CentOS7.4伪分布式搭建 hadoop+zookeeper+hbase+opentsdb
前言
由于hadoop和hbase都得想zookeeper注册,所以启动顺序为 zookeeper——》hadoop——》hbase,关闭顺序反之
一、前期准备
1、配置ip
进入文件编辑模式:
vim /etc/sysconfig/network-scripts/ifcfg-ens192
原内容:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=dhcp
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens192
UUID=f384ed85-2e1e-4087-9f53-81afd746f459
DEVICE=ens192
ONBOOT=no
修改后内容:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens192
UUID=f384ed85-2e1e-4087-9f53-81afd746f459
DEVICE=ens192
ONBOOT=yes
IPADDR=192.168.0.214
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
DNS=183.***.***.100
重启网络使之生效
service network restart
用CRT进行登录
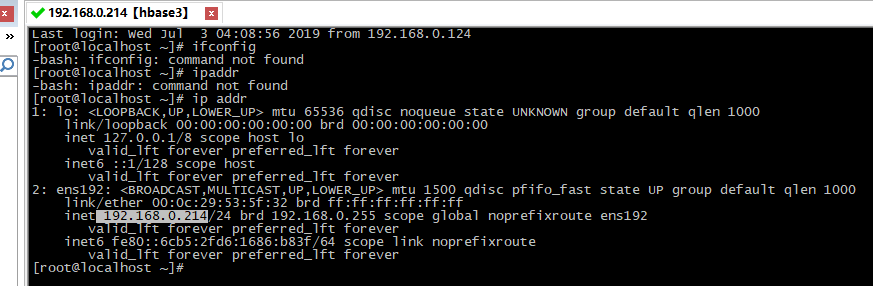
2、修改hostname
# 查看
hostname
# 修改
hostnamectl set-hostname 'hbase3'

3、映射hostname
vi /etc/hosts
添加红框栏:

4、联网
方便yum下载安装包或者安装一些命令,就必须联网:
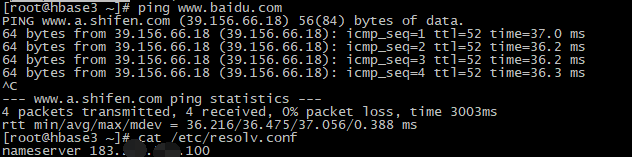
#检查是否联网: ping: www.baidu.com: Name or service not known说明未联网 #配置/etc/resolv.conf
vi /etc/resolv.conf
#添加以下内容: 这里的ip与第1步的DNS后面的ip相同
nameserver 183.***.***.100
#验证:PING www.a.shifen.com (39.156.66.18) 56(84) bytes of data. 说明联网成功
ping www.baidu.com
5、安装vim、rz、sz
yum install -y vim
yum install -y lrzsz
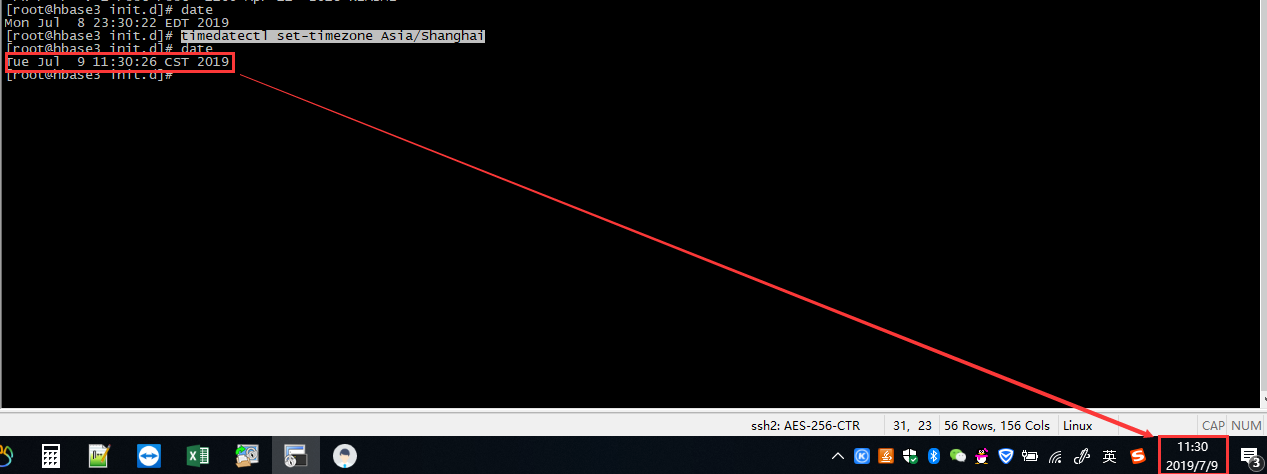
6、设置时区
注:操作系统有两个时间: 软件时间(date)和硬件时间(hwclock )
# 查看时间
date
# 设置时区
timedatectl set-timezone Asia/Shanghai #检查时间
date
hwclock

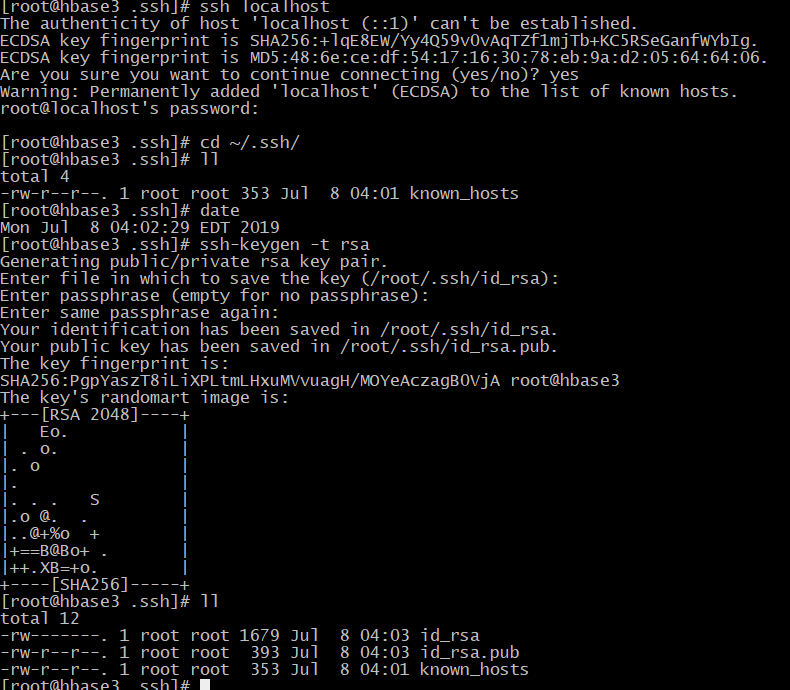
7、免密登录
#测试是否免密登录
ssh localhost #进入路径
cd ~/.ssh/
#生成对钥
ssh-keygen -t rsa
#将公钥拷贝到 authorized_keys
cat id_rsa.pub >> authorized_keys #验证
ssh localhost
验证结果:

8、下载准备安装包
注:1、hbase与hadoop的匹配表见http://hbase.apache.org/book.html#basic.prerequisites
2、我在/opt/soft分别准备以下安装包:点击链接可以卡查看并下载最新版本
jdk: jdk-8u191-linux-x64.tar.gz
hadoop: hadoop-3.1.2.tar.gz
zookeeper: zookeeper-3.4.13.tar.gz
hbase: hbase-2.1.4-bin.tar.gz
opentsdb:opentsdb-2.4.0.tar.gz

二、开始安装
1、安装jdk
注:由于要安装的hadoop、zookeeper、habse、opentsdb都是java语言开发的,故首先需要安装jdk。
#进入到安装包所在路径
cd /opt/soft/jdk
#解压安装包
tar -zxvf jdk-8u191-linux-x64.tar.gz #配置环境变量
vim /etc/profile
#在/etc/profile最后添加内容
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin #使环境变量生效
source /etc/profile #验证
java -version
验证时出现如截图内容则说明安装成功

2、安装hadoop
【1】解压安装
#进入到安装包所在路径
cd /opt/soft/hadoop
#解压安装包
tar -zxvf hadoop-3.1.2.tar.gz #配置环境变量
vim /etc/profile
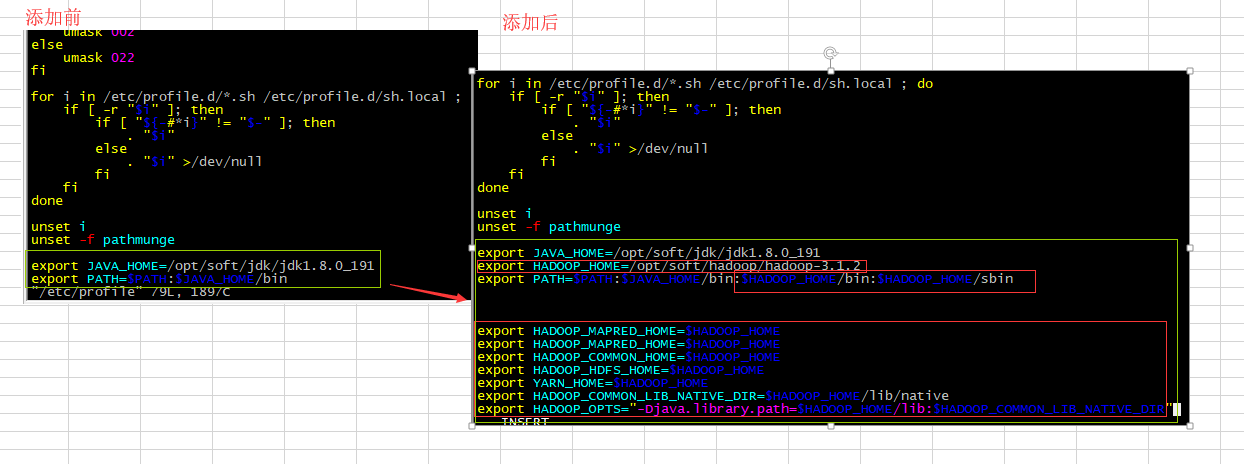
#在/etc/profile添加JAVA_HOME的后面继续添加 綠色部分
export HADOOP_HOME=/opt/soft/hadoop/hadoop-3.1.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
#使环境变量生效
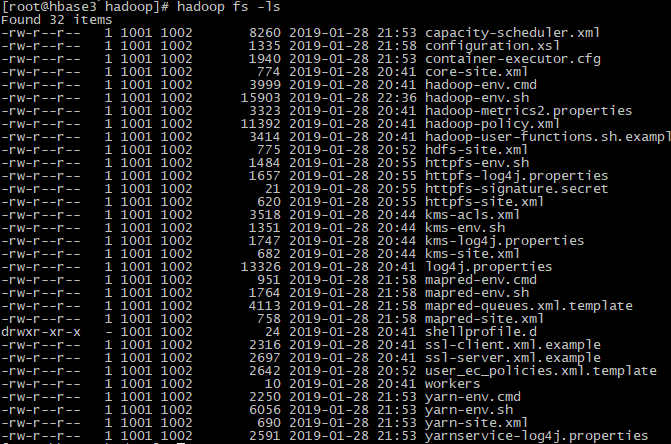
source /etc/profile #验证:不报-bash: hadoop: command not found则说明成功
hadoop fs -ls
【2】配置
hadoop-env.sh
#进入到配置文件路径:
cd /opt/soft/hadoop/hadoop-3.1.2/etc/hadoop #备份:
cp hadoop-env.sh hadoop-env.sh.bak #进入配置文件:
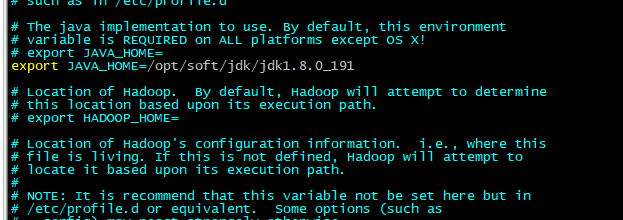
vim hadoop-env.sh #设置java 环境变量,虽然系统中定义了java_home,在hadoop中需要重新配置
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_191
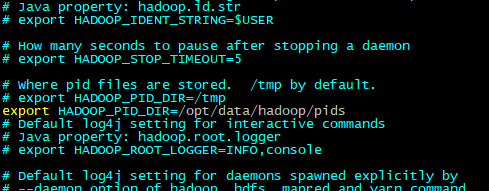
#配置数据路径
export HADOOP_PID_DIR=/opt/data/hadoop/pids
core-site.xml
#备份:
cp core-site.xml core-site.xml.bak #进入配置文件:
vim core-site.xml <!--配置:configration标签中添加以下内容--> <property>
<name>fs.defaultFS</name>
<value>hdfs://hbase3:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop/hadoop-3.1.2/data</value>
</property>
hdfs-site.xml
#备份:
cp hdfs-site.xml hdfs-site.xml.bak #进入配置文件:
vim hdfs-site.xml <!--配置:configuration标签中加以下内容--> <property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop/hadoop-3.1.2/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/opt/soft/hadoop/hadoop-3.1.2/hdfs/data,/opt/soft/hadoop/hadoop-3.1.2/hdfs/data_bak</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hbase3:50070</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
mapred-site.xml
# 备份:
cp mapred-site.xml mapred-site.xml.bak # 进入配置文件:
vim mapred-site.xml <!--配置:configuration标签中加以下内容--> <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/soft/hadoop/hadoop-3.1.2/etc/hadoop,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/common/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/common/lib/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/hdfs/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/hdfs/lib/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/mapreduce/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/mapreduce/lib/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/yarn/*,
/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>mapreduce.jobhistroy.address</name>
<value>hbase3:10020</value>
</property>
<property>
<name>mapreduce.jobhistroy.webapp.address</name>
<value>hbase3:19888</value>
</property>
yarn-site.xml
#备份:
cp yarn-site.xml yarn-site.xml.bak #进入配置文件:
vim yarn-site.xml <!--配置:configuration标签中加以下内容--> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.resourcemanager.hostname</name>
<value>hbase3</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hbase3:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hbase3:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hbase3:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hbase3:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hbase3:8088</value>
</property>
注:以下配置是为了解决报错:no HDFS_NAMENODE_USER defined
start-dfs.sh、stop-dfs.sh
# 进入目录
cd /opt/soft/hadoop/hadoop-3.1.2/sbin
# 备份:
cp start-dfs.sh start-dfs.sh.bak
cp stop-dfs.sh stop-dfs.sh.bak # 进入文件编辑模式:
vim start-dfs.sh
vim stop-dfs.sh # 配置:添加以下内容(我是用root账户安装和启动HADOOP) HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh、stop-yarn.sh
# 备份:
cp start-yarn.sh start-yarn.sh.bak
cp stop-yarn.sh stop-yarn.sh.bak # 进入文件编辑模式:
vim start-yarn.sh
vim stop-yarn.sh # 配置:添加以下内容 YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
【3】启动
注:1、重新格式化HADOOP前需要清空所有DATA目录数据:包括dfs下的、保存缓存数据的、以及hadoop的、zookeeper的log日志文件;以及zookeeper的data下zookeeper_service.pid
2、如果出现nativelib不能加载的情况,需要查看native包的版本是否为64位(file libhadoop.so.1.0.0 ),如果不匹配则需要用64位环境编译或者更换64位包。
start-dfs.sh、stop-dfs.sh
# 格式化hdfs
hdfs namenode -format
# 启动(start-all.sh 相当于start-dfs.sh+start-yarn.sh )
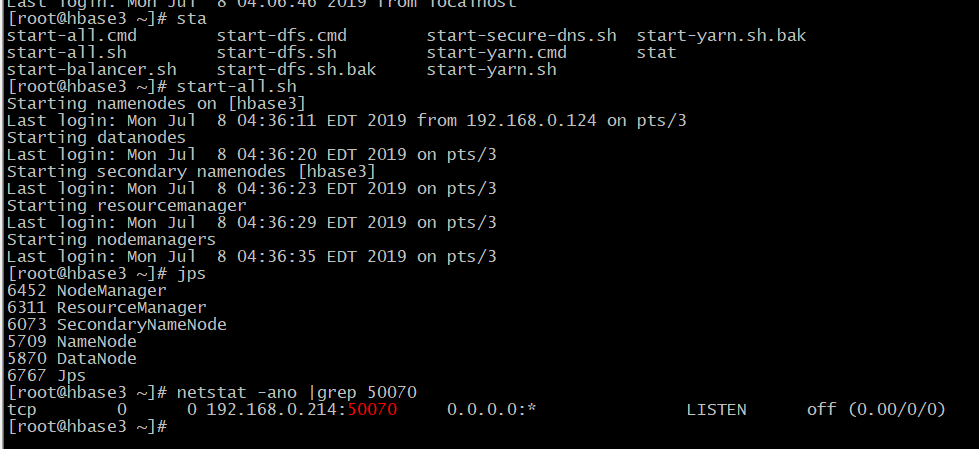
start-all.sh
## 验证
# 1、端口验证
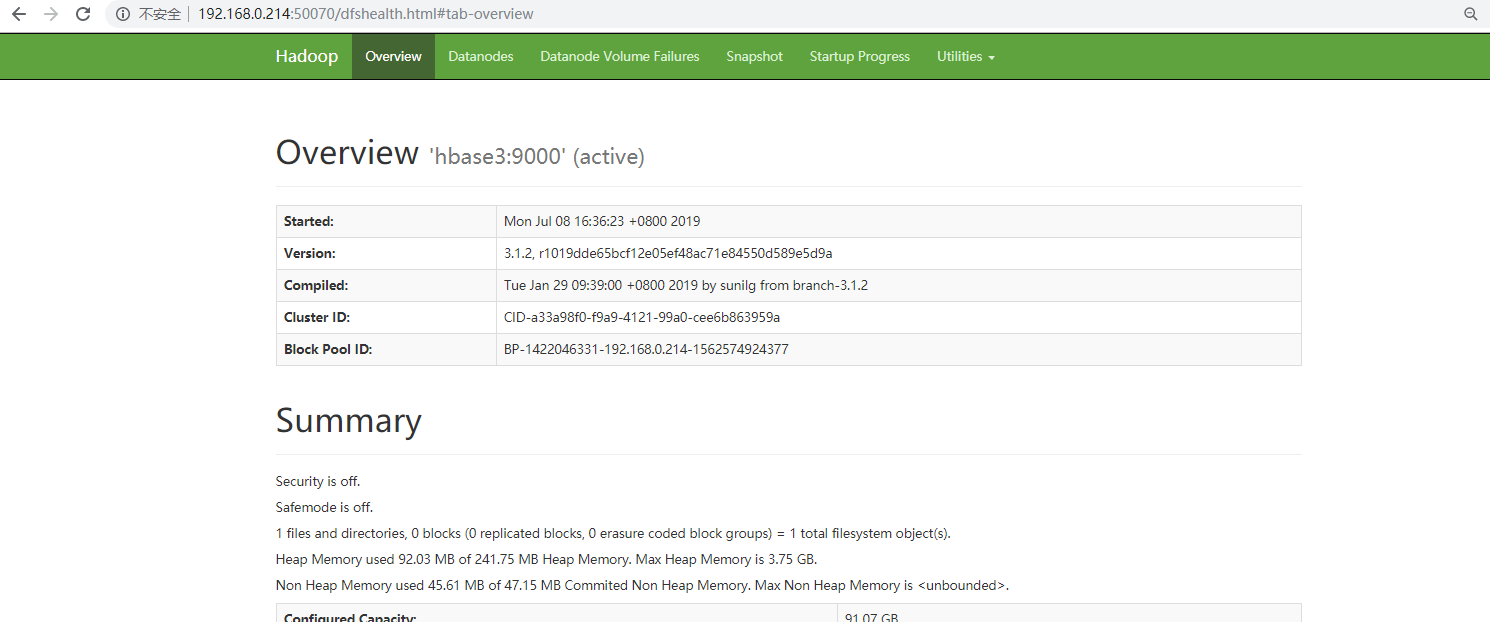
netstat -ano |grep 50070 # 2、web验证: 如上面验证正常,不能访问web,检查防火墙等
http://192.168.0.214:50070
3、安装zookeeper
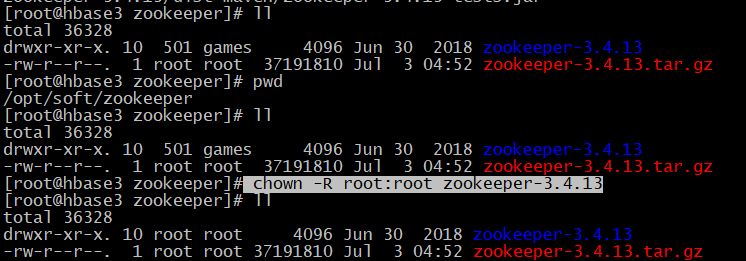
【1】解压安装
# 进入目录
cd /opt/soft/zookeeper # 解压
tar -zxvf zookeeper-3.4.13.tar.gz
# 修改用户权限
chown -R root:root zookeeper-3.4.13
【2】配置
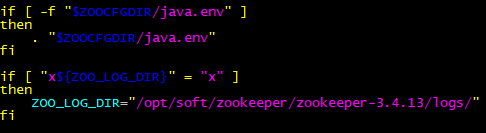
日志路径zkEnv.sh
如果不指定zkEnv.sh的ZOO_LOG_DIR的话,则当前在什么位置启动,则日志就生成到那个目录,不方便以后查找日志
vim /opt/soft/zookeeper/zookeeper-3.4.13/bin/zkEnv.sh #将ZOO_LOG_DIR="."设置为
ZOO_LOG_DIR="/opt/soft/zookeeper/zookeeper-3.4.13/logs/"

zoo.cfg
# 进入目录
cd zookeeper-3.4.13/conf/
# 将zoo_sample.cfg复制给zoo.cfg
cp zoo_sample.cfg zoo.cfg # 修改zoo.cfg
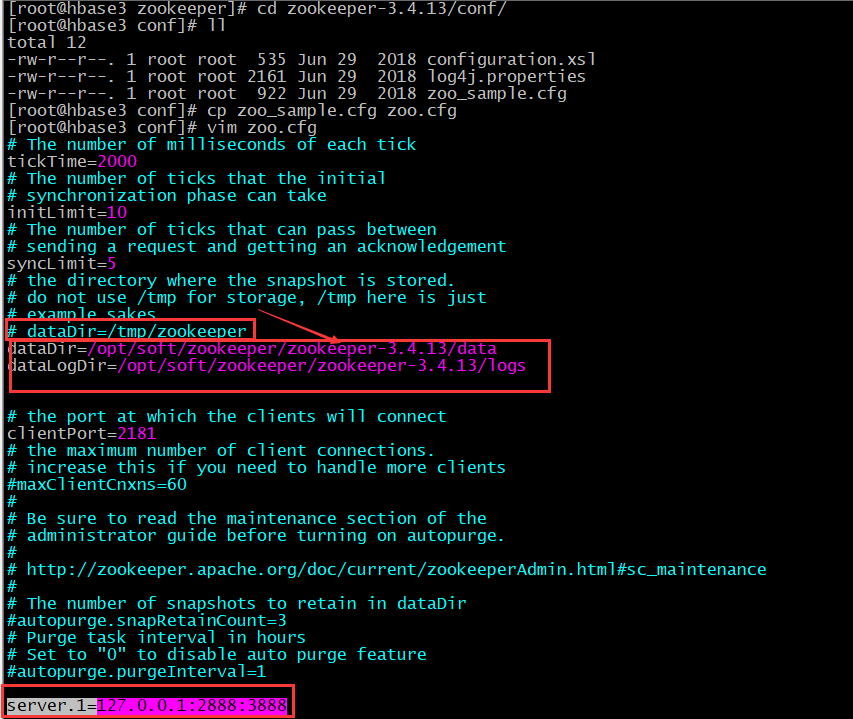
vim zoo.cfg # 配置:添加以下内容(注释掉dataDir=/tmp/zookeeper) dataDir=/opt/soft/zookeeper/zookeeper-3.4.13/data
dataLogDir=/opt/soft/zookeeper/zookeeper-3.4.13/logs server.1=127.0.0.1:2888:3888
环境变量 /etc/profile
# 进入环境变量
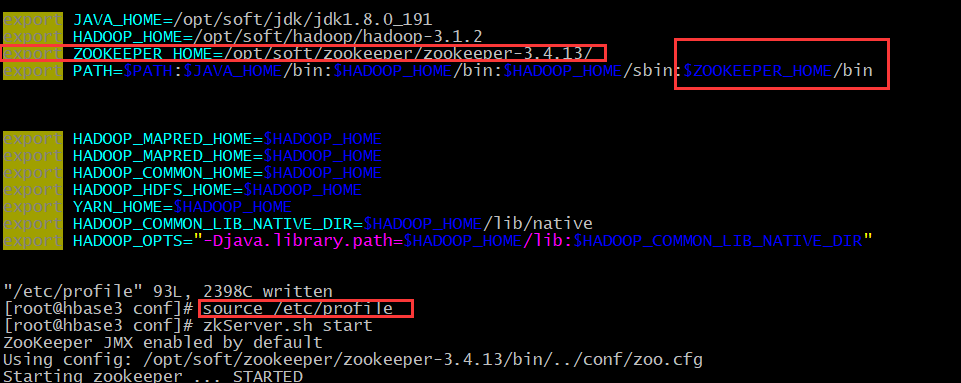
vim /etc/profile # 继续添加
export ZOOKEEPER_HOME=/opt/soft/zookeeper/zookeeper-3.4.13/
:$ZOOKEEPER_HOME/bin # 使环境变量生效
source /etc/profile
【3】启动
# 启动
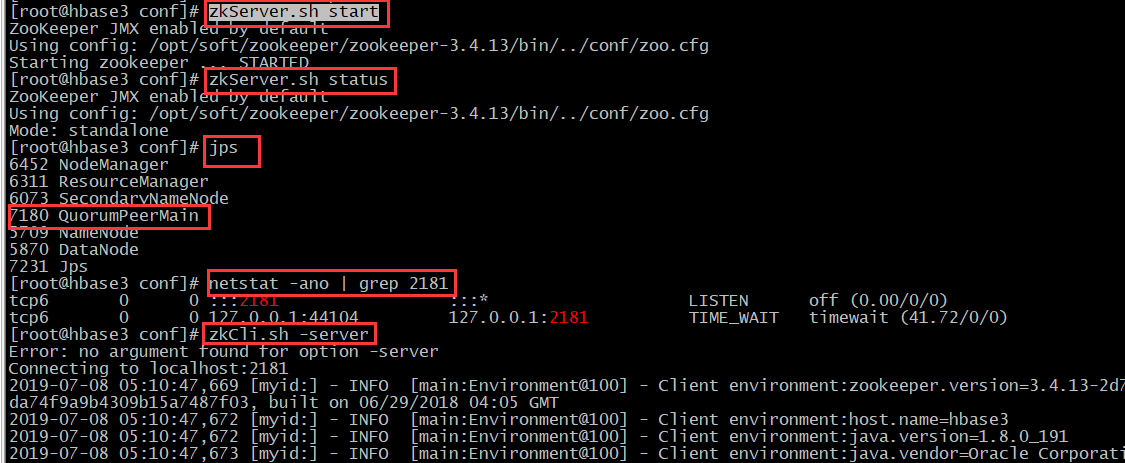
zkServer.sh start # 验证
# 1、端口验证
netstat -ano | grep 2181
# 2、客户端验证
zkCli.sh -server
4、安装hbase
【1】解压安装
注:hbase与hadoop的匹配表见http://hbase.apache.org/book.html#basic.prerequisites
# 进入目录
cd /opt/soft/hbase/ #解压
tar -zxvf hbase-2.1.4-bin.tar.gz
【2】配置
zoo.cfg
# 将zookeeper下的zoo.cfg拷贝到hbase的conf下
cp /opt/soft/zookeeper/zookeeper-3.4.13/conf/zoo.cfg /opt/soft/hbase/hbase-2.1.4/conf/
hbase-env.sh
# 进入目录
/opt/soft/hbase/hbase-2.1.4/conf/ # 备份
cp hbase-env.sh hbase-env.sh.bak # 进入编辑模式
vim hbase-env.sh # 配置:添加以下内容(注释掉:export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC")
export JAVA_HOME=/opt/soft/jdk/jdk1.8.0_191
export HBASE_OPTS="$HBASE_OPTS -Xmx8G -Xms8G -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70" export HBASE_HOME=/opt/soft/hbase/hbase-2.1.4/
export HBASE_CLASSPATH=/opt/soft/hbase/hbase-2.1.4/conf
export HBASE_LOG_DIR=/opt/soft/hbase/hbase-2.1.4/logs export HADOOP_HOME=/opt/soft/hadoop/hadoop-3.1.2 export HBASE_PID_DIR=/opt/data/hadoop/pids
export HBASE_MANAGES_ZK=false
hbase-site.xml
# 备份:
cp hbase-site.xml hbase-site.xml.bak # 进入编辑模式:
vim hbase-site.xml # 配置:<configuration>标签中添加 <property>
<name>hbase.rootdir</name>
<value>hdfs://hbase3:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>127.0.0.1:60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>127.0.0.1</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/soft/hbase/hbase-2.1.4/tmpdata</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.2</value>
</property>
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>180000</value>
</property>
环境变量 /etc/profile
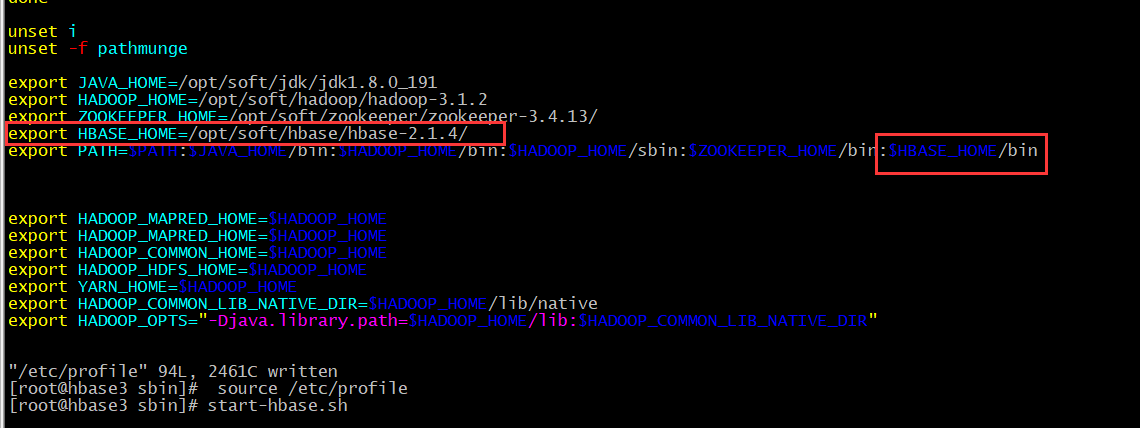
# 进入环境变量 vim /etc/profile # 继续添加
export HBASE_HOME=/opt/soft/hbase/hbase-2.1.4/
:$HBASE_HOME/bin # 使环境变量生效
source /etc/profile
【3】启动
start-hbase.sh
报错1:java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
启动时显示:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/soft/hadoop/hadoop-3.1.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/soft/hbase/hbase-2.1.4/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
# 查看日志
tailf hbase-root-master-hbase3.log -n 500 # 报错内容
2019-07-08 06:08:48,407 INFO [main] ipc.NettyRpcServer: Bind to /192.168.0.214:16000
2019-07-08 06:08:48,554 INFO [main] hfile.CacheConfig: Created cacheConfig: CacheConfig:disabled
2019-07-08 06:08:48,555 INFO [main] hfile.CacheConfig: Created cacheConfig: CacheConfig:disabled
2019-07-08 06:08:49,105 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:644)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:628)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:149)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2667)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:93)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2701)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2683)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:372)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:295)
at org.apache.hadoop.hbase.util.CommonFSUtils.getRootDir(CommonFSUtils.java:362)
at org.apache.hadoop.hbase.util.CommonFSUtils.isValidWALRootDir(CommonFSUtils.java:411)
at org.apache.hadoop.hbase.util.CommonFSUtils.getWALRootDir(CommonFSUtils.java:387)
at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:704)
at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:613)
at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:489)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3093)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:236)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:140)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:3111)
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 25 more
2019-07-08 06:08:49,118 ERROR [main] master.HMasterCommandLine: Master exiting
java.lang.RuntimeException: Failed construction of Master: class org.apache.hadoop.hbase.master.HMaster.
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3100)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:236)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:140)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:3111)
Caused by: java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:644)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:628)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:149)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2667)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:93)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2701)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2683)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:372)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:295)
at org.apache.hadoop.hbase.util.CommonFSUtils.getRootDir(CommonFSUtils.java:362)
at org.apache.hadoop.hbase.util.CommonFSUtils.isValidWALRootDir(CommonFSUtils.java:411)
at org.apache.hadoop.hbase.util.CommonFSUtils.getWALRootDir(CommonFSUtils.java:387)
at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:704)
at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:613)
at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:489)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:3093)
... 5 more
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 25 more
## 解决方案
# 找到 htrace-core 开头的jar
find / -name 'htrace-core-*'
# 将 htrace-core 开头的jar 复制到 /opt/soft/hbase/hbase-2.1.4/lib/目录下
cp /opt/soft/hadoop/hadoop-3.1.2/share/hadoop/yarn/timelineservice/lib/htrace-core-3.1.0-incubating.jar /opt/soft/hbase/hbase-2.1.4/lib/


【4】验证
192.168.0.214:16010进入web页面
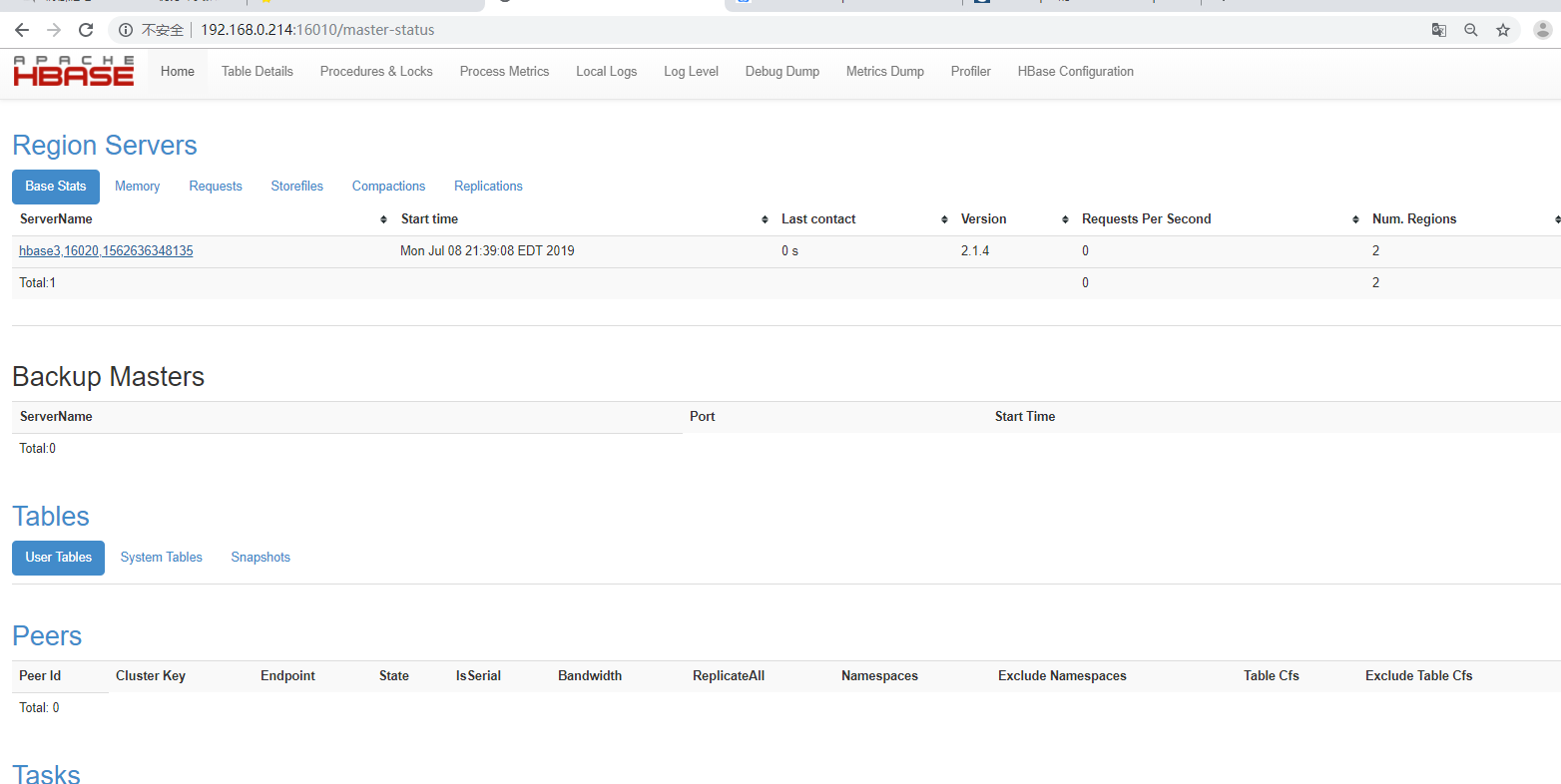
5、安装opentsdb
【1】解压
# 进入目录
cd /opt/soft/opentsdb # 解压
tar -zxvf opentsdb-2.4.0.tar.gz # 修改用户权限
chown -R root:root opentsdb-2.4.0

【2】编译
# 进入目录
cd opentsdb-2.4.0
# 编译:会生成一个build文件,但会报错
./build.sh
# 将third_party中的文件放入build文件夹中
cp -r third_party build
# 再次编译
./build.sh
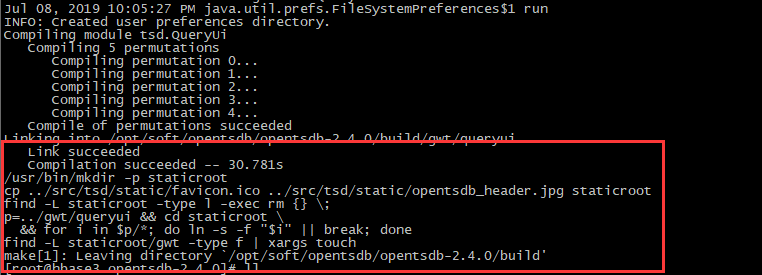
【3】配置
opentsdb.conf
# 将/opt/soft/opentsdb/opentsdb-2.4.0/src/opentsdb.conf复制到/opt/soft/opentsdb/opentsdb-2.4.0/build目录下
cp /opt/soft/opentsdb/opentsdb-2.4.0/src/opentsdb.conf /opt/soft/opentsdb/opentsdb-2.4.0/build/ # 进入编辑模式
vim opentsdb.conf
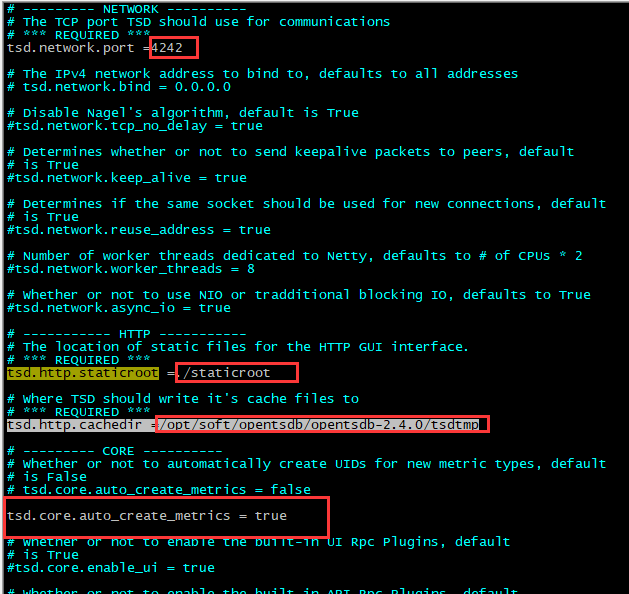
# 分别配置以下内容 tsd.network.port =4242
tsd.http.staticroot =./staticroot
tsd.http.cachedir =/opt/soft/opentsdb/opentsdb-2.4.0/tsdtmp
tsd.core.auto_create_metrics = true
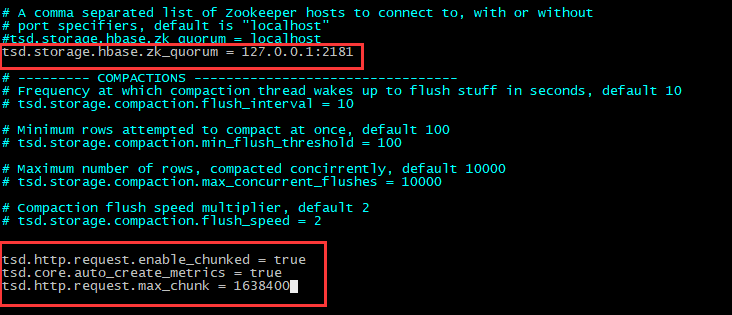
tsd.storage.hbase.zk_quorum = 127.0.0.1:2181
tsd.http.request.enable_chunked = true
tsd.core.auto_create_metrics = true
tsd.http.request.max_chunk = 1638400
【4】生成表
# 进入目录
cd /opt/soft/opentsdb/opentsdb-2.4.0/src
# 在hbase中生成表
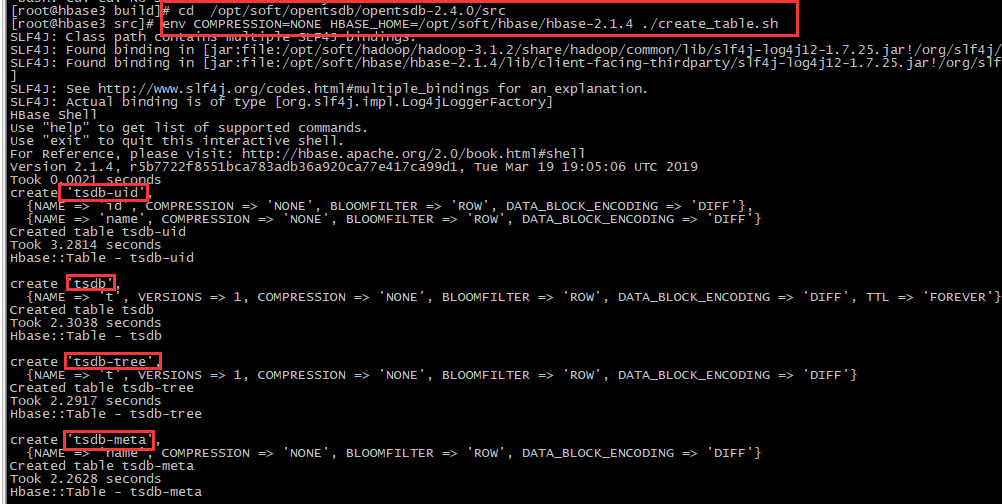
env COMPRESSION=NONE HBASE_HOME=/opt/soft/hbase/hbase-2.1.4 ./create_table.sh ## 验证
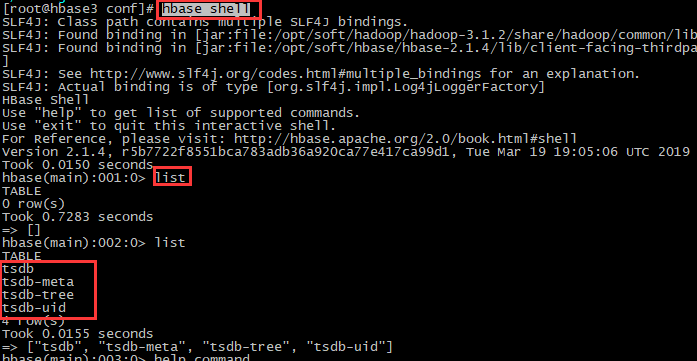
#1、hbase验证: 进入hbase的shell命令:更多habse shell命令参考https://www.cnblogs.com/i80386/p/4105423.html
hbase shell
# 查看所有表:opentsdb在hbase中会生成4个表(tsdb, tsdb-meta, tsdb-tree, tsdb-uid),其中tsdb这个表最重要,数据迁移时,备份还原此表即可
list
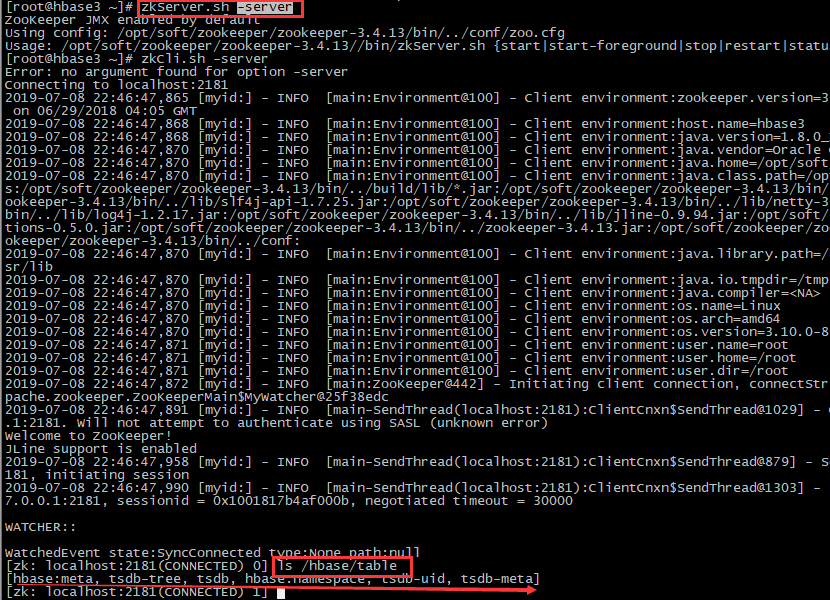
#2、zookeeper验证:进入zkCli.sh客户端,相关命令指南参考https://www.e-learn.cn/content/linux/835320
zkCli.sh -server
# 查看hbase相关表
ls /hbase/table
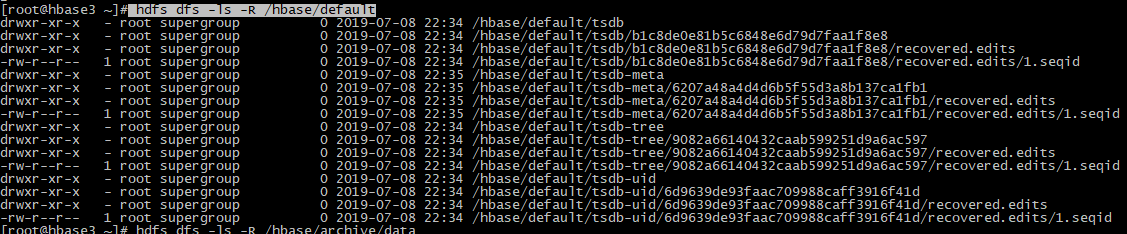
#3、hadoop验证:hbas相关数据在 /hbase/default目录下,其他相关命令指南参考https://blog.csdn.net/m0_38003171/article/details/79086780
hdfs dfs -ls -R /hbase/default
【5】启动
# 进入目录
cd /opt/soft/opentsdb/opentsdb-2.4.0/build/
# 启动
sh tsdb tsd &
## 验证
# 1、端口验证
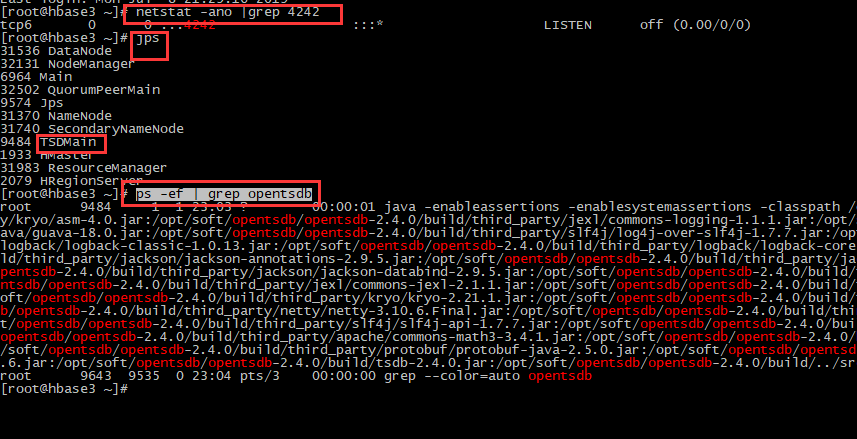
netstat -ano |grep 4242
# 2、进程验证
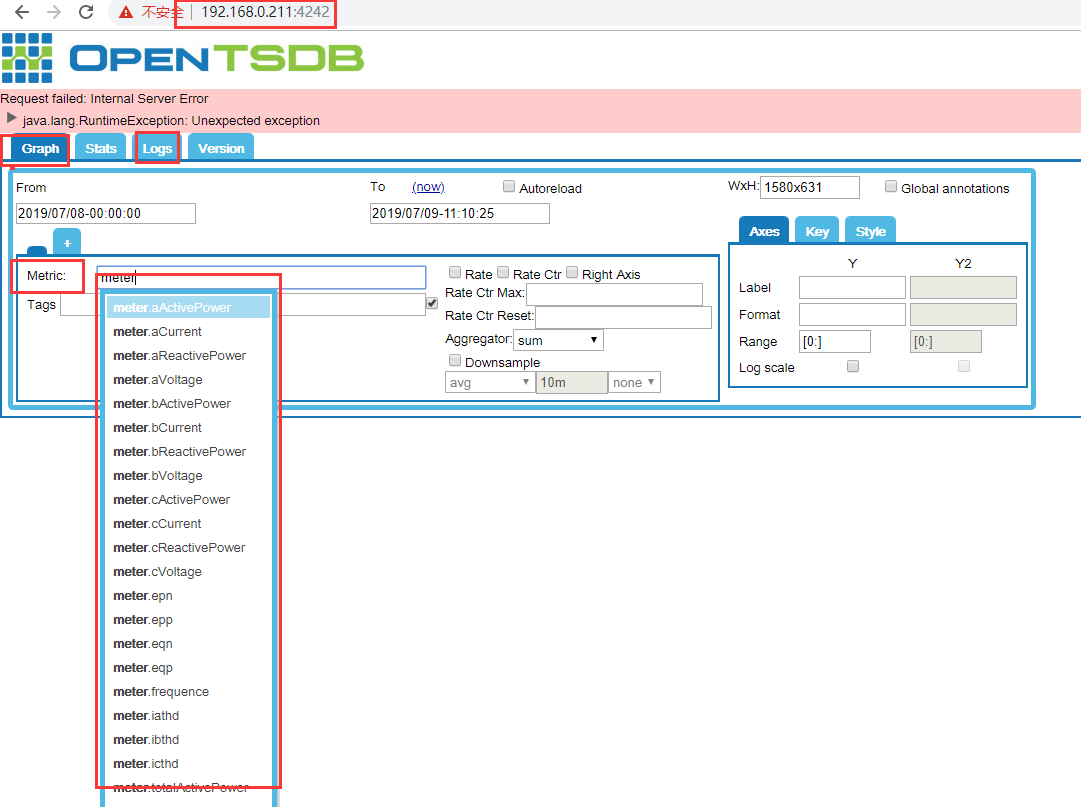
ps -ef | grep opentsdb # 3、web验证:如上面验证都正常,web无法访问,检查防火墙等 http://192.168.0.211:4242/

【6】写数据
#启动写入数据程序: /opt/soft/tsdb/property-0.0.1-SNAPSHOT.jar 程序为写入数据的程序
java -jar /opt/soft/tsdb/property-0.0.1-SNAPSHOT.jar &
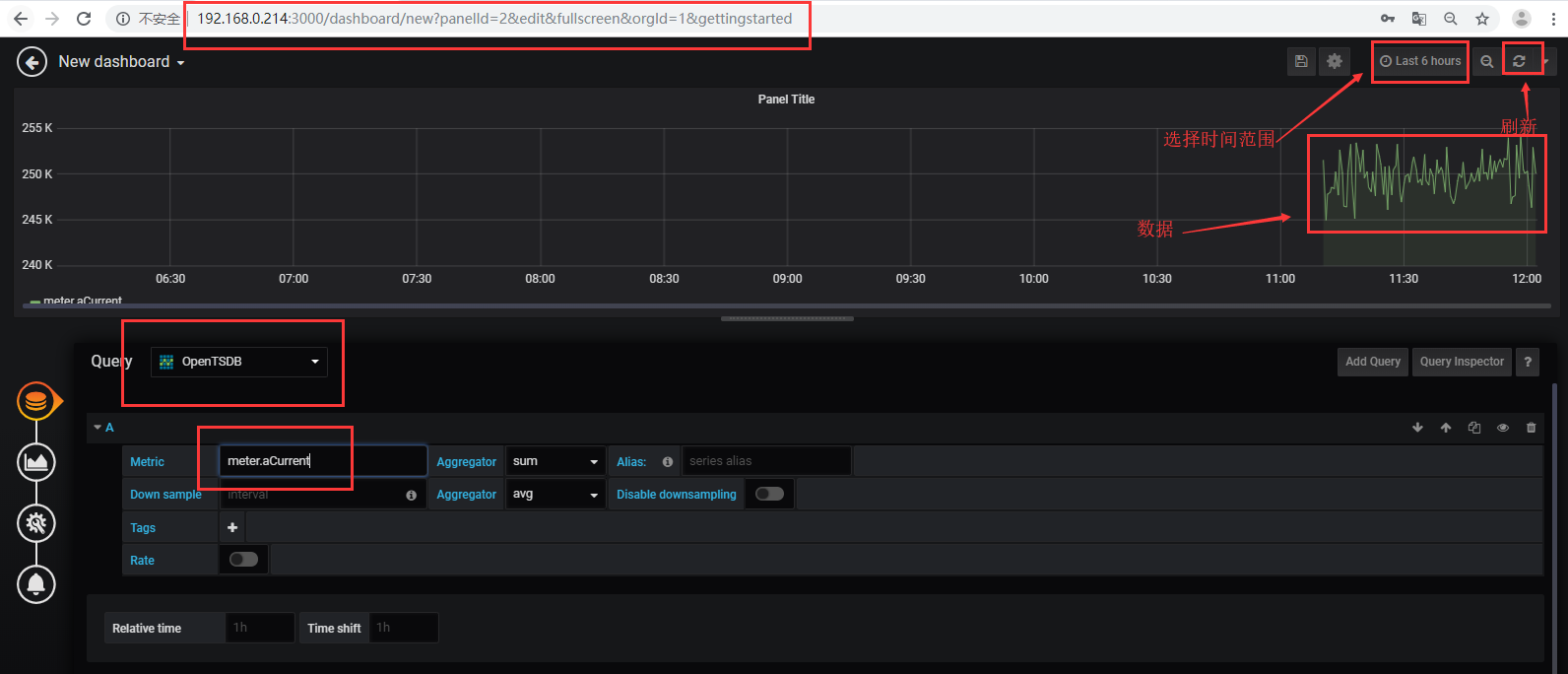
注:在web页面的Graph中,可以看到写入的指标(标签),则说明写入成功,如未写入成,可以在logs下看相关日志。想要看具体数据,可安装 grafana辅助查看。安装步骤参考下面。
6、安装grafana
参考:https://grafana.com/grafana/download?platform=linux
【1】安装
方法一:
# 创建目录
mkdir /opt/soft/grafana/ # 进入目录
cd /opt/soft/grafana/ # 下载安装包
wget https://dl.grafana.com/oss/release/grafana-6.2.5.linux-amd64.tar.gz # 解压
tar -zxvf grafana-6.2.5.linux-amd64.tar.gz
方法二:
yum install -y https://dl.grafana.com/oss/release/grafana-6.2.5-1.x86_64.rpm
【2】启动
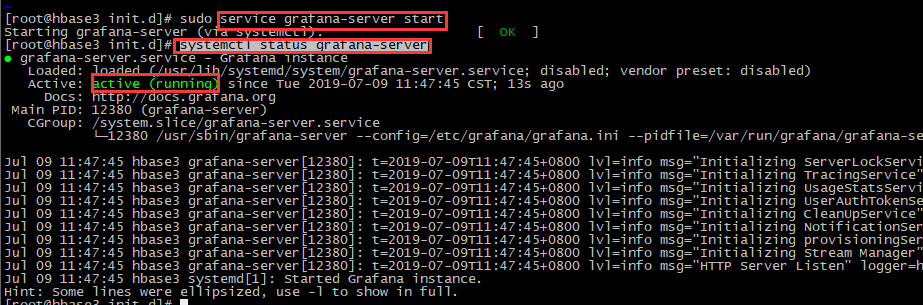
# 启动
service grafana-server start
## 验证 # 1、状态验证
systemctl status grafana-server # 2、web验证:默认端口为3000
192.168.0.214:3000

【3】查看数据
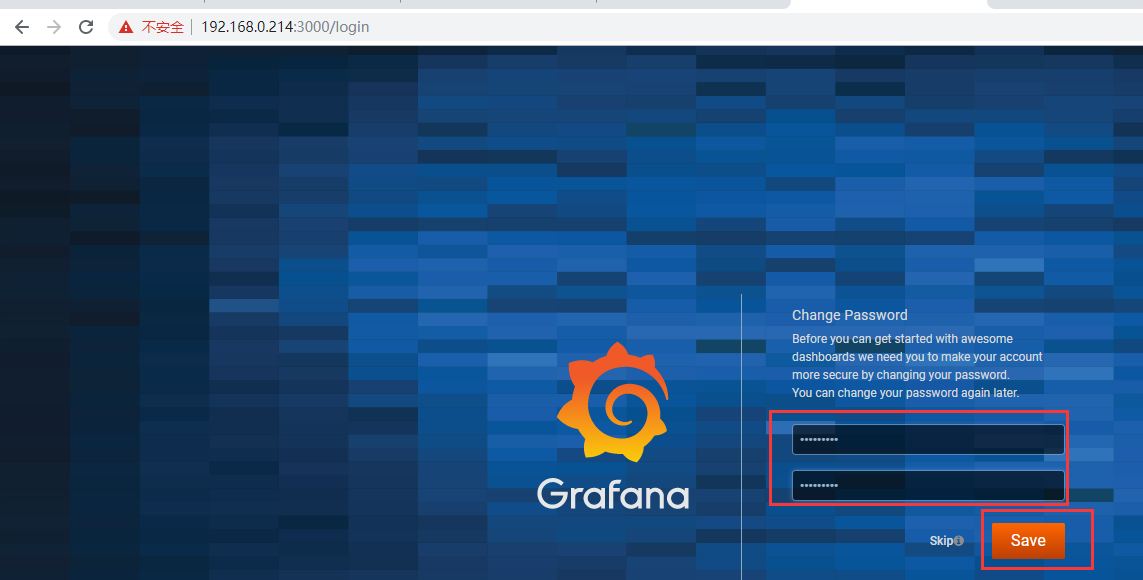
1、修改密码:
账户密码默认:admin admin,首次登陆要求修改密码,我这里改为Zxit@2018
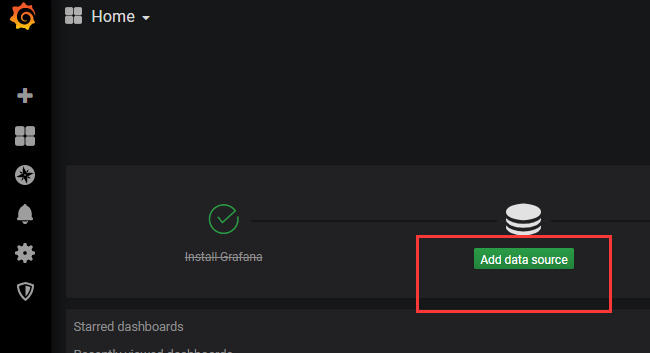
2、添加数据库
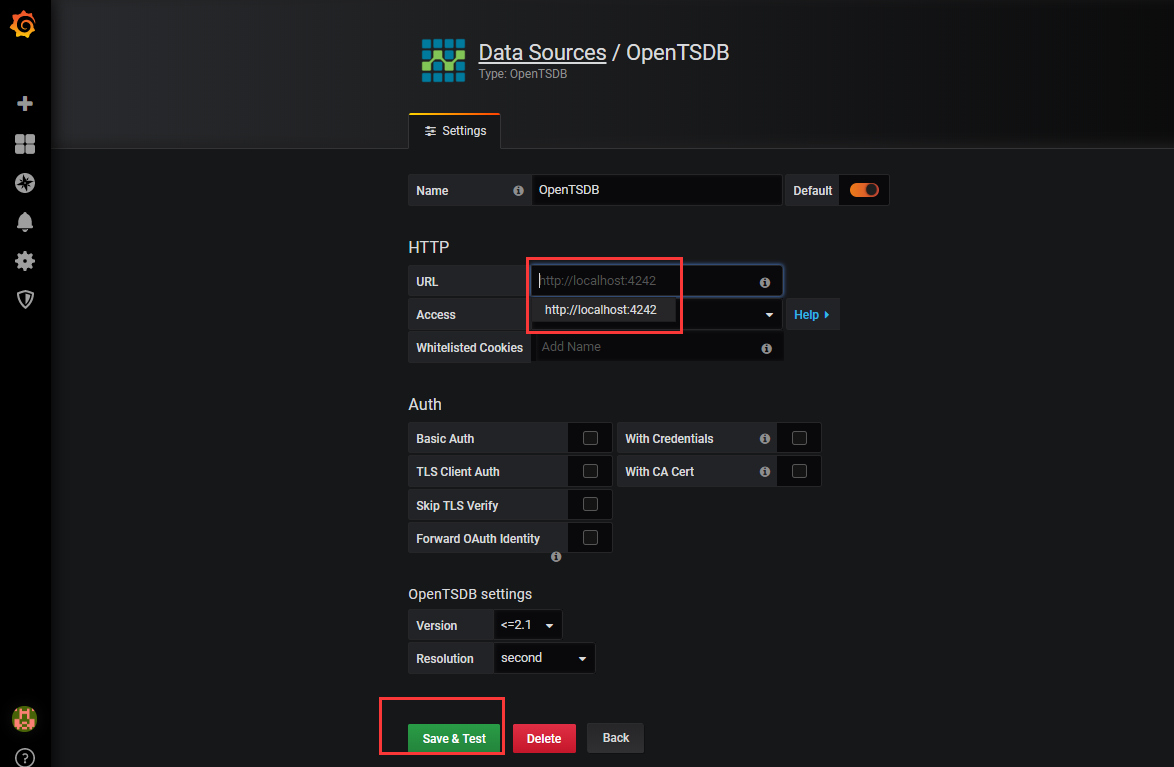
Add data source——》Data Sources——》OpenTSDB——》输入URL(http://localhost:4242)——》Save & Test——》back

3、查看数据
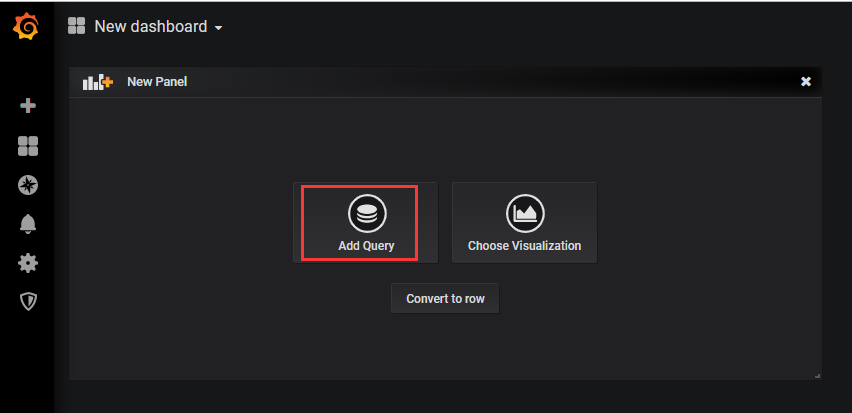
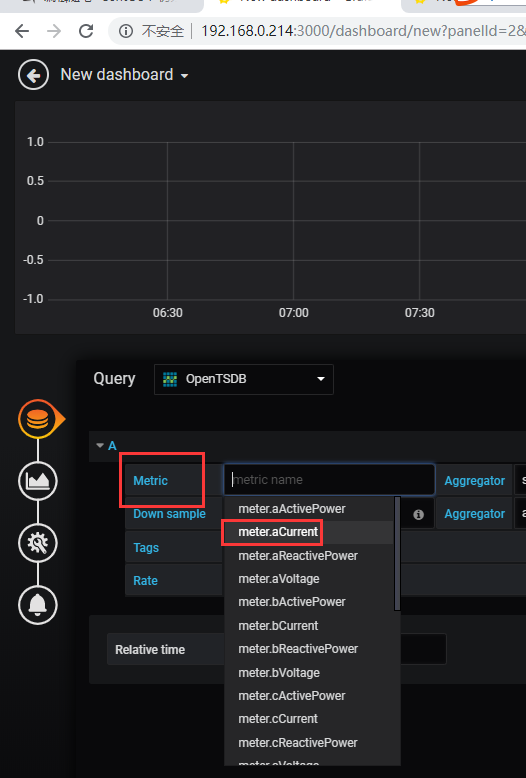
Home——》New dashboard——》Add Query——》选择数据库——》选择指标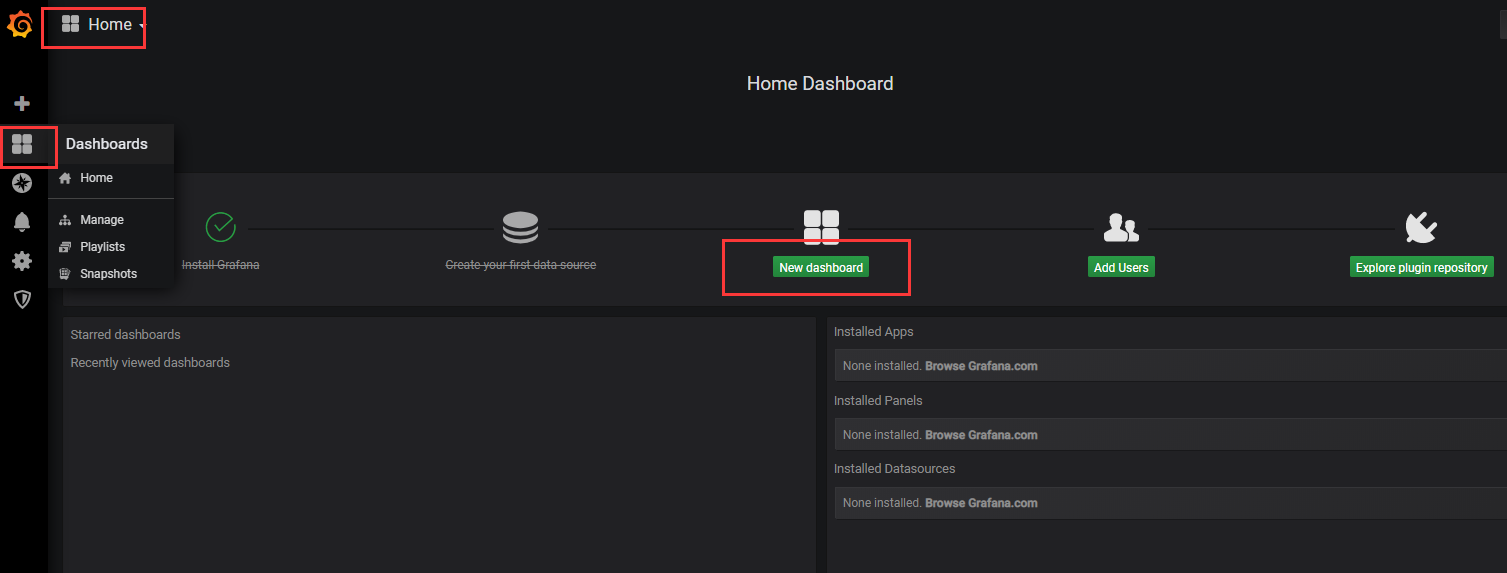

CentOS7.4伪分布式搭建 hadoop+zookeeper+hbase+opentsdb的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
- Hadoop简介与伪分布式搭建—DAY01
一. Hadoop的一些相关概念及思想 1.hadoop的核心组成: (1)hdfs分布式文件系统 (2)mapreduce 分布式批处理运算框架 (3)yarn 分布式资源调度系统 2.hadoo ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- hadoop+zookeeper+hbase分布式安装
前期服务器配置 修改/etc/hosts文件,添加以下信息(如果正常IP) 119.23.163.113 master 120.79.116.198 slave1 120.79.116.23 slav ...
- Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包)
Tags: Hadoop Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包) Centos7.5安装分布式Hadoop2.6.0+Hbase ...
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
随机推荐
- A + B Problem II(1002)
Problem Description I have a very simple problem for you. Given two integers A and B, your job is to ...
- React手稿之 React-Saga
Redux-Saga redux-saga 是一个用于管理应用程序副作用(例如异步获取数据,访问浏览器缓存等)的javascript库,它的目标是让副作用管理更容易,执行更高效,测试更简单,处理故障更 ...
- C++对象构造时,构造函数运行时并不知道VT的存在
class A {public: A() { init(); } virtual void init() { printf("A::init\n"); }}; class B : ...
- Gos: Armed Golang 💪
Gos: Armed Golang
- time模块的time方法、perf_counter方法和process_time方法的区别
1. time.time()方法 返回自纪元以来的秒数作为浮点数,但是时期的具体日期和闰秒的处理取决于使用的平台.比如:在Windows和大多数Unix系统上,纪元是1970年1月1日00:00:00 ...
- 2019-3-9-通过-frp-开启服务器打开本地的-ZeroNet-服务器外网访问
title author date CreateTime categories 通过 frp 开启服务器打开本地的 ZeroNet 服务器外网访问 lindexi 2019-03-09 11:47:4 ...
- 2018-11-19-visualStudio-无法登陆
title author date CreateTime categories visualStudio 无法登陆 lindexi 2018-11-19 15:24:15 +0800 2018-2-1 ...
- 团队中的 Git 实践
转载自:https://segmentfault.com/a/1190000004963641 本文首发于欧雷流.由于我会时不时对文章进行补充.修正和润色,为了保证所看到的是最新版本,请阅读原文. 在 ...
- PyQt5+qtdesigner开发环境配置
1.PyQt5安装 pip install PyQt5 2.qtdesigner安装 本来直接用pip install PyQt5-tools安装的,但是网速下的慢,中间还断了几次,在网上找到一个稳定 ...
- linux系统安装telnet服务
linux安装telnet 安装前准备工作 1.安装telnet服务需要三个软件包:telnet.telnet-server和xinetd包. telnet,telnet-sever,xinetd软件 ...