RNN神经网络和英中机器翻译的实现
本文系qitta的文章翻译而成,由renzhe0009实现。转载请注明以上信息,谢谢合作。
本文主要讲解以recurrent neural network为主,以及使用Chainer和自然语言处理其中的encoder-decoder翻译模型。
并将英中机器翻译用代码实现。
Recurrent Neural Network
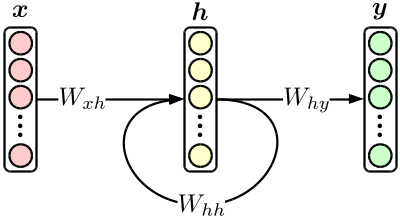
在chainer(本次实现所使用的程序库)中,我们就使用上面的式子。
from chainer import FunctionSet
from chainer.functions import * model = FunctionSet(
w_xh = EmbedID(VOCAB_SIZE, HIDDEN_SIZE), # 输入层(one-hot) -> 隐藏层
w_hh = Linear(HIDDEN_SIZE, HIDDEN_SIZE), # 隐藏层 -> 隐藏层
w_hy = Linear(HIDDEN_SIZE, VOCAB_SIZE), # 隐藏层 -> 输出层
)
VOCAB_SIZE是单词的数量、HIDDEN_SIZE是隐藏层的维数。
然后,定义实际的解析函数forward。在这里基本是按照上图的网络结构来再现模型的定义和实际的输入数据,最终进行求值计算。语言模型的情况下,是用下面的式表示句子的结合概率。

以下是代码的例子。
import math
import numpy as np
from chainer import Variable
from chainer.functions import * def forward(sentence, model): # sentence是strの排列结果。
sentence = [convert_to_your_word_id(word) for word in sentence] # 单词转换为ID
h = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32)) # 隐藏层的初值
log_joint_prob = float(0) # 句子的结合概率 for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) # 下一次的输入层
y = softmax(model.w_hy(h)) # 下一个单词的概率分布
log_joint_prob += math.log(y.data[0][word]) #结合概率的分布
h = tanh(model.w_xh(x) + model.w_hh(h)) #隐藏层的更新 return log_joint_prob #返回结合概率的计算结果
这样就可以求出句子的概率了。但是,上面并没有计算损失函数。所以我们使用softmax函数来进行计算。
也就是用chainer.functions.softmax_cross_entropy
def forward(sentence, model):
... accum_loss = Variable(np.zeros((), dtype=np.float32)) # 累计损失的初値
... for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) #下次的输入 (=现在的正确值)
u = model.w_hy(h)
accum_loss += softmax_cross_entropy(u, x) # 累计损失
y = softmax(u)
... return log_joint_prob, accum_loss # 累计损失全部返回
现在就可以进行学习了。
from chainer.optimizers import *
... def train(sentence_set, model):
opt = SGD() # 使用梯度下降法
opt.setup(model) # 学习初期化
for sentence in sentence_set:
opt.zero_grad(); # 勾配の初期化
log_joint_prob, accum_loss = forward(sentence, model) # 损失的计算
accum_loss.backward() # 误差反向传播
opt.clip_grads(10) # 剔除过大的梯度
opt.update() # 参数更新
那么基本上chainer的RNN代码就是这样实现的了。
Encoder-decode翻译模型
encoder-decoder是现在广泛使用的利用神经网络的翻译模型。
和过去的方法相比也能够达到很高精度,现在深受NLP研究者们喜爱的翻译模型。
encoder-decoder有很多种,以下是我在本文中实现的模型。
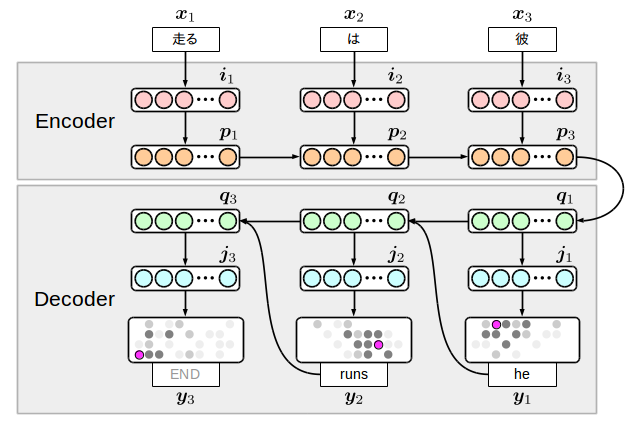
很简单的想法,准备输入方面(encoder)和输出方面(decoder)的2个RNN,在中间节点上连接。
这个模型的有趣之处在于,为了在输出方面一起生成终端符号,翻译的结束是由模型自己决定的。但是反过来讲,为了不生成无限的单词死循环,实际处理的时候,做一些限制还是有必要的。
i和j是embedding(词向量)层。
整个模型的计算式如下

对隐藏层p和q的位移,使用了LSTM神经网络。但是encoder方面实质的损失的计算位置y的距离很远,一般的传递函数很难进行学习。
所以LSTM神经网络的长距离时序依存关系的优点就能够体现出来。
上式的位移W∗∗一共有8种。用以下的代码来定义。
model = FunctionSet(
w_xi = EmbedID(SRC_VOCAB_SIZE, SRC_EMBED_SIZE), #输入层(one-hot) -> 输入词向量层
w_ip = Linear(SRC_EMBED_SIZE, 4 * HIDDEN_SIZE), # 输入词向量层-> 输入隐藏层
w_pp = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), # 输入隐藏层 -> 输入隐藏层
w_pq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), # 输入隐藏层-> 输出隐藏层
w_yq = EmbedID(TRG_VOCAB_SIZE, 4 * HIDDEN_SIZE), #输出层(one-hot) -> 输出隐藏层
w_qq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #输出隐藏层 -> 输出隐藏层
w_qj = Linear(HIDDEN_SIZE, TRG_EMBED_SIZE), # 输出隐藏层 -> 输出词向量层
w_jy = Linear(TRG_EMBED_SIZE, TRG_VOCAB_SIZE), # 输出隐藏层 -> 输出隐藏层
)
接下来是forward函数。
因为LSTM带有内部结构,注意p和q的计算需要多一个Variable。
# src_sentence: 需要翻译的句子 e.g. ['他', '在', '走']
# trg_sentence: 正解的翻译句子 e.g. ['he', 'runs']
# training: 机械学习的预测。
def forward(src_sentence, trg_sentence, model, training): # 转换单词ID
# 对正解的翻訳追加终端符号
src_sentence = [convert_to_your_src_id(word) for word in src_sentence]
trg_sentence = [convert_to_your_trg_id(word) for wprd in trg_sentence] + [END_OF_SENTENCE] # LSTM内部状态的初期値
c = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32)) # encoder
for word in reversed(src_sentence):
x = Variable(np.array([[word]], dtype=np.int32))
i = tanh(model.w_xi(x))
c, p = lstm(c, model.w_ip(i) + model.w_pp(p)) # encoder -> decoder
c, q = lstm(c, model.w_pq(p)) # decoder
if training:
# 学习时使用y作为正解的翻译、forward结果作为累计损失来返回
accum_loss = np.zeros((), dtype=np.float32)
for word in trg_sentence:
j = tanh(model.w_qj(q))
y = model.w_jy(j)
t = Variable(np.array([[word]], dtype=np.int32))
accum_loss += softmax_cross_entropy(y, t)
c, q = lstm(c, model.w_yq(t), model.w_qq(q))
return accum_loss
else:
# 预测时翻译器生成的y作为下次的输入,forward的结果作为生成了的单词句子
# 选择y中最大概率的单词、没必要用softmax。
hyp_sentence = []
while len(hyp_sentence) < 100: # 剔除生成100个单词以上的句子
j = tanh(model.w_qj(q))
y = model.w_jy(j)
word = y.data.argmax(1)[0]
if word == END_OF_SENTENCE:
break # 生成了终端符号,结束。
hyp_sentence.append(convert_to_your_trg_str(word))
c, q = lstm(c, model.w_yq(y), model.w_qq(q))
return hyp_sentence
稍微有点长,这段代码和之前的图结合起来读就会明白了。
最终结果如下:

第一次epoch的结果。

第100次epoch的结果。
src是英文原文。trg是正确译文。hyp是预测译文。
因为现在手头只有笔记本电脑,内存不足,所以把参数都调低了,不然无法执行。你们懂的。
看起来还不赖吧。参数调高必然能取得更好的效果。
Have fun!
Ps:过阵子回学校再把代码整理下发布。
RNN神经网络和英中机器翻译的实现的更多相关文章
- 3. RNN神经网络-LSTM模型结构
1. RNN神经网络模型原理 2. RNN神经网络模型的不同结构 3. RNN神经网络-LSTM模型结构 1. 前言 之前我们对RNN模型做了总结.由于RNN也有梯度消失的问题,因此很难处理长序列的数 ...
- [论文阅读] RNN 在阿里DIEN中的应用
[论文阅读] RNN 在阿里DIEN中的应用 0x00 摘要 本文基于阿里推荐DIEN代码,梳理了下RNN一些概念,以及TensorFlow中的部分源码.本博客旨在帮助小伙伴们详细了解每一步骤以及为什 ...
- 从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化
从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化 神经网络在训练过程中,为应对过拟合问题,可以采用正则化方法(regularization),一种常用的正则化方法是L2正则化. 神经网络中 ...
- 从MAP角度理解神经网络训练过程中的正则化
在前面的文章中,已经介绍了从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化,本次我们从最大后验概率点估计(MAP,maximum a posteriori point estimate)的 ...
- 一文看懂NLP神经网络发展历史中最重要的8个里程碑!
导读:这篇文章中作者尝试将 15 年的自然语言处理技术发展史浓缩为 8 个高度相关的里程碑事件,不过它有些偏向于选择与当前比较流行的神经网络技术相关的方向.我们需要关注的是,本文中介绍的许多神经网络模 ...
- PyTorch基础——使用神经网络识别文字中的情感信息
一.介绍 知识点 使用 Python 从网络上爬取信息的基本方法 处理语料"洗数据"的基本方法 词袋模型搭建方法 简单 RNN 的搭建方法 简单 LSTM 的搭建方法 二.从网络中 ...
- RNN神经网络产生梯度消失和梯度爆炸的原因及解决方案
1.RNN模型结构 循环神经网络RNN(Recurrent Neural Network)会记忆之前的信息,并利用之前的信息影响后面结点的输出.也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏 ...
- Deep Learning入门视频(下)之关于《感受神经网络》两节中的代码解释
代码1如下: #深度学习入门课程之感受神经网络(上)代码解释: import numpy as np import matplotlib.pyplot as plt #matplotlib是一个库,p ...
- 《TensorFlow实战》中AlexNet卷积神经网络的训练中
TensorFlow实战中AlexNet卷积神经网络的训练 01 出错 TypeError: as_default() missing 1 required positional argument: ...
随机推荐
- enmo_day_04
数据库名称 : PROD1 update employees set salary = salary + 1000 where LAST_NAME = ‘Bell’; select LAST_NAME ...
- Android M新特性之Permissions
User does not have to grant any permissions when they install or upgrade the app. Instead, the app r ...
- yii2-搜索带分页,分页的两种方式
1.文章表关联 <?php //...other code //关联 public function getCate(){ return $this->hasOne(ArticleCate ...
- 阿里 RocketMQ 安装与简介
一.简介 官方简介: l RocketMQ是一款分布式.队列模型的消息中间件,具有以下特点: l 能够保证严格的消息顺序 l 提供丰富的消息拉取模式 l 高效的订阅者水平扩展能力 l 实时的 ...
- Map/Reduce 工作机制分析 --- 错误处理机制
前言 对于Hadoop集群来说,节点损坏是非常常见的现象. 而Hadoop一个很大的特点就是某个节点的损坏,不会影响到整个分布式任务的运行. 下面就来分析Hadoop平台是如何做到的. 硬件故障 硬件 ...
- Linux下手动获取当前调用栈
被问到如何手动获取当前的调用栈,之前碰到过一时没记起来,现在回头整理一下. 其原理是:使用backtrace()从栈中获取当前调用各层函数调用的返回地址,backtrace_symbols()将对应地 ...
- POJ 2481 Cows(树状数组)
Cows Time Limit: 3000MS Memory L ...
- IplImage 结构解读(转)
typedef struct _IplImage { int nSize; /* IplImage大小 */ int ID; ...
- CSS 样式的优先级
1. 同一元素引用了多个样式时,排在后面的样式属性的优先级高 例如,下面的 div,同时引用了 [.default] 和 [.user] 中的样式,其中 [.user] 样式中的 width 属性会替 ...
- js中的this指针(四)
当一个函数前面加上 new 操作符来调用,此时 this 会被绑定到新生成的对象上. 这既是所谓的构造函数调用模式.