Python 2.7_First_try_爬取阳光电影网_20161206
之前看过用Scrapy 框架建立项目爬取 网页解析时候用的Xpath进行解析的网页元素 这次尝试用select方法匹配元素
1、入口爬取页面 http://www.ygdy8.com/index.html
2、用到模块 requests(网页源码下载) BeautifulSoup4(网页解析)
3、思路:首先由入口爬取页面进行获取网页上方栏目及对应url 如下图
4、建立菜单url列表 for 循环再次进行解析 爬取每个一级菜单下的具体电影title 和url
5、问题:每个菜单下的url 进行再次解析后 由于网站内容不同 select 元素会出现非电影标题的连接和标题
6、python 代码
#coding:utf-8
import requests
from bs4 import BeautifulSoup as bs #爬取入口
rooturl="http://www.ygdy8.com/index.html"
#获取网页源码
res=requests.get(rooturl)
#网站编码gb2312
res.encoding='gb2312'
#网页源码
html=res.text
soup=bs(html,'html.parser')
cate_urls = []
for cateurl in soup.select('.contain ul li a'):
#网站分类标题
cate_name=cateurl.text
#分类url 进行再次爬取
cate_url="http://www.ygdy8.com/"+ cateurl['href']
cate_urls.append(cate_url)
print "网站一级菜单:",cate_name,"菜单网址:",cate_url
#每个菜单url 解析
for i in range(len(cate_urls)):
cate_listurl=cate_urls[i]
res = requests.get(cate_listurl)
res.encoding = 'gb2312'
html = res.text
soup = bs(html, 'html.parser')
print "正在解析第"+str(i+1)+"个链接",cate_urls[i]
contenturls=[]
contents=soup.select('.co_content8 ul')[0].select('a')
#print contents
for title in contents:
moivetitle=title.text
moiveurl=title['href']
contenturls.append(moiveurl)
print moivetitle,moiveurl
print contenturls
8、运行结果

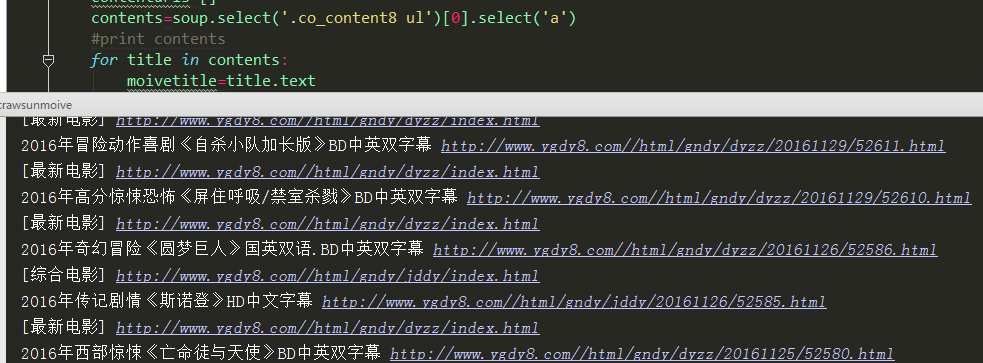
Python 2.7_First_try_爬取阳光电影网_20161206的更多相关文章
- Python 2.7_Second_try_爬取阳光电影网_获取电影下载地址并写入文件 20161207
1.昨天文章http://www.cnblogs.com/Mr-Cxy/p/6139705.html 是获取电影网站主菜单 然后获取每个菜单下的电影url 2.今天是对电影url 进行再次解析获取下 ...
- scrapy爬取阳光电影网全站资源
说一下我的爬取过程吧 第一步: 当然是 scrapy startproject + 名字 新建爬虫项目 第二步: scrapy genspider -t crawl +爬虫名字+ 所爬取网站的 ...
- Python 3.6 爬取BD电影网
2018-07-10 #coding:utf-8 #coding:utf-8 from lxml import etree import requests import pandas import t ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 零基础Python爬虫实现(爬取最新电影排行)
提示:本学习来自Ehco前辈的文章, 经过实现得出的笔记. 目标网站 http://dianying.2345.com/top/ 网站结构 要爬的部分,在ul标签下(包括li标签), 大致来说迭代li ...
- python爬虫:爬取易迅网价格信息,并写入Mysql数据库
本程序涉及以下方面知识: 1.python链接mysql数据库:http://www.cnblogs.com/miranda-tang/p/5523431.html 2.爬取中文网站以及各种乱码处 ...
- 用python爬虫简单爬取 笔趣网:类“起点网”的小说
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- python实战项目 — 爬取 校花网图片
重点: 1. 指定路径创建文件夹,判断是否存在 2. 保存图片文件 # 获得校花网的地址,图片的链接 import re import requests import time import os ...
随机推荐
- zTree简单使用和代码结构
1.页面使用元素代码 <input type="text" id="key" class="Side_Toput2" name=&qu ...
- AppStore 内购验证的方法
AppStore增加了验证内购(In App Purchasement)的方法, 就是苹果提供一个url地址, 开发测试用: https://sandbox.itunes.apple.com/veri ...
- ANSI C中关于FILE流的一些
ANSI C只是一个定义,定义了一个借口与标准,具体实现将是不同的. 刚看到I/O的时候就对于Stream非常的迷惑,这是什么玩意.后面才明白,这只是一个抽象出来的概念而已.对于一个Stream,它具 ...
- Thrift 个人实战--初次体验Thrift
前言: Thrift作为Facebook开源的RPC框架, 通过IDL中间语言, 并借助代码生成引擎生成各种主流语言的rpc框架服务端/客户端代码. 不过Thrift的实现, 简单使用离实际生产环境还 ...
- C# Excel导入
两张表导入到一个DataGrid里面(题目表和答案表) 前台代码 <asp:Content ID="Content1" ContentPlaceHolderID=" ...
- 2015.12.29~2015.12.30真题回顾!-- HTML5学堂
2015.12.29~2015.12.30真题回顾!-- HTML5学堂 吃饭,能够解决饥饿,提供身体运作机能.练习就像吃饭,强壮自己,提升编程技能,寻求编程技巧的最佳捷径!吃饭不能停,练习同样不能停 ...
- 认识CPU Cache
http://geek.csdn.net/news/detail/114619 7个示例科普CPU Cache:http://coolshell.cn/articles/10249.html Linu ...
- 家有学霸的CEO
小余老师说 http://learning.sohu.com/20161101/n471998591.shtml
- [洛谷OJ] P1114 “非常男女”计划
洛谷1114 “非常男女”计划 本题地址:http://www.luogu.org/problem/show?pid=1114 题目描述 近来,初一年的XXX小朋友致力于研究班上同学的配对问题(别想太 ...
- webpack-dev-server、webpack-dev-middleware、webpack-hot-middleware区别
webpack-dev-server: 它是一个静态资源服务器,只用于开发环境: webpack-dev-server会把编译后的静态文件全部保存在内存里: webpack-dev-middlewar ...