[大数据] hadoop高可用(HA)部署(未完)
一、HA部署架构
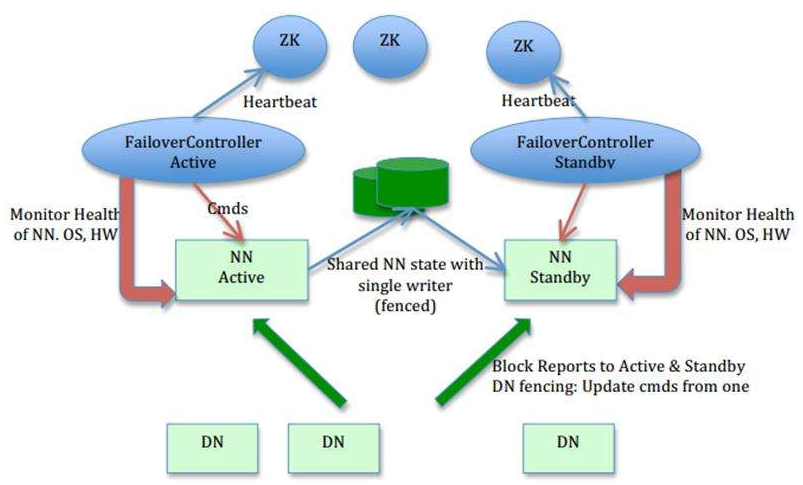
如上图所示,我们可以将其分为三个部分:
1.NN和DN组成Hadoop业务组件。浅绿色部分。
2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存储(元数据存储)。
3.蓝色部分为Zookeeper,提供自动NN切换。
在 hadoop全分布式安装 中,我们已经部署了一套全分布式的Hadoop集群,包含1个NN和3个DN。
我们在全分布式的基础上将其中一个DN(安装SNN的节点)变为SBNN(备用NN)。
在全分布式中,存在一个SNN(secondary Node),那是Hadoop 1.x中采用的技术。在hadoop 2.x中,使用SBNN(standby Namenode)来完成SNN的功能,并提供HA 备用。
各部分组件工作原理介绍:
1.NN之间的元数据同步:
1)多个NN之间要同步的元数据分为两种,静态数据和动态数据。静态数据指HDFS上存放文件的权限、偏移量等信息,动态数据指这些文件存放的块的信息。
2)静态信息由NN直接持久化到磁盘,而动态数据是由DN向上汇报的。
3)动态数据的同步,无需多个NN之间传递数据,只需要DN同时向多个NN汇报数据即可。
4)静态数据则可以通过JN集群或NFS(已淘汰,存在单点故障)来实现。
2.Journal Node:
1)JN节点组成的集群,用于存放多个NN之间共享的元数据,功能类似于我们在全分布式部署时指定的/var/hadoop文件夹。
2)当主NN挂掉时,SBNN可以从JN集群中同步元数据。JN集群提供高可用,保证元数据的安全性和一致性。
3)JN集群的节点数量一般为单数,使用过半机制,例如3个节点的集群可以允许一台宕机,5个节点的集群可以允许两台宕机。如果是偶数(一般不用偶数),6个节点的集群,也只能允许两台宕机。
3.Zookeeper:
1)每一个NN上存在一个Failover Controller进程(简称ZKFC),即图中蓝色椭圆部分。
2)Zookeeper提供选举机制,所有的NN通过ZKFC进程向Zookeeper申请成为主节点,即注册,谁注册成功,谁就是主节点,其余的为备用节点。
3)注册成功的NN会在Zookeeper上产生一个znode节点,节点之下是该NN的信息,我们可以把Zookeeper看成一个小型的数据库。
4)Zookeeper除了提供注册功能(register),还提供事件监控功能(event)。这里的事件是指NN是否出现故障,由处于NN节点上得ZKFC进程来监听,ZKFC提供健康监控和选举功能。当ZKFC发现NN出现故障,则马山通知Zeekeeper。
5)Zookeeper知道主节点挂掉后,则会通知SBNN节点(其实是SBNN委托Zookeeper来监控主节点)。
6)SBNN收到通知后,会将自己的级别从备提升为Active(这里实际上是一个由Zookeeper发起的回调,回调的是客户端的函数,这里的客户端就是ZKFC)。
7)当SBNN变成ANN后,他会强制性的将前任ANN的Active状态进行变更。避免形成Split brain(脑裂)情况出现。
二、部署时要注意的点(写在前面)
1.由于两个NN之间要互相操作(例如SBNN在NN出现问题的使用要操作NN,杀掉相应进程),所以两台NN之间需要相互做免秘钥登录。
2.在配置好Hadoop后,格式化HDFS之前,要先启动 Journal Nodes。
三、节点规划
我们对节点所要担任的角色进行规划:
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
| Node01 | * | * | * | |||
| Node02 | * | * | * | * | * | |
| Node03 | * | * | * | |||
| Node04 | * | * |
1)NN-1和NN-2表示两个NameNode。
2)ZK集群有3个节点,分别在node02-04。
3)ZKFC一定是对应NameNode的。
4)JNN集群的三个节点分别在node01-03。
四、Hadoop HA配置流程及解释
参照官方文档:
即基于QJM的HA环境搭建,另一种方式基于NFS(不推荐)。
1.NN之间免秘钥操作
# node01上操作
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node02
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node03
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node04
# node02上操作
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node01
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node03
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node04
2.配置hdfs-site.xml
参照官方文档中 Deployment 小节的 Configuration details部分:
先在hdfs-site.xml中为HA的多个NN节点定义一个逻辑名称,来代表这一组NN,这里叫mycluster:
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
然后定义这里HA有哪些NN节点:
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
定义nn1和nn2的确切节点名(这里的nn1要与前面对应,可修改为自己想要的名称):
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
注意:这里的端口号默认是8020,在前面我们部署的单节点情况下,使用的是9000端口。
定义http的访问端口,即提供WEB访问服务的端口号(这里同单节点一样,使用50070端口):
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
定义JNN节点的edits.dir:
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
注意:这里的格式要正确,只需要修改JN所处的实际节点,端口是8485,最后的mycluster是我们的HA逻辑ID,但可以不与HA逻辑名相同,主要是用于区分多个HA集群共用一个JNN的情况。
指定NN进行故障转移时,使用的代理类(这里照着官方网站配就行):
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
定义SBNN在要接替前任ANN时,如何来隔离前任ANN(可能是登录前任ANN来杀掉进程),从而保证只有一个Active节点来写JNN,避免Split brain的发生:
这里采用ssh的方式来隔离:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
注意:这里使用的是私钥,需要将id_rsa的绝对路径配置进去。(秘钥有rsa和dsa两种,都可以)
定义JN的edits存放位置(前面配置的dfs.namenode.shared.edits.dir只是指定了JNN的节点位置):
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/ha/journalnode</value>
</property>
3.配置core-site.xml
在配置完hdfs-site.xml后,已经定义了逻辑名、包含节点、服务端口等信息。此时,要在core-site.xml中配置对应的信息。
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
注意:我们之前在部署单NN节点时,这里使用的是hdfs://node01:9000,这里需要修改成HA集群的逻辑ID。
定义数据的存储位置:
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/ha</value>
</property>
注意:将全分布式的/var/hadoop/full修改为/var/hadoop/ha;
4.启动JNN集群(重要)
修改完Hadoop的配置文件,在格式化HDFS之前,需要首先启动JNN集群,否则edits文件没有地方存储,则无法启动Hadoop。
[大数据] hadoop高可用(HA)部署(未完)的更多相关文章
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- hadoop高可用HA的配置
zk3 zk4 zk5 配置hadoop的HA大概可以分为以下几步: 配置zookpeer(namenode之间的通信要靠zk来实现) 配置hadoop的 hadoop-env.sh hdfs-sit ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
- hadoop在zookeeper上的高可用HA
(参考文章:https://www.linuxprobe.com/hadoop-high-available.html) 一.技术背景 影响HDFS集群不可用主要包括以下两种情况:一是NameNode ...
- hadoop学习笔记(七):hadoop2.x的高可用HA(high avaliable)和联邦F(Federation)
Hadoop介绍——HA与联邦 0.1682019.06.04 13:30:55字数 820阅读 138 Hadoop 1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题: –HDFS ...
- 使用kubeadm进行单master(single master)和高可用(HA)kubernetes集群部署
kubeadm部署k8s 使用kubeadm进行k8s的部署主要分为以下几个步骤: 环境预装: 主要安装docker.kubeadm等相关工具. 集群部署: 集群部署分为single master(单 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
随机推荐
- Asteroid Collision
We are given an array asteroids of integers representing asteroids in a row. For each asteroid, the ...
- python学习笔记四 (运算符重载和命名空间、类)
从以上代码中应该了解到: obj.attribute 查找的顺序: 从对象,类组成的树中,从下到上,从左到右到查找最近到attribute属性值,因为rec中存在name的属性,所以x.name可以 ...
- nginx反向代理_负载均衡
注意ip地址为: 虚拟机ip设置 TYPE="Ethernet"BOOTPROTO="static"NAME="enp0s3"DEVICE= ...
- CF235A 【LCM Challenge】
这题好毒瘤啊 (特别是long long的坑,调了半天没调好!!)先将你特判一下小于3的话直接输出就是惹,不是的话就判断一下它能不能被2整除如果不能就直接输出n*(n-1)*(n-2)否则进行枚举枚举 ...
- 2019中山纪念中学夏令营-Day20[JZOJ] T1旅游详解
2019中山纪念中学夏令营-Day20[JZOJ] 提高组B组 Team_B组 T1 旅游 Time Limits: 2000 ms Memory Limits: 262144 KB Descrip ...
- JVM 线上故障排查基本操作 (转)
前言 对于后端程序员,特别是 Java 程序员来讲,排查线上问题是不可避免的.各种 CPU 飚高,内存溢出,频繁 GC 等等,这些都是令人头疼的问题.楼主同样也遇到过这些问题,那么,遇到这些问题该如何 ...
- 安装PIG
下载Pig 能够执行在Hadoop 0.20.* http://mirror.bit.edu.cn/apache/pig/pig-0.11.1/pig-0.11.1.tar.gz 也能够依据你的Had ...
- execjs执行js代码报错:Exception in thread Thread-1
最近在爬一个js数据加密的网站的时候,出了点问题,困扰了我两天 直接运行js文件的时候正常,但是用execjs运行js代码的时候总是会报错 最后翻了很多博客之后,终于找到了原因:原因是有一个程序在使用 ...
- 基于bootstrap的分页插件
之前做的分页,是自己后端写一堆代码,返回给前端页面显示,感觉比较繁重.不灵活.今天研究下基于bootstrap的做的插件,整理如下: 在使用bootstrap的插件的时候,需要导入一些css.js. ...
- 本地存储cookie,localStorage,sessionStorage
常见的前端存储有老朋友 cookie,短暂的 sessionStorage,和简单强大的localStorage 他们之间的区别有以下几点 1.. cookie在浏览器和服务器间来回传递.而sessi ...