5.MySQL优化---索引优化专题
来自互联网,整理转载.
摘要:
多关于索引,分为以下几点来讲解:
一、索引的概述(什么是索引,索引的优缺点)
二、索引的基本使用(创建索引)
三、索引的基本原理(面试重点)
四、索引的数据结构(B树,hash)
五、创建索引的原则(重中之重,面试必问!敬请收藏!)
六、百万级别或以上的数据如何删除
一、索引的概述
1)什么是索引?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,索引就相当于目录。当你在用新华字典时,帮你把目录撕掉了,你查询某个字开头的成语只能从第一页翻到第一千页。累!把目录还给你,则能快速定位!
2)索引的优缺点:
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。且通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。但是,索引也是有缺点的:索引需要额外的维护成本;因为索引文件是单独存在的文件,对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。
二、索引的基本使用
1)创建索引:(三种方式)
第一种方式:
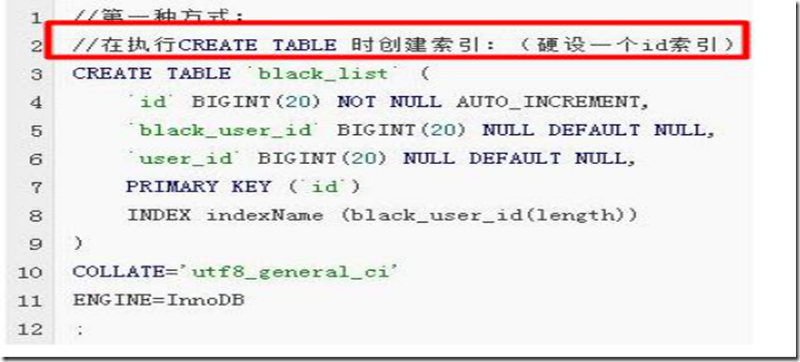
第二种方式:使用ALTER TABLE命令去增加索引:
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。

其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
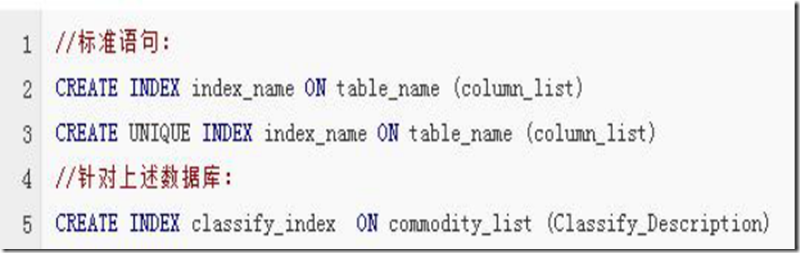
第三种方式:使用CREATE INDEX命令创建
CREATE INDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARY KEY索引)
三、索引的基本原理
索引用来快速地寻找那些具有特定值的记录。
如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询
1、把创建了索引的列的内容进行排序
2、对排序结果生成倒排表
3、在倒排表内容上拼上数据地址链
4、在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
四、索引的数据结构(b树,hash)
1)B树索引
mysql通过存储引擎取数据,基本上90%的人用的就是InnoDB了,按照实现方式分,InnoDB的索引类型目前只有两种:BTREE(B树)索引和HASH索引。B树索引是Mysql数据库中使用最频繁的索引类型,基本所有存储引擎都支持BTree索引。通常我们说的索引不出意外指的就是(B树)索引(实际是用B+树实现的,因为在查看表索引时,mysql一律打印BTREE,所以简称为B树索引)
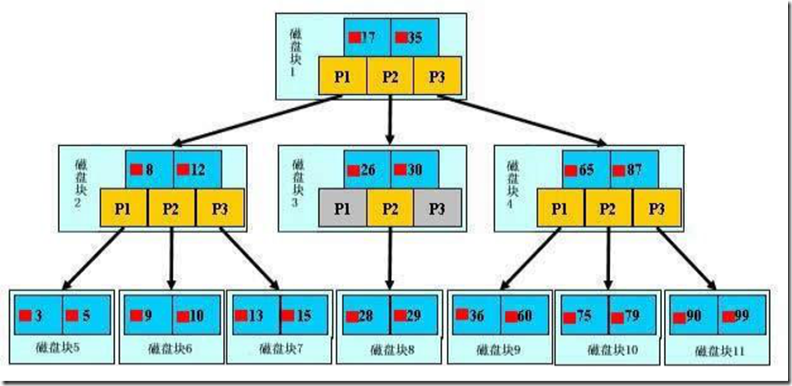
查询方式:
主键索引区:PI(关联保存的时数据的地址)按主键查询.
普通索引区:si(关联的id的地址,然后再到达上面的地址)。所以按主键查询,速度最快
B+tree性质:
1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
4.)B+ 树中,数据对象的插入和删除仅在叶节点上进行。
5.)B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
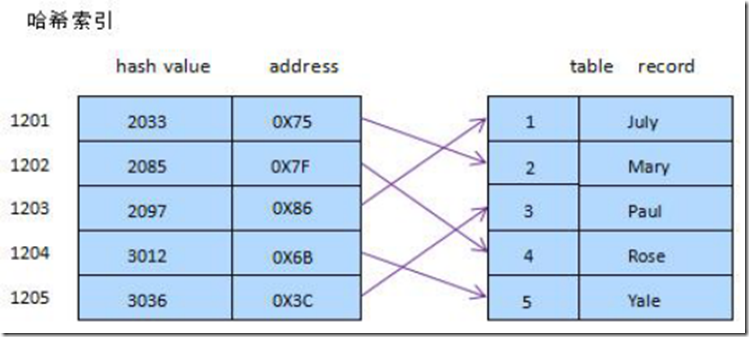
哈希索引(好技术文)
简要说下,类似于数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。
五、创建索引的原则(重中之重)
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1)最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
六、百万级别或以上的数据如何删除
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
我们想要删除百万数据的时候步骤如下:
1.可以先删除索引(此时大概耗时三分多钟)
2.然后删除其中无用数据(此过程需要不到两分钟)
3.删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
注意:与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
5.MySQL优化---索引优化专题的更多相关文章
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- mysql数据库索引优化与实践(一)
前言 mysql数据库是现在应用最广泛的数据库系统.与数据库打交道是每个Java程序员日常工作之一,索引优化是必备的技能之一. 为什么要了解索引 真实案例 案例一:大学有段时间学习爬虫,爬取了知乎30 ...
- 【mysql】索引优化记录
基础知识 Innodb存储引擎 支持行锁 支持事务: Myisam存储引擎 只支持表锁: 不支持事务: 常见索引列表 独立的列 前缀索引(索引选择性) 多列索引(并不是多个单列索引,索引顺序很重要) ...
- MySQL高级-索引优化
索引失效 1. 2.最佳左前缀法则 4. 8. 使用覆盖索引解决这个问题. 二.索引优化 1.ORDER BY 子句,尽量使用Index方式排序,避免使用FileSort方式排序 MySQL支持两种方 ...
- MySQL的索引优化,查询优化
MySQL逻辑架构 如果能在头脑中构建一幅MySQL各组件之间如何协同工作的架构图,有助于深入理解MySQL服务器.下图展示了MySQL的逻辑架构图. MySQL逻辑架构,来自:高性能MySQL My ...
- mysql数据库索引优化
参考 :http://www.cnblogs.com/yangmei123/archive/2016/04/10/5375723.html MySQL数据库的优化: 数据库优化的目的: ...
- MySQL的索引优化分析(一)
一.SQL分析 性能下降.SQL慢.执行时间长.等待时间长 查询语句写的差 索引失效关联查询太多join(设计缺陷) 单值索引:在user表中给name属性创建索引,create index idx_ ...
- MySQL的索引优化分析(二)
一.索引优化 1,单表索引优化 建表 CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO ...
- mysql前缀索引优化示例
现有一数据表,数据量79W, 微信openid字段为定长28位char型,目前是做的全字段索引,需要做一下索引优化,. 我们先来看下选择性, 全字段索引的: SELECT COUNT(DISTINCT ...
随机推荐
- 基于CentOS的SSHD服务的Docker镜像
原文地址 1.Dockerfile文件 FROM registry.aliyuncs.com/acs-sample/centos:6 MAINTAINER xuqh "xqh_163@163 ...
- 剑指offer 面试60题
面试60题 题目:把n个骰子扔在地上,所有骰子朝上一面的点数之和为s.输入n,打印出s的所有可能的值出现的概率. 解决代码:
- oracle 函数 截取 连接 替换 判断
一个处理不规范日期的函数,廖记一下吧,以免再忘. --注意全角半角 CREATE OR REPLACE function f_str2form( date_string in varchar2 ) r ...
- 【HackerRank】QuickSort(稳定快排,空间复杂度O(n))
QuickSort In the previous challenge, you wrote a partition method to split an array into 2 sub-array ...
- 父元素设置overflow,绝对定位的子元素会被隐藏或一起滚动
一般情况: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <met ...
- gradle配置笔记
apply plugin 使用插件 group 包名 version 项目版本 sourceCompatibility 指定编译.java文件的jdk版本 targetCompatibility 确保 ...
- strspn() 和 strcspn() 函数【转】
本文转载自:https://flyer103.wordpress.com/2011/06/03/strspn-%E5%92%8C-strcspn-%E5%87%BD%E6%95%B0/ 前几天在看一本 ...
- 项目打包部署到tomcat操作步骤
对于项目部署到tomcat中,需进行一下步骤: 1.对于项目打war包,方式有以下几种:install一下 找到war包的路径即可 另外:在eclipse中,选中项目 1.1 选中Export 1 ...
- linux基础(3)-java安装
安装jdk1.8 [root@spark1 usr]# mkdir java #创建java目录 通过WinSCP将jdk-8u77-linux-x64.tar.gz传到/usr/java目录下 [r ...
- dr01_SetColor
1. TGraphicUnit.SetColor 2. 3.