python 操作solr索引数据
测试代码1:
def test(self):
data = {"add": {"doc": {"id": "", "*字段名*": u"我是一个大好人"}}}
params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000}
url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json'
headers = {"Content-Type": "application/json"}
r = requests.post(url, json=data, params=params, headers=headers)
print r.text def Index_data(self):
solr = pysolr.Solr('http://127.0.0.1:8983/solr/mycore/', timeout=10) # How you'd index data.
result = solr.add([
{
"id": "doc_1",
"title": "A test document",
},
{
"id": "doc_2",
"title": "The Banana: Tasty or Dangerous?",
},
])
print result
测试代码2
实际数据:
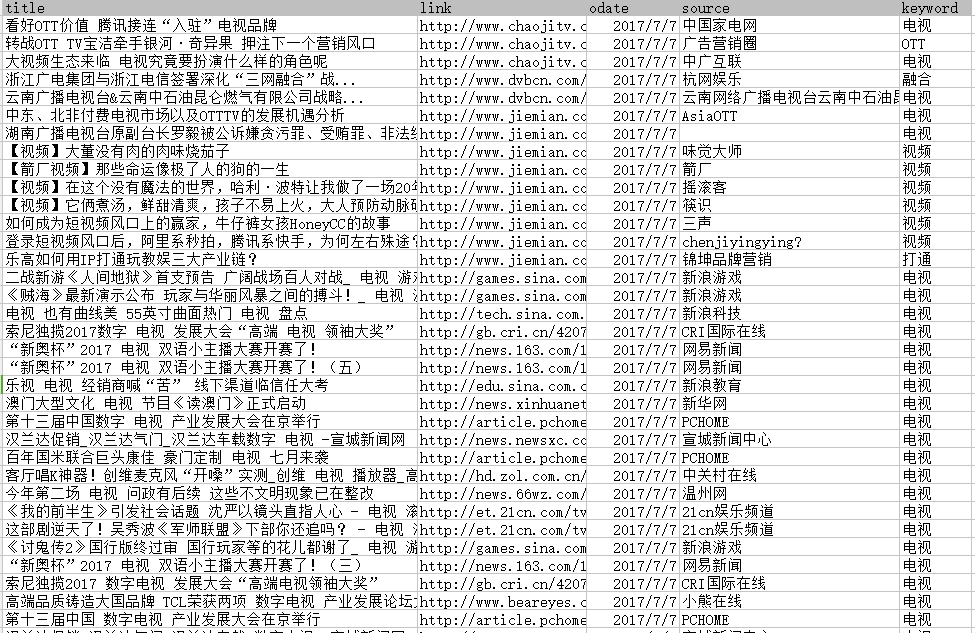
def Index_Data_FromCSV(self, csvfile):
'''
从CSV文件中读取数据,并索引到solr中
:param csvfile: csv文件,包括完整路径
:return:
'''
list = CSVOP.ReadCSV(csvfile)
index = 0
doc = {}
params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000}
url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json'
headers = {"Content-Type": "application/json"}
for item in list:
if index > 0: # 第一行是标题
try:
doc['title'] = item[0].decode('GB2312')
doc['link'] = item[1]
# doc['date'] = item[2]
doc['source'] = item[3].decode('GB2312')
doc['keyword'] = item[4].decode('GB2312')
data = {"add": {"doc": doc}}
r = requests.post(url, json=data, params=params, headers=headers)
print r.text
except Exception,e:
print e.message print index
index += 1 #pysolr客户端代码
def pysolr_Index_Data_FromCSV(self, csvfile,url='http://127.0.0.1:8983/solr/mycore/'):
'''
从CSV文件中读取数据,并索引到solr中
:param csvfile: csv文件,包括完整路径
:return:
'''
list = CSVOP.ReadCSV(csvfile)
index = 0
listdocs = []
for item in list:
if index > 0: # 第一行是标题
doc = {}
try:
doc['title'] = item[0].decode('GB2312')
doc['link'] = item[1]
# doc['date'] = item[2]
doc['source'] = item[3].decode('GB2312')
doc['keyword'] = item[4].decode('GB2312')
listdocs.append(doc)
except Exception,e:
print e.message
index += 1
solr = pysolr.Solr(url, timeout=10)
result = solr.add(listdocs)
print result
查询代码:
def search_data(self,message='视频'):
url = 'http://127.0.0.1:8983/solr/mycore/select?q=title:"\%s"&wt=json&indent=true' % message
r = requests.get(url, verify=False)
print r.text
r = r.json()['response']['numFound']
print message + ":" + str(r)
#pysolr客户端
def search_data(self,where='视频',url='http://127.0.0.1:8983/solr/mycore/'):
solr = pysolr.Solr(url, timeout=10)
dict = {'start':10,'rows': 30,'fl':'title,keyword,source,link'}
result = solr.search('title:视频',**dict)
# result = solr.search('title:视频')
# print result.raw_response['response']['numFound']
for item in result:
print 'keyword: %s'% item['keyword']
print 'title: %s'% item['title']
print 'source: %s'% item['source']
print 'link: %s'% item['link']
print ' '
输出结果:
{
"responseHeader":{
"status":0,
"QTime":0,
"params":{
"q":"title:\"\\视频\"",
"indent":"true",
"wt":"json"}},
"response":{"numFound":123,"start":0,"docs":[
{
"source":"中彩网",
"link":"http://www.zhcw.com/video/kaijiangshipin-3D/11981126.shtml",
"keyword":"视频",
"title":"福彩3D开奖 视频 -中彩 视频",
"id":"2f0a9d21-3771-4efa-a0cc-e0484cc97993",
"_version_":1584214368617234432},
{
"source":"新浪视频",
"link":"http://video.sina.com.cn/news/spj/topvideoes20170707/?opsubject_id=top1",
"keyword":"视频",
"title":"今日热门 视频 汇总20170707",
"id":"c8aae0af-01e9-491f-b999-24b97004a4ba",
"_version_":1584214367507841024},
{
"source":"网易新闻",
"link":"http://news.163.com/17/0707/13/COOCNUIE00018AOR.html",
"keyword":"视频",
"title":"网传"兰桂坊附近不雅 视频 " 警方:传播 视频 将追责",
"id":"353de48d-ede7-481b-89d3-bc20ab4b3884",
"_version_":1584214367821365248},
{
"source":"凤凰视频",
"link":"http://v.ifeng.com/video_7480871.shtml",
"keyword":"视频",
"title":"创想动画片:花粉过敏症的痛谁懂-凤凰 视频 -最具媒体品质的综合 视频 ...",
"id":"dc5f19c4-180f-4004-a0db-4499d875a60f",
"_version_":1584214366819975168},
{
"source":"凤凰视频",
"link":"http://v.ifeng.com/video_7805858.shtml",
"keyword":"视频",
"title":"节气说:小暑时节就该这样养生-凤凰 视频 -最具媒体品质的综合 视频 门...",
"id":"5e9eb7a7-48b8-4e41-9514-7712ae619d9a",
"_version_":1584214367516229632},
{
"source":"凤凰视频",
"link":"http://v.ifeng.com/video_7483506.shtml",
"keyword":"视频",
"title":"听导演讲《神奇女侠》的故事 -凤凰 视频 -最具媒体品质的综合 视频 门户-...",
"id":"6b1482f1-c0c9-479f-bef7-7de324fb9372",
"_version_":1584214367647301632},
{
"source":"汽车杂志",
"link":"http://www.jiemian.com/article/1445267.html",
"keyword":"视频",
"title":"【视频】欧宝最近找了一堆穿睡衣的辣妈拍了一段超牛的视频",
"id":"1d327555-a6f3-4513-9a21-43d59418ab82",
"_version_":1584214368157958144},
{
"source":"味觉大师",
"link":"http://www.jiemian.com/article/1453545.html",
"keyword":"视频",
"title":"【视频】大董没有肉的肉味烧茄子",
"id":"7d777870-93cb-4c18-a32b-734af8f133f1",
"_version_":1584213891451191296},
{
"source":"新浪汽车",
"link":"http://auto.sina.com.cn/video/zz/2017-07-07/detail-ifyhwehx5311889.shtml",
"keyword":"视频",
"title":"视频 :两大神车pk!高尔夫思域怎么选?",
"id":"3a50b303-6b54-4da3-aee1-a61c678c752d",
"_version_":1584213892090822656},
{
"source":"味觉大师",
"link":"http://www.jiemian.com/article/1453545.html",
"keyword":"视频",
"title":"【视频】大董没有肉的肉味烧茄子",
"id":"01da8e11-77bc-4c31-ba3a-ba668e846d9d",
"_version_":1584214366191878144}]
}}
完整代码:
#-*- coding: UTF-8 -*-
import csv
import os
import codecs def ReadCSV(filename):
if os.path.exists(filename):
with open(filename, 'r') as f:
reader = csv.reader(f)
list = []
for item in reader:
list.append(item)
return list #################################################
#coding=utf-8
import json
import requests import os
import time
from os import walk
import CSVOP
from datetime import datetime
import pysolr
import math class SolrClientObj: def test(self):
data = {"add": {"doc": {"id": "", "*字段名*": u"我是一个大好人"}}}
params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000}
url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json'
headers = {"Content-Type": "application/json"}
r = requests.post(url, json=data, params=params, headers=headers)
print r.text def pysolr_Index_Data_FromCSV(self, csvfile,url='http://127.0.0.1:8983/solr/mycore/'):
'''
从CSV文件中读取数据,并索引到solr中
:param csvfile: csv文件,包括完整路径
:return:
'''
list = CSVOP.ReadCSV(csvfile)
index = 0
listdocs = []
for item in list:
if index > 0: # 第一行是标题
doc = {}
try:
doc['title'] = item[0].decode('GB2312')
doc['link'] = item[1]
# doc['date'] = item[2]
doc['source'] = item[3].decode('GB2312')
doc['keyword'] = item[4].decode('GB2312')
listdocs.append(doc)
except Exception,e:
print e.message
index += 1
solr = pysolr.Solr(url, timeout=10)
result = solr.add(listdocs)
print result def Index_Data_FromCSV(self, csvfile):
'''
从CSV文件中读取数据,并索引到solr中
:param csvfile: csv文件,包括完整路径
:return:
'''
list = CSVOP.ReadCSV(csvfile)
index = 0
doc = {}
params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000}
url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json'
headers = {"Content-Type": "application/json"}
for item in list:
if index > 0: # 第一行是标题
try:
doc['title'] = item[0].decode('GB2312')
doc['link'] = item[1]
# doc['date'] = item[2]
doc['source'] = item[3].decode('GB2312')
doc['keyword'] = item[4].decode('GB2312')
data = {"add": {"doc": doc}}
r = requests.post(url, json=data, params=params, headers=headers)
print r.text
except Exception,e:
print e.message print index
index += 1 def Index_data(self):
solr = pysolr.Solr('http://127.0.0.1:8983/solr/mycore/', timeout=10) # How you'd index data.
result = solr.add([
{
"id": "doc_1",
"title": "A test document",
},
{
"id": "doc_2",
"title": "The Banana: Tasty or Dangerous?",
},
])
print result def search_data(self,where='视频',url='http://127.0.0.1:8983/solr/mycore/'):
solr = pysolr.Solr(url, timeout=10)
dict = {'start':10,'rows': 30,'fl':'title,keyword,source,link'}
result = solr.search('title:视频',**dict)
# result = solr.search('title:视频')
# print result.raw_response['response']['numFound'] for item in result:
print 'keyword: %s'% item['keyword']
print 'title: %s'% item['title']
print 'source: %s'% item['source']
print 'link: %s'% item['link']
print ' ' def delete_index_data(self,where,url='http://127.0.0.1:8983/solr/mycore/'):
'''
删除索引
:param where: 删除的条件
:param url: url
:return:
'''
solr = pysolr.Solr(url, timeout=10)
# solr.delete(id=where) #id='id1':删除id为“id1”的索引
result = solr.delete(q=where) #q='*:*'删除所有索引
print result obj = SolrClientObj()
# obj.delete_index_data('*:*') #删除所有索引
# obj.Index_data()
# obj.search_data()
# obj.delete_index_data('doc_1')
obj.search_data('视频')
# csvfile = 'D:/work/Solr/other/exportExcels/2017-07-07_info.csv'
# obj.pysolr_Index_Data_FromCSV(csvfile)
python 操作solr索引数据的更多相关文章
- 使用solrj操作solr索引库
(solrj)初次使用solr的开发人员总是很郁闷,不知道如何去操作solr索引库,以为只能用<五分钟solr4.5教程(搭建.运行)>中讲到的用xml文件的形式提交数据到索引库,其实没有 ...
- 使用solrj操作solr索引库,solr是lucene服务器
客户端开发 Solrj 客户端开发 Solrj Solr是搭建好的lucene服务器 当然不可能完全满足一般的业务需求 可能 要针对各种的架构和业务调整 这里就需要用到Solrj了 Solrj是Sol ...
- [solr] - 索引数据删除
删除solr索引数据,使用XML有两种写法: 1) <delete><id>1</id></delete> <commit/> 2) < ...
- Solr(六)Solr索引数据存放到HDFS下
Solr索引数据存放到HDFS下 一 新建solr core hdfs 方法:http://www.cnblogs.com/Matchman/p/7287385.html 二 修改solrconfig ...
- [转][solr] - 索引数据删除
删除solr索引数据,使用XML有两种写法: 1) <delete><id>1</id></delete> <commit/> 2) < ...
- Solr索引数据
一般来说,索引是系统地排列文档或(其他实体).索引使用户能够在文档中快速地查找信息. 索引集合,解析和存储文档. 索引是为了在查找所需文档时提高搜索查询的速度和性能. 在Apache Solr中的索引 ...
- (二) solr 索引数据导入:xml格式
xml 是最常用的数据索引格式,不仅可以索引数据,还可以对文档与字段进行增强,从而改变它们的重要程度. 下面就是具体的实现方式: schema.xml的字段配置部分如下: <field name ...
- Java solr 索引数据增删改查
具体代码如下: import java.io.IOException; import java.util.*; import org.apache.solr.client.solrj.SolrClie ...
- 企业级搜索引擎Solr 第三章 索引数据(Indexing Data)[1]
转载:http://quweiprotoss.wap.blog.163.com/ Push data to Solr or have Solr pull it 尽管一个应用通过HTTP方式与Solr通 ...
随机推荐
- 【Uva11762】Race to 1
模拟马尔可夫过程,具体看书. #include<bits/stdc++.h> #define N 1000010 using namespace std; ; void calcprime ...
- 获取struts迭代list在页面显示的数据
js代码: function modifyPactMoney(){ var table=$("#pactfee"); var trs=table.find("tr&quo ...
- mysql分页查询语法
一.limit语法 SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT 子句可以被用于强制 SELECT 语句返回指 ...
- go语言实现拷贝文件
package main import ( "fmt" "io" "os" ) func main(){ list := os.Args / ...
- 《Java编程思想》笔记 第五章 初始化与清理
1.构造器 因为创建一个类的对象构造器就会自动执行,故初始化某些东西特好 2.方法重载 方法名相同,参数列表不同. 2.1 区分重载方法 方法重载后区别不同方法的就是方法签名 -->参数类型和个 ...
- EAScript 2016的新增语法(1)
1)let 语法,这个和var的声明类似,但是,只存在于其所在的代码块里. 举例: var x=1 console.log(x) { let x=2 console.log(x) } console. ...
- sybase ase 重启
sybase ase 重启 https://blog.csdn.net/davidmeng10/article/details/50344305 https://blog.csdn.net/wengy ...
- QTP自动化测试框架的基础知识
1. 什么是自动化测试框架? 假定你有一个活,需要构建许多自动化测试用例来测试这个应用程序.当你对这个应用程序完成自动化测试后,你对自己创建脚本应该有什么期望吗?你难道不想要- 脚本应该按照预期的来执 ...
- Codeforces 702D Road to Post Office(模拟 + 公式推导)
题目链接:http://codeforces.com/problemset/problem/702/D 题意: 一个人要去邮局取东西,从家到达邮局的距离为 d, 它可以选择步行或者开车,车每走 k 公 ...
- Proxmox VE
Proxmox虚拟化环境是基于QEMU/KVM和LXC的开源服务器虚拟化管理解决方案.我们可以使用集成的易于使用的WEB界面或通过CLI管理虚拟机,容器,高可用集群,存储和网络. Proxmox VE ...