1.kafka的介绍
kafka是一种高可用,高吞吐量,基于zookeeper协调的分布式发布订阅消息系统。
消息中间件:生产者和消费者
举个例子:
生产者:做馒头,消费者:吃馒头,数据流:馒头
如果消费者宕机了,吃不下去了,那么馒头就浪费了,所以生产者生产之后丢在篮子里,消费者要吃的时候到篮子立面去取。
这个篮子就好比我们的kafka,起到一个缓冲的作用,如果篮子满了装不下馒头了,那就多准备几个篮子,多准备篮子就是kafka的扩容
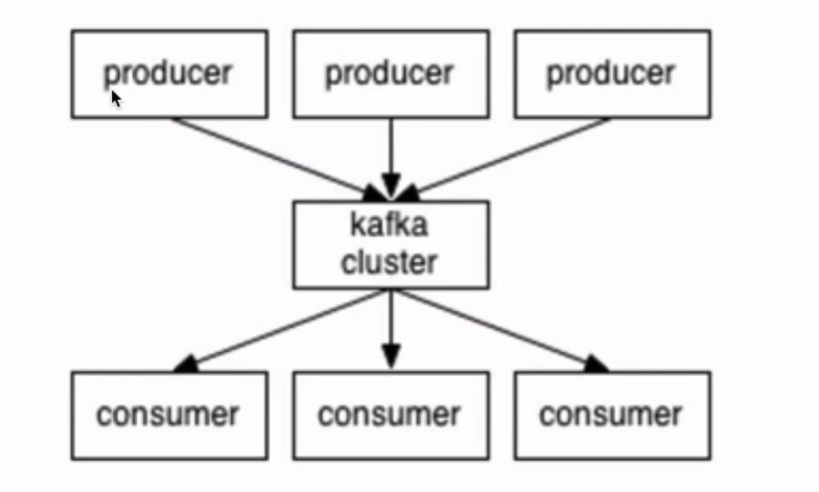
producer:生产者,生产馒头的
consumer:消费者,吃馒头的
broker:篮子
topic:主题,相当于给馒头打一个标签,并不是生产者生产的所有馒头消费者都会吃的。比方说topicA馒头是给你吃的,topicB馒头是给你妹妹吃的
消息系统有两种模式:peer to peer,和发布/订阅
peer to peer:
1.一般基于pull和polling接收消息
2.发送到队列的消息被一个且仅仅被一个接收者接收,即便有多个接收者在队列中监听同一消息
3.支持异步"即发即弃"的消息传送方式,也支持同步请求/应答传送方式。意思是我们即可以发送完就滚蛋,也可以发送完不走,确定被接收者接收之后再走
发布/订阅
1.发布到一个主题的消息,可被多个订阅者接收
2.发布/订阅即可基于push消费数据,也可以基于pull/polling消费数据
3.解耦能力比peer to peer模型更强
消息系统适用场景:
1.解耦:各位系统之间通过消息系统这个统一的接口交换数据,无需了解彼此的存在
2.冗余:部分消息系统具有消息持久化的能力,可规避消息处理前丢失的风险
3.扩展:消息系统是统一的数据接口,各系统可独立扩展
4.峰值处理能力:消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取对应处理量的请求
5.可恢复性:系统中部分组件失效并不会影响整个系统,回复之后仍然可以从消息系统中获取数据
6.异步通信:在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理
常用消息系统对比:
rabbitMQ:erlang编写,支持多协议,AMQP,XMPP,SMTP,STOMP.支持负载均衡,数据持久化。同时支持peer to peer和发布/订阅模式
Redis:基于key-value的nosql数据库,同时支持MQ功能,可做轻量队列使用。就入队操作而言,对短消息(小于10kb)的处理,redis的性能比rabbitmq要好
kafka/jafka:高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理。jafka是kafka的java实现。
以及还有zeroMQ,activeMQ,MetaQ等等这里就不推荐了,个人建议使用rabbitMQ或者kafka
kafka的设计目标:
高吞吐率:在链家的商用机器上单机可支持每秒100万条消息的读写,尽管是把消息持久化到磁盘,但是不代表性能低,实际上吞吐率是相当高的
消息持久化:所有消息均被持久化到磁盘,无消息丢失,支持消息重放
完全分布式:producer,broker,consumer均支持水平扩展
同时满足适应在线流处理和离线流处理,现在的sparkStreaming也和kafka结合的比较好。也可以将kafka里的数据导入到HDFS里面,方式也比较多,一般是通过flume的kafka source将kafka的数据拿过来,在使用flume的hdfs sink或者hive sink将数据导入hdfs或者hive进行离线的流式批处理
1.kafka的介绍的更多相关文章
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- Kafka设计解析(十四)Kafka producer介绍
转载自 huxihx,原文链接 Kafka producer介绍 Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本produce ...
- kafka基础介绍
kafka基础介绍 一.kafka介绍 1.1主要功能 根据官网的介绍,kafka是一个分布式流媒体的平台,它主要有三大功能: 1.11:It lets you publish and subscri ...
- 【转帖】Kafka入门介绍
Kafka入门介绍 https://www.cnblogs.com/swordfall/p/8251700.html 最近在看hdoop的hdfs 以及看了下kafka的底层存储,发现分布式的技术基本 ...
- kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍
kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍 一.初识kafka 1.1SparkStreaming+Kafka好处: 1.2Kafka的架构: 二.k ...
- [Kafka] - Kafka 安装介绍
Kafka是由LinkedIn公司开发的,之后贡献给Apache基金会,成为Apache的一个顶级项目,开发语言为Scala.提供了各种不同语言的API,具体参考Kafka的cwiki页面: Kafk ...
- kafka搜索介绍
kafka详解 https://blog.csdn.net/liubenlong007/article/details/55211196##1 1.2 Kafka诞生 Kafka由 linked- ...
- 第1节 kafka消息队列:1、kafka基本介绍以及与传统消息队列的对比
1. Kafka介绍 l Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. l Kafka最初是由LinkedIn开发,并于20 ...
- 【Kafka】Kafka简单介绍
目录 基本介绍 概述 优点 主要应用场景 Kafka的架构 四大核心API 架构内部细节 基本介绍 概述 Kafka官网网站:http://kafka.apache.org/ Kafka是由Apach ...
- kafka综合介绍
设计目标 高吞吐率.即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输. 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输 同 ...
随机推荐
- 英特尔CEO科再奇:尚未发现通过漏洞获取用户数据的行为
1月9日消息,英特尔CEO科再奇在美国西部时间1月8日举行的2018年CES中发表主题演讲,他在开场时面向产业界谈到了最近报道的安全研究发现.科再奇表示:“在我们开始之前,我想借此机会感谢整个行业,为 ...
- UVA 1085 House of Cards(对抗搜索)
Description Axel and Birgit like to play a card game in which they build a house of cards, gaining ...
- vue2.0中vue-router使用总结
#在vue-cli所创建的项目中使用 进入到项目的目录后使用 npm install vue-router --save 安装vue-router,同时保存在webpack.Json配置文件中,然 ...
- Redis使用手册
简介 Redis 是一个开源的使用 ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型. Key-Value数据库. Redis面向互联网的方案提供了三种形式: 1.主从 主机进行写操作, ...
- Luogu3952 NOIP2017时间复杂度
搞一个栈模拟即可.对比一下和一年前考场上的代码233 //2018.11.8 #include<iostream> #include<cstdio> #include<c ...
- xinetd不太详的详解
xinetd不太详的详解 http://blog.sina.com.cn/s/blog_88cdde9f01019fg5.html ################################## ...
- [AT2558]Many Moves
题目大意:有$n$个位置$1,2,\dots n$:你有两个棋子$A$和$B$,你要进行$q$次操作,第$i$次操作给定一个$x_i$,你要选择一个棋子移动到$x_i$:求两个棋子最小移动的步数之和. ...
- BZOJ 1040: [ZJOI2008]骑士 | 在基环外向树上DP
题目: http://www.lydsy.com/JudgeOnline/problem.php?id=1040 题解: 我AC了 是自己写的 超开心 的 考虑断一条边 这样如果根节点不选答案一定正确 ...
- API网关Kong部署和使用文档
KONG安装使用说明 系统版本:ubuntu14 1.下载安装包 $ wget https://github.com/Mashape/kong/releases/download/0.8.3/kong ...
- CentOS 6.4安装配置ldap
CentOS 6.5安装配置ldap 时间:2015-07-14 00:54来源:blog.51cto.com 作者:"ly36843运维" 博客 举报 点击:274次 一.安装l ...