sqlalchemy使用
1.SQLAlchemy的作用
ORM对象关系映射技术
2.SQLAlchemy安装
pip install SQLAlchemy
查看SQLAlchemy版本

3.生成数据库连接
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
DB_CONNECT_STRING = 'postgresql+psycopg2://postgres:@localhost:5432/postgres'
engine = create_engine(DB_CONNECT_STRING)
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
DB_CONNECT_STRING:数据库连接字符串
engine:创建数据库引擎
DB_Session:数据库会话工厂,用于创建数据库连接实例
session:数据库会话实例,可以理解为一个数据库连接, SQLAlchemy 自己维护了一个数据库连接池(默认 5 个连接),因此初始化一个会话的开销并不大。
4.直接执行sql
print(session.execute('select * from "user" where id = 1').first())
print(session.execute('select * from "user" where id = :id', {'id': 1}).first())
运行结果:

5.sqlalchemy一般使用的是它的ORM特性,声明模型Model
from sqlalchemy import Column,String,Integer
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__='user'
id=Column(Integer,primary_key=True)
name=Column(String(50))
# 属性名可以和字段名不一致
from_=Column('from',String(50))
Base.metadata.drop_all(engine)
Base.metadata.create_all(engine)
基类Base,是一个model和数据库表管理类。
通过继承Base,可自动实现model和数据库表的关联。
create_all(engine) 会找到 BaseModel 的所有子类,并在数据库中建立这些表。
drop_all() 则是删除这些表。
6.批量插入
# 一次插入10000
start = time.time()
for i in range(10000):
user = User()
user.name = str(i)
session.add(user)
session.commit()
end = time.time()
print(end - start)
start = time.time()
session.execute(User.__table__.insert(),
[{'name': str(i)} for i in range(10000)]
)
session.commit()
end = time.time()
print(end - start)
运行结果:

使用非ORM的方式批量插入可以大幅提高效率
7.增删改查
session是关系型数据库中的事务。
1)增加记录
user=User(name="shijingjing07")
session.add(user)
session.commit()
必须commit,才能真正写入数据库
2)删除记录
usr=session.query(User).first()
session.delete(usr)
session.commit()
3)更新记录
usr=session.query(User).first()
usr.name="icefinger"
session.add(usr)
session.commit()
4)查询记录
过滤器:
#==
usr=session.query(User).filter(User.name=="icefinger").first()
print(usr.id)
#!=
usr=session.query(User).filter(User.name!="icefinger").first()
print(usr.id)
#like
usr=session.query(User).filter(User.name.like("icefinger%")).first()
print(usr.id)
#in
usr=session.query(User).filter(User.name.in_(["icefinger","tomcat","james"])).first()
print(usr.id)
#not in
usr=session.query(User).filter(~User.name.in_(["icefinger","tomcat","james"])).first()
print(usr.id)
#is null
usr=session.query(User).filter(User.name==None).first()
print(usr.id)
usr=session.query(User).filter(User.name.is_(None)).first()
print(usr.id)
#and
from sqlalchemy import and_
usr=session.query(User).filter(and_(User.name=="icefinger",User.id=="2")).first()
print(usr.id)
#or
from sqlalchemy import or_
usr=session.query(User).filter(or_(User.name=="icefinger",User.id=="3")).first()
print(usr.id)
返回值:
#first,使用limit返回第一行
print("--first--")
usr=session.query(User).filter(or_(User.name=="icefinger",User.id=="3")).first()
print(usr.id)
#all,返回所有行
print("--all--")
usrlist=session.query(User).filter(or_(User.name=="icefinger",User.id=="3")).all()
for usr in usrlist:
print(usr.id)
#one,返回行数只能是一条
print("--one--")
try:
usr = session.query(User).filter(or_(User.name == "icefinger", User.id == "3")).one()
print(usr)
except:
print("must be one")
#one_on_none,返回行数只能是一条,或none
print("--one_or_none--")
usr = session.query(User).filter(and_(User.name == "icefinger", User.id == "2")).one_or_none()
print(usr)
#scalar,同one_on_none,返回行数只能是一条,或none
print("--scalar--")
usr = session.query(User).filter(or_(User.name == "icefinger", User.id == "2")).scalar()
print(usr)
运行结果:
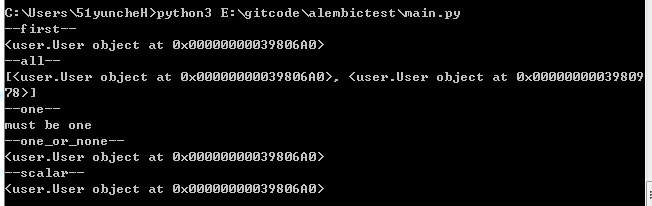
统计个数:
print("--count1--")
count=session.query(User).count()
print(count)
print("--count2--")
count = session.query(func.count('*')).select_from(User).scalar()
print(count)
8.其他常用语法
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, func
DB_CONNECT_STRING = 'postgresql+psycopg2://postgres:@localhost:5432/postgres'
engine = create_engine(DB_CONNECT_STRING)
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(30))
BaseModel.metadata.drop_all(engine)
BaseModel.metadata.create_all(engine)
user = User(name='a')
session.add(user)
user = User(name='b')
session.add(user)
user = User(name='a')
session.add(user)
user = User()
session.add(user)
session.commit()
query = session.query(User)
print(query) # 显示SQL 语句
print(query.statement) # 同上
for user in query: # 遍历时查询
print(user.name)
print(query.all()) # 返回的是一个类似列表的对象
print(query.first().name) # 记录不存在时,first() 会返回 None
# print query.one().name # 不存在,或有多行记录时会抛出异常
print(query.filter(User.id == 2).first().name)
print(query.get(2).name) # 以主键获取,等效于上句
print(query.filter('id = 2').first().name) # 支持字符串
query2 = session.query(User.name)
print(query2.all()) # 每行是个元组
print(query2.limit(1).all()) # 最多返回 1 条记录
print(query2.offset(1).all()) # 从第 2 条记录开始返回
print(query2.order_by(User.name).all())
print(query2.order_by('name').all())
print(query2.order_by(User.name.desc()).all())
print(query2.order_by('name desc').all())
print(session.query(User.id).order_by(User.name.desc(), User.id).all())
print(query2.filter(User.id == 1).scalar()) # 如果有记录,返回第一条记录的第一个元素
print(session.query('id').select_from(User).filter('id = 1').scalar())
print(query.count())
print(session.query(func.count('*')).select_from(User).scalar())
print(session.query(func.current_timestamp()).scalar()) # 使用func调用数据库函数
9.替换一个已有主键的记录
user = User(id=1, name='ooxx')
session.merge(user)
session.commit()
10.关系-一对多
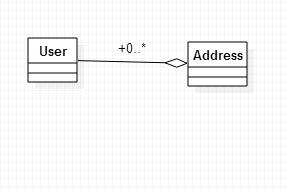
1)如下图所示,一个用户可能对应多个地址
from sqlalchemy import create_engine,and_,or_,func
from sqlalchemy import Table,Column,String,Integer,ForeignKey
from sqlalchemy.orm import relationship,sessionmaker
from sqlalchemy.ext.declarative import declarative_base
engine=create_engine("postgresql://postgres:sj1107@localhost:5432/sampledb")
Session=sessionmaker(bind=engine)
session = Session()
Base = declarative_base(bind=engine)
class User(Base):
__tablename__='user'
id=Column(Integer,primary_key=True)
addresses=relationship('Address')
class Address(Base):
__tablename__='address'
id=Column(Integer,primary_key=True)
user_id=Column(Integer,ForeignKey('user.id'))
if __name__ == "__main__":
Base.metadata.create_all()
u=User()
session.add(u)
session.commit()
a1=Address(user_id=u.id)
a2=Address(user_id=u.id)
session.add(a1)
session.add(a2)
session.commit()
print(u.addresses)
运行结果:

ForeignKey:外键,制定了user_id和User的关系
relationship:绑定了两个Model的联系,通过User直接得到所有的地址。
2)根据address获取user:
address只能获得user_id,然后根据user_id获取user
能不能通过address直接获取user呢?在model里,添加relationship关系就可以了。
class User(Base):
__tablename__='user'
id=Column(Integer,primary_key=True)
addresses=relationship('Address')
class Address(Base):
__tablename__='address'
id=Column(Integer,primary_key=True)
user_id=Column(Integer,ForeignKey('user.id'))
user=relationship('User')
运行结果:

3)上例中两个model中都添加relationship,看起来很繁琐,能不能只指定一个,另一个默认就可以访问呢?
backref参数就可以了。
class User(Base):
__tablename__='user'
id=Column(Integer,primary_key=True)
addresses=relationship('Address',backref="user")
class Address(Base):
__tablename__='address'
id=Column(Integer,primary_key=True)
user_id=Column(Integer,ForeignKey('user.id'))
运行结果:

11.关系-多对多
user和address关系为多对多,即一个user对应多个address,一个address对应多个user
多对多需要中间表来关联
#定义中间表,关联多对多关系
user_address_table =Table(
'user_address',Base.metadata,
Column('user_id',Integer,ForeignKey('user.id')),
Column('address_id',Integer,ForeignKey('address.id'))
)
class User(Base):
__tablename__='user'
id=Column(Integer,primary_key=True)
addresses=relationship('Address',secondary=user_address_table)
class Address(Base):
__tablename__='address'
id=Column(Integer,primary_key=True)
users=relationship('User',secondary=user_address_table)
if __name__ == "__main__":
# Base.metadata.create_all()
u1=User()
u2=User()
session.add(u1)
session.add(u2)
session.commit()
a1=Address(users=[u1,u2])
a2 = Address(users=[u1, u2])
session.add(a1)
session.add(a2)
session.commit()
print(u1.addresses)
print(a1.users)
session.delete(u1)
print(a1.users)
运行结果:

12.连接表
上例提到,可以使用relationship关联表,relationship虽然看上去比较方便,但是比较复杂,且存在性能问题,所以一般自己join
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, func, ForeignKey
DB_CONNECT_STRING = 'postgresql+psycopg2://postgres:@localhost:5432/postgres'
engine = create_engine(DB_CONNECT_STRING)
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(30))
class Friend(BaseModel):
__tablename__ = 'friend'
id = Column(Integer, primary_key=True)
name = Column(String(30))
user_id = Column(Integer, ForeignKey('user.id'))
BaseModel.metadata.drop_all(engine)
BaseModel.metadata.create_all(engine)
user = User(name='a')
session.add(user)
user = User(name='b')
session.add(user)
session.commit()
friend = Friend(name='er',user_id=1)
session.add(friend)
friend = Friend(name='tr',user_id=1)
session.add(friend)
session.commit()
# 拥有朋友的用户,方法一
query = session.query(User).join(Friend, Friend.user_id == User.id)
print(query.all())
# 拥有朋友的用户,方法二
query = session.query(User).filter(
User.id == Friend.user_id
)
print(query.all())
# 所有用户,及用户对应的朋友
query = session.query(User, Friend).outerjoin(Friend, Friend.user_id == User.id)
print(query.all())
运行结果:
【1.png】
13.扩展基类
declarative_base基类,是一个model和数据库表管理类。
我们可以定义一个扩展基类,抽象model的公共属性,和一些公共的数据库操作函数。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, func, ForeignKey
DB_CONNECT_STRING = 'postgresql+psycopg2://postgres:@localhost:5432/postgres'
engine = create_engine(DB_CONNECT_STRING)
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
BaseModel = declarative_base()
class CommonModel(object):
id = Column(Integer, primary_key=True)
@classmethod
def get_one_by_id(cls, session, id):
try:
query = session.query(cls).filter(cls.id == id)
return query.one_or_none()
except Exception as e:
return None
@classmethod
def get_all(cls, session,query_columns=None, filter_columns=None, offset=None, limit=None,order_by=None):
try:
if not query_columns:
query = session.query(cls)
else:
query = session.query(*query_columns)
if filter_columns:
query = query.filter(*filter_columns)
if limit:
query = query.limit(limit)
if offset:
query = query.offset(offset)
if order_by:
query = query.order_by(order_by)
return query.all()
except Exception as e:
return None
@classmethod
def get_count(cls, session, filter_columns=None):
try:
query = session.query(cls)
if filter_columns:
query = query.filter(*filter_columns)
count = query.count()
return count
except Exception as e:
return None
class User(BaseModel, CommonModel):
__tablename__ = 'user'
name = Column(String(30))
# BaseModel.metadata.drop_all(engine)
# BaseModel.metadata.create_all(engine)
result = User.get_one_by_id(session, 1)
print(result)
result = User.get_all(session)
print(result)
result = User.get_count(session)
print(result)
运行结果:

sqlalchemy使用的更多相关文章
- sqlalchemy学习
sqlalchemy官网API参考 原文作为一个Pythoner,不会SQLAlchemy都不好意思跟同行打招呼! #作者:笑虎 #链接:https://zhuanlan.zhihu.com/p/23 ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- 冰冻三尺非一日之寒-mysql(orm/sqlalchemy)
第十二章 mysql ORM介绍 2.sqlalchemy基本使用 ORM介绍: orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似pyt ...
- Python 【第六章】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- SQLAlchemy(一)
说明 SQLAlchemy只是一个翻译的过程,我们通过类来操作数据库,他会将我们的对应数据转换成SQL语句. 运用ORM创建表 #!/usr/bin/env python #! -*- coding: ...
- sqlalchemy(二)高级用法
sqlalchemy(二)高级用法 本文将介绍sqlalchemy的高级用法. 外键以及relationship 首先创建数据库,在这里一个user对应多个address,因此需要在address上增 ...
- sqlalchemy(一)基本操作
sqlalchemy(一)基本操作 sqlalchemy采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型. 安装 需要安装MySQLdb pip install ...
- python SQLAlchemy
这里我们记录几个python SQLAlchemy的使用例子: 如何对一个字段进行自增操作 user = session.query(User).with_lockmode('update').get ...
- Python-12-MySQL & sqlalchemy ORM
MySQL MySQL相关文章这里不在赘述,想了解的点击下面的链接: >> MySQL安装 >> 数据库介绍 && MySQL基本使用 >> MyS ...
- 20.Python笔记之SqlAlchemy使用
Date:2016-03-27 Title:20.Python笔记之SqlAlchemy使用 Tags:python Category:Python 作者:刘耀 博客:www.liuyao.me 一. ...
随机推荐
- 使用Android编写录制视频小程序演示样例
主要实现录制功能的类:Camera类和MediaRecorder类.功能描写叙述:首先进入视频录制界面,点击录像button进入录像功能界面,点击录制開始录制视频, 点击停止button,将录制的视频 ...
- 解决vsftpd乱码
不管是中文环境还是英文环境,需要改的地方如下: /etc/sysconfig/i18n 其内容改为: LANG="zh_CN.GB2312"SYSFONT="latarc ...
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.2)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8932310 项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个 ...
- jQuery知识集锦
CreateTime--2017年2月16日14:00:22Author:MarydonjQuery知识集锦1.empty()与remove()的区别 <select id="ty ...
- Socket实现服务器与客户端的交互
连接过程: 根据连接启动的方式以及本地套接字要连接的目标,套接字之间的连接过程可以分为三个步骤:服务器监听,客户端请求,连接确认. (1)服务器监听:是服务器端套接字并不定位具体的客户端套接 ...
- webservice系统学习笔记9-使用契约优先的方式的一个服务端demo(隐式传Header信息)
服务器端: 1.编写wsdl文件 <?xml version="1.0" encoding="UTF-8" standalone="no&quo ...
- 类的专有方法(__init__)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #http://www.cnblogs.com/zyxstar2003/archive/2011/03/21/ ...
- iOS升级swift3 遇到Overriding non-open instance method outside of its defining module的解决方案
最近将我之前的一个swift项目升级swift3,说多了都是泪... 其中,遇到这样一个错误: 这是用的三方:ENSwiftSideMenu时引出的 报了两个错: 1.Cannot inherit f ...
- WCF 的 WebGet 方式
.NET 3.5以后,WCF中提供了WebGet的方式,允许通过url的形式进行Web 服务的访问.在以前的代码中,写过多次类似的例子,但总是忘记如何配置,现在将设置步骤记录如下: endpoint通 ...
- 数据库分析函数 ROW_NUMBER() rank() dense_rank() 的区别 first_value(D) , last_value(D)
直接上图 select * from tab select B,ROW_NUMBER()over(order by B) from tab 当碰到相同数据时,排名按照记录集中记录的顺序依次递增. 遇 ...