scrapy_redis之官网列子domz
一. domz.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
#gihtub上面给的举例网址挂了,换成这个
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/'] #这个链接提取器秩序要定位到标签,他会自动提取链接
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
#解析过程
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
看一下和scapy的主要区别:

二. settings.py
# Scrapy settings for example project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders' #ua不同
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)' #比scrappy多了这三行
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #指定去重方法给requests对象去重
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #指定scheduler队列
SCHEDULER_PERSIST = True #队列中的内容是否持久化保存,如果为False会在会在关闭redis的时候清空redis
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" #pipline多了下面一行,并且打开的
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400, #scrapy_redis实现item保存到redis的pipline
} LOG_LEVEL = 'DEBUG' # 这个需要自己添加
#链接数据库,只要pipline开启,并且'scrapy_redis.pipelines.RedisPipeline': 400,
#那么数据就会保存到数据库,并且我们并不需要去pipline写保存的函数
REDIS_URL='redis://127.0.0.1:6379' #redis也可以这么写:
# REDIS_HOST='127.0.0.1'
# REDIS_PORT=6379 # Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
DOWNLOAD_DELAY = 1
三.运行爬虫后的的结果
进入项目文件夹,执行:
scrapy crawl domz
再看一下数据库:
·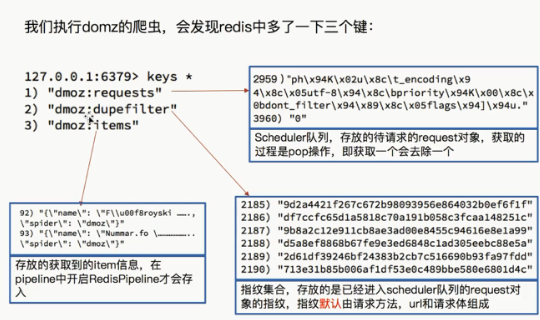
注意:
1.这个并没有用到items和pipline所以我们先研究这两个文件
四.注释掉写入reid的语句,在运行一下看下结果
在settings.py 注释这一句
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline': 400,
}
运行爬虫,发现
爬虫正常运行,但是items的数量并没有增多,说明RedisPipeline只是实现了item出具存储到redis的过程,
我们可以新建一个pipeline(或者修改example的的examplepipinne),让数据存储到任意地方
scrapy_redis之官网列子domz的更多相关文章
- React 官网列子学习
一个有状态的组件 除了接受输入数据(通过 this.props ),组件还可以保持内部状态数据(通过this.state ).当一个组件的状态数据的变化,展现的标记将被重新调用render() 更新. ...
- 转+更新 Graphviz 教程,例子+ 高级应用 写代码,编程绘制架构图(分层拓扑图) 转自官网
1. Graphviz介绍 Graphviz是大名鼎鼎的贝尔实验室的几位牛人开发的一个画图工具. 它的理念和一般的“所见即所得”的画图工具不一样,是“所想即所得”. Graphviz提供了dot语言来 ...
- 千呼万唤始出来,微软Power BI简体中文版官网终于上线了,中文文档也全了。。
前几个月时间,研究微软Power BI技术,由于没有任何文档和资料,只能在英文官网瞎折腾,同时也发布了英文文档的相关文章:系列文章,刚好上周把文章发布完,结果简体中文版上线了.哈哈,心里有苦啊,早知道 ...
- Yeoman 官网教学案例:使用 Yeoman 构建 WebApp
STEP 1:设置开发环境 与yeoman的所有交互都是通过命令行.Mac系统使用terminal.app,Linux系统使用shell,windows系统可以使用cmder/PowerShell/c ...
- 一键生成APP官网
只需要输入苹果下载地址,安卓市场下载地址,或者内测下载地址,就能一键生成APP的官网,方便在网上推广. 好推APP官网 www.hotapp.cn/app
- RavenDB官网文档翻译系列第一
本系列文章主要翻译自RavenDB官方文档,有些地方做了删减,有些内容整合在一起.欢迎有需要的朋友阅读.毕竟还是中文读起来更亲切吗.下面进入正题. 起航 获取RavenDB RavenDB可以通过Nu ...
- FineUI(开源版)v4.2.2发布(8年125个版本,官网示例突破300个)!
开源版是 FineUI 的基石,从 2008 年至今已经持续发布了 120 多个版本,拥有会员 15,000 多位,捐赠会员达到 1,200 多位. FineUI(开源版)v4.2.2 是 8 年 ...
- [干货]Chloe官网及基于NFine的后台源码毫无保留开放
扯淡 经过不少日夜的赶工,Chloe 的官网于上周正式上线.上篇博客中LZ说过要将官网以及后台源码都会开放出来,为了尽快兑现我说过的话,趁周末,我稍微整理了一下项目的源码,就今儿毫无保留的开放给大家, ...
- React.js 官网入门教程 分离文件 操作无法正常显示HelloWord
对着React官网的教程练习操作,在做到分离文件练习时,按照官网步骤来却怎么也无法正常显示HelloWord. 经测试,html文件中内容改为: <!DOCTYPE html><ht ...
随机推荐
- list 的扩展
数据挖掘中会遇到添加多个新的特征s,对一个feature = list()来说, 除了可以用 feature.append('xx') # 在尾部添加一个特征 feature.extend(['xx' ...
- SQLite在php中的接口
sqlite是一种比较轻型的嵌入式数据库,它与 SQL 之间的不同,为什么需要它,以及它的应用程序数据库处理方式.SQLite是一个软件库,实现了自给自足的.无服务器的.零配置的.事务性的 SQL 数 ...
- 过渡函数transition-timing-function
- (转)15个非常棒的jQuery无限滚动插件【瀑布流效果】
原文地址:http://www.cnblogs.com/lyw0301/archive/2013/06/19/3145084.html 现在,最热门的网站分页趋势之一是jQuery的无限滚动(也即瀑布 ...
- ORCHARD学习教程-安装
安装说明:测试对象为正式版1.8 安装方法: 使用Microsoft Web Platform Installer 利用Microsoft WebMatrix 来安装 Working with Orc ...
- 洛谷P2420 让我们异或吧(树链剖分)
题目描述异或是一种神奇的运算,大部分人把它总结成不进位加法. 在生活中…xor运算也很常见.比如,对于一个问题的回答,是为1,否为0.那么: (A是否是男生 )xor( B是否是男生)=A和B是否能够 ...
- Snapshot--使用脚本创建快照
USE master; SET NOCOUNT ON; GO ); --数据库名 );--快照名 );--保存路径 SET @dbname='DB1'; SET @snapname='DB1_SNAP ...
- wp socket tcp链接
using System; using System.Net; /// <summary> /// 客户端通过TCP/IP连接服务端的方法,包含连接,发送数据,接收数据功能 /// < ...
- L - Ch’s gift HDU - 6162
Ch’s gift Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total S ...
- Ecliplse导入maven项目applicationContext.xml报错:Referenced file contains errors (http://www.springframework.org/schema/context/spring-context-3.1.xsd). For more information, right click on the message in
刚刚导入的maven项目的Spring配置文件报错: 大体意思是说: 引用的文件包含错误(http://www.springframework.org/schema/context/springing ...