sklearn.preprocessing.StandardScaler数据标准化
原文链接:https://blog.csdn.net/weixin_39175124/article/details/79463993
数据在前处理的时候,经常会涉及到数据标准化。将现有的数据通过某种关系,映射到某一空间内。常用的标准化方式是,减去平均值,然后通过标准差映射到均至为0的空间内。系统会记录每个输入参数的平均数和标准差,以便数据可以还原。
很多ML的算法要求训练的输入参数的平均值是0并且有相同阶数的方差例如:RBF核的SVM,L1和L2正则的线性回归
sklearn.preprocessing.StandardScaler能够轻松的实现上述功能。
调用方式为:
首先定义一个对象:
ss = sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
在这里
copy; with_mean;with_std
默认的值都是True.
copy 如果为false,就会用归一化的值替代原来的值;如果被标准化的数据不是np.array或scipy.sparse CSR matrix, 原来的数据还是被copy而不是被替代
with_mean 在处理sparse CSR或者 CSC matrices 一定要设置False不然会超内存
能够查询的属性:
scale_: 缩放比例,同时也是标准差
mean_: 每个特征的平均值
var_:每个特征的方差
n_sample_seen_:样本数量,可以通过patial_fit 增加
举个例子:
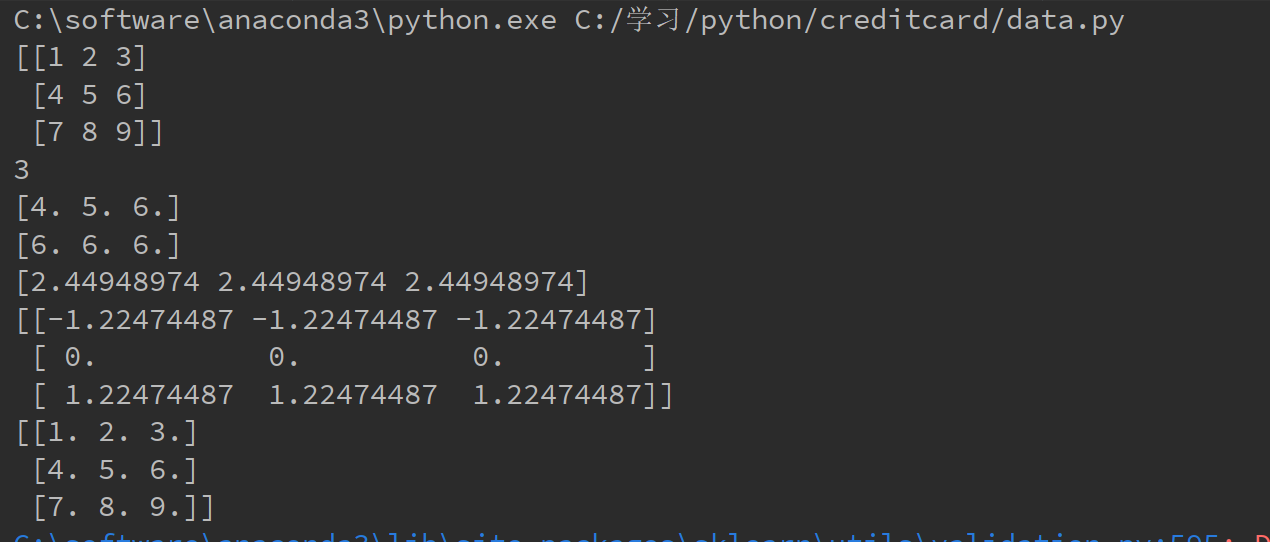
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
#data = pd.read_csv("C:/学习/python/creditcard/creditcard.csv")
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]).reshape((3, 3))
ss = StandardScaler()
print(x)
ss.fit(X=x)
print(ss.n_samples_seen_)
print(ss.mean_)
print(ss.var_)
print(ss.scale_)
y = ss.fit_transform(x)
print(y)
z = ss.inverse_transform(y)
print(z)
运行结果为:
能够被调用的Methods:
fit(X,y=None):计算输入数据各特征的平均值,标准差以及之后的缩放系数 ,以后就可以按照这个数据调用transofrm()
X:训练集
y: 传入为了使得和Pipeline兼容
fit_transform(X,y=None,**fit_params): 通过fit_params调整数据X,y得到一个调整后的X ,使得每个特征的数据分布平均值为0,方差为1
X 为array:训练集
y 为标签
返回一个改变后的X
get_params(deep=True): 返回StandardScaler对象的设置参数,
inverse_transform(X,copy=None):顾名思义,就是按照缩放规律反向还原当前数据
transform(X, y=’deprecated’, copy=None):基于现有的对象规则,标准化新的参数
可以认为fit_transform()是fit()和transform()的合体。
sklearn.preprocessing.StandardScaler数据标准化的更多相关文章
- sklearn.preprocessing.StandardScaler 离线使用 不使用pickle如何做
Having said that, you can query sklearn.preprocessing.StandardScaler for the fit parameters: scale_ ...
- sklearn preprocessing data(数据预处理)
参考: http://scikit-learn.org/stable/modules/preprocessing.html
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- 数据规范化——sklearn.preprocessing
sklearn实现---归类为5大类 sklearn.preprocessing.scale()(最常用,易受异常值影响) sklearn.preprocessing.StandardScaler() ...
- sklearn中的数据预处理----good!! 标准化 归一化 在何时使用
RESCALING attribute data to values to scale the range in [0, 1] or [−1, 1] is useful for the optimiz ...
- sklearn preprocessing (预处理)
预处理的几种方法:标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 知识回顾: p-范数:先算绝对值的p次方,再求和,再开p次方. 数据标准化:尽量将数据转化为均值为0,方差为1的数 ...
- sklearn中常用数据预处理方法
1. 标准化(Standardization or Mean Removal and Variance Scaling) 变换后各维特征有0均值,单位方差.也叫z-score规范化(零均值规范化).计 ...
- 11.sklearn.preprocessing.LabelEncoder的作用
In [5]: from sklearn import preprocessing ...: le =preprocessing.LabelEncoder() ...: le.fit(["p ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
随机推荐
- php和http协议
http协议:电脑与电脑,网络与网络之间传输需要的一些条件: 比如网线互联,能相互找到ip地址(tcp/ip: b/s结构一定要遵循http协议): 报文都要有报头,要给谁传数据,要传什么数据,传什么 ...
- DveOps路线指南
学习DevOps所需的技能 1. 编程语言 python java javascrit 2. 学习不同的操作系统概念 进程管理,线程和兵法,套接字,I/O管理,虚拟化,内存储存储和文件系统. 3. ...
- Http的通信机制?
HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用. HTTP连接 ...
- C# 常用方法——图片转base64字符串
其他扩展方法详见:https://www.cnblogs.com/zhuanjiao/p/12060937.html /// <summary> /// Image 转成 base64 / ...
- DOM添加
㈠添加元素的步骤 ⑴创建空元素 ⑵设置关键属性 ⑶将元素添加到DOM树 ㈡创建空元素 var elem = document.createElement('table'); 示例: var t ...
- mysql 报错从 新安装
卸载从新安装,综合运用 https://www.jb51.net/article/146050.htm https://www.jb51.net/article/90275.htm https://w ...
- 51 Nod 1020 逆序排列
1020 逆序排列 基准时间限制:2 秒 空间限制:131072 KB 分值: 80 难度:5级算法题 收藏 关注 在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么 ...
- tensorboard的log查看方法
使用:tensorboard --logdir=D:\LOG logs --host=127.0.0.1
- 使用Qt Designer进行布局
在使用Form之前,需要将Form上的对象放置到布局中.这确保在应用程序中预览或使用Form时,对象将正确显示.在布局中放置对象还可以确保在调整窗体大小时它们也能正确调整大小. 应用和打断布局 ...
- C++入门经典-例3.19-使用break跳出循环
1:代码如下: // 3.19.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> usin ...