(数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接用来聚类分析的函数,但是要想掌握一种方法就得深刻地理解它的思想,因此自己从最底层开始编写代码来实现这个过程是最好的学习方法,所以本篇前半段是笔者自己写的代码,如有不细致的地方,望指出。
一、仅使用numpy包进行系统聚类的实现:
'''以重心法为距离选择方法搭建的系统聚类算法原型'''
# @Feffery
# @说明:目前仅支持维度为2,重心法的情况 import numpy as np
import time price = [1.1,1.2,1.3,1.4,10,11,20,21,33,34]
increase = [1 for i in range(10)]
data = np.array([price,increase],dtype='float32') class Myhcluster(): def __init__(self):
print('开始进行系统聚类')
'''系统聚类法的启动函数,有输入变量和距离计算方法两个输入参数'''
def prepare(self,data,method='zx'):
if method == 'zx':
self.zx(data)
'''重心法进行系统聚类'''
def zx(self,data):
token = len(data[0,:])
flu_data = data.copy()
classfier =[[] for i in range(len(data[1,]))]
LSdist = np.array([0 for i in range(token ** 2)], dtype='float32').reshape([len(data[0, :]), token])
index = 0
while token > 1:
'''计算距离矩阵'''
for i in range(len(data[0,:])):
for j in range(len(data[0,:])):
LSdist[i,j] = round(((flu_data[0,i]-flu_data[0,j])**2+(flu_data[1,i]-flu_data[1,j])**2)**0.5,4) '''将距离矩阵中的0元素替换为NAN'''
for i in range(len(data[0,:])):
for j in range(len(data[0,:])):
if LSdist[i,j] == 0:
LSdist[i,j] = np.nan '''保存该次系统聚类中最短距离对应的两个样本的标号'''
T = set([np.argwhere(LSdist == np.nanmin(LSdist))[0,0],np.argwhere(LSdist == np.nanmin(LSdist))[0,1]])
TT = [i for i in T] '''针对该次聚类情况进行产生新子类亦或是归入旧子类的选择'''
RQ = TT
for x in range(len(classfier)):
if classfier[0] == []:#判断是否为n个样本中第一次迭代产生新类
classfier[0] = TT
index = 0
break
elif classfier[-2] != []:#判断是否已在理论最大归类次数前完成所有样品的聚类
print('最后一次分类,获得由样本{}组成的新类'.format([__ for __ in range(len(data[1,]))]))
return 0
elif TT[0] in classfier[x] or TT[1] in classfier[x]:
if classfier[x+1]==[]:
classfier[x+1] = list(set(classfier[x]).union(set(RQ)))
index = x+1
break
else:
RQ = list(set(classfier[x]).union(set(RQ)))
classfier[len(data[1,])-token] = RQ
continue
elif x == len(data[1,])-1:
classfier[len(data[0,:])-token] = TT
index = len(data[0,:])-token
print('第{}次分类,获得由样本{}组成的新类'.format(str(len(data[0,:])-token+1),set(classfier[index])))
#求得重心并对原数据进行覆盖
for k in set(classfier[index]):
flu_data[0,k] = np.mean([data[0,_] for _ in set(classfier[index])])
flu_data[1,k] = np.mean([data[1, _] for _ in set(classfier[index])])
token -= 1 a = time.clock()
dd = Myhcluster()#进行算法封装的类的传递
dd.prepare(data)#调用类中的系统聚类法(默认重心法)
print('自己编写的系统聚类算法使用了'+str(round(time.clock()-a,3))+'秒')

与Scipy中系统聚类方法进行比较:
'''与Scipy中自带的层次聚类方法进行比较'''
import scipy.cluster.hierarchy as sch
import numpy as np a = time.clock()
disMat = sch.distance.pdist(data.T,'euclidean') Z=sch.linkage(disMat,method='average') sch.dendrogram(Z)
print('Scipy中的系统聚类算法用了'+str(round(time.clock()-a,3))+'秒')
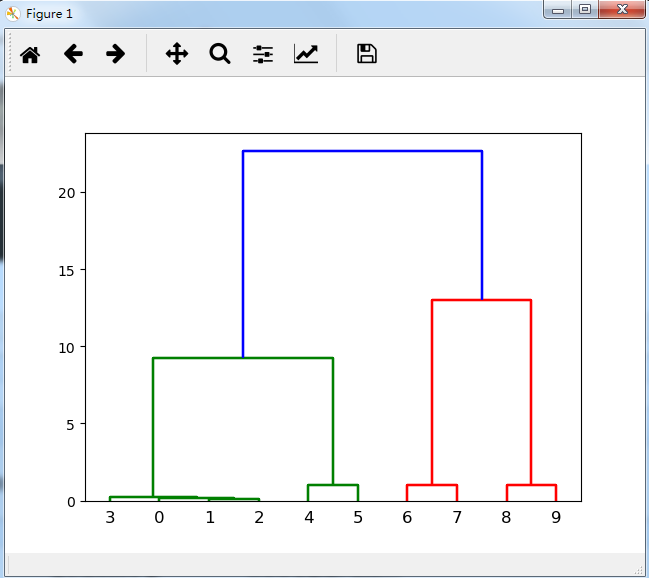
与R自带系统聚类算法进行比较:
> #系统聚类法的R实现
> rm(list=ls())
> a <- Sys.time()
> price <- c(1.1,1.2,1.3,1.4,10,11,20,21,33,34)
> increase <- rep(1,10)
> data <- data.frame(price,increase)#生成样本数据框
> d <- dist(data)#创建样本距离阵
> hc <- hclust(d,'centroid')#用重心法进行系统聚类
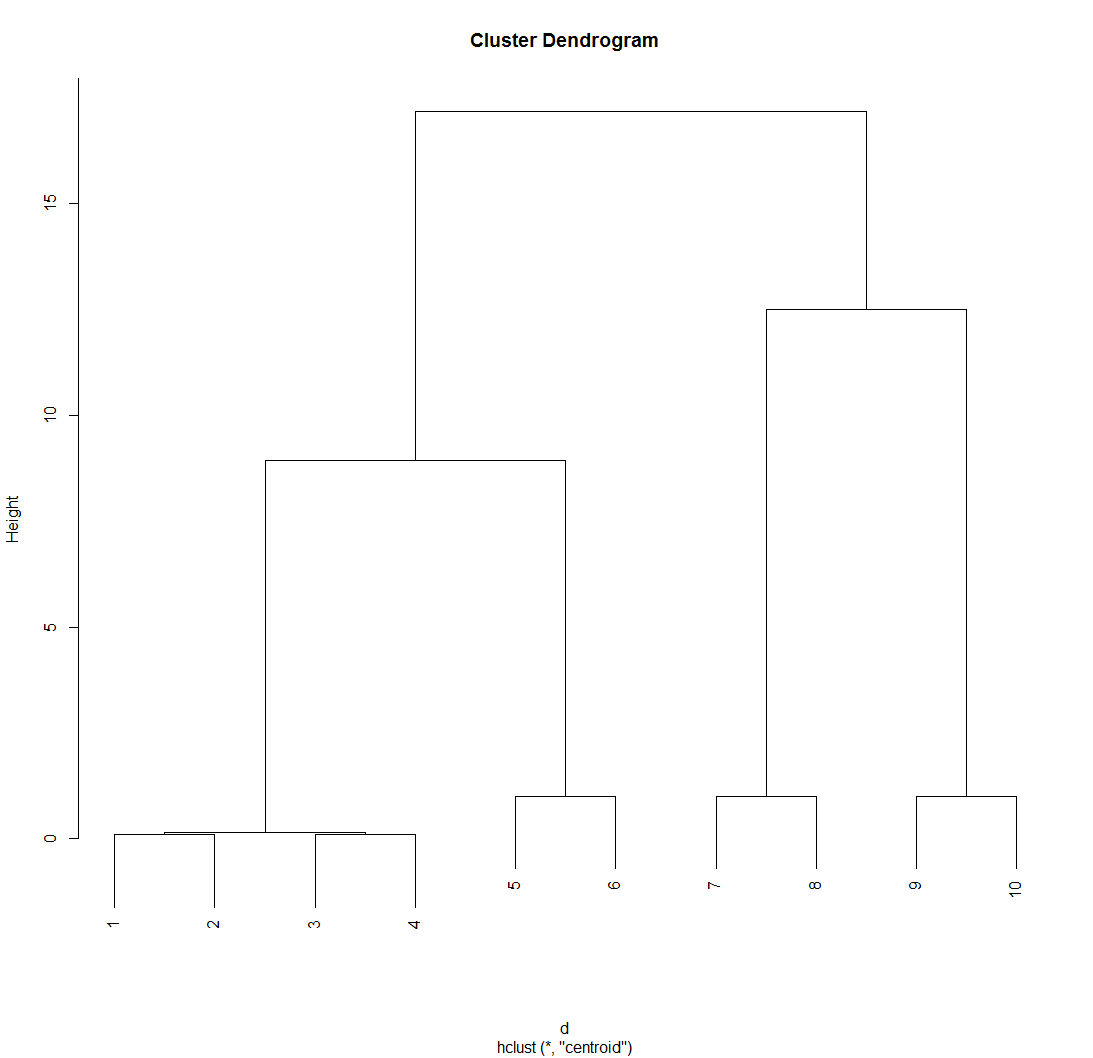
> cbind(hc$merge, hc$height)#展示分类过程
[,1] [,2] [,3]
[1,] -1 -2 0.10000
[2,] -3 -4 0.10000
[3,] 1 2 0.15000
[4,] -5 -6 1.00000
[5,] -7 -8 1.00000
[6,] -9 -10 1.00000
[7,] 3 4 8.93750
[8,] 5 6 12.50000
[9,] 7 8 17.18056
> Sys.time() - a
Time difference of 0.007000923 secs
> plot(hc)#绘制层次聚类图
(数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)的更多相关文章
- (数据科学学习手札22)主成分分析法在Python与R中的基本功能实现
上一篇中我们详细介绍推导了主成分分析法的原理,并基于Python通过自编函数实现了挑选主成分的过程,而在Python与R中都有比较成熟的主成分分析函数,本篇我们就对这些方法进行介绍: R 在R的基础函 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- SpringBoot 启动参数设置环境变量、JVM参数、tomcat远程调试
java命令的模版:java [-options] -jar jarfile [args...] 先贴一下我的简单的启动命令: java -Xms128m -Xmx256m -Xdebug -Xrun ...
- Browser进程和浏览器内核(Renderer进程)的通信过程
看到这里,首先,应该对浏览器内的进程和线程都有一定理解了,那么接下来,再谈谈浏览器的Browser进程(控制进程)是如何和内核通信的, 这点也理解后,就可以将这部分的知识串联起来,从头到尾有一个完整的 ...
- 转载: Centos7 升级python3,解决升级后不兼容问题
Centos7配置更新国内yum源 http://blog.csdn.net/qingguiyu/article/details/50721956 Centos7 升级python3,解决升级后不兼容 ...
- day3 函数、递归、及内置函数
请查看我的云笔记链接: http://note.youdao.com/noteshare?id=7d5aa803981ae4375a1f648f48e7ade3&sub=5DFD553A6C5 ...
- C++ double 小数精度控制
第一种方法:cout<<fixed<<setprecision(20)<<mydouble<<endl; #include <iostream&g ...
- 关于git的使用
一.关于GIT Git --- The stupid content tracker, 傻瓜内容跟踪器.Linus Torvalds 是这样给我们介绍 Git 的. Git 是用于 Linux内核 ...
- IOS PushMeBaby(是一款用来测试ANPs的开源Mac项目)
● PushMeBaby是一款用来测试ANPs的开源Mac项目 ● 它充当了服务器的作用,用法非常简单 ● 它负责将内容提交给苹果的APNs服务器,苹果的APNs服务器再将内容推送给用户 的设备 ● ...
- Gym 101334C 无向仙人掌
给出图,求他的“仙人掌度”,即求包括他自身的生成子图有多少? 只能删去仙人掌上的叶子的一条边,然后根据乘法原理相乘: 1.怎么求一个仙人掌叶子上有多少边? 可以利用点,边双连通的时间戳这个概念,但是绝 ...
- 【转】 Android Fragment 真正的完全解析(下)
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/37992017 上篇博客中已经介绍了Fragment产生原因,以及一些基本的用法和 ...
- System.Chare的成员
实现效果: 知识运用: System.Char的静态方法 (判断一个给定的字符是否为数字 字母 标点符号或其他) 实现效果: static void CharFunctionality() { Con ...