000RX bytes:230636 (225.2 KiB) TX bytes:56128 (54.8 KiB)lo Link encap:Local Loopbackinet addr:127.0.0.1 Mask:255.0.0.0inet6 addr: ::1/128 Scope:HostUP LOOPBACK RUNNING MTU:16436 Metric:1RX packets:76 errors:0 dropped:0 overruns:0 frame:0TX packets:76 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:0RX bytes:6266 (6.1 KiB) TX bytes:6266 (6.1 KiB)[root@hadoop-master software]#
修改VirtualBox的虚拟网卡地址
该步骤需保证虚拟机中的Linux能与客户机在同一网段并且ping通。
设置VirtualBox虚拟机的网络连接方式为Host-Only
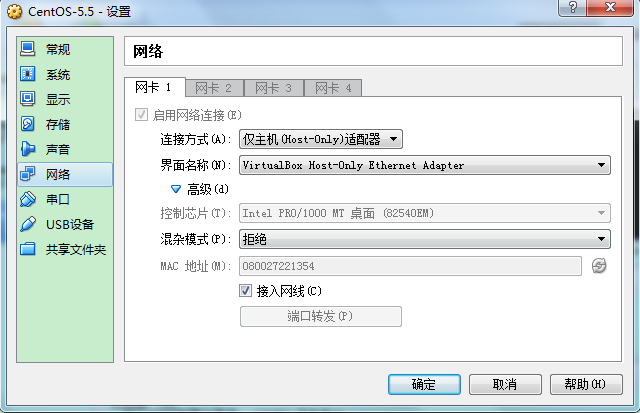
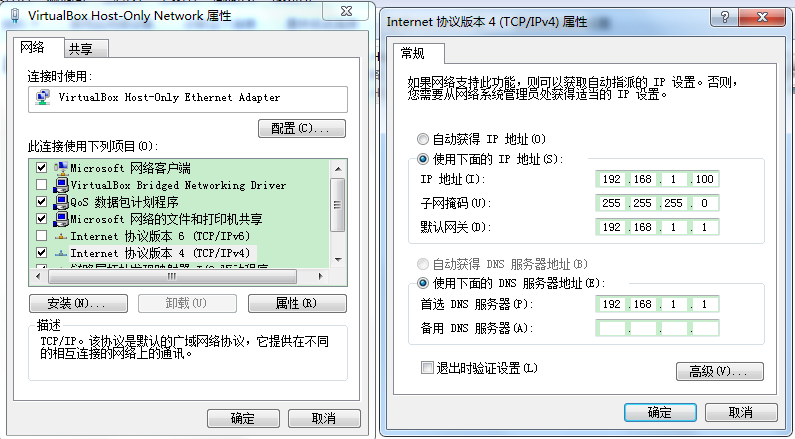
再修改VirtualBox虚拟出那块网卡的ip地址

修改为如下内容:
最后需要验证宿主机和虚拟机是否能够互通
宿主机ping虚拟机:
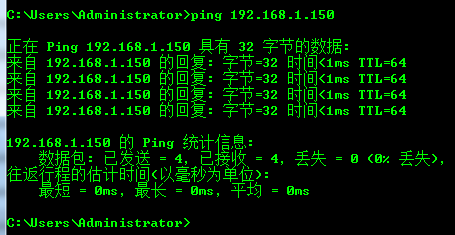
虚拟机ping宿主机:
[root@hadoop-master software]# ping -c3 192.168.1.100PING 192.168.1.100 (192.168.1.100) 56(84) bytes of data.64 bytes from 192.168.1.100: icmp_seq=1 ttl=64 time=0.366 ms64 bytes from 192.168.1.100: icmp_seq=2 ttl=64 time=0.357 ms64 bytes from 192.168.1.100: icmp_seq=3 ttl=64 time=0.189 ms--- 192.168.1.100 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2000msrtt min/avg/max/mdev = 0.189/0.304/0.366/0.081 ms[root@hadoop-master software]#
修改主机名
修改当前会话主机名(当前会话生效):hostname 主机名
修改配置文件主机名(永久生效):vi /etc/sysconfig/network
[root@hadoop-master software]# cat /etc/sysconfig/networkNETWORKING=yesNETWORKING_IPV6=noHOSTNAME=hadoop-master[root@hadoop-master software]# hostnamehadoop-master
把hostname和ip绑定
修改hosts文件:vi /etc/hosts文件,增加一行
192.168.1.150 hadoop-master
关闭防火墙:service iptables stop
- 查看防火墙状态:service iptables status
- 关闭防火墙:service iptables stop
关闭防火墙的自运行:
查看自运行状态:chkconfig –list | grep ‘iptables’
[root@hadoop-master sysconfig]# chkconfig --list | grep 'iptables'iptables 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
关闭防火墙:chkconfig iptables off
[root@hadoop-master sysconfig]# chkconfig iptables off
再次查看自运行状态:chkconfig –list | grep ‘iptables’
[root@hadoop-master sysconfig]# chkconfig --list | grep 'iptables'iptables 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
这样下次开机的时候就会不开启防火墙了
二、SSH免密码登陆
生成秘钥文件
进入~/.ssh文件夹,使用ssh-keygen -t rsa命令
注意:
1.如果没有.ssh文件夹,就使用ssh协议登录一次试试
2.如果还是没有.ssh文件夹,就自己创建一个。修改文件夹权限为700
3.authorized_keys文件的权限为644
[root@hadoop-master software]# cd ~/.ssh/[root@hadoop-master .ssh]# ssh-keygen -t rsa
查看.ssh文件夹中已经多出了两个文件id_rsa和 id_rsa.pub
[root@hadoop-master .ssh]# lsid_rsa id_rsa.pub[root@hadoop-master .ssh]#
将id_rsa.pub公钥文件内容放入到authorized_keys中,变成私钥
[root@hadoop-master .ssh]# cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
测试免密码登陆是否成功
使用:ssh localhost命令连接本机,第一次连接时会让输入yes。以后就不用输入了。
[root@hadoop-master .ssh]# ssh localhostThe authenticity of host 'localhost (127.0.0.1)' can't be established.RSA key fingerprint is 8c:f4:bf:b5:c4:95:30:7b:1c:d7:cc:f8:69:15:e1:ab.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'localhost' (RSA) to the list of known hosts.Last login: Sun Apr 5 17:45:25 2015
三、安装JDK
JDK的安装很简单,解压缩。然后配置环境变量即可。
安装步骤如下:
1. 授予执行权限
[root@hadoop-master software]# chmod u+x jdk-6u24-linux-i586.bin
2. 解压缩
[root@hadoop-master software]# ./jdk-6u24-linux-i586.bin
3. 配置环境变量
编辑/etc/profile文件,增加如下代码
# JAVA_HOMEexport JAVA_HOME=/opt/modules/jdk1.6.0_24export PATH=$JAVA_HOME/bin:$PATHexport CLASS_PATH=.:$JAVA_HOME/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
然后使设置立即生效:
source /etc/profile
4. 测试安装
[root@hadoop-master software]# java -versionjava version "1.6.0_24"Java(TM) SE Runtime Environment (build 1.6.0_24-b07)Java HotSpot(TM) Client VM (build 19.1-b02, mixed mode, sharing)[root@hadoop-master software]#
四、安装Hadoop
Hadoop伪分布式的安装也很简单
解压缩,配置环境变量。修改配置文件即可
1、解压缩hadoop-1.1.2.tar.gz
[root@hadoop-master software]# tar -zxvf hadoop-1.1.2.tar.gz
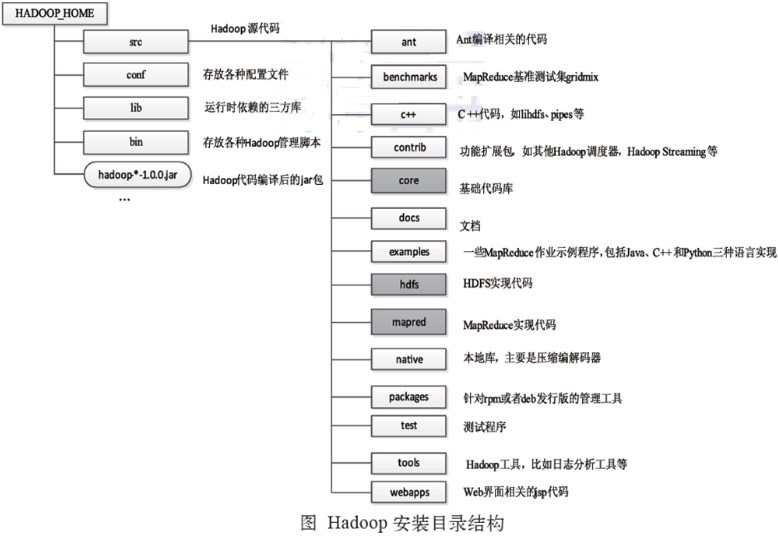
解压完成后,可以看下Hadoop1.x的目录结构
2、添加到环境变量中
编辑/etc/profile文件,在文件最后增加如下内容
# HADOOP_HOMEexport HADOOP_HOME=/opt/modules/hadoop-1.1.2export PATH=$PATH:$HADOOP_HOME/bin
3、使设置立即生效
source /etc/profile
4、修改hadoop的配置文件
伪分布式的安装需要修改Hadoop的6个配置文件(${HADOOP_HOME}/conf),如下:
Hadoop脚本配置文件:hadoop-env.sh
核心配置文件:core-site.xml
HDFS的配置文件:hdfs-site.xml
MapReduces的配置文件:mapred-site.xml
管理节点配置文件:masters
工作节点配置文件:slaves
配置hadoop-env.sh
打开${HADOOP_HOME}/conf/hadoop-env.sh
修改JAVA_HOME变量为自己安装的JDK的位置
export JAVA_HOME=/opt/modules/jdk1.6.0_24
配置core-site.xml
${HADOOP_HOME}/conf/core-site.xml中需要配置HDFS的默认主机名、端口和hadoop在本地的文件系统目录(目录需要存在)
为什么要设置HDFS的工作目录呢?
因为不设置的话,Hadoop的HDFS默认的工作目录是在Linux系统的/tmp目录下,

这个目录在Linux重启后内容会被清空。所以你还需要重新再格式化。所以,这里我们指定HDFS的工作目录为我们自定义的目录。
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.default.name</name><value>hdfs://hadoop-master:9000</value><description>hadoop-master</description></property><property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property></configuration>
配置hdfs-site.xml
${HADOOP_HOME}/conf/hdfs-site.xml中主要配置:
文件块的副本数(dfs.replication):由于是伪分布式,主节点和从节点都在同一台机器上,所以副本数为1
是否进行权限检查(dfs.permissions):false
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration>
配置mapred-site.xml
${HADOOP_HOME}/conf/mapred-site.xml中主要配置MapReduce的jobTracker的主机和端口
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>mapred.job.tracker</name><value>hadoop-master:9001</value></property></configuration>
配置masters
指定SecondaryNameNode的位置(主机名)。
打开${HADOOP_HOME}/conf/masters文件,增加如下内容:
hadoop-master
配置slaves
指定DataNode和TaskTracker的位置(主机名)。
打开${HADOOP_HOME}/conf/slaves文件,增加如下内容:
hadoop-master
5、格式化NameNode
配置完成后需要格式化NameNode,第一次使用时需要格式化,之后再次使用时就不再需要。
在${HADOOP_HOME}/bin/目录下执行
[root@hadoop-master bin]# hadoop namenode -format
五、测试Hadoop安装是否成功
启动Hadoop
Hadoop的执行命令都在${HADOOP_HOME}/bin目录下,启动和停止的2种方式
全部启动或停止:
启动:start-all.sh
启动顺序为:
NameNode–>DataNode–>SecondaryNameNode–>JobTracker–>TaskTracker停止:stop-all.sh
停止顺序为:
JobTracker–>TaskTracker–>NameNode–>DataNode–>SecondaryNameNode单个启动:
启动:start-dfs.sh start-mapred.sh
停止:stop-dfs.sh stop-mapred.sh
这里我们直接全部启动:start-all.sh
[root@hadoop-master bin]# start-all.shstarting namenode, logging to /opt/modules/hadoop-1.1.2/libexec/../logs/hadoop-root-namenode-hadoop-master.outhadoop-master: starting datanode, logging to /opt/modules/hadoop-1.1.2/libexec/../logs/hadoop-root-datanode-hadoop-master.outhadoop-master: starting secondarynamenode, logging to /opt/modules/hadoop-1.1.2/libexec/../logs/hadoop-root-secondarynamenode-hadoop-master.outstarting jobtracker, logging to /opt/modules/hadoop-1.1.2/libexec/../logs/hadoop-root-jobtracker-hadoop-master.outhadoop-master: starting tasktracker, logging to /opt/modules/hadoop-1.1.2/libexec/../logs/hadoop-root-tasktracker-hadoop-master.out[root@hadoop-master bin]#
可以从控制台看到,启动后的日志信息都存在在了HADOOPHOME/logs/目录下,如果启动报错可以去查看相应的日志信息。当然这个日志目录可以自定义。默认是在HADOOPHOME/logs/目录下,如果启动报错可以去查看相应的日志信息。当然这个日志目录可以自定义。默认是在{HADOOP_HOME}/logs/目录下。打开${HADOOP_HOME}/conf/hadoop-env.sh文件,里面有如下一行配置:
# Where log files are stored. $HADOOP_HOME/logs by default.# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
日志类型有2种,分别以log和out结尾。
- 以log结尾的日志
通过log4j采用每日滚动的方式来记录日志,主要记录了启动和停止的日志信息。 - 以out结尾的日志
记录标准输出和标准错误的日志,内容比较少。
日志文件名格式:
hadoop-root-datanode-hadoop-master.log
hadoop-用户名-守护进程名称-运行守护进程的节点名称.log
消除start-all.sh时候的警告信息
如果启动过程中出现如下警告信息
Warning: $HADOOP_HOME is deprecated
出现该警告的原因为:${HADOOP_HOME}/bin/hadoop-config.sh文件中的如下代码

主要是:$HADOOP_HOME_WARN_SUPPERSS变量内容为空的原因,
解决办法是设置其不为空即可!
修改vi /etc/profile文件,增加如下代码
export HADOOP_HOME_WARN_SUPPRESS=1
然后使设置生效
source /etc/profile
通过jps命令查看Hadoop的5个守护进程
ps表示查看Linux系统中的进程。jps表示查看系统中的Java进程
[root@hadoop-master bin]# jps6432 DataNode6639 JobTracker6915 Jps6316 NameNode6545 SecondaryNameNode6791 TaskTracker[root@hadoop-master bin]#
登陆WEB管理页面
在Windwos系统的hosts文件中配置ip地址和hostname的映射
打开C:\Windows\System32\drivers\etc\hosts文件,增加如下内容。这样在访问192.168.1.150时,可以直接输入hadoop-master来访问了。
## Hadoop1.1.2192.168.1.150 hadoop-master
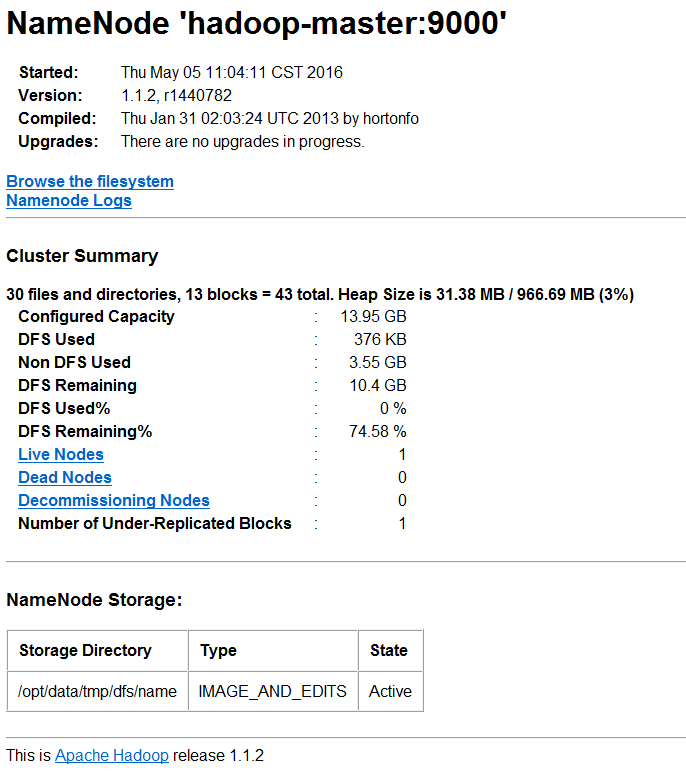
HDFS的管理页面
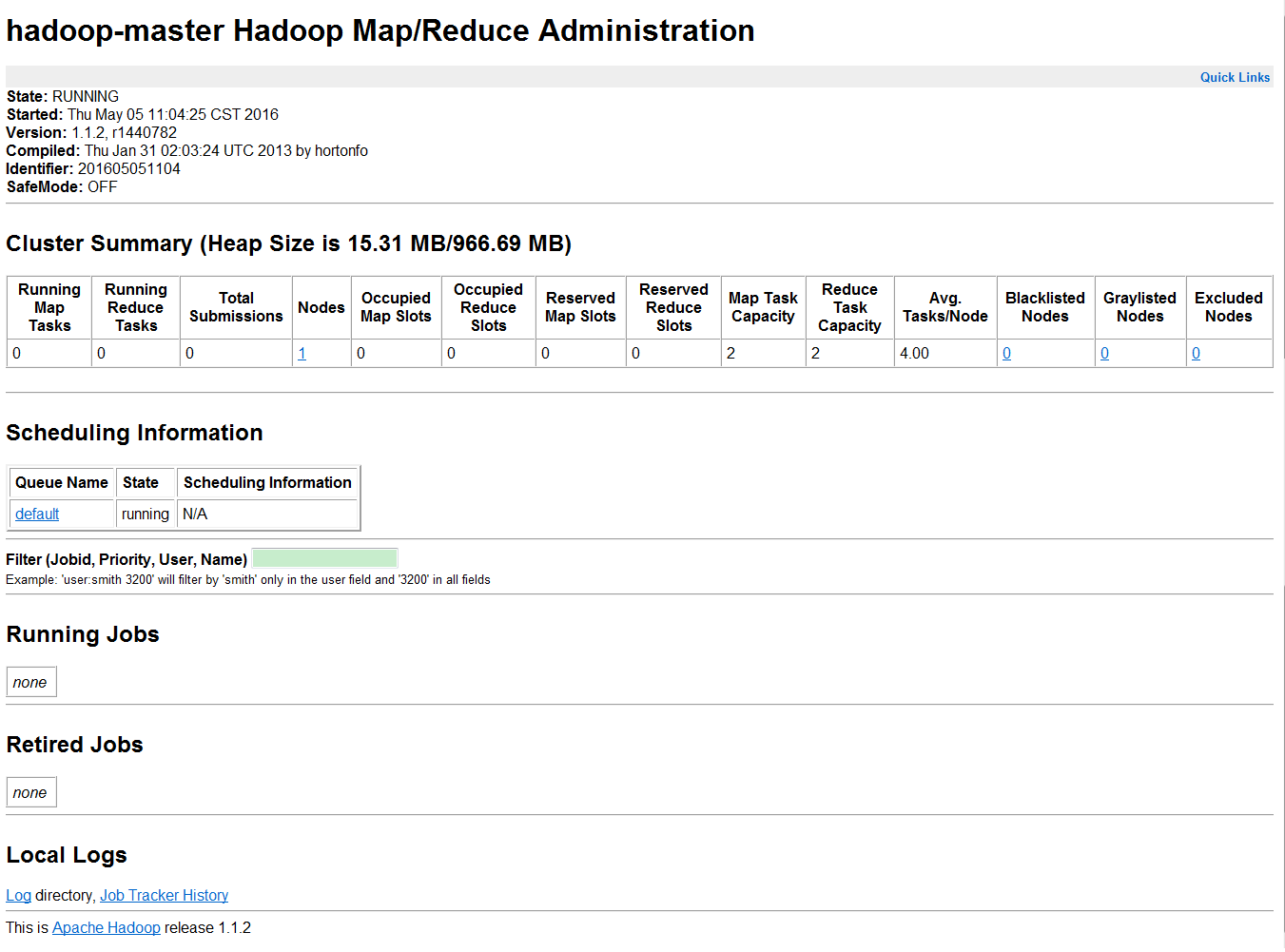
MapReduce的管理页面
各监控页面显示正常的话,表示Hadoop伪分布式安装成功!
Hadoop1.1.2伪分布式安装的更多相关文章
- Hadoop1.2.1 伪分布式安装
Hadoop1.2.1 单机模式安装 Hadoop组件依赖图(从下往上看) 安装步骤: 详细步骤: 设置ssh自动登录(如下图): 1.输入命令 [ssh-keygen -t rsa],然后一直按回车 ...
- Hadoop1.1.2伪分布式安装笔记
一.设置Linux的静态IP 修改桌面图标修改,或者修改配置文件修改 1.先执行ifconfig,得到网络设备的名称eth0 2.编辑/etc/sysconfig/network-scripts/if ...
- Hadoop1.0.4伪分布式安装
前言: 目前,学习hadoop的目的是想配合其它两个开源软件Hbase(一种NoSQL数据库)和Nutch(开源版的搜索引擎)来搭建一个知识问答系统,Nutch从指定网站爬取数据存储在Hbase数据库 ...
- redhat 安装hadoop1.2.1伪分布式
完整安装过程参考:http://www.cnblogs.com/shishanyuan/p/4147580.html 一.环境准备 1.安装linux.jdk 2.下载hadoop2. ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- Hadoop开发第3期---Hadoop的伪分布式安装
一.准备工作 1. 远程连接工具的安装 PieTTY 是在PuTTY 基础上开发的,改进了Putty 的用户界面,提供了多语种支持.Putty 作为远程连接linux 的工具,支持SSH 和telne ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- HBase基础和伪分布式安装配置
一.HBase(NoSQL)的数据模型 1.1 表(table),是存储管理数据的. 1.2 行键(row key),类似于MySQL中的主键,行键是HBase表天然自带的,创建表时不需要指定 1.3 ...
- Zookeeper 初体验之——伪分布式安装(转)
原文地址: http://blog.csdn.net/salonzhou/article/details/47401069 简介 Apache Zookeeper 是由 Apache Hadoop 的 ...
随机推荐
- ZOHO 免费小型企业邮箱和个人邮箱
Zoho Mail 提供免费小型企业邮箱注册.精简版只能添加一个域到您的机构帐号,最多允许10用户.如果您想添加多个域,您可以升级到标准版.10用户免费,5 GB /每用户,5 GB (共享). 除了 ...
- glog安装与使用
window环境下glog的安装 载后解压,利用Visual Studio打开google-glog.sln.生成解决方案 打开sln会有几个项目,libglog是动态库,生成dll,libglog_ ...
- Smarty小结提纲
Smarty:模板技术 实现功能:前后分离. 原理:主要通过Smarty核心类实现,调用display方法,将模板文件读取,用正则进行替换,替换完保存到临时文件,将临时文件加载到当前页面. 配置文件( ...
- liunx ubuntu java 环境的配置
手动安装jdk 一,下载jdk安装文件: jdk网站地 址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- MapReduce: number of mappers/reducers
14 down vote It's the other way round. Number of mappers is decided based on the number of splits. I ...
- springcloud17---zuul-reg-exp
package com.itmuch.cloud; import org.springframework.boot.SpringApplication; import org.springframew ...
- Ubuntu下dlib库编译安装
安装libboost 按照dlib的说明安装始终不成功,参考machine learning is fun作者的指导installing_dlib_on_macos_for_python.md,需要首 ...
- ansible之template模块
趁着最近在搞ansible,现在学习了一波template模块的用法: 1.使用template模块在jinja2中引用变量,先来目录结构树 [root@master ansible]# tree . ...
- 20145118 《Java程序设计》第5周学习总结 教材学习内容总结
20145118 <Java程序设计>第5周学习总结 教材学习内容总结 1.Java中所有错误都会被打包成对象,可以通过try.catch语法对错误对象作处理,先执行try,如果出错则跳出 ...