python爬取b站排行榜
爬取b站排行榜并存到mysql中
目的
b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设。首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化。
网站的结构
目标网站:bilibili排行榜
网页的层次
- 首先要确定要提取的信息,也就是标题、播放量、作者up主、评分、播放量和评论量

- 在网页源代码中找到要找的信息
每个网页中大概有多条这样的rank-item项目,要提取的信息就包含其中
<li class="rank-item"><div class="num">3</div><div class="content"><div class="img"><a href="//bangumi.bilibili.com/anime/28016" target="_blank"><div class="lazy-img cover"><img alt="女高中生的虚度日常" src=""></div></a><!----></div><div class="info"><a href="//bangumi.bilibili.com/anime/28016" target="_blank"class="title">女高中生的虚度日常</a><div class="bangumi-info">全12话</div><div class="detail"><span class="data-box"><i class="b-icon play"></i>3491.1万</span><span class="data-box"><i class="b-icon view"></i>74.3万</span><span class="data-box"><i class="fav"></i>176.4万</span></div><div class="pts"><div>2218000</div>综合得分</div></div></div></li>
1.名称在title类的a标签下
2.播放量、评论数、和up主在data-box类的span标签下
3.综合评分在pts类的div标签下
对应解析其的代码
def getPage(url):#爬取单个页面,核心代码spider=Spider(url)spider.setSoup()itemList=spider.findTagByAttrs('li','rank-item')pageContentList=[]for item in itemList:pageContentItem=[]for title in item.find_all('a','title'):pageContentItem.append(title.string)# print(title.string)for playnum in item.find_all('span','data-box'):pattern=r">([^<]+)<"n=re.findall(pattern,playnum.__str__())[0]pageContentItem.append(n)# print(n)# print(item.find_all('div','pts')[0].div.string)pageContentItem.append(item.find_all('div','pts')[0].div.string)pageContentList.append(pageContentItem)return pageContentList
网站的层次
通过观察连接参数的变化
https://www.bilibili.com/ranking/all/0/0/3
以这个链接为例,通过实验,该网页链接的参数代表各种意义,ranking代表排行,all代表是否是全站还是原创,第一个参数0代表,各个分区,第二个参数0代表了全部投稿还是近期投稿,第三个参数3代表了是三日内投递的,根据实验规律,得到了生成连接的代码,但是只有全站榜和原创榜支持这个规律,其他的暂时没爬
def getURLFormBilibili():# 获取各种各样排行的榜单的信息date={1:'日排行',3:'三日排行',7:'周排行',30:'月排行'}areatype={0:'全站',1:'动画',168:'国漫相关',3:'音乐',129:'舞蹈',4:'游戏',36:'科技',188:'数码',160:'生活',119:'鬼畜',155:'时尚',5:'娱乐',181:'影视'}ranktype={'all':'全站','origin':'原创'}submit={'0':'全部投稿','1':'近期投稿'}urlDict={}#存放相应url的字典for ranktypeItem in ranktype.keys():for areatypeItem in areatype.keys():for submitItem in submit.keys():for dateTypeItem in date.keys():title=ranktype[ranktypeItem]+'_'+areatype[areatypeItem]+'_'+submit[submitItem]+'_'+date[dateTypeItem]destinaTionUrl='https://www.bilibili.com/ranking/{}/{}/{}/{}'.format(ranktypeItem,areatypeItem,submitItem,dateTypeItem)urlDict[title]=destinaTionUrlreturn urlDict
保存到mysql数据库
这里使用了pymysql这个库,安装使用pip就好了,就不再赘述,为了方便我把它写成了一个类
class MysqlConnect:#数据库的连接类def __init__(self):passdef getConnect(self):db=coon = pymysql.connect(host = 'localhost',user = 'root',passwd = '你的密码',port = 3306,db = 'bilibilirank',charset = 'utf8'#port必须写int类型#charset必须写utf8,不能写utf-8)return dbdef insertInfo(self,sql):db=self.getConnect()cursor=db.cursor()try:cursor.execute(sql)db.commit()print("sucessed...")except:print("failed...")db.rollback()def queryOutCome(self,sql):# 获取数据库连接db = self.getConnect()# 使用cursor() 方法创建一个游标对象 cursorcursor = db.cursor()try:# 执行sql语句cursor.execute(sql)result = cursor.fetchone()except: #方法二:采用traceback模块查看异常#输出异常信息traceback.print_exc()# 如果发生异常,则回滚db.rollback()finally:# 最终关闭数据库连接db.close()return resultdef getCreateTableSql(self,tableName):#获取创建表的sql语句sql='''create table `{}` (id int(11) auto_increment primary key,title char(100) NOT NULL UNIQUE,playnum char(100) NOT NULL,commentnum char(100) NOT NULL,author char(100) NOT NULL,score char(100) NOT NULL)ENGINE=innodb DEFAULT CHARSET=utf8;'''.format(tableName)return sqldef getInsertToTableSql(self,tableName,title,playnum,commentnum,author,score):sql='''insert into `{}` values(null,'{}','{}','{}','{}','{}');'''.format(tableName,title,playnum,commentnum,author,score)return sqldef createTable(self,tableName,sql):db=self.getConnect()cursor=db.cursor()cursor.execute("drop table if exists %s" %(tableName))cursor.execute(sql)db.close()
爬取数据
按照页面逐个爬取保存到数据库
if __name__ == "__main__":#开始爬取数据urlDict=getURLFormBilibili()#获取对应的URL信息mysqlconnect=MysqlConnect()#用于连接数据库for urlName in urlDict:print("正在处理"+urlName+"页面...")url=urlDict[urlName]tableName=urlNamecreatesql=mysqlconnect.getCreateTableSql(tableName)mysqlconnect.createTable(tableName,createsql)pageList=getPage(url)for contentItem in pageList:insertsql=mysqlconnect.getInsertToTableSql(tableName,contentItem[0],contentItem[1],contentItem[2],contentItem[3],contentItem[4])print(insertsql)mysqlconnect.insertInfo(insertsql)
结果

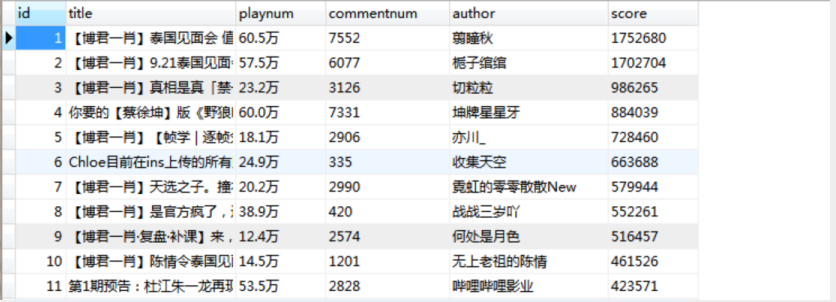
源代码
import requestsimport refrom bs4 import BeautifulSoupimport pymysqlimport tracebackclass Spider:#常用的爬取方法的简单封装def __init__(self,url):self.url=urldef getHTML(self):#获取html的对应代码headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.103 Safari/537.36'}try:response=requests.get(url=self.url,headers=headers,timeout=20)response.raise_for_status()response.encoding=response.apparent_encodingreturn response.textexcept:return "网页访问失败"def setSoup(self):#获取soup对象html=self.getHTML()self.soup=BeautifulSoup(html,'html.parser')def findTag(self,tagName):#按照标签名查找标签return self.soup.find_all(tagName)def findTagByAttrs(self,tagName,attrs):return self.soup.find_all(tagName,attrs)def getBeautifyHTML(self):return self.soup.prettify()def getPage(url):#爬取单个页面,核心代码spider=Spider(url)spider.setSoup()itemList=spider.findTagByAttrs('li','rank-item')pageContentList=[]for item in itemList:pageContentItem=[]for title in item.find_all('a','title'):pageContentItem.append(title.string)# print(title.string)for playnum in item.find_all('span','data-box'):pattern=r">([^<]+)<"n=re.findall(pattern,playnum.__str__())[0]pageContentItem.append(n)# print(n)# print(item.find_all('div','pts')[0].div.string)pageContentItem.append(item.find_all('div','pts')[0].div.string)pageContentList.append(pageContentItem)return pageContentListdef getURLFormBilibili():# 获取各种各样排行的榜单的信息date={1:'日排行',3:'三日排行',7:'周排行',30:'月排行'}areatype={0:'全站',1:'动画',168:'国漫相关',3:'音乐',129:'舞蹈',4:'游戏',36:'科技',188:'数码',160:'生活',119:'鬼畜',155:'时尚',5:'娱乐',181:'影视'}ranktype={'all':'全站','origin':'原创'}submit={'0':'全部投稿','1':'近期投稿'}urlDict={}#存放相应url的字典for ranktypeItem in ranktype.keys():for areatypeItem in areatype.keys():for submitItem in submit.keys():for dateTypeItem in date.keys():title=ranktype[ranktypeItem]+'_'+areatype[areatypeItem]+'_'+submit[submitItem]+'_'+date[dateTypeItem]destinaTionUrl='https://www.bilibili.com/ranking/{}/{}/{}/{}'.format(ranktypeItem,areatypeItem,submitItem,dateTypeItem)urlDict[title]=destinaTionUrlreturn urlDictclass MysqlConnect:#数据库的连接类def __init__(self):passdef getConnect(self):db=coon = pymysql.connect(host = 'localhost',user = 'root',passwd = '你的密码',port = 3306,db = 'bilibilirank',charset = 'utf8'#port必须写int类型#charset必须写utf8,不能写utf-8)return dbdef insertInfo(self,sql):db=self.getConnect()cursor=db.cursor()try:cursor.execute(sql)db.commit()print("sucessed...")except:print("failed...")db.rollback()def queryOutCome(self,sql):# 获取数据库连接db = self.getConnect()# 使用cursor() 方法创建一个游标对象 cursorcursor = db.cursor()try:# 执行sql语句cursor.execute(sql)result = cursor.fetchone()except: #方法二:采用traceback模块查看异常#输出异常信息traceback.print_exc()# 如果发生异常,则回滚db.rollback()finally:# 最终关闭数据库连接db.close()return resultdef getCreateTableSql(self,tableName):#获取创建表的sql语句sql='''create table `{}` (id int(11) auto_increment primary key,title char(100) NOT NULL UNIQUE,playnum char(100) NOT NULL,commentnum char(100) NOT NULL,author char(100) NOT NULL,score char(100) NOT NULL)ENGINE=innodb DEFAULT CHARSET=utf8;'''.format(tableName)return sqldef getInsertToTableSql(self,tableName,title,playnum,commentnum,author,score):sql='''insert into `{}` values(null,'{}','{}','{}','{}','{}');'''.format(tableName,title,playnum,commentnum,author,score)return sqldef createTable(self,tableName,sql):db=self.getConnect()cursor=db.cursor()cursor.execute("drop table if exists %s" %(tableName))cursor.execute(sql)db.close()if __name__ == "__main__":#开始爬取数据urlDict=getURLFormBilibili()#获取对应的URL信息mysqlconnect=MysqlConnect()#用于连接数据库for urlName in urlDict:print("正在处理"+urlName+"页面...")url=urlDict[urlName]tableName=urlNamecreatesql=mysqlconnect.getCreateTableSql(tableName)mysqlconnect.createTable(tableName,createsql)pageList=getPage(url)for contentItem in pageList:insertsql=mysqlconnect.getInsertToTableSql(tableName,contentItem[0],contentItem[1],contentItem[2],contentItem[3],contentItem[4])print(insertsql)mysqlconnect.insertInfo(insertsql)
python爬取b站排行榜的更多相关文章
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- python爬取某站新闻,并分析最近新闻关键词
在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错: 一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任 ...
- 用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下 设计思路 首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- Python爬取B站耗子尾汁、不讲武德出处的视频弹幕
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前言 耗子喂汁是什么意思什么梗呢?可能很多人不知道,这个梗是出自马保国,经常上网的人可能听说过这个 ...
- 使用python爬取P站图片
刚开学时有一段时间周末没事,于是经常在P站的特辑里收图,但是P站加载图片的速度比较感人,觉得自己身为计算机专业,怎么可以做一张张图慢慢下这么low的事,而且这样效率的确也太低了,于是就想写个程序来帮我 ...
随机推荐
- react在视频中截图,保存为base64位
wq:之前看了网上很多教程,有点模糊,但是最后还是搞了出来 1 不要将视频放到canvas上面! 之前一直将video重新画到canvas上面,然后再次将第一个canvas放到第二个canvas上 ...
- oracle基本语句(第五章、数据库逻辑存储结构管理)
1.使用SYS用户以SYSDBA身份登录到SQL Plus,使用视图V$TABLESPACE查看表空间信息 SELECT * FROM V$TABLESPACE; 2.查看视图DBA_TABLESPA ...
- 【NOIP2016提高A组模拟8.23】函数
题目 分析 观察这个是式子\(\sum_{d|n}f(n)=n\), 发现其实函数\(f()\)就是欧拉函数\(φ()\)(见http://blog.csdn.net/chen1352/article ...
- 【leetcode】1185. Day of the Week
题目如下: Given a date, return the corresponding day of the week for that date. The input is given as th ...
- linux RPM(红帽软件包管理器)和Yum软件仓库中常见的命令
RPM(红帽软件包管理器)常用命令 安装软件:rpm -ivh filename.rpm 升级软件:rpm -Uvh filename.rpm 卸载软件:rpm -e filename.rpm 查询软 ...
- ClustrixDB安装配置
前提条件 在安装ClustrixDB之前,需要: ClustrixDB安装程序和许可证密钥. 运行CentOS或RHEL 7.4的服务器(本地或云中). 具有root或sudo特权来安装Clustri ...
- tomcat7 与tomcat8 使用tomcat dbcp pool注意对应类变化
tomcat dbcp pool在tomcat 7 和tomcat8下的jar包有变化,相应包名也发生变化,对应类名有相应变化! tomcat的lib文件夹下会有jar包tomcat-dbcp.jar ...
- Egret Tween
最近开始接触Egret,其实也就是为了写一些小的特效 1.egret.Tween.get() ,激活一个对象,对其添加 Tween 动画 2.to() ,将指定对象的属性修改为指定值 egret.Tw ...
- Python实现人脸识别
识别图片 #coding=utf-8 import requests,cv2 import re import os import bs4 #2.读取图片 filename = 'E:/Python/ ...
- leetcode 234 回文链表 Palindrome Linked List
要求用O(n)时间,和O(1)空间,因此思路是用本身链表进行判断,既然考虑回文,本方法思想是先遍历一次求链表长度,然后翻转前半部分链表:然后同时对前半部分链表和后半部分链表遍历,来判断对应节点的值是否 ...