Task5.NB_SVM_LDA
参考:https://blog.csdn.net/u013710265/article/details/72780520
贝叶斯公式就一行: P(Y|X)=P(X|Y)P(Y)P(X)
而它其实是由以下的联合概率公式推导出来:P(Y,X)=P(Y|X)P(X)=P(X|Y)P(Y)
P(X)为X的先验概率,P(Y|X)称为后验概率。
从机器学习看贝叶斯:
我们把X理解成“具有某特征”,把Y理解成“类别标签”(一般机器学习为题中都是X=>特征, Y=>结果对吧)。在最简单的二分类问题(是与否判定)下,我们将Y理解成“属于某类”的标签。于是贝叶斯公式就变形成了下面的样子:
P(“属于某类”|“具有某特征”)=P(“具有某特征”|“属于某类”)P(“属于某类”)P(“具有某特征”)
我们简化解释一下上述公式:
P(“属于某类”|“具有某特征”)=在已知某样本“具有某特征”的条件下,该样本“属于某类”的概率。所以叫做『后验概率』。
P(“具有某特征”|“属于某类”)=在已知某样本“属于某类”的条件下,该样本“具有某特征”的概率。
P(“属于某类”)=(在未知某样本具有该“具有某特征”的条件下,)该样本“属于某类”的概率。所以叫做『先验概率』。
P(“具有某特征”)=(在未知某样本“属于某类”的条件下,)该样本“具有某特征”的概率。
而我们二分类问题的最终目的就是要判断P(“属于某类”|“具有某特征”)是否大于1/2就够了。
这里再补充一下,一般『先验概率』、『后验概率』是相对出现的,比如P(Y)与P(Y|X)是关于Y的先验概率与后验概率,P(X)与P(X|Y)是关于X的先验概率与后验概率。
朴素贝叶斯:
假设事物属性之间相互条件独立。相当于词袋模型,失去了词语之间的顺序信息,比如“我吃了小猪”和“小猪吃了我”被它认为是同一件事。
虽然很naive,但是在很多时候比一些复杂的分类器还要好用。
朴素贝叶斯分类器是是一种有监督学习,常见两种模型:
1.多项式模型(词频型),伯努利模型(文档型)
2.高斯模型
模型1中两者在计算重复出现的词时有些不同,多项式模型考虑每个文档中出现某个词的次数(重复出现的词语视为出现多次),而伯努利模型考虑出现某个词的文档的个数(重复出现的词语视为1次)
P((“代开”,“发票”,“增值税”,“发票”,“正规”,“发票”)|S)=P(“代开””|S)P(“发票”|S)P(“增值税”|S)P(“发票”|S)P(“正规”|S)P(“发票”|S)=P(“代开””|S)P3(“发票”|S)P(“增值税”|S)P(“正规”|S) 注意这一项:P^3(“发票”|S)。
在统计计算P(“发票”|S)时,每个被统计的垃圾邮件样本中重复的词语也统计多次。
P(“发票”|S)=每封垃圾邮件中出现“发票”的次数的总和/每封垃圾邮件中所有词出现次数(计算重复次数)的总和
你看这个多次出现的结果,出现在概率的指数/次方上,因此这样的模型叫作多项式模型。
P((“代开”,“发票”,“增值税”,“发票”,“正规”,“发票”)|S)=P(“发票”|S)P(“代开””|S)P(“增值税”|S)P(“正规”|S)
统计计算)P(“词语”|S)时也是如此。
P(“发票”|S)=出现“发票”的垃圾邮件的封数 / 每封垃圾邮件中所有词出现次数(出现了只计算一次)的总和
这样的模型叫作伯努利模型(又称为二项独立模型)。这种方式更加简化与方便。当然它丢失了词频的信息,因此效果可能会差一些。
当对连续属性进行离散化时,如对身高,小于160记为0,160~170记为1,170~180记为2.。。或者用onehot,但是这样的离散化都不细腻,用高斯模型来解决这个问题。
高斯模型假设这些一个特征的所有属于某个类别的观测值属于高斯分布。
代码:
from sklearn.naive_bayes import GaussianNB def train_model_GaussianNB():
pass
clf3 = GaussianNB()
clf3.fit(X[499:],y[499:])
predict_labels = clf3.predict(X[0:499]) n = 0
for i in range(len(predict_labels)):
if(predict_labels[i] == y[i]):
n += 1
print("高斯贝叶斯:") print(n/499.0)
//混淆矩阵
confusion_matrix(y[0:499],predict_labels)
return
多项式模型:
在多项式模型中,设某文档d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复,则先验概率P(c)= 类c下单词总数/整个训练样本的单词总数。类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|)。
其中V是训练样本的单词表(即抽取单词,单词出现多次,只算一个),|V|则表示训练样本包含多少种单词。P(tk|c)可以看作是单词tk在证明d属于类c上提供了多大的证据,而P(c)则可以认为是类别c在整体上占多大比例(有多大可能性)。
#多项式贝叶斯
from sklearn.naive_bayes import MultinomialNB def train_model_MultinomialNB():
pass
clf = MultinomialNB()
clf.fit(X[499:],y[499:]) predict_labels = clf.predict(X[0:499]) n = 0
for i in range(len(predict_labels)):
if(predict_labels[i] == y[i]):
n += 1
print(n/499.0)
confusion_matrix(y[0:499],predict_labels)
return
伯努利贝叶斯:
P(c)= 类c下文件总数/整个训练样本的文件总数
P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下包含的文件+2)
from sklearn.naive_bayes import BernoulliNB
#伯努利贝叶斯
def train_model_BernoulliNB():
pass
clf2 = BernoulliNB()
clf2.fit(X[499:],y[499:])
predict_labels = clf2.predict(X[0:499]) n = 0
for i in range(len(predict_labels)):
if predict_labels[i] == y[i]:
n += 1
print(n/499.0)
confusion_matrix(y[0:499],predict_labels)
return
SVM




LDA
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
1、LDA生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
(1)对每一篇文档,从主题分布中抽取一个主题;
(2)从上述被抽到的主题所对应的单词分布中抽取一个单词;
(3)重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
2、LDA整体流程
文档集合D,主题集合T
D中每个文档d看作一个单词序列<w1, w2, …… ,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)
文档集合D中的所有单词组成一个大集合VOCABULARY(简称VOC)。
LDA以文档集合D作为输入,希望训练出两个结果向量(设聚成k个topic,VOC中共包含m个词)。
对每个D中的文档d,对应到不同Topic的概率θd<pt1,...,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
对每个T中的topic,生成不同单词的概率φt<pw1,...,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。
LDA的核心公式如下:
p(w|d)=p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
LDA处理文本:
先pip install lda --user
from __future__ import division,print_function import numpy as np
import lda
import lda.datasets x = lda.datasets.load_reuters()
print('type(X):{}'.format(type(x)))
print('shape:{}\n'.format(x.shape))
print(x[:5,:5])

x为395x4258的矩阵,文本数395,单词数4258,值代表出现次数
查看前六个单词:
vocab = lda.datasets.load_reuters_vocab()
print('type(vocab):{}'.format(type(vocab)))
print('len(vocab):{}\n'.format(len(vocab)))
print(vocab[:6])

x中第0列为church,第1列为pope...
查看文章标题:
titles = lda.datasets.load_reuters_titles()
print('type(titles):{}'.format(type(titles)))
print('len(titles):{}'.format(len(titles)))
print(titles[:2])

训练数据,迭代500次,指定主题个数20:
model = lda.LDA(n_topics=20,n_iter=500,random_state=1)
model.fit(x)
查看主题-单词分布:
topic_word = model.topic_word_
print('type(topic_word):{}'.format(type(topic_word)))
print('shape:{}'.format(topic_word.shape))

topic_word中一行是一个topic,每一行的和为1.
查看church,pope,years在每个主题中占的比重:
print(topic_word[:,:3])

获取每个topic下权重最高的5个词:
n = 5
for i,topic_dist in enumerate(topic_word):
topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n+1):-1]
print('Topic{}\n-{}'.format(i,' '.join(topic_words)))

文档-主题分布:
#文档主题分布
doc_topic = model.doc_topic_
print('type(doc_topic):{}'.format(type(doc_topic)))
print('shape:{}'.format(doc_topic.shape))
同主题-单词分布,每一行为每篇文章,没行和为1
输出前10篇文章最可能的topic:
for n in range(10):
topic_most_pr = doc_topic[n].argmax()
print('doc:{}topic:{}'.format(n,topic_most_pr))
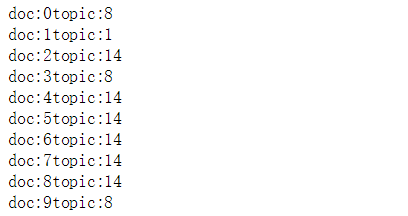
关于数据集替换
下载包以后,把datasets.py里面的load_reuters()里面的reuters.ldac,load_reuters_vocab()里面的reuters.tokens,load_reuters_titles()里面的reuters.titles替换成自己的数据集就行了.数据集格式按照包里的生成就行.
参考:https://blog.csdn.net/u013710265/article/details/73480332
参考:https://blog.csdn.net/fisherming/article/details/79462627
Task5.NB_SVM_LDA的更多相关文章
- Datawhale MySQL 训练营 Task5
数据导入导出 导入table http://www.runoob.com/mysql/mysql-database-import.html 导出table http://www.runoob.com/ ...
- Task5.PyTorch实现L1,L2正则化以及Dropout
1.了解知道Dropout原理 深度学习网路中,参数多,可能出现过拟合及费时问题.为了解决这一问题,通过实验,在2012年,Hinton在其论文<Improving neural network ...
- iOS多线程实现3-GCD
原文链接:http://www.cnblogs.com/mddblog/p/4767559.html 敲下gcd三个字母,搜狗第一条显示居然是“滚床单” ^_^ 一.介绍 GCD,英文全称是Grand ...
- java多线程系类:JUC线程池:05之线程池原理(四)(转)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
- java并发编程学习:如何等待多个线程执行完成后再继续后续处理(synchronized、join、FutureTask、CyclicBarrier)
多线程应用中,经常会遇到这种场景:后面的处理,依赖前面的N个线程的处理结果,必须等前面的线程执行完毕后,后面的代码才允许执行. 在我不知道CyclicBarrier之前,最容易想到的就是放置一个公用的 ...
- Spring task定时任务
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://mave ...
- [分享] 封装工具ES4配置文件解释
[分享] 封装工具ES4配置文件解释 LiQiang 发表于 2015-2-3 14:41:21 https://www.itsk.com/thread-346132-1-4.html [分享] 封装 ...
- Java多线程系列--“JUC线程池”05之 线程池原理(四)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
- java并发编程(4)--线程池的使用
转载:http://www.cnblogs.com/dolphin0520/p/3932921.html 一. java中的ThreadPoolExecutor类 java.util.concurre ...
随机推荐
- 十三、python列表方法汇总
'''1.append():更新列表'''l=[]l.append('111')l.append('[123,456]')print l-------------------------------- ...
- 【cs231n作业笔记】二:SVM分类器
可以参考:cs231n assignment1 SVM 完整代码 231n作业 多类 SVM 的损失函数及其梯度计算(最好)https://blog.csdn.net/NODIECANFLY/ar ...
- Firefox,Chrome使用
Firefox 插件 REDIRECTOR Automatically redirect pages based on user-defined rules. 根据用户定义的规则自动重定向页面的插件. ...
- JS-预留字符和转义字符转换
字符实体(Entity) 转义字符(Escape Sequence)也称字符实体 (Character Entity). 定义转义字符串的主要原因是: <和>等符号已经用来表示 HTML ...
- android hidl
1.定义.hal接口文件,如: 在vendor/sprd/interface中新建目录hello,其中定义好hidl接口,如: package vendor.sprd.hardware.hello@1 ...
- IncSecond:将一个TDateTime变量加减一定数量的秒数
http://tieba.baidu.com/p/1998083296 IncSecond:将一个TDateTime变量加减一定数量的秒数 声明:function IncSecond ( const ...
- [Usaco2005 mar]Yogurt factory 奶酪工厂
接下来的N(1≤N10000)星期中,奶酪工厂在第i个星期要花C_i分来生产一个单位的奶酪.约克奶酪工厂拥有一个无限大的仓库,每个星期生产的多余的奶酪都会放在这里.而且每个星期存放一个单位的奶酪要花费 ...
- Docker中使用多阶段Dockerfile构建容器镜像image(镜像优化)
使用多阶段构建 预计阅读时间: 6分钟 多阶段构建是守护程序和客户端上需要Docker 17.05或更高版本的新功能.多阶段构建对于那些努力优化Dockerfiles同时使其易于阅读和维护的人来说非常 ...
- [Web 前端] 012 css 元素溢出
overflow 当子元素的尺寸超过父元素的尺寸时,需要设置父元素显示溢出的子元素的方式 通过 overflow 属性来设置 概览 参数 释义 visible(默认值) 内容不会被修剪会呈现在元素框之 ...
- [Python3] 018 if:我终于从分支中走出来了
目录 0. 谁是主角 1. 从三大结构说起 (1) 顺序 (2) 分支 1) 分支的基本语法 2) 双向分支 3) 多路分支 (3) 循环 0. 谁是主角 分支是主角 我前面几篇随笔提到 if 不下2 ...