机器学习基础(HGL的机器学习笔记1)
统计学习:统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科,统计学习也成为统计机器人学习[1]。
统计学习分类:有监督学习与无监督学习[2]。
统计学习三要素:模型、策略与算法[1]。
统计学习的对象:统计学习的对象是数据。统计学习从数据出发,提取数据的特征,抽取数据的模型,发现数据中的指示,又回到对数据的分析与预测中去[1]。
统计学习的目的:建立输入与输出的关系,评价输入与输出的关系,即Y = f(X) + ε。其中输入变量X可以称为预测变量、自变量、属性变量及变量。输出变量Y可以称为响应变量或因变量。ε为随机误差项,与X独立且均值为0[2]。
统计学习的目的实际上就是估计f,估计f的原因主要又两个:预测与推断[2]。
预测实际上是计算出Ẏ = ḟ(X),其中Ẏ为Y值的预测值,ḟ为f的预测。Ẏ作为Y的预测,其精确性依赖两个量,一个是可约误差,另一个是不可约误差。
证明:假设ḟ与X是固定的,则
E(Y - Ẏ)^2 = E[f(X) + ε - ḟ(X)]^2 = [f(X) - ḟ(X)]^2 + Var(ε)。其中,[f(X) - ḟ(X)]^2可约误差,Var(ε)不可约误差。
E(Y - Ẏ)^2代表预测量与实际值Y的均方根误差或期望平方根误差值。Var(ε)表示误差项ε的方差。统计学习关注的重点就是最小化可约误差。
给出损失函数,损失函数是对一次预测好与坏的一种评价,损失函数越小,模型越好。常见的有:
,否则为0
平方损失函数:L(Y, ḟ(X)) = [Y - ḟ(X)]^2 (常用)
绝对损失函数:L(Y, ḟ(X)) = |Y - ḟ(X)|
对数损失函数:L(Y, P(Y|X)) = -log P(Y|X)
推断实际上就是理解输入X与输出Y的关系。换句话说,X的变化怎样影响Y的变化。
统计学习关心三类事情,一类是预测,一类是推断,还有一类是预测与推断的混合。
估计f的方法[2]
1. 参数法
- + a1
+ … + an
…an这n + 1个参数。 - 一旦模型选定,可以用训练集去拟合或训练模型。常用的线性拟合方法为最小二乘法。
参数法把估计f的问题简化为估计一组参数,因为估计参数更为容易。
参数法的缺陷:选定的模型并非与真正f的在形式上一致。假设选择的模型与真实的f相差很大,那么尝试去选择更光滑的模型。但光滑度更强的模型需要更多的参数估计,且更光滑的模型可能导致过拟合。
过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测得很好,但对于未知数据预测得很差的现象[1]。
2.非参数法
非参数法不需要对函数f的形式事先做明确的假设。相反,这类方法追求的是接近数据点的估计,估计函数在去粗和光滑处理后尽可能与更多的数据点接近。
非参数法的优点:不限定函数f的具体形式,于是可能在更大的范围选择更适合f形状估计。
非参数法的缺点:无法将估计f的问题简化到仅仅对少数参数进行估计的问题,所以为了对f更为精确的估计,往往需要大量的观测点(远远超出参数法需要的观测点)。
具体方法以后介绍。
模型评估[1]
训练误差:
训练集平均误差,即

其中,N为训练集容量,L常选择平方损失函数。
测试误差:测试集平均误差,即
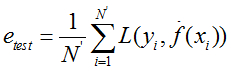
其中,N'为测试集容量,L常选择平方损失函数。
测试误差越小的方法具有更好的预测能力,更有效的方法。
模型选择——正则化与交叉验证[1]
正则化:正则化是结构风险最小化策略的实现,是载经验风险上加一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值越大。正则化一般形式为

其中,第一项为损失函数(经验风险),第二项为正则化,λ为调整两者间的关系系数。正则化原则根据具体问题具体分析,各种问题的形式不仅相同。
交叉验证:如果给定足够的数据,可以将简单的将数据分为三部分,分别为训练集、验证集与测试集。训练集用于训练模型,验证集用于模型选择,而测试集用于对最终学习方法的评估。主要包含有:
- 简单交叉验证:首先随机将数据分为两部分,一部分作为训练集,一部分作为测试集(一般按照70%训练集,30%测试集分配)。
- S交叉验证:将数据切分称互不相交且大小相同的子集,然后利用S-1个子集训练,用剩下一个子集测试,将这个过程对可能的S种选择重复进行,最终选出测试误差最小的模型。
- 留一交叉验证:S交叉验证的特殊形式是S = N,称为留一交叉验证,往往在数据缺乏的情况下使用,N是给定的数据集容量。
预测精度与模型解释性的权衡[2]
统计学习方法是在预测精度与模型解释性之间权衡,如果仅仅是对预测感兴趣,至于预测模型是否易于解释并不关心,所以选择光滑度更高的方法才是最优选择,但是光滑度越高解释性越低,甚至产生过拟合。
有监督学习与无监督学习[3]
有监督学习:对具有概念标记(分类)的训练样本进行学习,以尽可能对训练样本集外的数据进行标记(分类)预测。这里,所有的标记(分类)是已知的。典型的有监督学习方法:回归方法,分类方法等等。
无监督学习:对没有概念标记(分类)的训练样本进行学习,以发现训练样本集中的结构性知识。这里,所有的标记(分类)是未知的。因此,训练样本的岐义性高。典型无监督学习:聚类方法。
泛化能力[1]
泛化能力:学习方法的泛化能力是指由该方法学习到的模型对未知数据的预测能力。
泛化误差:对未知数据预测的误差,即
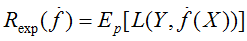
注:并没有包含[1]、[2]的全部内容,仅包含作者认为重要的内容。
[1] 《统计学习方法》,李航
[2] 《统计学习导论》,Gareth James等.
[3] http://blog.sina.com.cn/s/blog_56c221b00100gjl6.html
原创文章,转载请注明出处。
机器学习基础(HGL的机器学习笔记1)的更多相关文章
- 1.1机器学习基础-python深度机器学习
参考彭亮老师的视频教程:转载请注明出处及彭亮老师原创 视频教程: http://pan.baidu.com/s/1kVNe5EJ 1. 课程介绍 2. 机器学习 (Machine Learning, ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 机器学习框架ML.NET学习笔记【1】基本概念与系列文章目录
一.序言 微软的机器学习框架于2018年5月出了0.1版本,2019年5月发布1.0版本.期间各版本之间差异(包括命名空间.方法等)还是比较大的,随着1.0版发布,应该是趋于稳定了.之前在园子里也看到 ...
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- zz 机器学习系统或者SysML&DL笔记
机器学习系统或者SysML&DL笔记(一) Oldpan 2019年5月12日 0条评论 971次阅读 1人点赞 在使用过TVM.TensorRT等优秀的机器学习编译优化系统以及Py ...
- 深度学习与CV教程(2) | 图像分类与机器学习基础
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- Coursera 机器学习课程 机器学习基础:案例研究 证书
完成了课程1 机器学习基础:案例研究 贴个证书,继续努力完成后续的课程:
- 机器学习 —— 基础整理(六)线性判别函数:感知器、松弛算法、Ho-Kashyap算法
这篇总结继续复习分类问题.本文简单整理了以下内容: (一)线性判别函数与广义线性判别函数 (二)感知器 (三)松弛算法 (四)Ho-Kashyap算法 闲话:本篇是本系列[机器学习基础整理]在time ...
- 算法工程师<机器学习基础>
<机器学习基础> 逻辑回归,SVM,决策树 1.逻辑回归和SVM的区别是什么?各适用于解决什么问题? https://www.zhihu.com/question/24904422 2.L ...
随机推荐
- JS识别不同浏览器信息
总所周知,不同浏览器兼容是不一致的,然而今天我在Coding的时候深深体会到那个痛苦,一样的代码在Firefox里面是没问题的,可以根据索引找到 对应的对象元素然后进行操作,但是同样的却获取不到对象元 ...
- jQuery中的DOM操作——《锋利的JQuery》
jQuery封装了大量DOM操作的API,极大提高了操作DOM节点的效率. 1.查找节点 通过我们上一节介绍了JQuery选择器,可以非常轻松地查找节点元素.不过,这时得到的是jQuery对象,只能使 ...
- C# 判断List集合中是否有重复的项
/*在.Net 3.5 以上*/ ).Count() >= ;
- python的用户输入和while循环
1.函数input()工作原理 函数input()让程序暂停运行,等待用户输入一些文本.获取用户输入后,Python将其存储在一个变量中,以方便你使用. (1)获取数值可以用 int()函数 (2)求 ...
- Java使用UDP聊天程序
主要想测试Java UDP通信.Java UDP使用DatagramSocket和DatagramPacket完成UDP通信 主要思路: 1.本机通信,ip地址为:127.0.0.1 2.开一个线程监 ...
- 微信小程序入门案例
本文通过具体的实例记录微信小程序的入门知识. 1.特点 不需要安装 依赖微信应用 更接近原生APP 丰富的框架及API可达到快速开发的目的 2.工具使用 在开发的过程中可以使用微信开发者工具,更加直观 ...
- css3总结之居中
居中在前端布局上很常见,也很常用,也是最基本的技巧.居中效果在方向控制上基本可以分解成水平居中,垂直居中和水平垂直居中. 针对调整的元素不同,具体的处理方式上有些差异.这里我们先不讲绝对定位下的居中, ...
- Xshell连接不上虚拟机的问题和解决办法
第一次用xshell,一直连不上linux,搞了好久,也查了很多办法,但是最后也终于解决了,在这里我分享一下自己的解决办法,再列举网上的办法,希望可以帮助其他人. 1,你的linux ip地址没有配置 ...
- gamemakerstudio:加载精灵
如果精灵图片不是单一图片(拥有子图)可以称它为长条图,当gamemakerstudio加载这类精灵图片时,我们给图片名字命名为*_strip列数.*,这样当加载图片时gamemakerstudio会自 ...
- LESS初体验
将一个变量赋值给另一个变量,用引号:@white: 'color-white';,使用另一个变量,需要双@@符号:p {color: @@white;}. 而以这样进行变量的赋值:@white: @c ...