Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言
1.理论知识:UFLDL教程、Deep learning:十六(deep networks)
2.实验环境:win7, matlab2015b,16G内存,2T硬盘
3.实验内容:Exercise: Implement deep networks for digit classification。利用深度网络完成MNIST手写数字数据库中手写数字的识别。即:用6万个已标注数据(即:6万张28*28的图像块(patches)),作为训练数据集,然后把它输入到栈式自编码器中,它的第一层自编码器提取出训练数据集的一阶特征,接着把这个一阶特征输入到第二层自编码器中提取出二阶特征,然后把把这个二阶特征输入到softmax分类器,再用原始数据的标签和二阶特征来训练softmax分类器,最后利用BP算法对整个网络的权重值进行微调以更好地学习数据,再用1万个已标注数据(即:1万张28*28的图像块(patches))作为测试数据集,用前面训练好的softmax分类器对测试数据集进行分类,并计算分类的正确率。本节整个网络结构如下:

注意:本节实验与Deep Learning六:Softmax Regression_Exercise(斯坦福大学深度学习教程UFLDL)和Deep Learning七:Self-Taught Learning_Exercise(斯坦福大学深度学习教程UFLDL)的区别如下:
Deep Learning六:Softmax Regression_Exercise(斯坦福大学深度学习教程UFLDL)用原始数据本身作训练集直接输入softmax分类器分类,Deep Learning七:Self-Taught Learning_Exercise(斯坦福大学深度学习教程UFLDL)是从原始数据中提取特征作训练集,再把其特征输入softmax分类器分类,而本节实验是从原始数据中提取特征作训练集,再把其特征输入softmax分类器分类,最后再用大量已标注数据对整个网络的权重值进行微调,从而得到更好的分类结果。所以,最后结果能看出,本节实验方法得到的准确率97.590%高于Deep Learning六:Softmax Regression_Exercise(斯坦福大学深度学习教程UFLDL)中得到的准确率92.640%。对于Deep Learning七:Self-Taught Learning_Exercise(斯坦福大学深度学习教程UFLDL),因为它的训练样本不一样,故其准确率结果不能直接比较。但是,本节实验对进行微调前后的准确率作了对比,见本节实验结果。
4.本节方法适用范围
在什么时候应用微调?通常仅在有大量已标注训练数据的情况下使用。在这样的情况下,微调能显著提升分类器性能。然而,如果有大量未标注数据集(用于非监督特征学习/预训练),却只有相对较少的已标注训练集,微调的作用非常有限,这时可用Deep Learning七:Self-Taught Learning_Exercise(斯坦福大学深度学习教程UFLDL)中介绍的方法。
5.一些matlab函数
[params, netconfig] = stack2params(stack)
是将stack层次的网络参数(可能是多个参数)转换成一个向量params,这样有利用使用各种优化算法来进行优化操作。Netconfig中保存的是该网络的相关信息,其中netconfig.inputsize表示的是网络的输入层节点的个数。netconfig.layersizes中的元素分别表示每一个隐含层对应节点的个数。
[ cost, grad ] = stackedAECost(theta, inputSize, hiddenSize, numClasses, netconfig,lambda, data, labels)
该函数内部实现整个网络损失函数和损失函数对每个参数偏导的计算。其中损失函数是个实数值,当然就只有1个了,其计算方法是根据sofmax分类器来计算的,只需知道标签值和softmax输出层的值即可。而损失函数对所有参数的偏导却有很多个,因此每个参数处应该就有一个偏导值,这些参数不仅包括了多个隐含层的,而且还包括了softmax那个网络层的。其中softmax那部分的偏导是根据其公式直接获得,而深度网络层那部分这通过BP算法方向推理得到(即先计算每一层的误差值,然后利用该误差值计算参数w和b)。
stack = params2stack(params, netconfig)
和上面的函数功能相反,是吧一个向量参数按照深度网络的结构依次展开。
[pred] = stackedAEPredict(theta, inputSize, hiddenSize, numClasses, netconfig, data)
这个函数其实就是对输入的data数据进行预测,看该data对应的输出类别是多少。其中theta为整个网络的参数(包括了分类器部分的网络),numClasses为所需分类的类别,netconfig为网络的结构参数。
[h, array] = display_network(A, opt_normalize, opt_graycolor, cols, opt_colmajor)
该函数是用来显示矩阵A的,此时要求A中的每一列为一个权值,并且A是完全平方数。函数运行后会将A中每一列显示为一个小的patch图像,具体的有多少个patch和patch之间该怎么摆设是程序内部自动决定的。
struct:
s = sturct;表示创建一个结构数组s。
nargout:
表示函数输出参数的个数。
save:
比如函数save('saves/step2.mat', 'sae1OptTheta');则要求当前目录下有saves这个目录,否则该语句会调用失败的。
栈式自编码神经网络是一个由多层稀疏自编码器组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。
6.解疑
1. 解决了Deep Learning六:Softmax Regression_Exercise(斯坦福大学深度学习教程UFLDL)中提出的一个问题:
在softmaxExercise.m中有如下一句代码:
images = loadMNISTImages('train-images.idx3-ubyte');
labels = loadMNISTLabels('train-labels.idx1-ubyte');
labels(labels==0) = 10; % 把标签0变为标签10,故labels的值是[1,10],而原来是[0,9] ?为什么非要这样?
为什么非要把原来的标签0变为标签10呢?搞不懂!
这个问题在本节实验中的stackedAEExercise.m中也有:
trainLabels(trainLabels == 0) = 10; % 一直没搞懂,为什么非要把标签0变为10?
原因:为了方便后面预测分类结果时,能直接通过max函数返回的是大值的列号就是所预测的分类结果。如本节实验中stackedAEPredict.m中的这句话:
[prob pred] = max(softmaxTheta*a{depth+1});
其中pred就是保存的所要预测的结果。
7. 疑问
1.如果我们后面的分类器不是用的softmax分类器,而是用的其它的,比如svm等,这个时候前面特征提取的网络参数已经预训练好了,用该参数是可以初始化前面的网络,但是此时该怎么微调呢?
2.从代码中,可以看出整个网络的代价函数实际上就是softmax分类器的代价函数,这是怎么推导来的?
3.第二个隐含层的特征怎么显示出来?这个问题折腾了我好几天,然后最近还因为发一篇论文各种折腾,所以一直没有静下心来想这个问题。
为了解答这个问题,有必要把显示每一层特征的函数display_network.m完全看懂,搞懂为什么不能按照用它显示第一层特征的方式来显示第二特征,所以在这里我详细注释了display_network.m的代码,见下面。
首先,要清楚第二个隐含层特征显示不出来的原因是什么,很多人(比如:Deep learning:二十四(stacked autoencoder练习))以为是这个原因: 因为display_network.m这个函数要求隐含层神经元数的均方根必须是整数,而在本节实验中隐含层神经元数设置的是200,它不是一个整数的平方,所以不能显示出来,但这只是一个程序编写的问题,实际上这个问题很好解决,我们只需要把隐含层神经元数设置为196,就可以用按照显示第一层特征的方式用函数display_network.m把它显示出。但实际上并不是这个原因,具体我们可以从下面得到的结果证明,结果如下:
隐含层神经元数设置为196时,第一层特征可视化为:

隐含层神经元数设置为196时,第二层特征可视化为:

从第二层特征的可视化结果可看出,上面实现第二层可视化的方式肯定是错的,因为它并没有显示出什么点、角等特征。
那么,它究竟为什么不能这样显示,究竟该怎么样显示呢?这实际上是一个深度学习的一个研究方向,具体可参考:Deep Learning论文笔记之(七)深度网络高层特征可视化
8 代价函数
Ng没有直接给出代价函数,但可能通过代码看出他的代价函数.他的计算代价函数的代码如下:
depth = size(stack, ); % 隐藏层的数量
a = cell(depth+, ); % 输入层和隐藏层的输出值,即:输入层的输出值和隐藏层的激活值
a{} = data; % 输入层的输出值
Jweight = ; % 权重惩罚项
m = size(data, ); % 样本数 % 计算隐藏层的激活值
for i=:numel(a)
a{i} = sigmoid(stack{i-}.w*a{i-}+repmat(stack{i-}.b, [ size(a{i-}, )]));
%Jweight = Jweight + sum(sum(stack{i-}.w).^);
end M = softmaxTheta*a{depth+}; % a{depth+}为最后一层隐藏层的输出,此时M为输入softmax层的数据,即它是未计算softmax层激活函数前的数值.
M = bsxfun(@minus, M, max(M, [], )); %防止下一步计算指数函数时溢出
M = exp(M);
p = bsxfun(@rdivide, M, sum(M)); % p为softmax层的输出,就是每种类别的分类概率 Jweight = Jweight + sum(softmaxTheta(:).^); % softmaxTheta是softmax层的权重参数 % 计算softmax分类器的代价函数,为什么它就是整个模型的代价函数?
cost = -/m .* groundTruth(:)'*log(p(:)) + lambda/2*Jweight;% 代价函数=均方差项+权重衰减项(也叫:规则化项)
所以,其代价函数实际上就是softmax分类器的代价函数,而softmax的代价函数可见Softmax回归,即代价函数为:
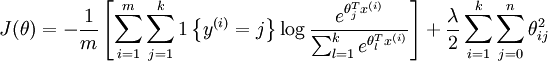
实验步骤
1.初始化参数,加载MNIST手写数字数据库。
2.利用原始数据训练第一个自编码器,得到它的权重参数值sae1OptTheta,通过sae1OptTheta可得到原始数据的一阶特征sae1Features。
3.利用一阶特征sae1Features训练第二个自编码器,得到它的权重参数值sae2OptTheta,通过sae2OptTheta可得到原始数据的二阶特征sae2Features。
4.利用二阶特征sae2Features和原始数据的标签来训练softmax分类器,得到softmax分类器的权重参数saeSoftmaxOptTheta。
5.利用前面得到的所有权重参数sae1OptTheta、sae2OptTheta、saeSoftmaxOptTheta,得到微调前整个网络的权重参数stackedAETheta,然后在利用原始数据及其标签的基础上通过BP算法对stackedAETheta进行微调,得到微调后的整个网络的权重参数stackedAEOptTheta。
6.通过微调前整个网络的权重参数stackedAETheta和微调后的整个网络的权重参数stackedAEOptTheta,分别对测试数据进行分类,得到两者的分类准确率。
运行结果:
Before Finetuning Test Accuracy: 92.140%
After Finetuning Test Accuracy: 97.590%
第一层特征显示如下:

代码
stackedAEExercise.m:
%% CS294A/CS294W Stacked Autoencoder Exercise % Instructions
% ------------
%
% This file contains code that helps you get started on the
% sstacked autoencoder exercise. You will need to complete code in
% stackedAECost.m
% You will also need to have implemented sparseAutoencoderCost.m and
% softmaxCost.m from previous exercises. You will need the initializeParameters.m
% loadMNISTImages.m, and loadMNISTLabels.m files from previous exercises.
%
% For the purpose of completing the assignment, you do not need to
% change the code in this file.
%
%%======================================================================
%% STEP : Here we provide the relevant parameters values that will
% allow your sparse autoencoder to get good filters; you do not need to
% change the parameters below.
DISPLAY = true;
inputSize = * ;
numClasses = ;
hiddenSizeL1 = ; % Layer Hidden Size
hiddenSizeL2 = ; % Layer Hidden Size
sparsityParam = 0.1; % desired average activation of the hidden units.
% (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
% in the lecture notes).
lambda = 3e-; % weight decay parameter
beta = ; % weight of sparsity penalty term %%======================================================================
%% STEP : Load data from the MNIST database
%
% This loads our training data from the MNIST database files. % Load MNIST database files
trainData = loadMNISTImages('train-images.idx3-ubyte');
trainLabels = loadMNISTLabels('train-labels.idx1-ubyte'); trainLabels(trainLabels == ) = ; % 一直没搞懂,为什么非要把标签0变为10? Remap to since our labels need to start from %%======================================================================
%% STEP : Train the first sparse autoencoder
% This trains the first sparse autoencoder on the unlabelled STL training
% images.
% If you've correctly implemented sparseAutoencoderCost.m, you don't need
% to change anything here. % Randomly initialize the parameters
sae1Theta = initializeParameters(hiddenSizeL1, inputSize); %% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the first layer sparse autoencoder, this layer has
% an hidden size of "hiddenSizeL1"
% You should store the optimal parameters in sae1OptTheta addpath minFunc/;
options = struct;
options.Method = 'lbfgs';
options.maxIter = ;
options.display = 'on';
[sae1OptTheta, cost] = minFunc(@(p)sparseAutoencoderCost(p,...
inputSize,hiddenSizeL1,lambda,sparsityParam,beta,trainData),sae1Theta,options);%训练出第一层网络的参数
save('saves/step2.mat', 'sae1OptTheta'); if DISPLAY
W1 = reshape(sae1OptTheta(:hiddenSizeL1 * inputSize), hiddenSizeL1, inputSize);
display_network(W1');
end % ------------------------------------------------------------------------- %%======================================================================
%% STEP : Train the second sparse autoencoder
% This trains the second sparse autoencoder on the first autoencoder
% featurse.
% If you've correctly implemented sparseAutoencoderCost.m, you don't need
% to change anything here.
% 利用第一个稀疏自编码器的权重参数sae1OptTheta,得到输入数据的一阶特征表示 [sae1Features] = feedForwardAutoencoder(sae1OptTheta, hiddenSizeL1, ...
inputSize, trainData); % Randomly initialize the parameters
sae2Theta = initializeParameters(hiddenSizeL2, hiddenSizeL1); %% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the second layer sparse autoencoder, this layer has
% an hidden size of "hiddenSizeL2" and an inputsize of
% "hiddenSizeL1"
%
% You should store the optimal parameters in sae2OptTheta [sae2OptTheta, cost] = minFunc(@(p)sparseAutoencoderCost(p,...
hiddenSizeL1,hiddenSizeL2,lambda,sparsityParam,beta,sae1Features),sae2Theta,options);%训练出第二层网络的参数
save('saves/step3.mat', 'sae2OptTheta'); figure;
if DISPLAY
W11 = reshape(sae1OptTheta(:hiddenSizeL1 * inputSize), hiddenSizeL1, inputSize);
W12 = reshape(sae2OptTheta(:hiddenSizeL2 * hiddenSizeL1), hiddenSizeL2, hiddenSizeL1);
% TODO(zellyn): figure out how to display a -level network
% display_network(log(W11' ./ (1-W11')) * W12');
% W12_temp = W12(:,:);
% display_network(W12_temp');
% figure;
% display_network(W12_temp');
end % ------------------------------------------------------------------------- %%======================================================================
%% STEP : 用二阶特征训练softmax分类器 Train the softmax classifier
% This trains the sparse autoencoder on the second autoencoder features.
% If you've correctly implemented softmaxCost.m, you don't need
% to change anything here. % 利用第二个稀疏自编码器的权重参数sae2OptTheta,得到输入数据的二阶特征表示
[sae2Features] = feedForwardAutoencoder(sae2OptTheta, hiddenSizeL2, ...
hiddenSizeL1, sae1Features); % Randomly initialize the parameters
saeSoftmaxTheta = 0.005 * randn(hiddenSizeL2 * numClasses, );%这个参数拿来干嘛?计算softmaxCost函数吗?可以舍去!
%因为softmaxCost函数在softmaxExercise练习中已经实现,并且已经证明其梯度计算是正确的! %% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the softmax classifier, the classifier takes in
% input of dimension "hiddenSizeL2" corresponding to the
% hidden layer size of the 2nd layer.
%
% You should store the optimal parameters in saeSoftmaxOptTheta
%
% NOTE: If you used softmaxTrain to complete this part of the exercise,
% set saeSoftmaxOptTheta = softmaxModel.optTheta(:); softmaxLambda = 1e-;
numClasses = ;
softoptions = struct;
softoptions.maxIter = ;
softmaxModel = softmaxTrain(hiddenSizeL2,numClasses,softmaxLambda,...
sae2Features,trainLabels,softoptions);
saeSoftmaxOptTheta = softmaxModel.optTheta(:);%得到softmax分类器的权重参数 save('saves/step4.mat', 'saeSoftmaxOptTheta'); % ------------------------------------------------------------------------- %%======================================================================
%% STEP : 微调 Finetune softmax model % Implement the stackedAECost to give the combined cost of the whole model
% then run this cell. % Initialize the stack using the parameters learned
stack = cell(,);
stack{}.w = reshape(sae1OptTheta(:hiddenSizeL1*inputSize), ...
hiddenSizeL1, inputSize);
stack{}.b = sae1OptTheta(*hiddenSizeL1*inputSize+:*hiddenSizeL1*inputSize+hiddenSizeL1);
stack{}.w = reshape(sae2OptTheta(:hiddenSizeL2*hiddenSizeL1), ...
hiddenSizeL2, hiddenSizeL1);
stack{}.b = sae2OptTheta(*hiddenSizeL2*hiddenSizeL1+:*hiddenSizeL2*hiddenSizeL1+hiddenSizeL2); % Initialize the parameters for the deep model
[stackparams, netconfig] = stack2params(stack);%把stack层(即:两个隐藏层)的权重参数变为一个向量stackparams
stackedAETheta = [ saeSoftmaxOptTheta ; stackparams ];% 得到微调前整个网络参数向量stackedAETheta,它包括softmax分类器那部分的参数向量saeSoftmaxOptTheta,且分类器那部分的参数放前面 %% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the deep network, hidden size here refers to the '
% dimension of the input to the classifier, which corresponds
% to "hiddenSizeL2".
%
% 用BP算法微调,得到微调后的整个网络参数stackedAEOptTheta [stackedAEOptTheta, cost] = minFunc(@(p)stackedAECost(p,inputSize,hiddenSizeL2,...
numClasses, netconfig,lambda, trainData, trainLabels),...
stackedAETheta,options);%训练出第三层网络的参数
save('saves/step5.mat', 'stackedAEOptTheta'); figure;
if DISPLAY
optStack = params2stack(stackedAEOptTheta(hiddenSizeL2*numClasses+:end), netconfig);
W11 = optStack{}.w;
W12 = optStack{}.w;
% TODO(zellyn): figure out how to display a -level network
% display_network(log( ./ (-W11')) * W12');
end % ------------------------------------------------------------------------- %%======================================================================
%% STEP : Test
% Instructions: You will need to complete the code in stackedAEPredict.m
% before running this part of the code
% % Get labelled test images
% Note that we apply the same kind of preprocessing as the training set
testData = loadMNISTImages('t10k-images.idx3-ubyte');
testLabels = loadMNISTLabels('t10k-labels.idx1-ubyte'); testLabels(testLabels == ) = ; % Remap to [pred] = stackedAEPredict(stackedAETheta, inputSize, hiddenSizeL2, ...
numClasses, netconfig, testData); acc = mean(testLabels(:) == pred(:));
fprintf('Before Finetuning Test Accuracy: %0.3f%%\n', acc * ); [pred] = stackedAEPredict(stackedAEOptTheta, inputSize, hiddenSizeL2, ...
numClasses, netconfig, testData); acc = mean(testLabels(:) == pred(:));
fprintf('After Finetuning Test Accuracy: %0.3f%%\n', acc * ); % Accuracy is the proportion of correctly classified images
% The results for our implementation were:
%
% Before Finetuning Test Accuracy: 87.7%
% After Finetuning Test Accuracy: 97.6%
%
% If your values are too low (accuracy less than %), you should check
% your code for errors, and make sure you are training on the
% entire data set of 28x28 training images
% (unless you modified the loading code, this should be the case)
stackedAECost.m
function [ cost, grad ] = stackedAECost(theta, inputSize, hiddenSize, ...
numClasses, netconfig, ...
lambda, data, labels)
% 计算整个模型的代价函数及其梯度
% 注意:完成这个函数后最好用checkStackedAECost函数检查梯度计算是否正确 % stackedAECost: Takes a trained softmaxTheta and a training data set with labels,
% and returns cost and gradient using a stacked autoencoder model. Used for
% finetuning. % theta: trained weights from the autoencoder
% visibleSize: the number of input units
% hiddenSize: the number of hidden units *at the 2nd layer*
% numClasses: the number of categories
% netconfig: the network configuration of the stack
% lambda: the weight regularization penalty
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example.
% labels: A vector containing labels, where labels(i) is the label for the
% i-th training example %% Unroll softmaxTheta parameter % We first extract the part which compute the softmax gradient
softmaxTheta = reshape(theta(:hiddenSize*numClasses), numClasses, hiddenSize);%从整个网络参数向量中提取出softmax分类器部分的参数,并以矩阵表示 % Extract out the "stack"
stack = params2stack(theta(hiddenSize*numClasses+:end), netconfig);%从整个网络参数向量中提取出隐藏层部分的参数,并以结构表示 % You will need to compute the following gradients
softmaxThetaGrad = zeros(size(softmaxTheta));% softmaxTheta的梯度
stackgrad = cell(size(stack)); % stack的梯度
for d = :numel(stack)
stackgrad{d}.w = zeros(size(stack{d}.w));
stackgrad{d}.b = zeros(size(stack{d}.b));
end cost = ; % You need to compute this % You might find these variables useful
M = size(data, );
groundTruth = full(sparse(labels, :M, )); %% --------------------------- YOUR CODE HERE -----------------------------
% Instructions: Compute the cost function and gradient vector for
% the stacked autoencoder.
%
% You are given a stack variable which is a cell-array of
% the weights and biases for every layer. In particular, you
% can refer to the weights of Layer d, using stack{d}.w and
% the biases using stack{d}.b . To get the total number of
% layers, you can use numel(stack).
%
% The last layer of the network is connected to the softmax
% classification layer, softmaxTheta.
%
% You should compute the gradients for the softmaxTheta,
% storing that in softmaxThetaGrad. Similarly, you should
% compute the gradients for each layer in the stack, storing
% the gradients in stackgrad{d}.w and stackgrad{d}.b
% Note that the size of the matrices in stackgrad should
% match exactly that of the size of the matrices in stack.
% depth = size(stack, ); % 隐藏层的数量
a = cell(depth+, ); % 输入层和隐藏层的输出值,即:输入层的输出值和隐藏层的激活值
a{} = data; % 输入层的输出值
Jweight = ; % 权重惩罚项
m = size(data, ); % 样本数 % 计算隐藏层的激活值
for i=:numel(a)
a{i} = sigmoid(stack{i-}.w*a{i-}+repmat(stack{i-}.b, [ size(a{i-}, )]));
%Jweight = Jweight + sum(sum(stack{i-}.w).^);
end M = softmaxTheta*a{depth+};
M = bsxfun(@minus, M, max(M, [], )); %防止下一步计算指数函数时溢出
M = exp(M);
p = bsxfun(@rdivide, M, sum(M)); Jweight = Jweight + sum(softmaxTheta(:).^); % 计算softmax分类器的代价函数,为什么它就是整个模型的代价函数?
cost = -/m .* groundTruth(:)'*log(p(:)) + lambda/2*Jweight;% 代价函数=均方差项+权重衰减项(也叫:规则化项) %计算softmax分类器代价函数的梯度,即输出层的梯度
softmaxThetaGrad = -/m .* (groundTruth - p)*a{depth+}' + lambda*softmaxTheta; delta = cell(depth+, ); %隐藏层和输出层的残差 %计算输出层的残差
delta{depth+} = -softmaxTheta' * (groundTruth - p) .* a{depth+1} .* (1-a{depth+1}); %计算隐藏层的残差
for i=depth:-:
delta{i} = stack{i}.w'*delta{i+1}.*a{i}.*(1-a{i});
end % 通过前面得到的输出层和隐藏层的残差,计算隐藏层参数的梯度
for i=depth:-:
stackgrad{i}.w = /m .* delta{i+}*a{i}';
stackgrad{i}.b = /m .* sum(delta{i+}, );
end % ------------------------------------------------------------------------- %% Roll gradient vector
grad = [softmaxThetaGrad(:) ; stack2params(stackgrad)]; end % You might find this useful
function sigm = sigmoid(x)
sigm = ./ ( + exp(-x));
end
stackedAEPredict.m
function [pred] = stackedAEPredict(theta, inputSize, hiddenSize, numClasses, netconfig, data) % stackedAEPredict: Takes a trained theta and a test data set,
% and returns the predicted labels for each example. % theta: trained weights from the autoencoder
% visibleSize: the number of input units
% hiddenSize: the number of hidden units *at the 2nd layer*
% numClasses: the number of categories
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example. % Your code should produce the prediction matrix
% pred, where pred(i) is argmax_c P(y(c) | x(i)). %% Unroll theta parameter % We first extract the part which compute the softmax gradient
softmaxTheta = reshape(theta(:hiddenSize*numClasses), numClasses, hiddenSize); % Extract out the "stack"
stack = params2stack(theta(hiddenSize*numClasses+:end), netconfig); %% ---------- YOUR CODE HERE --------------------------------------
% Instructions: Compute pred using theta assuming that the labels start
% from . depth = numel(stack);
a = cell(depth+);
a{} = data;
m = size(data, ); for i=:depth+
a{i} = sigmoid(stack{i-}.w*a{i-}+ repmat(stack{i-}.b, [ m]));
end [prob pred] = max(softmaxTheta*a{depth+}); % ----------------------------------------------------------- end % You might find this useful
function sigm = sigmoid(x)
sigm = ./ ( + exp(-x));
end
display_network.m
function [h, array] = display_network(A, opt_normalize, opt_graycolor, cols, opt_colmajor)
% This function visualizes filters in matrix A. Each column of A is a
% filter. We will reshape each column into a square image and visualizes
% on each cell of the visualization panel.
% All other parameters are optional, usually you do not need to worry
% about it.
% opt_normalize:whether we need to normalize the filter so that all of
% them can have similar contrast. Default value is true.
% opt_graycolor: whether we use gray as the heat map. Default is true.
% cols: how many columns are there in the display. Default value is the
% squareroot of the number of columns in A.
% opt_colmajor: you can switch convention to row major for A. In that
% case, each row of A is a filter. Default value is false. % opt_normalize:是否需要归一化的参数。真:每个图像块归一化(即:每个图像块元素值除以该图像块中像素值绝对值的最大值);
% 假:整幅大图像一起归一化(即:每个图像块元素值除以整幅图像中像素值绝对值的最大值)。默认为真。
% opt_graycolor: 该参数决定是否显示灰度图。
% 真:显示灰度图;假:不显示灰度图。默认为真。
% cols: 该参数决定将要显示的整幅大图像每一行中小图像块的个数。默认为A列数的均方根。
% opt_colmajor:该参数决定将要显示的整个大图像中每个小图像块是按行从左到右依次排列,还是按列从上到下依次排列
% 真:整个大图像由每个小图像块按列从上到下依次排列组成;
% 假:整个大图像由每个小图像块按行从左到右依次排列组成。默认为假。 warning off all %关闭警告 % 参数的默认值
if ~exist('opt_normalize', 'var') || isempty(opt_normalize)
opt_normalize= true;
end if ~exist('opt_graycolor', 'var') || isempty(opt_graycolor)
opt_graycolor= true;
end if ~exist('opt_colmajor', 'var') || isempty(opt_colmajor)
opt_colmajor = false;
end % 整幅大图像或整个数据0均值化 rescale
A = A - mean(A(:)); if opt_graycolor, colormap(gray); end %如果要显示灰度图,就把该图形的色图(即:colormap)设置为gray % 计算整幅大图像中每一行中小图像块的个数和第一列中小图像块的个数,即列数n和行数m compute rows, cols
[L M]=size(A); % M即为小图像块的总数
sz=sqrt(L); % 每个小图像块内像素点的行数和列数
buf=; % 用于把每个小图像块隔开,即小图像块之间的缓冲区。每个小图像块的边缘都是一行和一列像素值为-1的像素点。
if ~exist('cols', 'var') % 如变量cols不存在时
if floor(sqrt(M))^ ~= M % 如果M的均方根不是整数,列数n就先暂时取值为M均方根的向右取整
n=ceil(sqrt(M));
while mod(M, n)~= && n<1.2*sqrt(M), n=n+; end % 当M不是n的整数倍且n小于1.2倍的M均方根值时,列数n加1
m=ceil(M/n); % 行数m取值为小图像块总数M除以大图像中每一行中小图像块的个数n,再向右取整
else
n=sqrt(M); % 如果M的均方根是整数,那m和n都取值为M的均方根
m=n;
end
else
n = cols; % 如果变量cols存在,就直接令列数n等于cols,行数m为M除以n后向右取整
m = ceil(M/n);
end array=-ones(buf+m*(sz+buf),buf+n*(sz+buf));%要保证每个小图像块的四周边缘都是单行和单列像素值为-1的像素点。所以得到这个目标矩阵 if ~opt_graycolor % 如果分隔区不显示黑色,而显示灰度,那就要是要保证:每个小图像块的四周边缘都是单行和单列像素值为-.1的像素点
array = 0.1.* array;
end if ~opt_colmajor % 如果opt_colmajor为假,即:整个大图像由每个小图像块按行从左到右依次排列组成
k=; %第k个小图像块
for i=:m % 行数
for j=:n % 列数
if k>M,
continue;
end
clim=max(abs(A(:,k)));
if opt_normalize
array(buf+(i-)*(sz+buf)+(:sz),buf+(j-)*(sz+buf)+(:sz))=reshape(A(:,k),sz,sz)/clim; %从这可看是n是列数,m是行数
else
array(buf+(i-)*(sz+buf)+(:sz),buf+(j-)*(sz+buf)+(:sz))=reshape(A(:,k),sz,sz)/max(abs(A(:)));
end
k=k+;
end
end
else % 如果opt_colmajor为真,即:整个大图像由每个小图像块按列从上到下依次排列组成
k=;
for j=:n %列数
for i=:m %行数
if k>M,
continue;
end
clim=max(abs(A(:,k)));
if opt_normalize
array(buf+(i-)*(sz+buf)+(:sz),buf+(j-)*(sz+buf)+(:sz))=reshape(A(:,k),sz,sz)/clim;
else
array(buf+(i-)*(sz+buf)+(:sz),buf+(j-)*(sz+buf)+(:sz))=reshape(A(:,k),sz,sz);
end
k=k+;
end
end
end if opt_graycolor % 要显示灰度图,此时每个小图像块的四周边缘都是单行和单列像素值为-1的像素点。
h=imagesc(array,'EraseMode','none',[- ]); %图形的EraseMode属性设置为none:即为在该图像上不做任何擦除,直接在原来图形上绘制
else % 不显示灰度图,此时每个小图像块的四周边缘都是单行和单列像素值为-.1的像素点。
h=imagesc(array,'EraseMode','none',[- ]);
end
axis image off %去掉坐标轴 drawnow; %刷新屏幕,使图像可一点一点地显示 warning on all %打开警告
参考资料:
Deep learning:二十四(stacked autoencoder练习)
http://blog.csdn.net/freeliao/article/details/19618855
http://www.tuicool.com/articles/MnANFn
……
Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)的更多相关文章
- Deep Learning 3_深度学习UFLDL教程:预处理之主成分分析与白化_总结(斯坦福大学深度学习教程)
1PCA ①PCA的作用:一是降维:二是可用于数据可视化: 注意:降维的原因是因为原始数据太大,希望提高训练速度但又不希望产生很大的误差. ② PCA的使用场合:一是希望提高训练速度:二是内存太小:三 ...
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
1前言 本人写技术博客的目的,其实是感觉好多东西,很长一段时间不动就会忘记了,为了加深学习记忆以及方便以后可能忘记后能很快回忆起自己曾经学过的东西. 首先,在网上找了一些资料,看见介绍说UFLDL很不 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- Deep Learning 11_深度学习UFLDL教程:数据预处理(斯坦福大学深度学习教程)
理论知识:UFLDL数据预处理和http://www.cnblogs.com/tornadomeet/archive/2013/04/20/3033149.html 数据预处理是深度学习中非常重要的一 ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
- Deep Learning 7_深度学习UFLDL教程:Self-Taught Learning_Exercise(斯坦福大学深度学习教程)
前言 理论知识:自我学习 练习环境:win7, matlab2015b,16G内存,2T硬盘 练习内容及步骤:Exercise:Self-Taught Learning.具体如下: 一是用29404个 ...
随机推荐
- 几个常见Win32 API函数
1.获取客户区矩形区域 RECT cliRect; GetClientRect(hWnd, &cliRect); 2.获取窗口上下文句柄 HDC hdc = GetDC(hWnd);//... ...
- Android开发之Intent略解
Intent是一种运行时绑定(run-time binding)机制,它能在程序运行过程中连接两个不同的组件.通过Intent,你的程序可以向Android表达某种请求或者意愿,Android会根据意 ...
- 连接mysql问题 mysqlnd cannot connect to MySQL 4.1+ using old authentication
第一篇:PHP5.3开始使用MySqlND作为默认的MySql访问驱动,而且从这个版本开始将不再支持使用旧的用户接口链接Mysql了,你可能会看到类似的提示: #2000 - mysqlnd cann ...
- 多线程 - CyclicBarrier
一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point).在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarri ...
- sdk 更新的时连接不上dl-ssl.google.com解决办法
今天有朋友说sdk的更新不了,借了个VPN给他也没解决问题,后来还是他自己解决了,下面分享下经验 这里介绍一种不需要FQ的解决办法,修改C:\Windows\System32\drivers\etc下 ...
- 读源码之RESideMenu
RESideMenu是github上比较出名的一个开源库,主要是实现侧滑菜单,现在有三千多个star了.效果如下. 据说创意来源于dribbble的一个设计,还是比较好看的.感兴趣的可以去gith ...
- linux添加ip、路由相关命令
1- Linux添加永久路由vi /etc/sysconfig/network-scripts/route-eth1ADDRESS0=192.168.10.0NETMASK0=255.255.255. ...
- Android利用canvas画各种图形(点、直线、弧、圆、椭圆、文字、矩形、多边形、曲线、圆角矩形) .
1.首先说一下canvas类: Class Overview The Canvas class holds the "draw" calls. To draw something, ...
- 浏览器网页判断手机是否安装IOS/Android客户端程序
IOS 原理如下: 为HTML页面中的超链接点击事件增加一个setTimeout方法. 如果在iPhone上面500ms内,本机有应用程序能解析这个协议并打开程序,则这个回调方法失效: 如果本机没有应 ...
- Jquery入门指南教程
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka jQuery,顾名思义,也就是JavaScript和查询(Query),即是辅助JavaScr ...