NetAnalyzer笔记 之 八 NetAnalyzer2016使用方法(2)
[创建时间:2016-05-06 22:07:00]
在写本篇的时候,NetAnalyzer 3.1版本已经发布,所以本篇就以最新版本的为例继续使用,并且顺带说明一下,新版本中一些功能。
那我们就开始吧
四.数据菜单

这部分主要是为开发和数据分析相关人员准备的一组功能,这部分主要针对的是对对数据窗口区域的操作
这部分需要借助软件中一个一个特殊的区域来完成,那就是转换窗口,点击 转换窗口 中的 显示
如下图所示:

就会打开一个转化窗口,本质就是一个可以输入输出的文本框,同理,当点击 关闭 时候就可以隐藏这个窗口,而 清理记录 就是清空里面的内容
那么接下来就是开始工作的时候了,当我们在数据区域中选择一块数据,然后选择 IPv4地址

那么输出窗口中自动以选择的第一个字节开始转化为IPv4地址在转换窗口中显示,颜色较浅的部分字节为当前未参与转化的数据,同样我们可以把字节转换为字符串(受选定的编码格式影响,详细说明见NetAnalyzer笔记 七),数字等
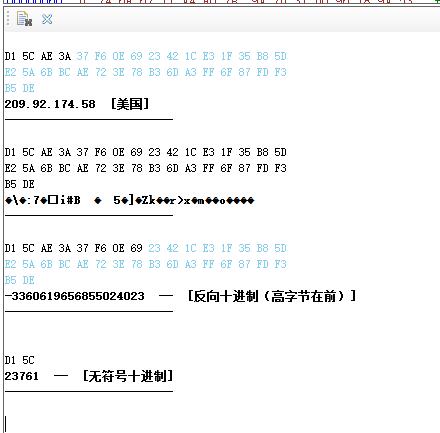
同样,我们还可以吧这些选中的字节以字符串、代码等方式复制出来,如可以复制出下列代码:
byte[] tmpBuffer= new byte[]
{
0xD1,0x5C,0xAE,0x3A,0x37,0xF6,0x0E,0x69,
0x23,0x42,0x1C,0xE3,0x1F,0x35,0xB8,0x5D,
0xE2,0x5A,0x6B,0xBC,0xAE,0x72,0x3E,0x78,
0xB3,0x6D,0xA3,0xFF,0x6F,0x87,0xFD,0xF3,
0xB5,0xDE
};
接下来一个重要的功能就是 定位
该功能,通过指定一个或连续多个字节的位置以及值,来查找其他在制定位置具有指定值的数据包,这个想法是受曾经一个项目中要查找一个指定位置的代码而来。
使用起来也很简单

(1) 选择数据;
(2) 点击 定位(当没有选择时,默认取光标后一个字节进行定位);
(3) 点击 查找字节 就可以查找当前位置是9A 7D 的数据包了
五.工具
工具菜单负责提供一些辅助分析和统计工具界面如下

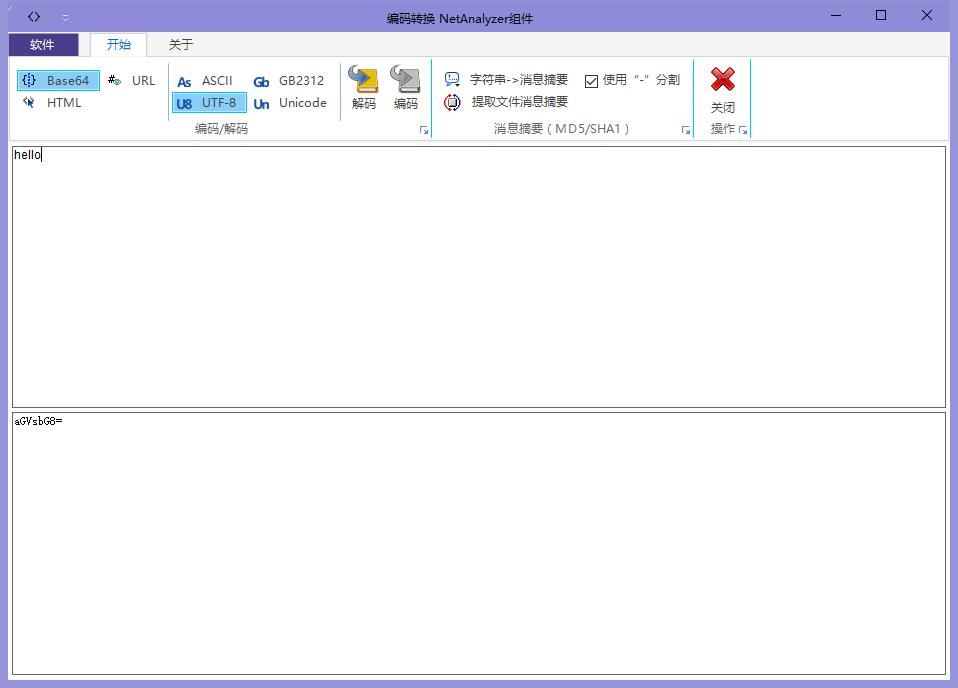
编码转换 主要用来处理字符串编码 如 base64 html url 等
流量监控,用于实时监控选定的网卡数据信息统计

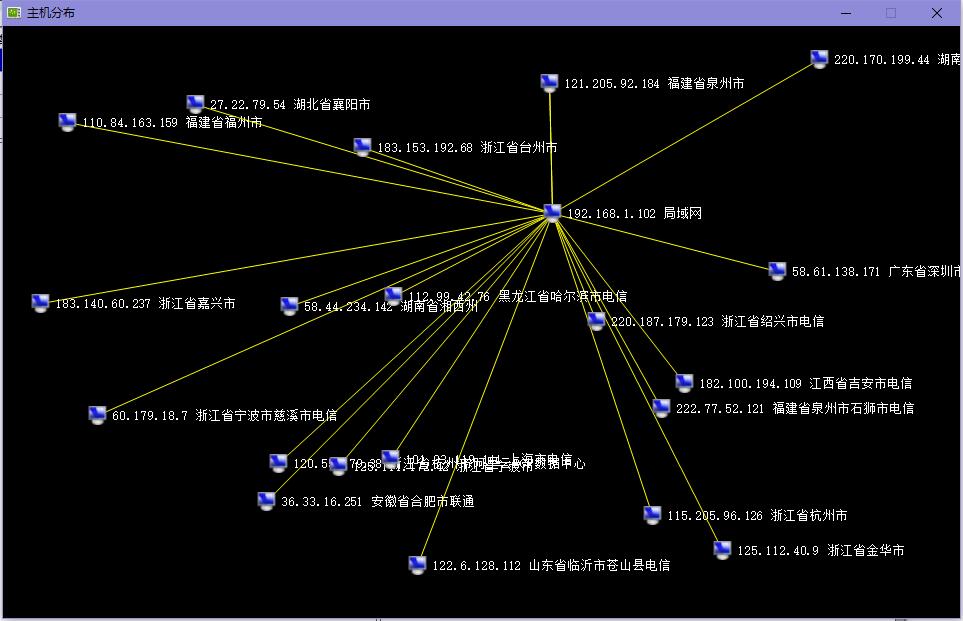
主机分布 则用于呈现与当前主机通信的的服务器
对于后面的后台抓包,地理位置查询,以及ping工具,因为比较简单,此处就不再详细说明,对于插件扩展因为所涉及的内容较多,以后会专门出一篇文档,此处也就略过
对于配置和关于菜单,因为比较简单,大家可以自行下载尝试一下,此处也就不再做过的介绍了。
六.新增内容
(1) 进程抓包,经过不懈的努力,终于把进程抓包功能实现了,实现原理比较简单,可以参考NetAnalyzer笔记第六篇,

当我们勾选所要抓包的进程(可以多选),然后点击开始抓包,就可以按照指定的端口号进行抓包了。
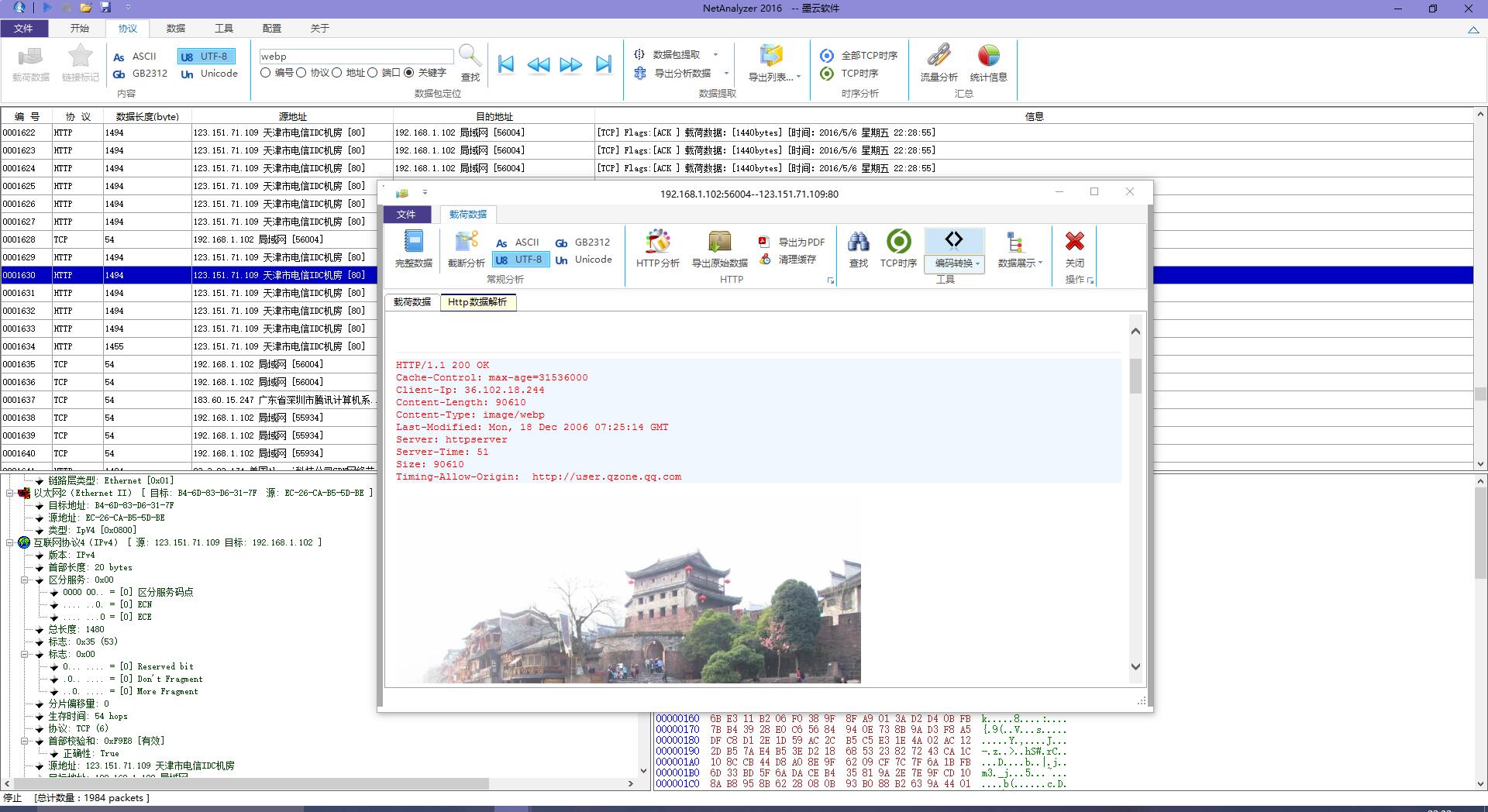
(2) webp图片的还原,当我们使用NetAnalyzer抓取QQ空间图片的时候,可以看到,http协议下 Content-Type:image/webp 格式的图片,具体图片内容自行百度,
现在webp格式的图片再NetAnalyzer自动转化为png格式,方便提取
(3) 载荷数据分析截断,当进行载荷数据提取的时候经常遇到无意义的数据一直在转换,可以通过截断分析停止转换线程,另外对于http分析增加了载荷数据导出,分析数据pdf导出等功能
(4) 数据包列表,分析信息导出增加pdf导出功能,并且对导出html页面做了美化调整
七.结尾
经过两篇的介绍,大体上已经完成了对NetAnalyzer主要功能的说明,希望对大家有所帮助,同时也感谢大家的支持。别忘了关注文章后面的公众平台哦^_^
NetAnalyzer笔记 之 八 NetAnalyzer2016使用方法(2)的更多相关文章
- NetAnalyzer笔记 之 七 NetAnalyzer2016使用方法(1)
[创建时间:2016-04-17 14:47:00] NetAnalyzer下载地址 距离新本的NetAnalyzer已经发布一段时间了,因为比较忙期间只出了一个视频教程,一直没有来的急写文档,今天就 ...
- NetAnalyzer笔记 目录
目录 NetAnalyzer笔记 之 一 开篇语 NetAnalyzer笔记 之 二 简单的协议分析 NetAnalyzer笔记 之 三 用C++做一个抓包程序 NetAnalyzer笔记 之 四 C ...
- NetAnalyzer2016使用方法
NetAnalyzer笔记 之 八 NetAnalyzer2016使用方法(2) [创建时间:2016-05-06 22:07:00] NetAnalyzer下载地址 在写本篇的时候,NetAna ...
- NetAnalyzer笔记 之 九 使用C#对HTTP数据还原
[创建时间:2016-05-12 00:19:00] NetAnalyzer下载地址 在NetAnalyzer2016中加入了一个HTTP分析功能,很过用户对此都很感兴趣,那么今天写一下具体的实现方式 ...
- NetAnalyzer笔记 之 五 一些抓包技巧分享(不定期更新)
[创建时间:2016-03-12 10:00:00] [更新时间:2016-05-21 10:00:00] NetAnalyzer下载地址 前一段时间应为工作关系,NetAnalyzer笔记系列已经很 ...
- VSTO学习笔记(八)向 Word 2010 中写入表结构
原文:VSTO学习笔记(八)向 Word 2010 中写入表结构 前几天公司在做CMMI 3级认证,需要提交一系列的Word文档,其中有一种文档要求添加公司几个系统的数据库中的表结构.我临时接到了这项 ...
- 《C#从现象到本质》读书笔记(八)第10章反射
<C#从现象到本质>读书笔记(八)第10章反射 个人感觉,反射其实就是为了能够在程序运行期间动态的加载一个外部的DLL集合,然后通过某种办法找到这个DLL集合中的某个空间下的某个类的某个成 ...
- python3.4学习笔记(十八) pycharm 安装使用、注册码、显示行号和字体大小等常用设置
python3.4学习笔记(十八) pycharm 安装使用.注册码.显示行号和字体大小等常用设置Download JetBrains Python IDE :: PyCharmhttp://www. ...
- 前端学习笔记汇总(之merge方法)
学习笔记 关于Jquery的merge方法 话不多说,先上图 使用jquery时,其智能提示如上,大概意思就是合并first和second两个数组,得到的结果是first+(second去重后的结果) ...
随机推荐
- Android-自定义PopupWindow
PopupWindow在应用中应该是随处可见的,很常用到,比如在旧版本的微信当中就用到下拉的PopupWindow,那是自定义的.新版微信5.2的ActionBar,有人已经模仿了它,但微信具体是使用 ...
- (各个公司面试原题)在线做了一套CC++综合測试题,也来測一下你的水平吧(二)
刚才把最后的10道题又看了下.也发上来吧. 以下给出试题.和我对题目的一些理解 前10道题地址 (各个公司面试原题)在线做了一套CC++综合測试题.也来測一下你的水平吧(一) 11.设已经有A,B,C ...
- web开发小白之路
今天就来谈谈本人从事web开发的一系列白只又白的经历,本人刚开始是从事ios开发的,由于一系列的变故现在变为了web前端开发,不过说来也奇怪,刚开始接触前端时间可以说是彻底蒙圈,各种选择器,各种适配搞 ...
- Java可见性机制的原理
基本概念 可见性 当一个线程修改了共享变量时,另一个线程可以读取到这个修改后的值. 内存屏障(Memory Barriers) 处理器的一组指令,用于实现对内存操作的顺序限制. 缓冲行 CPU告诉缓存 ...
- C语言之可重入函数 && 不可重入函数
可重入函数 在 实时系统的设计中,经常会出现多个任务调用同一个函数的情况.如果这个函数不幸被设计成为不可重入的函数的话,那么不同任务调用这个函数时可能修改其他任 务调用这个函数的数据,从而导致不可预料 ...
- SELinux 与强制访问控制系统
SELinux 全称 Security Enhanced Linux (安全强化 Linux),是 MAC (Mandatory Access Control,强制访问控制系统)的一个实现,目的在于明 ...
- mongo 初始配置
连接mongo 时 在window的可视化工具 有时会出现这种无法找到表的情况 那么我们所需要的是什么?? 用客户端的命令行 查看是否能够真正连接成功 下载mongo window 并安装 这个网 ...
- Accordion( 分类) 组件
一. 加载方式 //class 加载方式<div id="box" class="easyui-accordion"style="width:3 ...
- 一小时搞定DIV+CSS布局-固定页面开度布局
本文讲解使用DIV+CSS布局最基本的内容,读完本文你讲会使用DIV+CSS进行简单的页面布局. 转载请标明:http://www.kwstu.com/ArticleView/divcss_20139 ...
- (转)回车 执行button点击
功能说明:当我们注册或者执行搜索时,输入内容后,不用单击按钮来执行按钮单击事件,而直接通过回车来执行按钮单击事件.只要在text框中onkeydown事件中加入执行按钮的onclick事件就OK了 代 ...