Oracle中读取数据一些原理研究
文章很多摘录了
http://blog.163.com/liaoxiangui@126/blog/static/7956964020131069843572/
同时基于这篇文章的基础上,补充一些学习要点,如有问题,希望指出探讨.
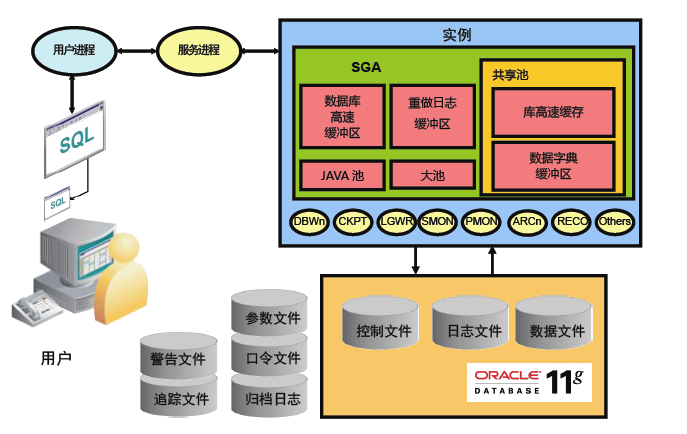
1 ORACLE体系结构
下图描述了oracle的体系结构。SGA(system global area)是各个进程共享的内存块,Buffer cache用来缓存数据文件的数据块(block)。
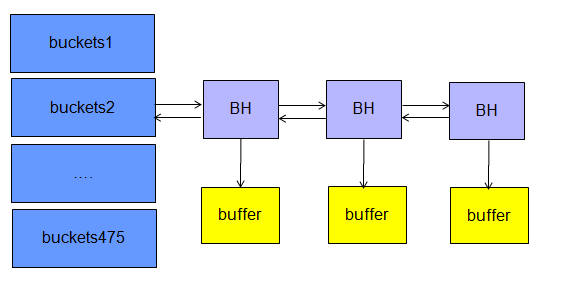
2 如何在data buffer中查找数据块
data buffer存在的意义就是为了在内存中进行高速的数据查找和更新,尽量减少磁盘的IO操作, Buffer Cache中存在一个Hash Bucket结构,将数据库中已经读取的数据块放到里面,在从数据库文件中读取到一个数据块后,Oracle会根据这个数据块的文件编号,段编号,数据块号组合到一起通过一个内部的hash算法运算后,会放到不同的hash bucket中,每个Hash Bucket都有一个Hash chain list,保留Buffer Header中的信息,然后通过这个list,把相同hash值的Buffer串起来.结构如图:
为保护这个结构不受同步更新的破坏,Oracle设计了一个CBC latch的锁结构(Cache Buffers Chains),一个latch保护32的桶(Bucket),所以为了访问hash列表,必须先获得CBC Latch.先获取Latch后,在对Buffer进行操作.
对buffer操作是一个比较耗时的操作,比如从磁盘读取block。由于一个latch管理32个桶,所以对buffer操作时不能继续持有latch。Oracle使用两阶段加latch锁的方式解决这个问题。
1) 加latch锁
2) 查找buffer,并对buffer加pin锁,如果是读取操作则为shared pin,若是写操作,则是exclusive pin
3) 释放latch锁
4) 对buffer进行操作
5) 加latch锁
6) 释放pin锁
7) 释放latch锁
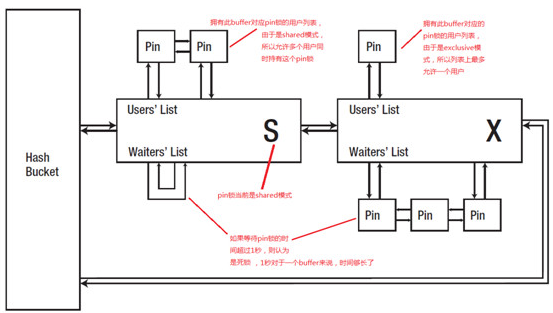
参见下图,一个buffer拥有一个pin锁,每个pin锁对应两个列表,user's list(拥有锁的用户列表)和waiter's list(等待锁的列表),如果用户等待pin锁的时间超过1秒,则认为出现死锁。buffer和pin锁是一一对应关系。
加上锁保护以后,整体的图
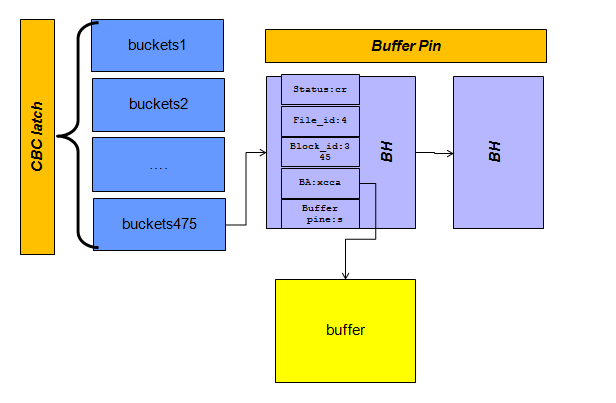
所以读取数据块的过程如下,当一个用户进程想要访问一个数据块:
- 根据数据文件号,块号生成hash 值
- 在Hash Table中找到bucket地址
- 获取CBC latch,一个latch保护32个bucket
- bucket有一个指针指向bh(buffer head)
- 根据bh的搜索链表
- 匹配bh里面的内容和要找的
- 匹配到一个bh,给bh加锁buffer pin(共享和独占)
- 释放cbc latch, cbc latch做两件事情:保护链表,保护加buffer pin锁
- 进程根据bh里面的ba地址找内存块
- 找完了,获得cbc latch,在保护下 释放buffer pin锁
利用哈希表管理已经被缓存的data block。为了使得哈希桶上链表尽量短,理想目标是一个链表上最多只有一个buffer,哈希桶的数量一般是data buffer数量的两倍,并把桶分组,每个组对应一个latch,latch用来保护桶中的链表。一个latch保护32个桶。
虽然和lock相比,latch是轻量级的,但是使用latch也是有比较大的开销的,所以oracle尽量减少latch数量,所以一个latch管理了高达32个桶。
问题: Oracle如何知道我们需要找的是哪个或者哪些数据块?
=============================================
数据库并不知道,根据sql语句执行计划来判断是走索引还是全表扫描
如果是索引,能直接返回块号,如果走全表扫描,数据库知道每个表段最开始的block号.所以我理解从表的第一个block开始寻找.
2粒度
oracle分配内存的单位是granule,一般是16MB。granule中有两种数据,data buffer和buffer header。data buffer是数据文件的data block在内存中的镜像,一个data buffer对应一个data block。buffer header存储了data buffer的状态和一些指向其它buffer header的指针,buffer header和data buffer是一一对应关系。由于指针在不同平台上大小不一样,所以buffer header的大小不固定,一般是150--250字节。
注意,buffer header与buffer header的关系不是block header与block的关系。为什么不把buffer header和data buffer合并在一起?因为把buffer header和data buffer分开,可以使得buffer的地址在一个固定的边界,这样会使得从磁盘读取数据时效率更高。
3 cache的种类
buffer cache中有8个cache,各对应一个参数,见下表。
| db_cache_size | system,sysaux,temporary表空间使用 |
| db_keep_cache_size | keep池。定义表或索引使用buffer_pool keep子句时,使用这个池。 意思是这个表和索引需要常驻内存。 |
| db_recycle_cache_size | recycle池。若在定义表或索引以及其它对象时使用buffer_pool recycle子句,则对象的缓存在这个池。意思是这个对象的数据很少被使用,不宜常驻内存。读一致性块的内存也从这个内存池中分配。 |
| db_2k_cache_size db_4k_cache_size db_8k_cache_size db_16k_cache_size db_32k_cache_size db_NK_cache_size |
db_NK_cache_size 提供自定义block的选项。db_2k_cache_size用来缓存大小为2K的data block。依次类推,db_32k_cache_size用来缓存大小为32K的data block。另外,8K是oracle默认的block大小。 |
在buffercache中存在两种链表,write list和LRU链表。LRU链表包含了free buffers(还没有使用的buffer);pinned buffers(被锁住的buffer,正在执行读写操作);还没有移到write list的dirty buffers。write list包含了脏块,需要DBWn进程写入到数据文件。
4 LRU算法
4.1 REPL链表
普通LRU算法的实现原理是每访问一个buffer,就把这个buffer移到MRU端。由于在oracle内部,访问buffer的频率非常高,不断的移动buffer在LRU中的位置开销相当大,并且不利于并发。所以oracle对LRU进行了改进。下图是一个buffer pool中的结构,包含两个链表,REPL和REPLAX。链表上的每个buffer header对应一个buffer,每个buffer缓存一个data block。
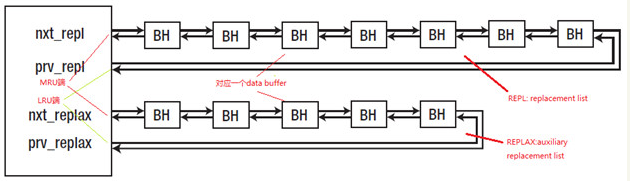
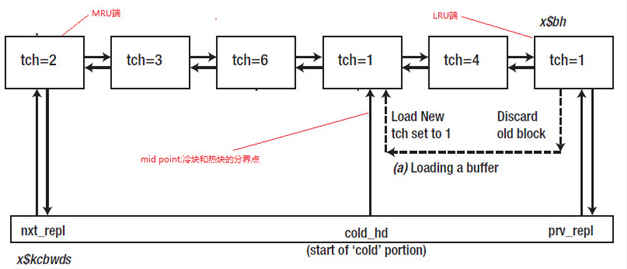
首先,我们在假设在没有REPLAX链表的情况下,oracle是如何淘汰buffer的。oracle对传统的LRU算法进行了改进。在每个buffer header增加了一个计数器(称为touch count,简称为TCH)和一个时间戳。每次访问buffer后,如果上次更新buffer header的TCH是在3秒之前,则对TCH加1,并把buffer header中的时间戳更新为当前时间。
oracle为REPL链表增加了一个字段cold_hd,可以理解为cold_hd后面的大部分buffer都是冷块。以下图为例,我们现在读取一个没有被缓存的data block,需要从REPL链表上得到一个buffer来缓存当前的data block。首先从LRU端获取一个buffer,如果是一个冷快(通过TCH来判断),则使用这个buffer缓存当前的data block,并把这个buffer header移到cold_hd的位置,更新TCH为1;如果是一个热快(通过TCH来判断),把这个buffer header移到MRU端,并更新TCH为原来的一半,然后继续检查LRU端的buffer是否是一个冷块,直到找到一个冷块为止。
LRU淘汰算法
curr_buffer_header=prv_repl
label1:
while(curr_buffer_header被锁住(pinned))
curr_buffer_header=curr_buffer_header->prev_buffer
if(curr_buffer_header是dirty块)
curr_buffer_header=curr_buffer_header->prev_buffer
把这个buffer移到write list,
goto lable1
if(curr_buffer_header是热快)
curr_buffer_header=curr_buffer_header->prev_buffer;
计数器减半;
移动到MRU端;
goto lable1;
else
移动到cold_hd位置
更新计数器为1
为data buffer加锁;
从磁盘读取数据,更新buffer header,更新计数器为1;
为data buffer解锁;
4.2 LRU进一步优化
在REPL中淘汰一个buffer需要很多操作,比如判断是否被锁住,是否是dirty块。相对来说,REPL淘汰一个buffer是一个重量级操作。为此,oracle 增加了另外一个链表REPLAX(replacement list auxilitary),这个链表里的所有buffer可以立即被淘汰,不用检查是否是dirty buffer、是否被pinned。从REPLAX链表淘汰buffer是轻量级操作。
oracle启动时,所有buffer header都挂在REPLAX上,随着计数器的增加,这些buffer header会被从REPLAX移到REPL中。当DBWn把dirty块写入到磁盘后,这些buffer会移到到REPLAX。目前为止,我们还不清楚REPLAX和REPL之间的buffer的移动细节。
7 全表扫描对LRU的影响
对大表全表扫描时,如果上述改进LRU算法的淘汰策略,会导致所有热快被立即换出。oracle首先会对表大小进行评估,进行大表进行全表扫描时,对大表的buffer采用不同的淘汰策略。
表大小> cache的10%。第一次扫描当作大表来对待,计数器不增加,并且buffer header放入REPLAX链表。如果表数据还在缓存的情况下又进行的全部扫描,则认为这个把这个表当作小表扫描来对待,增加计数器。
表大小> cache的25%。计数器的值不会增加,且表对应的buffer header只会出现在REPLAX链表上。
在create table时,使用cache子句也会影响buffer的淘汰侧路。cache子句包括3个选项CACHE、NOCACHE、CACHE和READS。CACHE适用于经常被访问的小表,NOCACHE适用于大表和访问频次低的表,CACHE READS适用于包含LOB的表。
Oracle中读取数据一些原理研究的更多相关文章
- 关于python从Oracle中读取数据中文全是问号的问题
import os os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' 问题搞定
- oracle中的数据读取与查找
数据读取 首先数据块读入到Buffer Cache中,并将其放在LRU(Last Recently Used)链表的MRU(Most Recently Used)端,当需要再次访问该块时可以直接从bu ...
- 一个I/O线程可以并发处理N个客户端连接和读写操作 I/O复用模型 基于Buf操作NIO可以读取任意位置的数据 Channel中读取数据到Buffer中或将数据 Buffer 中写入到 Channel 事件驱动消息通知观察者模式
Tomcat那些事儿 https://mp.weixin.qq.com/s?__biz=MzI3MTEwODc5Ng==&mid=2650860016&idx=2&sn=549 ...
- 从多个XML文档中读取数据用于显示webapi帮助文档
前言: 你先得知道HelpPageConfig文件,不知道说明你现在不需要这个,所以下文就不用看了,等知道了再看也不急.当然如果你很知道这个,下文也不用看了,因为你会了. 方法一: new XmlDo ...
- oracle中的数据对象
oracle中的数据对象有表.视图.索引.序列等 表的相关操作 1.创建表 方式一: 方式二:create table person( create table person1 id number(1 ...
- ffmpeg 从内存中读取数据(或将数据输出到内存)
更新记录(2014.7.24): 1.为了使本文更通俗易懂,更新了部分内容,将例子改为从内存中打开. 2.增加了将数据输出到内存的方法. 从内存中读取数据 ffmpeg一般情况下支持打开一个本地文件, ...
- 在Oracle中更新数据时,抛出:ORA-01008: not all variables bound
在Oracle中更新数据时,抛出了一个 :ORA-01008 not all variables bound, 我的理解是不是所有的变量/参数都有边界,不懂: 后来知道了,原来是“不是所有变量/参数都 ...
- 程序一 用记事本建立文件src.dat,其中存放若干字符。编写程序,从文件src.dat中读取数据,统计其中的大写字母、小写字母、数字、其它字符的个数,并将这些数据写入到文件test.dat中。
用记事本建立文件src.dat,其中存放若干字符.编写程序,从文件src.dat中读取数据,统计其中的大写字母.小写字母.数字.其它字符的个数,并将这些数据写入到文件test.dat中. #inclu ...
- MyBatis在Oracle中插入数据并返回主键的问题解决
引言: 在MyBatis中,希望在Oracle中插入数据之时,同一时候返回主键值,而非插入的条数... 环境:MyBatis 3.2 , Oracle. Spring 3.2 SQL Snipp ...
随机推荐
- 【洛谷 P3805】 【模板】manacher算法
题目链接 manacher算法:在线性时间内求一个字符串中所有/最长回文串的算法. 先来考虑一下暴力的算法,枚举每个中点,向两边扩展,时间复杂度\(O(n^2)\). 来分析下此算法的缺点. 1.因为 ...
- UVA 10471 Gift Exchanging
题意:就5种盒子,给出每个盒子个数,盒子总数,每个人选择这个盒子的概率.求这个人选择哪个盒子取得第一个朋友的概率最大,最大多少 dp[N][sta]表示当前第N个人面临状态sta(选择盒子的状态可以用 ...
- Multi-Paxos协议日志同步应用
使用Multi-Paxos协议的日志同步与恢复 基于Basic-Paxos协议的日志同步方案, 所有成员的身份都是平等的, 任何成员都可以提出日志持久化的提案, 并且尝试在成员组中进行持久化. 而在实 ...
- SQLAlchemy中filter()和filter_by()有什么区别
from:https://segmentfault.com/q/1010000000140472 filter: apply the given filtering criterion to a co ...
- ReadOnly与Enabled
txtDlrCode.ReadOnly = true; 1.当设置为只读,文本框有点击事件,点击该文本框还是可以响应点击事件 2.设置为只读,C#后台无法取得文本框的值,txtDlrCode.Text ...
- 全面理解面向对象的 JavaScript(转载)
http://www.ibm.com/developerworks/cn/web/1304_zengyz_jsoo/#resources 前言 当今 JavaScript 大行其道,各种应用对其依赖日 ...
- button的格式的问题
1. <input type="button" class="buttoncls" onclick="" value=" ...
- HDU-5074
Hatsune Miku Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)To ...
- docker从零开始 存储(二)volumes 挂载
使用volumes 卷是保存Docker容器生成和使用的数据的首选机制.mount binds依赖于主机的目录结构,而卷完全由Docker管理.卷绑定安装有几个优点: 与绑定装入相比,卷更易于备份或迁 ...
- python算法:嵌套数组转变成一维数组
比如,输入是:[2, 1, [3, [4, 5], 6], 7, [8]] 则,输出是:[2, 1, 3, 4, 5, 6, 7, 8] def list_flatten(l, a=None): a ...