6-3 如何解析简单的XML文档

元素节点、元素树
>>> from xml.etree.ElementTree import parse
>>> help(parse)
Help on function parse in module xml.etree.ElementTree: parse(source, parser=None)
help(parse)
>>> f = open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\linker_log.xml')
>>>
>>> et = parse(f) #et ElementTree的对象
>>> help(et.getroot)
Help on method getroot in module xml.etree.ElementTree: getroot(self) method of xml.etree.ElementTree.ElementTree instance
help(et.getroot)
>>> root = et.getroot() #获取根节点 是一个元素对象 >>> root
<Element 'DOCUMENT' at 0x2e87f90>
#此节点的属性
>>> root.tag #查看标签
'DOCUMENT' >>> root.attrib #查看属性,是一个字典,本例中有值,无值时为空
{'gen_time': 'Fri Dec 01 16:04:26 2017 '} >>> root.text #查看节点文本,是一个回车无自符串
'\n'
>>> root.text.strip() #将节点文本对 空白字符串过滤
''
>>> root.text.strip()
''
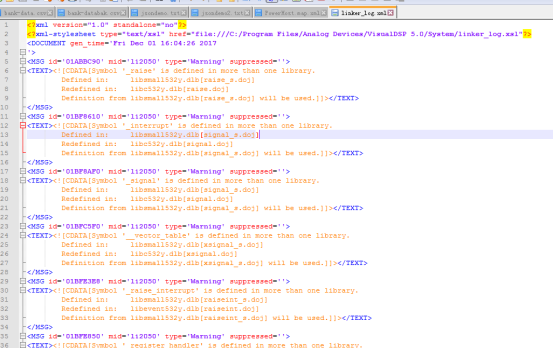
#root自身是一个可迭代对象,直接进行迭代遍历子元素
>>> for child in root:
print(child.get('id')) #child表示子元素 get()方法是获取某一属性。
输出结果
01ABBC90
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
01BFE850
01BFEAC8
01BFF128
01BFF2B0
01BFF4B8
01BFF730
01BFF960
01BFFB68
#通过find()、findall()、iterfind()只能找当前元素的直接子元素如本例中”root”只能找”MSG”而不能找”TEXT”
>>> root.find('MSG') #find()找到第一个碰到的元素
<Element 'MSG' at 0x2e87fd0>
>>> root.find('MSG')
<Element 'MSG' at 0x2e87fd0>
>>> root.findall('MSG') #find()找到所有的元素
[<Element 'MSG' at 0x2e87fd0>, <Element 'MSG' at 0x2e9f0d0>, <Element 'MSG' at 0x2e9f170>, <Element 'MSG' at 0x2e9f210>, <Element 'MSG' at 0x2e9f2b0>, <Element 'MSG' at 0x2e9f350>, <Element 'MSG' at 0x2e9f3f0>, <Element 'MSG' at 0x2e9f490>, <Element 'MSG' at 0x2e9f530>, <Element 'MSG' at 0x2e9f5d0>,
>>> root.find('TEXT') #“TEXT”是”MSG”的子元素,所以root直接find()找不到
>>>
>>> msg = root.find('MSG')
>>> msg.find('TEXT')
<Element 'TEXT' at 0x2e9f090>
#iterfind() 生成可迭代对表
>>> iterMsg = root.iterfind('MSG')
>>> for i in xrange(5):
x = iterMsg.next()
print x.get('id')
输出
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
01BFE850
>>> iterMsg = root.iterfind('MSG')
>>> i = 0
>>> for x in iterMsg:
print(x.get('id'))
i+=1
if(i ==5):
break
输出结果:
01ABBC90
01BF8610
01BF8AF0
01BFC5F0
01BFE3E8
#iter()可以迭代出所有元素的节点
>>> root.iter()
<generator object iter at 0x02ED3CD8>

#递归查找某一元素
>>> list(root.iter('TEXT'))

三、查找高级用法
1、“*”查找所有的节点
>>> root.findall('MSG/*') #查找MSG下的所有子节点,注意只能找其子节点而不能找其孙子节点

2、“.//”无论哪个层次下都能找到节点
>>> root.find('.//TEXT') #能找到
<Element 'TEXT' at 0x2e9f090>
>>> root.find('TEXT') #不能找到
>>>
3、“..”找到父层次的节点
>>> root.find('.//TEXT/..')
<Element 'MSG' at 0x2e87fd0>
4、“@”包含某一属性
>>> root.find('MSG[@name]') #没有包含name属性的
>>> root.find('MSG[@Type]') #没有包含Type属性的
>>> root.find('MSG[@type]') #存在包含type属性的,并返回
<Element 'MSG' at 0x2e87fd0>
5、属性等于特定值
>>> root.find('MSG[@id="01BFE3E8"]') #注意参数里的=号后面的字符串需要带引号
<Element 'MSG' at 0x2e9f2b0>
6、指定序号
>>> root.find("MSG[2]") #找第二个
<Element 'MSG' at 0x2e9f0d0>
>>> root.find("MSG[last()]") #找最后一个
<Element 'MSG' at 0x2ecdef0>
>>> root.find("MSG[last()-1]") #找倒数第二个
<Element 'MSG' at 0x2ecde30>
6-3 如何解析简单的XML文档的更多相关文章
- SAX解析和生成XML文档
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本人声明.否则将追究法律责任. 作者: 永恒の_☆ 地址: http://blog.csdn.net/chenghui031 ...
- 使用dom解析器对xml文档内容进行增删查改
直接添代码: XML文档名称(one.xml) <?xml version="1.0" encoding="UTF-8" standalone=" ...
- 用python批量生成简单的xml文档
最近生成训练数据时,给一批无效的背景图片生成对应的xml文档,我用python写了一个简单的批量生成xml文档的demo,遇见了意外的小问题,记录一下. 报错问题为:ImportError: No m ...
- Dom4j解析语音数据XML文档(注意ArrayList多次添加对象,会导致覆盖之前的对象)
今天做的一个用dom4j解析声音文本的xml文档时,我用ArrayList来存储每一个Item的信息,要注意ArrayList多次添加对象,会导致覆盖之前的对象:解决方案是在最后将对象添加入Array ...
- WSDL 文档-一个简单的 XML 文档
WSDL 文档是利用这些主要的元素来描述某个 web service 的: <portType>-web service 执行的操作 <message>-web service ...
- MVC模式简单的Xml文档解析加Vue渲染
前端代码: <script src="~/Js/jquery-3.3.1.min.js"></script> <script src="~/ ...
- Java DOM解析器 - 修改XML文档
这是我们需要修改的输入XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" encoding="UTF-8&q ...
- Java DOM解析器 - 查询XML文档
这是需要我们查询的输入XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?xml version="1.0"?> ...
- iOS网络编程笔记——XML文档解析
今天利用多余时间研究了一下XML文档解析,虽然现在移动端使用的数据格式基本为JSON格式,但是XML格式毕竟多年来一直在各种计算机语言之间使用,是一种老牌的经典的灵活的数据交换格式.所以我认为还是很有 ...
随机推荐
- linux-PXE-12
以DHCP+DNS模式管理服务器IP地址和主机名.服务器上架前,以其MAC地址为依据,在DHCP中配置主机保留并分配主机名.DHCP结合TFTP提供的PXE服务,提供PXE引导Linux内核和启动镜像 ...
- 【webpack4】webpack4配置需要注意的问题
需要注意的知识: 要全局安装webpack以及webpack cli,否则不能使用webpack指令 npm install webpack -g npm install webpack-cli -g ...
- POJ 3180 牛围着池塘跳舞 强连通分量裸题
题意:一群牛被有向的绳子拴起来,如果有一些牛(>=2)的绳子是同向的,他们就能跳跃.求能够跳跃的组数. #include <iostream> #include <cstdio ...
- R-CNN常见问题
可以不进行特定样本下的微调吗?可以直接采用AlexNet CNN网络的特征进行SVM训练吗? 不针对特定任务进行微调,而将CNN当成特征提取器,pool5层得到的特征是基础特征,类似于HOG.SIFT ...
- (74)c++再回顾一继承和派生
一:继承和派生 0.默认构造函数即不带参数的构造函数或者是系统自动生成的构造函数.每一个类的构造函数可以有多个,但是析构函数只能有一个. 1.采用公用public继承方式,则基类的公有成员变量和成员函 ...
- [BZOJ4011][HNOI2015]落忆枫音:拓扑排序+容斥原理
分析 又是一个有故事的题目背景.作为玩过原作的人,看题目背景都快看哭了ToT.强烈安利本境系列,话说SP-time的新作要咕到什么时候啊. 好像扯远了嘛不管了. 一句话题意就是求一个DAG再加上一条有 ...
- 使用指定MTU到特定IP
ping指令使用指定MTU到特定IP 命令如下 45.58.185.18 这里MTU为1300
- HTTP协议初步认识
1.基本概念: HTML:HyperText Transfer Protocol,中文名:超文本传输协议,基于请求/响应模式,基于TCP/IP协议,是一种,无连接,无状态协议: 2.HTTP传输过程: ...
- leetcode-mid-math -171. Excel Sheet Column Number
mycode 90.39% class Solution(object): def titleToNumber(self, s): """ :type s: str ...
- Mysql 创建函数出现This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary mys ...