38 是否要使用memory引擎的表
38 是否要使用memory引擎的表
内存表的数据组织结构
create table t1(id int primary key, c int) engine=Memory;
create table t2(id int primary key, c int) engine=innodb;
insert into t1 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
insert into t2 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
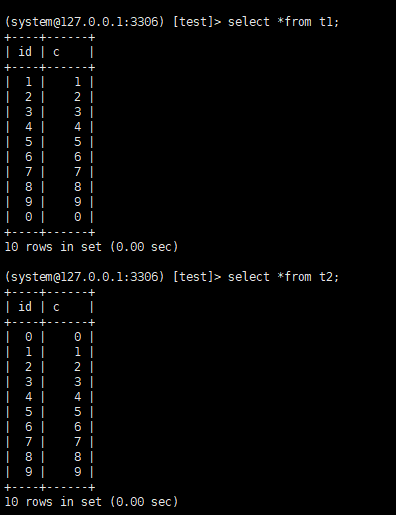
可以看到,内存表t1的返回结果里面0在最后一行,在innodb表t2的返回结果,0在第一行,二者的差别要从他们的主键索引的组织方式说起。
表t2是innodb表,是主键索引id的方式,innodb表的数据放在主键索引树上,是一个B+ tree,如下
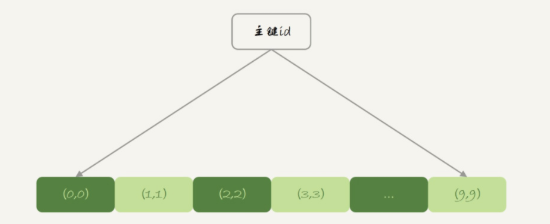
主键索引上的值是有序存储的,在select *的时候,就会按照叶子节点上从左往右扫描,所以结果里0在第一行。
与innodb不同,memory引擎的数据和索引是分开的,

可以看到,内存表的数据部分以数组的方式单独存放,而主键id索引里,存的是每个数据的位置,主键id是hash索引,可以看到索引上的key并不是有序的。
在select * from t1内存表的时候,走全表扫描,也就是顺序扫描这个数组,因此0被最后一个读到,并放入结果集。
Innodb和memory引擎的数据组织方式不同:
--innodb表数据放在主键索引上,其他索引上保存的是主键id,-索引组织表
--而memory把数据单独存放,索引上保存数据位置的数据组织方式--堆组织表
从中可以看出,这两个引擎的一些典型不同
--1 innodb表的数据总是有序存放的,而内存表的数据就是按照写入顺序存放的
--2 当数据文件有空洞的时候,innodb表在插入新数据的时候,为了保证数据有序性,只能在固定的位置写入新值,而内存表找到空位就可以插入新值
--3 数据位置发生变化的时候,innodb表只需要修改主键索引,而内存表需要修改所有索引
--4 innodb表用主键索引查询时候需要走一次索引查找,而普通索引查询的时候,需要走两次索引查找,而内存表没有这个区别,所有所以的”地位”都是相同的。
--5 innodb支持变长数据类型,不同记录的长度可能不同,内存表不支持blob,text字段,并且即使定义了varchar(n),实际上也当中char(n),也就是固定长度字符串来存储,因此内存表的每行数据长度相同。
由于内存表的这些特性,每个数据行被删除以后,空出的这个位置都可以被接下来插入的数据复用
delete from t1 where id=5;
insert into t1 values(10,10);
select * from t1;

可以看到id=10这一行出现在id=4之后,也就是原来id=5的位置,
表t1的这个主键是哈希索引,因此如果执行范围查询
select * from t1 where id<5;

是用不上主键索引的,需要走全表扫描
Hash索引和b+tree索引
实际上,内存表也支持b+tree索引,在id列上创建b+tree
alter table t1 add index a_btree_index using btree (id);

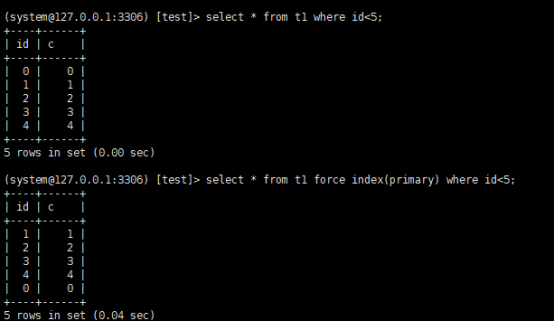
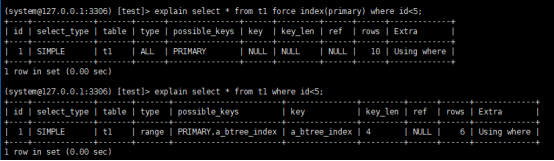
可以看到,执行select * from t1 where id<5;,优化器选择了b+tree索引,返回结果也是0到4
其实,一般在我们的印象中,内存表的优势是速度快,其中一个原因就是memory引擎支持hash索引,当然更重要的是内存表的所有数据都在内存中,而内存中的读取速度比磁盘快。
接下来要说,在生产环境不建议使用内存表,主要原因包括
--1 锁粒度问题
--2 数据持久化问题
内存表的锁
内存表不支持行锁,只支持表锁,因此,一张表只要有更新,就会堵住其他所有的在这个表上的写操作
需要注意的是,这个表锁跟表MDL锁不同,但都是表级锁,
|
SESSION A |
SESSION B |
SESSION C |
|
update t1 set id=sleep(50) where id=1; |
||
|
select * from t1 where id=2;(堵塞50秒) |
||
|
show full processlist; |


跟行锁比起来,表锁对并发访问的支持不够好,所以,内存表的锁粒度问题,在处理并发事务的时候,性能也不会太好
数据持久性问题
数据放在内存中,是内存表的优势,但也是一个劣势,在数据库重启的时候,内存中的数据会被清空。
在M-S架构下,使用内存表存在的问题
--1 业务正常访问主库
--2 备库硬件升级,备库重启,内存表t1内容被清空
--3 备库重启后,客户端发送一条update语句,修改表t1的数据行,这是备库报错找不到更新的行
这样就会导致主备同步停止,当然,如果这时候发生主备切换,客户端会看到,表t1的数据丢失了
由于mysql知道重启后,内存表的数据会丢失,所以,担心主库重启之后,出现主备不一致,mysql在数据库重启之后,往binlog里面写入一行delete from t1,在备库重启的时候,备库binlog里的delete语句就会传到主库,然后把主库内存表的数据删除。
内存表并不适合生产环境作为普通表使用。
所以,建议是把普通内存表都用innodb表来代替。
但是有一个场景例外,就是前面说到的用户临时表,在数据量可控,不会消耗过多内存的情况下,可以考虑使用内存表。
内存临时表刚好可以无视内存表的两个不足
--1 临时表不会被其他线程看到,没有并发性的问题
--2 临时表重启后也是需要删除的,清空数据这个问题不存在
--3 备库的临时表也不会影响主库的用户线程。
前面创建临时表用于保存中间结果集
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
--换成memory引擎
create temporary table temp_t(id int primary key, a int, b int, index (b))engine=memory;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
38 是否要使用memory引擎的表的更多相关文章
- 38 | 都说InnoDB好,那还要不要使用Memory引擎?
我在上一篇文章末尾留给你的问题是:两个 group by 语句都用了 order by null,为什么使用内存临时表得到的语句结果里,0 这个值在最后一行:而使用磁盘临时表得到的结果里,0 这个值在 ...
- 存储引擎和表的操作(mysql中的数据类型、完整性约束)
一.存储引擎 .概念 MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力. 通过选择不同的技术 ...
- mysql 库操作、存储引擎、表操作
阅读目录 库操作 存储引擎 什么是存储引擎 mysql支持的存储引擎 如何使用存储引擎 表操作 创建表 查看表结构 修改表ALTER TABLE 复制表 删除表 数据类型 表完整性约束 回到顶部 一. ...
- Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束
Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束 一丶MySQL的存储引擎 什么是存储引擎: MySQL中的数据用各种不同的技术存储在文件( ...
- MySQL-存储引擎-创建表-字段数据类型-严格模式-字段约束-键-02
目录 扩展点 查看服务端字符.IP.端口配置 取消本次错误输入 例外情况 database 数据库操作 table 数据表操作 查看MySQL存储引擎 常见几个存储引擎 InnoDB MyISAM M ...
- [MySQL数据库之表的详细操作:存储引擎、表介绍、表字段之数据类型]
[MySQL数据库之表的详细操作:存储引擎.表介绍.表字段之数据类型] 表的详细操作 存储引擎 mysql中建立的库======>文件夹 库中建立的表======>文件 用来存储数据的文件 ...
- InnoDB 引擎独立表空间 innodb_file_per_table
使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构.表索引.表数据空间.我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作.然而当你 ...
- memory引擎的索引失效一例
memory引擎的索引失效一例 memory引擎的索引失效一例
- InnoDB 引擎独立表空间
InnoDB 引擎独立表空间 使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构.表索引.表数据空间.我们可以将某个数据库目录直接迁移到 ...
随机推荐
- MongoDB的使用学习之(五)Spring集成MongoDB以及简单的CRUD
这篇文章不错:Spring Data - MongoDB 教程 (1.0.0.M1)http://miller-cn.iteye.com/blog/1258859 1.介绍 之前在很多地方一直见到这个 ...
- MOVE - 重定位一个游标
SYNOPSIS MOVE [ direction { FROM | IN } ] cursorname DESCRIPTION 描述 MOVE 在不检索数据的情况下重新定位一个游标. MOVE AL ...
- 07.Linux系统-Fastdfs分布式文件系统-互为主从配置搭建部署
Fastdfs分布式文件系统-互为主从配置部署 1.安装基础依赖 yum install -y gcc gcc-c++ pcre pcre-devel zlib zlib-devel openssl ...
- vscode 黑屏及类名报错解决方案
1.安装vscode之后打开黑屏,解决方案如下图,右键--属性--兼容性--勾选上 2.vscode 类名总报错 是ES2017的语法修饰器引起vscode警告. 解除的方法如果你使用的typescr ...
- VMware Workstation 卸载时卡在“正在卸载网络驱动程序(Virtual Network Editor夯死)”
出现此种问题,以下方式均无法成功卸载: 控制面板-卸载程序(Virtual Network Editor 未响应) Geek 卸载VMware Workstation(Virtual Network ...
- 长沙理工大学第十二届ACM大赛-重现赛 D 小M和天平 (01背包)
链接:https://ac.nowcoder.com/acm/contest/1/D 来源:牛客网 小M和天平 时间限制:C/C++ 2秒,其他语言4秒 空间限制:C/C++ 131072K,其他语言 ...
- Keepalived+Nginx+tomcat实现主备+负载
部署系统: Red Hat Enterprise Linux Server release 7.0 软件版本:apache-tomcat-7.0.92.tar.gzkeepalived-2.0.11. ...
- 左半连接left demi-join
返回左边表的记录,前提是其记录对于右边表满足on语句的判定条件 对于左表中一条指定的记录,在右表中一旦找到匹配的记录,hive就会立即停止扫描 1.sql select s.myd,s,symbol, ...
- C\C++下获取系统进程或线程ID(转)
在程序开发时有时需要获取线程和进程ID以分析程序运行 ()windows下获取进程或线程ID 通过调用系统提供的GetCurProcessId或GetNowThreadID来获取当前程序代码运行时的进 ...
- HTML/CSS实现文字环绕图片布局
原文: https://blog.csdn.net/yiyelanxin/article/details/75006925 在一个图文并茂的网页上,文字环绕图片可以使布局美观紧凑,如何实现呢?有两种办 ...