Apache Beam的API设计
不多说,直接上干货!
Apache Beam的API设计
Apache Beam还在开发之中,后续对应的API设计可能会有所变化,不过从当前版本来看,基于对数据处理领域对象的抽象,API的设计风格大量使用泛型来定义,具有很高的抽象级别。下面我们分别对感兴趣的的设计来详细说明。
- Source
Source表示数据输入的抽象,在API定义上分成两大类:一类是面向数据批处理的,称为BoundedSource,它能够从输入的数据集读取有限的数据记录,知道数据具有有限性的特点,从而能够对输入数据进行切分,分成一定大小的分片,进而实现数据的并行处理;另一类是面向数据流处理的,称为UnboundedSource,它所表示的数据是连续不断地进行输入,从而能够实现支持流式数据所特有的一些操作,如Checkpointing、Watermarks等。
Source对应的类设计,如下类图所示:
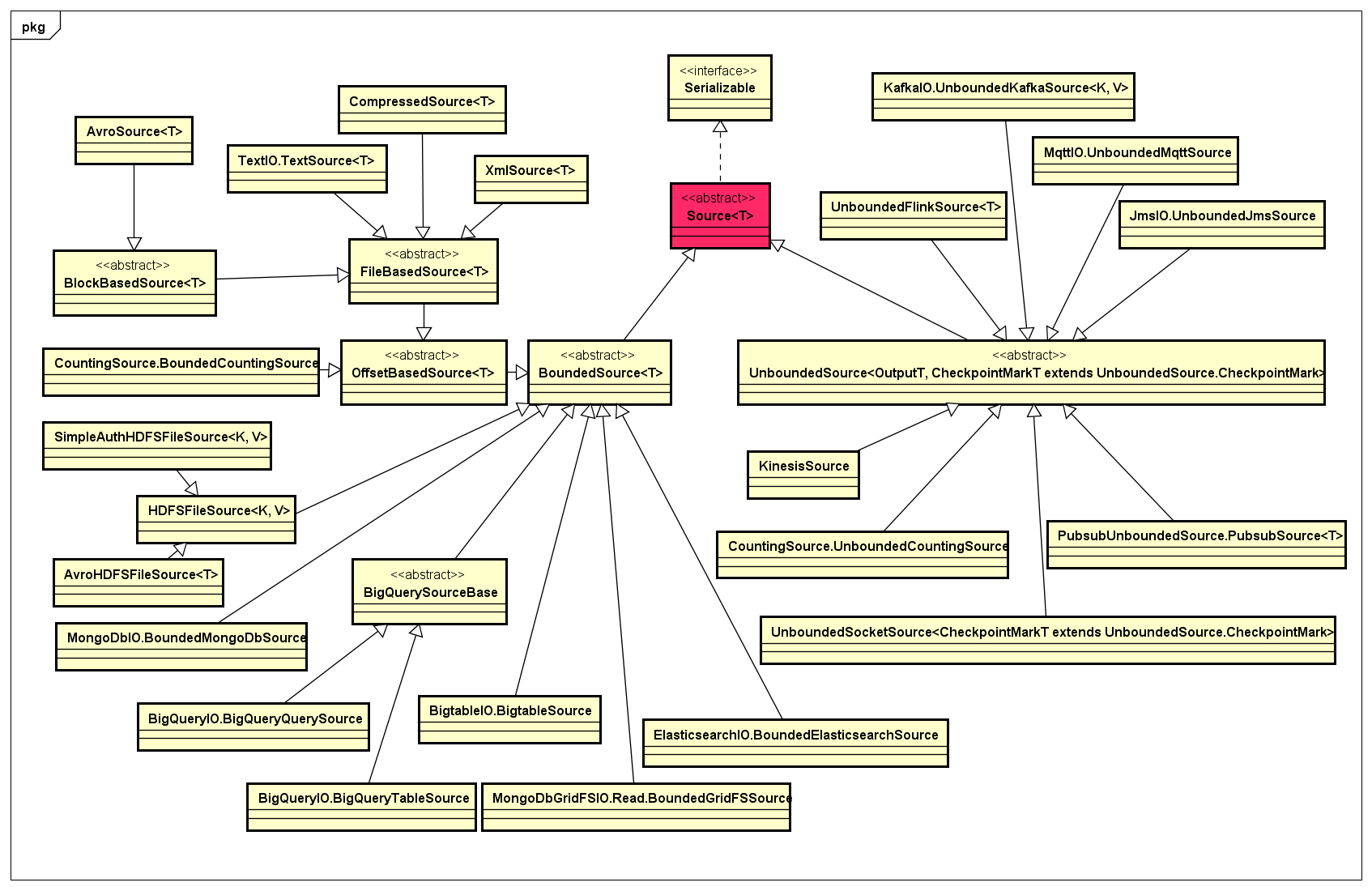
目前,Apache Beam支持BoundedSource的数据源主要有:HDFS、MongoDB、Elasticsearch、File等,支持UnboundedSource的数据源主要有:Kinesis、Pubsub、Socker等。未来,任何具有Bounded或Unbounded两类特性的数据源都可以在Apache Beam的抽象基础上实现对应的Source。
- Sink
Sink表示任何经过Pipeline中一个或多个PTransform处理过的PCollection,最终会输出到特定的存储中。与Source对应,其实Sink主要也是具有两种类型:一种是直接写入特定存储的Bounded类型,如文件系统;另一种是写入具有Unbounded特性的存储或系统中,如Flink。在API设计上,Sink的类图如下所示:

可见,基于Sink的抽象,可以实现任意可以写入的存储系统。
- PipelineRunner
下面,我们来看一下PipelineRunner的类设计以及目前开发中的PipelineRunner,如下图所示:
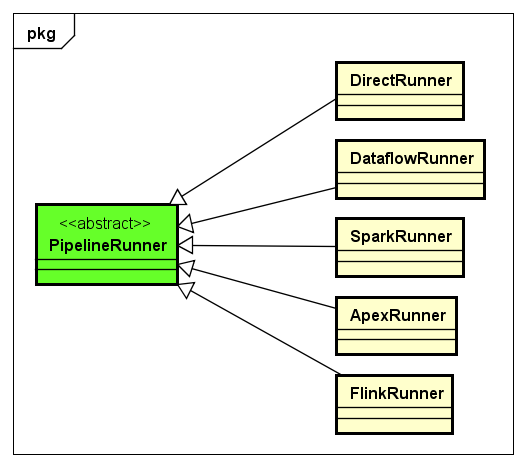
目前,PipelineRunner有DirectRunner、DataflowRunner、SparkRunner、ApexRunner、FlinkRunner,待这些主流的PipelineRunner稳定以后,如果有其他新的计算引擎框架出现,可以在PipelineRunner这一层进行扩展实现。
这些PipelineRunner中,DirectRunner是最简单的PipelineRunner,它非常有用,比如我们实现了一个从HDFS读取数据,但是需要在Spark集群上运行的ETL程序,使用DirectRunner可以在本地非常容易地调试ETL程序,调试到程序的数据处理逻辑没有问题了,再最终在实际的生产环境Spark集群上运行。如果特定的PipelineRunner所对应的计算引擎没有很好的支撑调试功能,使用DirectRunner是非常方便的。
- PCollection
PCollection是对分布式数据集的抽象,主要用作输入、输出、中间结果集。其中,在Apache Beam中对数据及其数据集的抽象有几类,我们画到一张类图上,如下图所示:
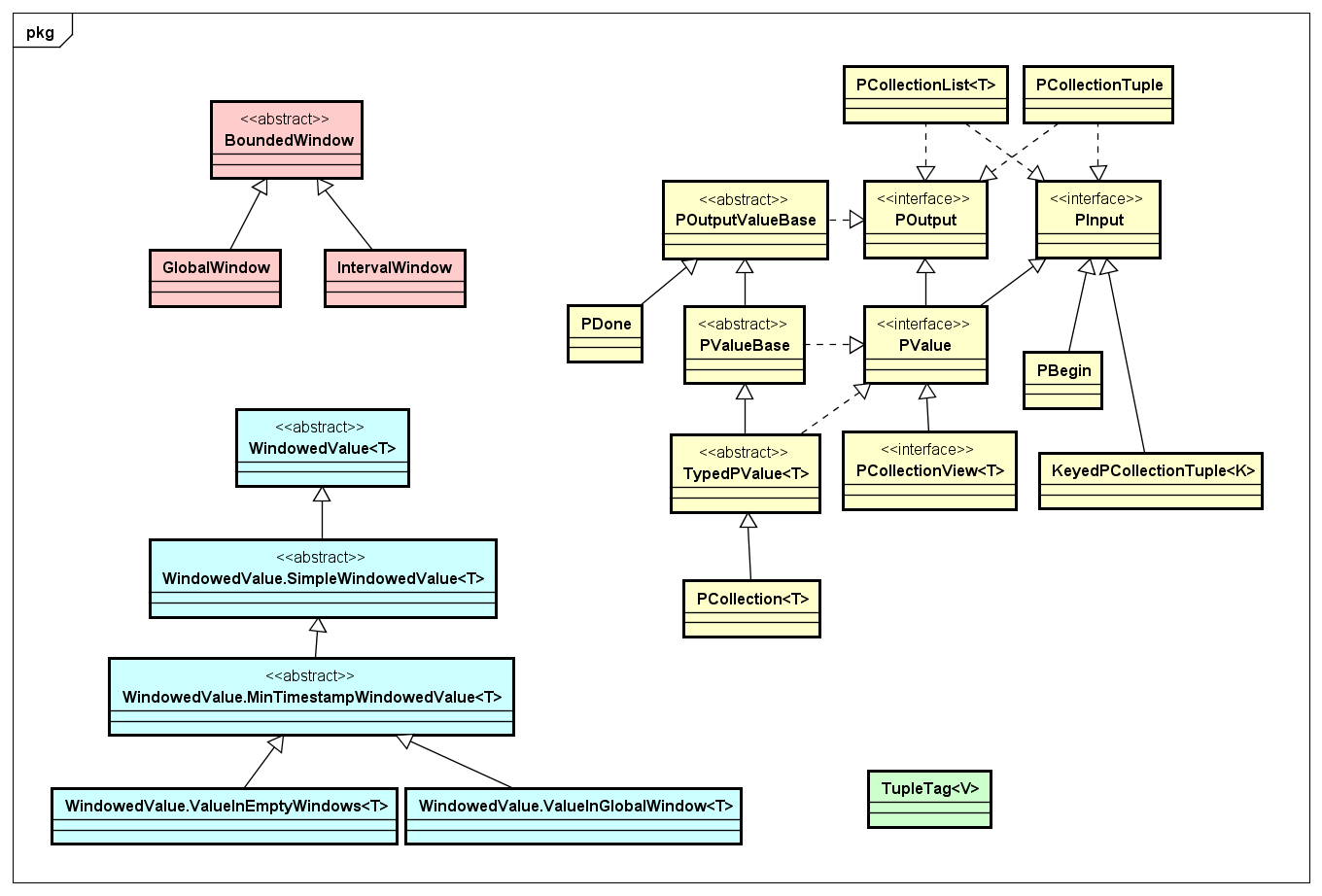
PCollection是对数据集的抽象,包括输入输出,而基于Window的数据处理有对应的Window相关的抽象,还有一类就是TupleTag,针对具有CoGroup操作的情况下用来标记对应数据中的Tuple数据,具体如何使用可以后面我们实现的Join的例子。
- PTransform
一个Pipeline是由一个或多个PTransform构建而成的DAG图,其中每一个PTransform都具有输入和输出,所以PTransform是Apache Beam中非常核心的组件,我按照PTransform的做了一下分类,如下类图所示:
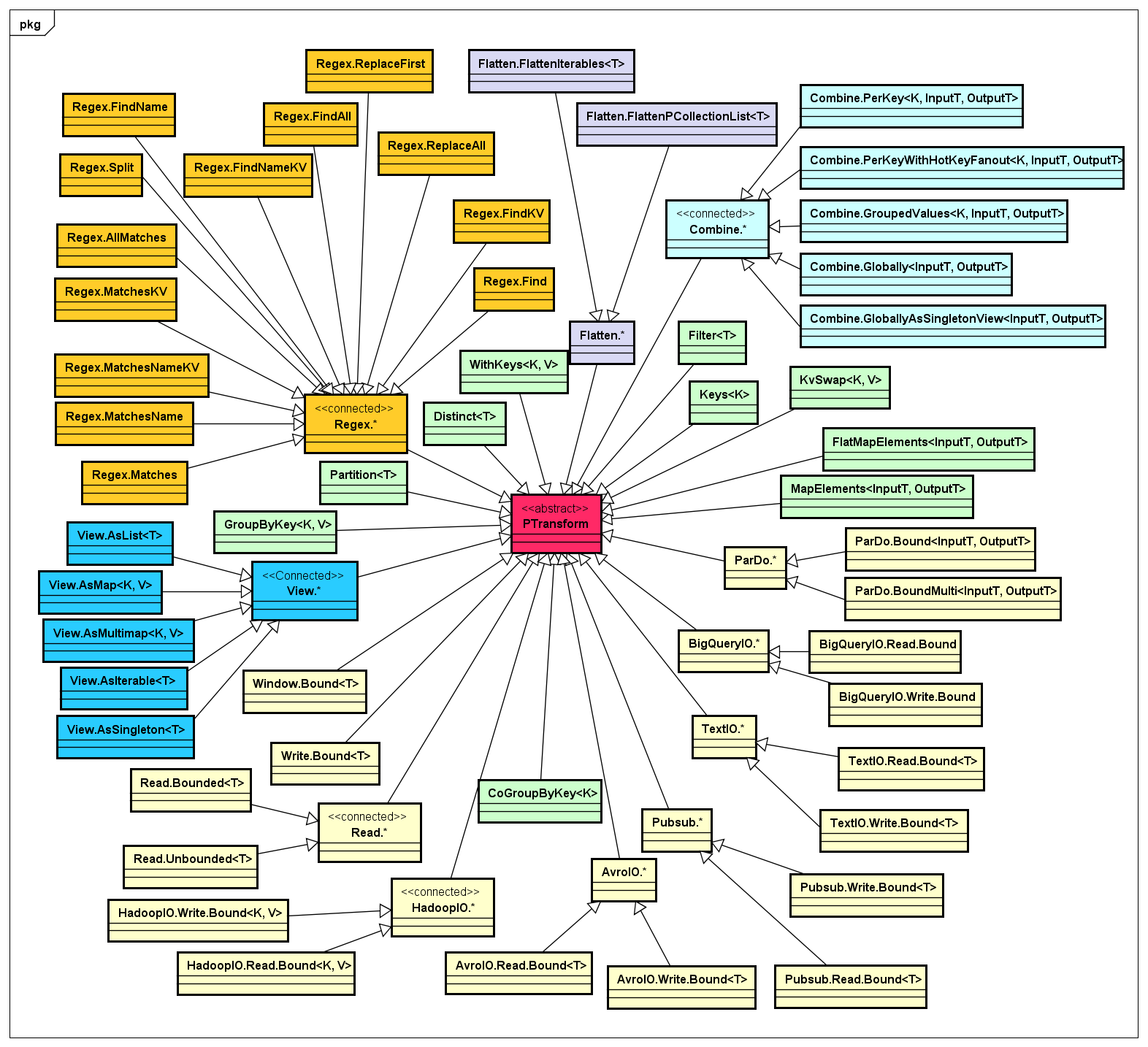
通过上图可以看出,PTransform针对不同输入或输出的数据的特征,实现了一个算子(Operator)的集合,而Apache Beam除了期望实现一些通用的PTransform实现来供数据处理的开发人员开箱即用,同时也在API的抽象级别上做的非常Open,如果你想实现自己的PTransform来处理指定数据集,只需要自定义即可。而且,随着社区的活跃及其在实际应用场景中推广和使用,会很快构建一个庞大的PTransform实现库,任何有数据处理需求的开发人员都可以共享这些组件。
- Combine
这里,单独把Combine这类合并数据集的实现拿出来,它的抽象很有趣,主要面向globally 和per-key这两类抽象,实现了一个非常丰富的PTransform算子库,对应的类图如下所示:
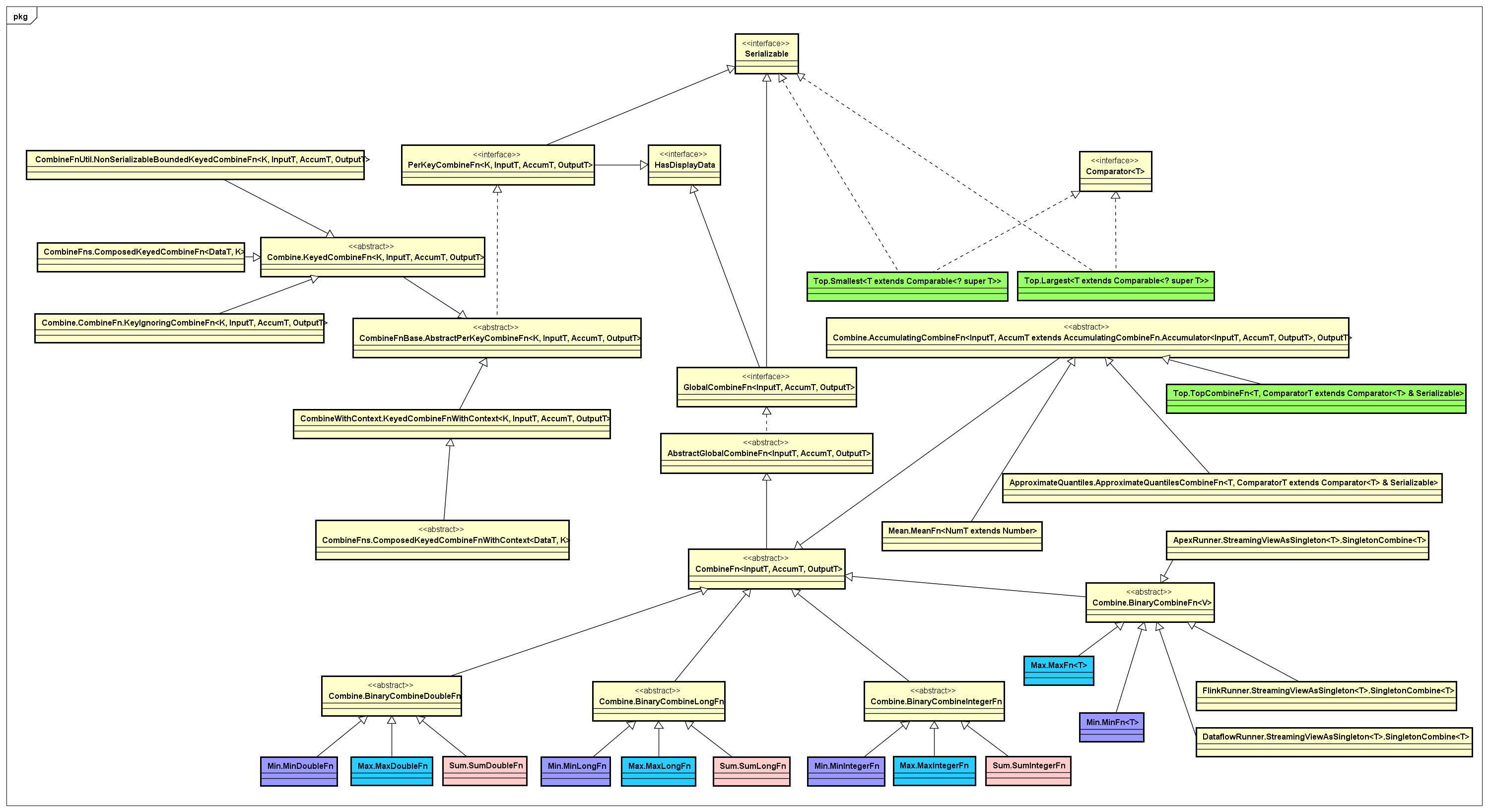
通过上图可以看出,作用在一个数据集上具有Combine特征的基本操作:Max、Min、Top、Mean、Sum、Count等等。
- Window
Window是用来处理某一个Micro batch的数据记录可以进行Merge这种场景的需求,通常用在Streaming处理的情况下。Apache Beam也提供了对Window的抽象,其中对于某一个Window下的数据的处理,是通过WindowFn接口来定义的,与该接口相关的处理类,如下类图所示:
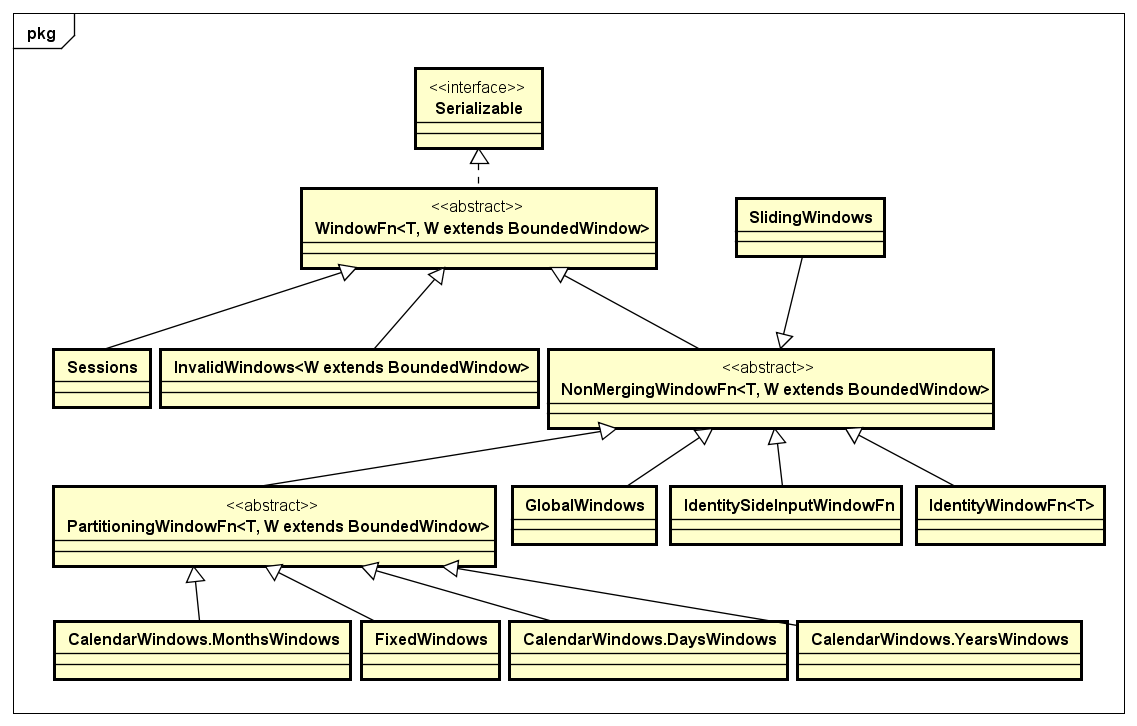
Apache Beam的API设计的更多相关文章
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- Why Apache Beam? A data Artisans perspective
https://cloud.google.com/dataflow/blog/dataflow-beam-and-spark-comparison https://github.com/apache/ ...
- Apache Beam—透视Google统一流式计算的野心
Google是最早实践大数据的公司,目前大数据繁荣的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文早就了以Hadoop为开端的整个开源大数据生态,但是很可惜的是Google内部的这些系 ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- Apache Beam编程指南
术语 Apache Beam:谷歌开源的统一批处理和流处理的编程模型和SDK. Beam: Apache Beam开源工程的简写 Beam SDK: Beam开发工具包 **Beam Java SDK ...
- Apache Beam是什么?
Apache Beam 的前世今生 1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源. 2003年,谷歌发布了著 ...
- Apache Beam: 下一代的大数据处理标准
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后 ...
- Apache Beam的架构概览
不多说,直接上干货! Apache Beam是一个开源的数据处理编程库,由Google贡献给Apache的项目,前不久刚刚成为Apache TLP项目.它提供了一个高级的.统一的编程模型,允许我们通过 ...
- Apache Beam,批处理和流式处理的融合!
1. 概述 在本教程中,我们将介绍 Apache Beam 并探讨其基本概念. 我们将首先演示使用 Apache Beam 的用例和好处,然后介绍基本概念和术语.之后,我们将通过一个简单的例子来说明 ...
随机推荐
- android eclipse 报error loading /system/media/audio/ xxx 错的解决办法。
只针对 报错..error loading /system/media/audio/ xxx.ogg 一步操作 解决烦恼..把 模拟器声音 关了..所有的错 都没了. 包括 关闭按键声音,触摸声音 ...
- [raspberry p3] suse wifi驱动加载
问题 raspberry pi3安装后发现wifi 启动不了, brcmf_sdio加载失败了,return error code为-110 处理方法 打开 /etc/dracut.conf.d/ra ...
- 【Linux-学习笔记-不定期更新】
command--help ./当前的路径 目录操作命令: mkdir 创建目录: 创建多级目录 : mkdir -p 查看目录:ls ls -a:显示所有文件,包括隐藏文件 隐藏文件以.开头 ls ...
- python 中如何判断list中是否包含某个元素
在python中可以通过in和not in关键字来判读一个list中是否包含一个元素 theList = ['a','b','c'] if 'a' in theList: print 'a in th ...
- 1221: Fibonacci数列 [数学]
1221: Fibonacci数列 [数学] 时间限制: 1 Sec 内存限制: 128 MB 提交: 116 解决: 36 统计 题目描述 Fibonacci数列的递推公式为:Fn=Fn-1+Fn- ...
- 解决JAR包里面打开源代码都是乱码
下面是解决方案 通过eclipse浏览源代码时,发现中文注释为乱码的问题.其实这个eclipse默认编码造成的问题.可以通过以下方法解决: 修改Eclipse中文本文件的默认编码:windows-&g ...
- oracle闪回存储过程
源地址:https://www.baidu.com/link?url=qgVCi_BLGOYqxJN0Fqqt-9N0SmCwtGI70SIh-TFpx1nP6oaVoMj8H6yjEqilto6TM ...
- Java面向对象之关键字super 入门实例
一.基础概念 (一)super关键字 super关键字的用法和this相似.this代表的是当前对象.super代表的是父类中内存空间. 子父类中是不会出现同名属性的情况. (二)继承中.成员变量问题 ...
- MATLAB版本(2012b 64bit),在尝试调用svmtrain函数时报错
问题:MATLAB版本(2012b 64bit),在尝试调用svmtrain函数时报错: 解决方案:参照https://blog.csdn.net/TIME_LEAF/article/details/ ...
- CF914E Palindromes in a Tree
$ \color{#0066ff}{ 题目描述 }$ 给你一颗 n 个顶点的树(连通无环图).顶点从 1 到 n 编号,并且每个顶点对应一个在'a'到't'的字母. 树上的一条路径是回文是指至少有一个 ...