kafka简介【转】
一、为什么需要消息系统
() 解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 () 冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 () 扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。 () 灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 () 顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。 () 缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
二、kafka 架构
2.1、概念
kafka是一款性能很高的消息组件,但是不管如何改变,对于消息组件本身其最基础的组成部分包括:
# 消息的生产者:负责进行消息信息的推送,推送给指定服务器。
# 消息的消费者:负责通过服务器获取消息的内容。
# 消息服务中间件(服务器):负责消息的存储,也就是说当消费者来不及处理完全部的消息后,可以在消息中间件之中进行消息内容的缓冲,所以消息中间件也往往被称为消息队列中间件。
2.2 拓扑结构
kakfa架构:
kafka整体采用显示分布式架构,producer,broker(kafka)和consumer都可以有多个。
producer,consumer实现kakfa注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用,broker分发注册到系统中的consumer。
broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议。
如下图:
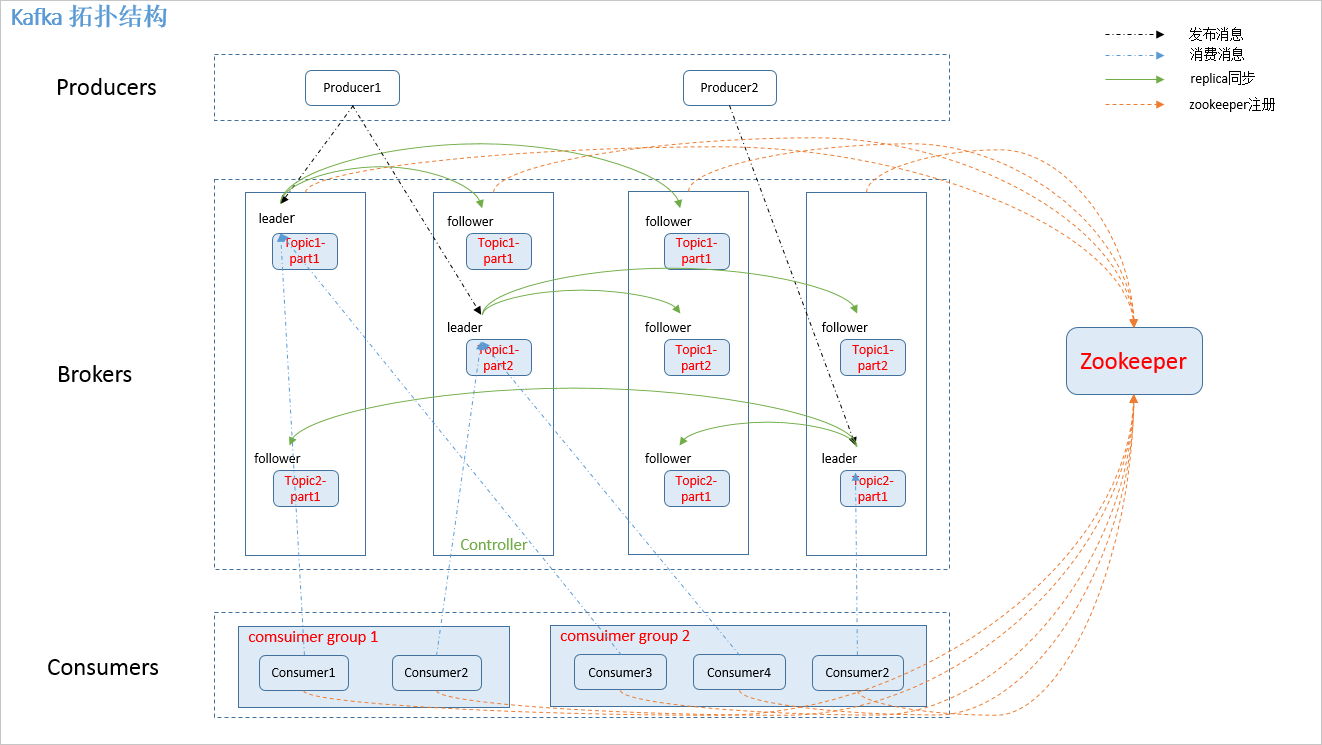
图.1
2.3、相关概念
如图.1中,kafka 相关名词解释如下:
.producer:
消息生产者,发布消息到 kafka 集群的终端或服务。
.broker:
kafka 集群中包含的服务器。broker:缓存代理,kafka集群中的一台或多台服务器统称为broker。
.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。topic特指kafka处理的消息源(feeds of messages)的不同分类。
.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
.consumer:
consumers:消息和数据消费者,订阅topics并处理其其发布的消息的过程叫做consumers;
.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
.replica:
partition 的副本,保障 partition 的高可用。
.leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
.follower:
replica 中的一个角色,从 leader 中复制数据。
.controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。
.messages:
消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
partition:指的是分区,如果你现在配置的主机只是单核CPU,那么你能够进行的合理分区划分,那么只能够有一个分区,但是你CPU的核心数字可能有16,那么你这台服务器上可以进行的分区操作就可以划分出16个分区,
在每一台服务器上,可以有多个分区,而分区划分最简单的依据:就是根据你的CPU的性能来决定的。
并不是说一核CPU无法进行多分区的配置,只不过要想发挥出最好的性能,那么一定要使用多核的CPU。整个kafka集群里面,所有的分区数量=主机的CPU内核数量。
要想发挥出最好的性能,那么一定要使用多核CPU再设置多个分区。
三、kafka要点
kafka消息发送流程:

在kafka之中消息的发送一定要依据主题进行划分,而每一个主题为了让消息处理更快,专门设置有多个分区,就好比一件工作,你一个人干绝对要比三个人干慢许多。
同时在整个kafka里面最新的版本之中支持有key=value结构传输,这样的传输模式对于消费者而言会更加容易处理数据。在进行消费者设计的时候,你的消费者可以使用的数据数量就是你的分区数量,也就是说如果你现在设置 了三个分区,
那么就表示可以使用三个消费者,反之,如果你只设计了一个分区,那么只能够有一个消费者。
kafka消息处理流程:
在进行信息写入的时候,所有的磁盘中的数据保存采用随机的方式,如果将消息以随机写的方式存入磁盘,就会按着柱面,磁头,扇区的方式进行(寻址过程)写入,缓慢的机械运动(相对内存)就会消耗大量的时间,导致磁盘的写入速度只能达到内存写入速度的几百万分之一,为了规避随机写带来的时间消耗,KAfka采取顺序写入的方式存储数据。
在整个KAFKA里面还有一个比较逆天的性能,传统的JMS设计的时候会存在一个缺陷,当某一个消息消费之后,那么该消息将会被自动删除,而kafka不是,他在进行消息获取之后不会立刻删除,而是将消息暂停2天,2天后自动删除,在这样的状态下为了保证kafka的读取性能,单独设计了一个offset,可以理解为当前要操作的消息的下标来读取历史消息,只需要修改offset的指向即可实现。在一些组件整合的过程中,需要考虑好offset造成的历史消息重复消费的问题。
offset与消息访问
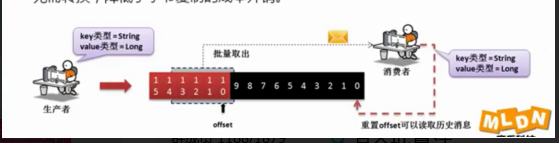
#消费者通过offset的方式来取得消息数据,利用offset偏移改变消息读取位置,可以实现历史消息读取。
#为了避免频繁的大量小数据的磁盘IO操作,kafka采用批量读取模式处理消息。
#在高负载状态下,为防止无效率的字节复制,kafka采用由producer,Broker和consumer共享的标准化二进制消息格式,这样数据库就可以在他们之间自由传输,无需转换,降低了字节复制的成本开销。
在磁盘之中如果要不断的进行各种细小的琐碎操作,那么就有可能造成性能下降,所以在kafka里面专门设计有批量的数据操作,也就是说所有要消费的数据会批量读取,这样就减少了磁盘的操作量,性能也会得到提升。
在很多的消息系统里面由于其可以传输数据类型比较少(字符串),所以在每一次消费的时候都需要去判断数据的类型,这样自然会造成时间复杂度的提升,那么为了解决这样的问题,kafka约定了,你的消息生产者一定要与消息的消费者协商好所有的消息数据类型。
kafka内存应用
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。kakfa采用了MMAP(memory mapped files,内存映射文件)技术。
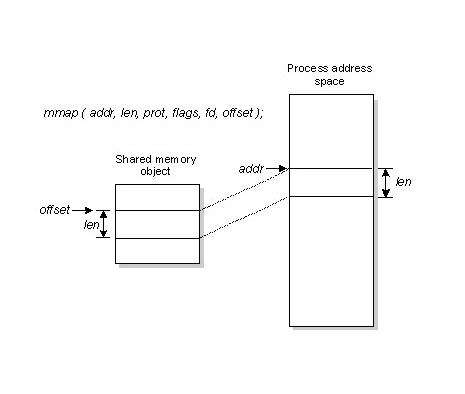
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销;也有一个很明显的缺陷——不可靠,
写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。现代操作系统都大量使用主存做磁盘缓存,一个现代操作系统可以将内存中所有的剩余空间做磁盘缓存,而当内存回收的时候几乎没有性能损失。
kafka是基于jvm技术的应用:
l 传统JVM技术:对象的内存开销非常高,通常是实际要存储数据大小的两倍;随着数据的增加,Java的垃圾收集也会越来越频繁并且缓慢。
l kafka内存维护:文件系统+页缓存(例如:FIFO,CLOCK);
由于使用操作系统页缓存,即使KAFKA重新启动,数据依然可以使用。
Kafka是基于JDK的实现,所以在kafka中对于内存要想发挥高效,就不能纯粹依靠JVM进行, 这样的好处是即使kafka奔溃了,但是数据不在JVM里面,数据也可以
立刻恢复
文件传输是整个网络操作的核心所在,毕竟消息组件之中是需要有消费者的,而所有的消费者如果 CPU读取磁盘数据,而后在通过CPU进行网络传输,那么这样的处理中间会
文件传输处理
消息的数据接收需要通过broker完成,broker维护的消息日志就是文件的目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。
维护公共的格式并允许优化最重要操作:网络传输持久性日志块。
传统文件传输处理操作步骤:
l 操作系统将数据从磁盘读入到内核空间的页缓存; l 应用程序将数据从内核空间读入到用户空间缓存中; l 应用程序将数据写回到内核空间到socket缓存中; l 操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出;
Sendfile系统传输:现代的Unix操作系统提供一个优化的代码路径,用于将数据从页缓存传输到socket;在linux中,是通过sendfile系统调用完成的。
Kafka传输速度保障---批量压缩
l 为了提升消息传输速率,同时为了节约网络带宽,kafka会在每次传输时将多个消息批量压缩;
l Kafka批量消息可以通过压缩形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩。(kafka支持gzip和snappy压缩协议)
Kafka数据可靠性分析---topic&partition
Kafka的消息保存在topic中,topic可分为多个分区,为保证数据的安全性,每个分区又有多个replica。
分区设计特点:
l 为了并发读写,加快读写速度;
l 利用多分区的存储,利于数据的均衡;
l 为了加快数据的恢复速率,一旦某台机器挂掉,整个集群只需要恢复一部分数据,可加快故障恢复的时间。(producer和consumer都只与leader交互,每个follower从leader拉去数据进行同步。)
当你现在设计有多台kafka服务器的时候,就可以进行副本的设计,也就是说如果设计有三个副本,那么这三个副本就要推选出一个leader,而后有两个follower,所有的跟随者通过leader进行数据的抓取,而所有的生产者会将数据交给leader,消费者也通过leader读取数据,这样当某一个leader出现问题之后,其他的两个follower将自动推选出新的leader。
Kafka快,性能高的原理:
综合以上的所有概念来讲,就可以轻松的总结出kafka所谓性能高的实现模型:
# 采用零拷贝技术,让数据传输更加的迅速; # 采用批量的数据读取,减少磁盘的IO操作,可以提升性能。 # 为了保证历史消息继续可以被消费,提供一个offset指向,通过指向来负责消息的读取顺序; #网络的传输采用数据压缩格式,所以传输更快,占用带宽越少; # Kafka中的数据可以设置副本,这样可以在出现问题之后依然保证该数据的有效性。
四、注意事项
producer 无法发送消息的问题
最开始在本机搭建了kafka伪集群,本地 producer 客户端成功发布消息至 broker。随后在服务器上搭建了 kafka 集群,在本机连接该集群,producer 却无法发布消息到 broker(奇怪也没有抛错)。最开始怀疑是 iptables 没开放,于是开放端口,结果还不行(又开始是代码问题、版本问题等等,倒腾了很久)。最后没办法,一项一项查看 server.properties 配置,发现以下两个配置:
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = security_protocol://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
以上说的就是 advertised.listeners 是 broker 给 producer 和 consumer 连接使用的,如果没有设置,就使用 listeners,而如果 host_name 没有设置的话,就使用 java.net.InetAddress.getCanonicalHostName() 方法返回的主机名。
修改方法:
1. listeners=PLAINTEXT://121.10.26.XXX:9092
2. advertised.listeners=PLAINTEXT://121.10.26.XXX:9092
修改后重启服务,正常工作。
kafka简介【转】的更多相关文章
- Kafka简介
Kafka简介 转载请注明出处:http://www.cnblogs.com/BYRans/ Apache Kafka发源于LinkedIn,于2011年成为Apache的孵化项目,随后于2012年成 ...
- Kafka简介及使用PHP处理Kafka消息
Kafka简介及使用PHP处理Kafka消息 Kafka 是一种高吞吐的分布式消息系统,能够替代传统的消息队列用于解耦合数据处理,缓存未处理消息等,同时具有更高的吞吐率,支持分区.多副本.冗余,因此被 ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- Kafka简介、安装
一.Kafka简介 Kafka是一个分布式.可分区的.可复制的消息系统.几个基本的消息系统术语:1.消费者(Consumer):从消息队列(Kafka)中请求消息的客户端应用程序.2.生产者(Prod ...
- 【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS.分布式数据库HBase.NoSQL数据库Redis),其次存储 ...
- KafKa简介和利用docker配置kafka集群及开发环境
KafKa的基本认识,写的很好的一篇博客:https://www.cnblogs.com/sujing/p/10960832.html 问题:1.kafka是什么?Kafka是一种高吞吐量的分布式发布 ...
- Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行 简介 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速.可扩展.可持久化的特点.它现在是Apache旗下的一个 ...
- Kafka简介、基本原理、执行流程与使用场景
一.简介 Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于201 ...
- Kafka 学习之路(一)—— Kafka简介
一.简介 Apache Kafka是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于RabbtMQ.ActiveMQ等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: 支 ...
- Kafka 系列(一)—— Kafka 简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
随机推荐
- ROS :为IDE配置环境变量
ROS hydro 自带安装好了opencv 2.4 为了在自己经常使用的开发环境Eric下调用,需要配置Eric的环境变量,好让它可以调用ROS的资源,当然你用其他IDE也要这样配置,配置好了环境变 ...
- e644. 处理Action事件
Action events are fired by subclasses of AbstractButton and includes buttons, checkboxes, and menus. ...
- 模式识别之线性判别---naive bayes朴素贝叶斯代码实现
http://blog.csdn.net/xceman1997/article/details/7955349 http://www.cnblogs.com/yuyang-DataAnalysis/a ...
- sqlldr导入数据(以PostgreSql>>>Oracle为例)
1.在目标数据库中创建表 1.1点击源表,复制创建语句 1.2 修改数据类型以匹配目标数据库,如: 字符串类型:character varying(20)>>>varchar2(20 ...
- 用ADO操作数据库的方法步骤
用ADO操作数据库的方法步骤 学习ADO时总结的一些经验 - 技术成就梦想 - 51CTO技术博客 http://freetoskey.blog.51cto.com/1355382/989218 ...
- OpenCV学习:OpenCV源码编译(vc9)
安装后的OpenCV程序下的build文件夹中,只找到了vc10.vc11和vc12三种编译版本的dll和lib文件,需要VS2010及以上的IDE版本,而没有我们常用的VS2008版本. 于是,需要 ...
- doDBA 监控用法
https://yq.aliyun.com/articles/67051 doDBA tools是什么 doDBA tools是一个基于控制台的远程监控工具,它不需要在本地/远程系统上安装任何软件,它 ...
- mysql数据库使用mysqldump工具针对一个数据库备份,使用--databases选项与不使用该参数的区别
需求描述: 今天在做mysqldump备份某个数据库的试验,在备份某个数据库的时候可以使用 --databases参数,也可以直接进行某个数据库的备份,那么这里记录下两者的区别 操作过程: 1.使用- ...
- spring xml properties split with comma for list
在注入spring bean 属性值的时候常常会用到list, 一般使用方式例如以下: <bean id="testBean" class="com.mytest. ...
- mybatis由浅入深day02_2一对一查询_2.3方法二:resultMap_resultType和resultMap实现一对一查询小结
2.3 方法二:resultMap 使用resultMap,定义专门的resultMap用于映射一对一查询结果. 2.3.1 sql语句 同resultType实现的sql SELECT orders ...