Python 爬虫练手项目—酒店信息爬取
from bs4 import BeautifulSoup
import requests
import time
import re url = 'http://search.qyer.com/hotel/89580_4.html'
urls = ['http://search.qyer.com/hotel/89580_{}.html'.format(str(i)) for i in range(1,10)] # 最多157页
infos = []
# print(urls) # 批量爬取数据
def getAUrl(urls):
data_number = 0
for url in urls:
getAttractions(url)
print('--------------{}-----------------'.format(len(infos)),sep='\n') # 爬取当页面数据
def getAttractions(url,data = None):
web_data = requests.get(url)
time.sleep(2)
soup = BeautifulSoup(web_data.text,'lxml')
# print(soup) hotel_names = soup.select('ul.shHotelList.clearfix > li > h2 > a')
hotel_images = soup.select('span[class="pic"] > a > img')
hotel_points = soup.select('span[class="points"]')
hotel_introduces = soup.select('p[class="comment"]')
hotel_prices = soup.select('p[class="seemore"] > span > em') if data == None:
for name,image,point,introduce,price in \
zip(hotel_names,hotel_images,hotel_points,hotel_introduces,hotel_prices):
data = {
'name':name.get_text().replace('\r\n','').strip(),
'image':image.get('src'),
'point':re.findall(r'-?\d+\.?\d*e?-?\d*?', point.get_text())[0],
'introduce':introduce.get_text().replace('\r\n','').strip(),
'price':int(price.get_text())
}
# print(data)
infos.append(data) # 根据价格从高到低进行排序
def getInfosByPrice(infos = infos):
infos = sorted(infos, key=lambda info: info['price'], reverse=True)
for info in infos:
print(info['price'], info['name']) # getAttractions(url)
爬取的网站链接
遇到的问题及解决办法
1.【转载】Python: 去掉字符串开头、结尾或者中间不想要的字符
①Strip()方法用于删除开始或结尾的字符。lstrip()|rstirp()分别从左右执行删除操作。默认情况下会删除空白或者换行符,也可以指定其他字符。
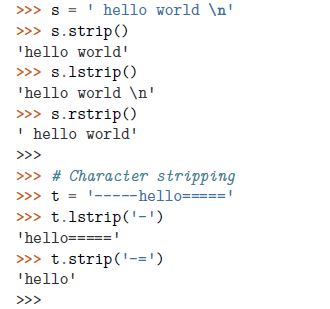
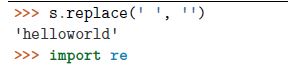
②如果想处理中间的空格,需要求助其他技术 ,比如replace(),或者正则表达式

③strip()和其他迭代结合,从文件中读取多行数据,使用生成器表达式

④更高阶的strip
可能需要使用translate()方法
2. 【转载】Python:object of type 'Response' has no len(),如何解决?
需要下载代码的可以到我的GitHub上下载 https://github.com/FightingBob/-Web-Crawler-training 如果觉得可以,请给我颗star鼓励一下,谢谢!
Python 爬虫练手项目—酒店信息爬取的更多相关文章
- python爬虫练手项目快递单号查询
import requests def main(): try: num = input('请输入快递单号:') url = 'http://www.kuaidi100.com/autonumber/ ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- python网络爬虫(12)去哪网酒店信息爬取
目的意义 爬取某地的酒店价格信息,示例使用selenium在Firefox中的使用. 来源 少部分来源于书.python爬虫开发与项目实战 构造 本次使用简易的方案,模拟浏览器访问,然后输入字段,查找 ...
- Python新手练手项目
1.新手练手项目集中推荐 https://zhuanlan.zhihu.com/p/22164270 2.Python学习网站 https://www.shiyanlou.com 3.数据结构可视化学 ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
随机推荐
- springMVC与Struts2区别
1.拦截级别 Struts2是类级别的拦截,一个类对应一个request上下文 SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应 所以说从架构本身 ...
- apktook 反编译错误
Exception in thread "main" brut.androlib.err.UndefinedResObject: resource spec: 0x01010490 ...
- Java数组和各种List的性能比较
以下程序分别对Java数组.ArrayList.LinkedList和Vector进行随机访问和迭代等操作,并比较这种集合的性能. package cn.lion.test; public class ...
- λ(lambda)表达式
理论阶段 函数接口 函数接口是行为的抽象: 函数接口是数据转换器; java.util.Function包.定义了四个最基础的函数接口: Supplier<T>: 数据提供器,可以提供 T ...
- 转载:GitHub 新手详细教程
GitHub 新手详细教程 https://blog.csdn.net/Hanani_Jia/article/details/77950594
- 【转】SQL SERVER 2005/2008 中关于架构的理解
在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询,提示“对象名'CustomEntry' 无效.”.当带上了架构名称 ...
- 基于 Annotation 的 Spring AOP 权限验证方法的实现
1. 配置 applicationContext 在 Spring 中支持 AOP 的配置非常的简单,只需要在 Spring 配置文件 applicationContext.xml 中添加: < ...
- A记录,CNAME,MX记录,TTL
A记录 A记录是用来指定主机名(或域名)对应的IP地址记录.用户可以将该域名下的网站服务器指向到自己的web server上.同时也可以设置您域名的二级域名. MX记录 MX记录邮件路由记录,用户可以 ...
- 数据适配:DataAdapter对象概述
DataAdapter对象可用于执行数据库的命令操作,含有四个不同的操作命令,分别如下: SelectCommand:用来选取数据源中的记录: InsertCommand:用来向数据源中新插入一条 ...
- zsh: command not found: gulp
明明安装了gulp,但是为什么执行gulp命令却在控制台输出 zsh: command not found: gulp 可能因为gulp没有被全局安装 在控制台输入 which gulp 如果输出 g ...