es之IK分词器
1:默认的分析器-- standard
使用默认的分词器
curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=standard' -d '我爱中国'
curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=simple' -d '我爱中国'
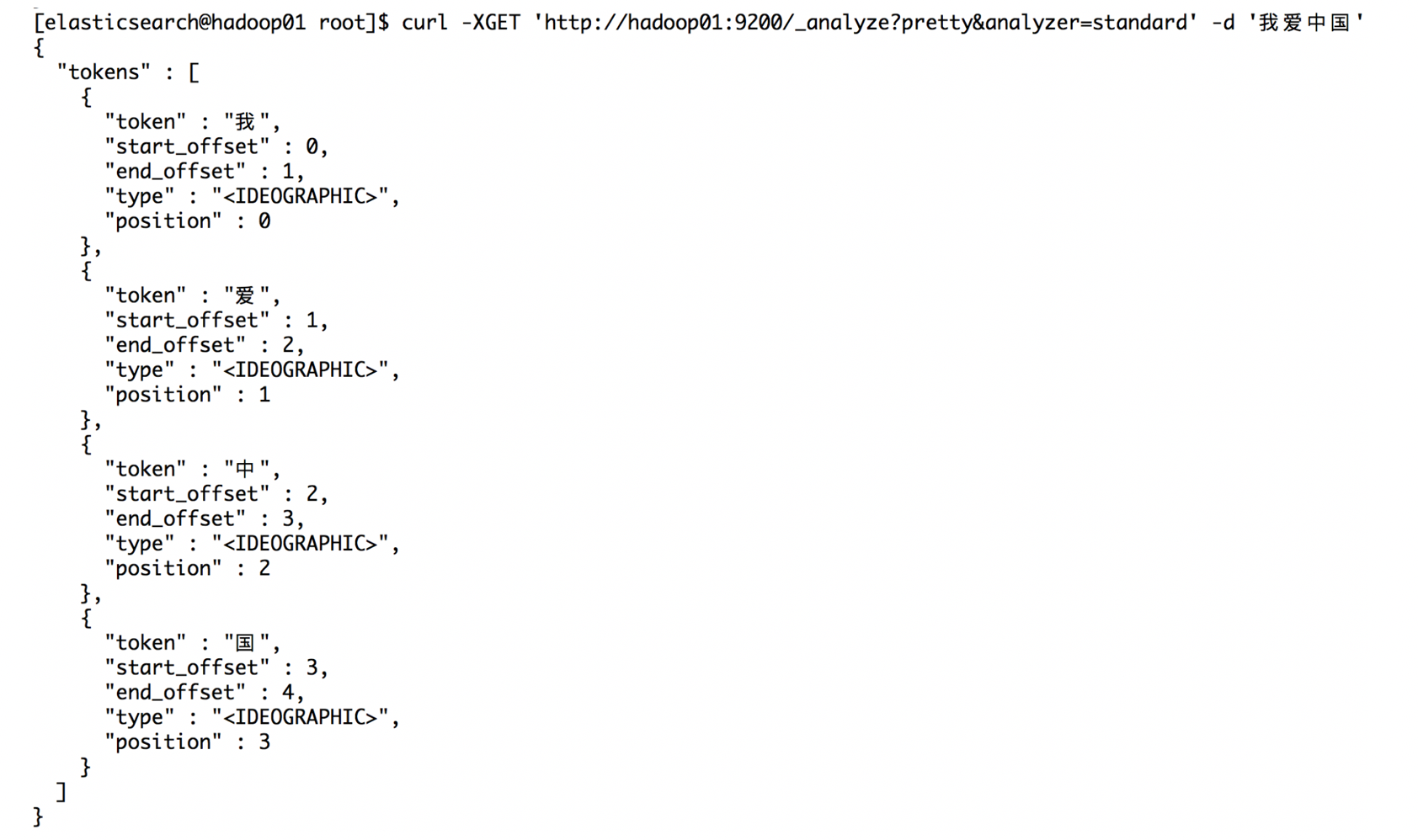
这就是默认的分词器,但是默认的分析器有时候在生产环境会出现问题,比如:
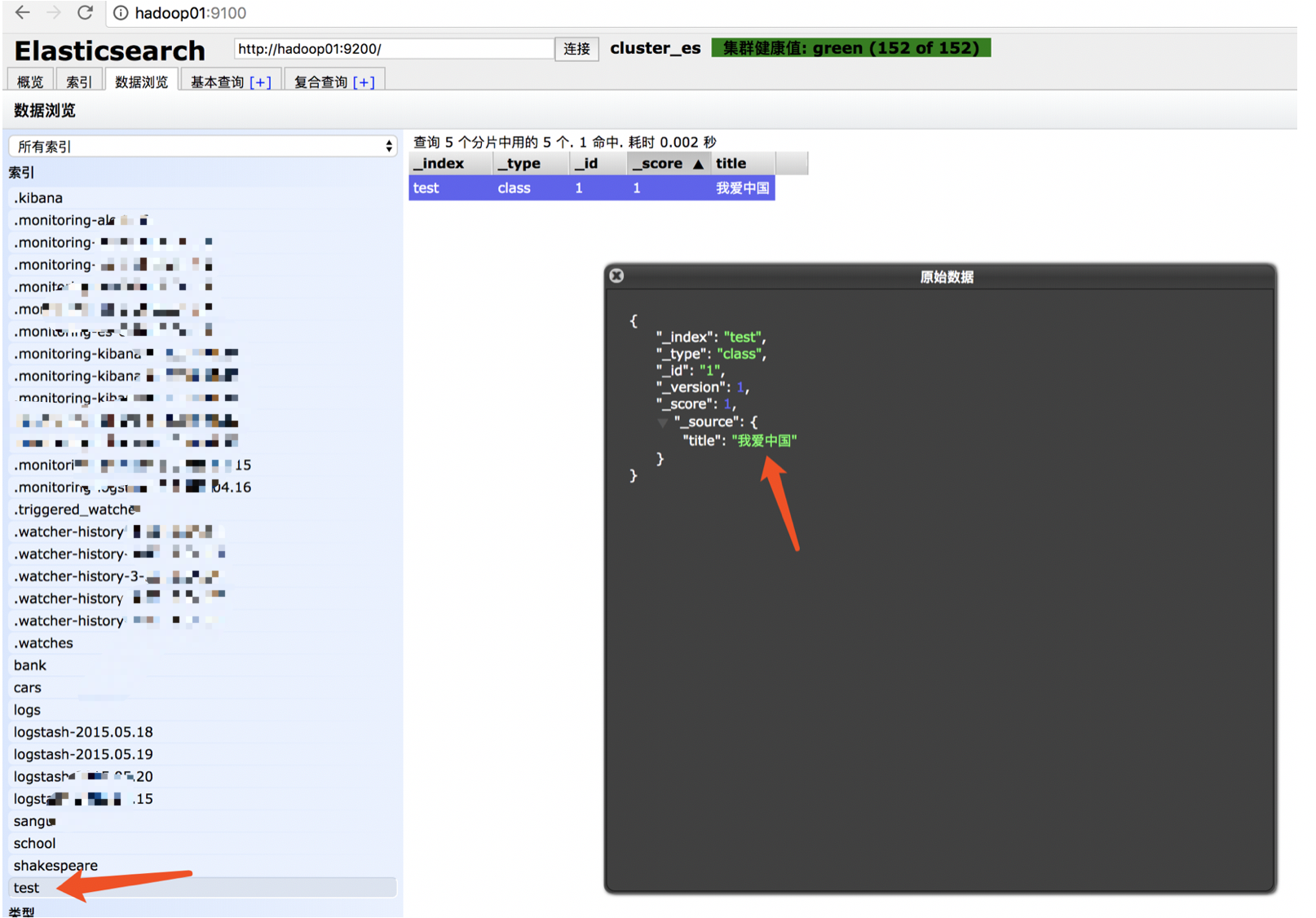
curl -XPUT 'http://hadoop01:9200/test/class/1' -d '{"title" : "我爱中国"}'
去hadoop01:9100查看当前索引数据:
然后使用命令查询:
curl -XGET 'hadoop01:9200/test/class/_search?pretty' -d '
{ "query": { "term": {"title": "我爱中国"}}}'
结果:
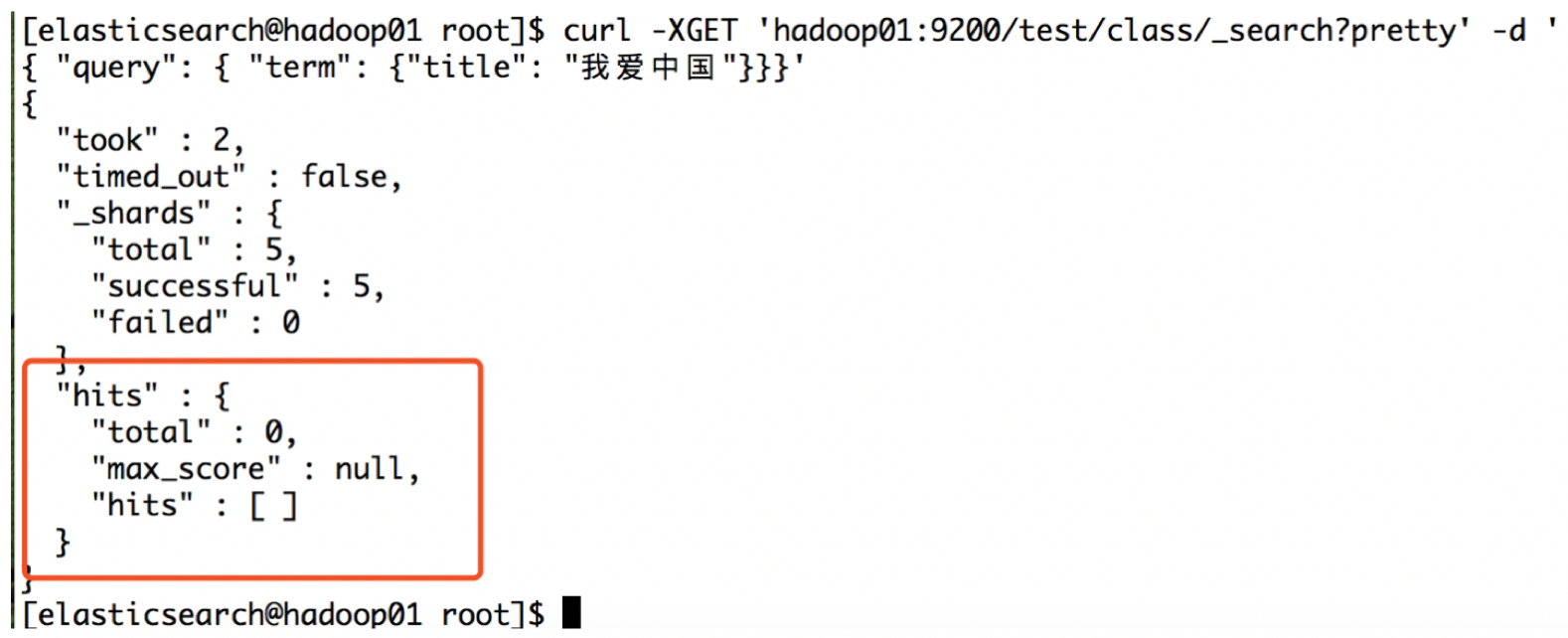
发现没有找到数据!
这说明分词器出了问题!然后我们可以通过分析器提供的接口去做查询,查看一下当前的分词器是如何进行分词的:
curl -XGET 'hadoop01:9200/test/_analyze?field=title?pretty' -d '我爱中国'

通过图片我们可以看到,我们的数据经过分词器后,会将数据切割成---我、爱、中、国;如果单独去查询每一个字段,都是可以查询到的:
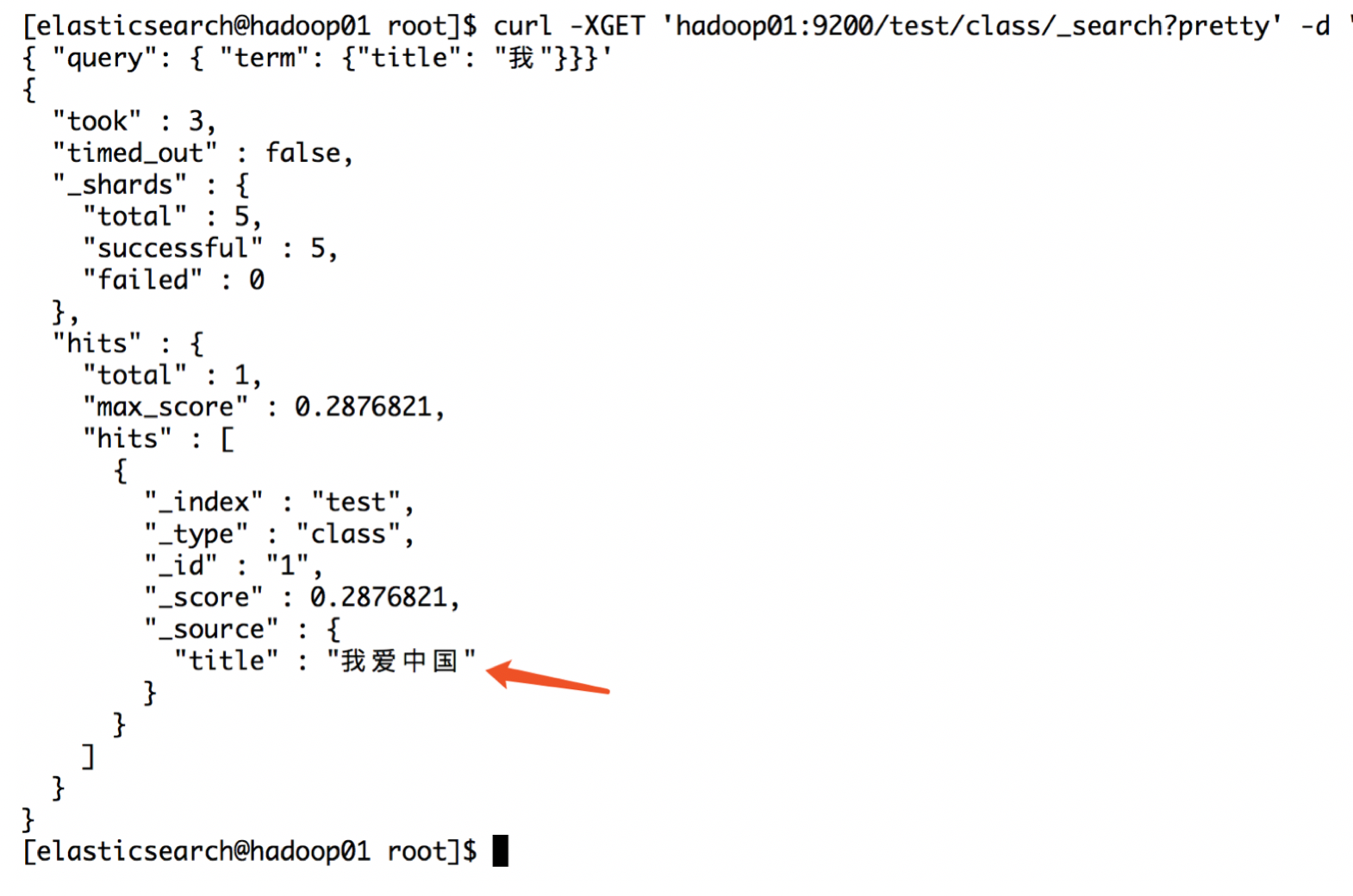
整体查询确查询不到;这就是默认的分词器存在的弊端;
2:IK分词器
2.1:安装
1):下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip
2):下载好了之后解压,将解压后的文件夹放在elasticsearch目录下的plugins目录下,并重命名为analysis-ik【发送到所有机器(本课程提供安装包)】
3):重启elasticsearch
ik带有两个分词器:
• ik_max_word :会将文本做最细粒度的拆分;尽可能多的拆分出词语
• ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
2.2:使用IK分词
1):构建索引,指定IK分词器
curl -XPUT 'http://hadoop01:9200/iktest?pretty' -d '{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik_max_word"
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"subject" : {
"type" : "string",
"analyzer" : "ik_max_word"
}
}
}
}
}'
2):插入数据
curl -XPOST http://hadoop01:9200/iktest/article/_bulk?pretty -d '
{ "index" : { "_id" : "1" } }
{"subject" : ""闺蜜"崔顺实被韩检方传唤 韩总统府促彻查真相" }
{ "index" : { "_id" : "2" } }
{"subject" : "韩举行"护国训练" 青瓦台:决不许国家安全出问题" }
{ "index" : { "_id" : "3" } }
{"subject" : "媒体称FBI已经取得搜查令 检视希拉里电邮" }
{ "index" : { "_id" : "4" } }
{"subject" : "村上春树获安徒生奖 演讲中谈及欧洲排外问题" }
{ "index" : { "_id" : "5" } }
{"subject" : "希拉里团队炮轰FBI 参院民主党领袖批其”违法”" }
'
3):查询测试
curl -XPOST http://hadoop01:9200/iktest/article/_search?pretty -d'
{
"query" : { "match" : { "subject" : "希拉里和韩国" }},
"highlight" : {
"pre_tags" : ["<font color='red'>"],
"post_tags" : ["</font>"],
"fields" : {
"subject" : {}
}
}
}
'
2.3:热词更新
现在网络热词很多,每隔一段时间就会出现网红热词;但是如果直接使用IK分词,是识别不了这些词的;
curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=ik_max_word' -d '
王者荣耀'
返回结果:

IK并没有识别出网红的词汇;ik 的主词典中没有【老铁、没毛病】词,所以被拆分了。
修改 IK 的配置文件 :ES 目录/export/servers/elasticsearch-5.5.2/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
修改配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">192.168.0.1/stopworld.di</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
在custom/my.dic中添加:老铁、没毛病
然后重启es;在次执行:
curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=ik_max_word' -d '老铁没毛病,双击666'
但是,上面的操作是需要进行重启的,上面的步骤只是更新词库,并不是所谓的热更新;所谓的热更新词库,是要在不重启es的前提下完成的;
es之IK分词器的更多相关文章
- Restful认识和 IK分词器的使用
什么是Restful风格 Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作. 使用Restful的好处: 透 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- 安装ik分词器以及版本和ES版本的兼容性
一.查看自己ES的版本号与之对应的IK分词器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二. ...
- ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询. 然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只 ...
- Elasticsearch5.1.1+ik分词器+HEAD插件安装小记
一.安装elasticsearch 1.首先需要安装好java,并配置好环境变量,详细教程请看 http://tecadmin.net/install-java-8-on-centos-rhel-an ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- elasticsearch安装ik分词器
一.概要: 1.es默认的分词器对中文支持不好,会分割成一个个的汉字.ik分词器对中文的支持要好一些,主要由两种模式:ik_smart和ik_max_word 2.环境 操作系统:centos es版 ...
随机推荐
- Bean与Map的转换 和 Map与Bean的转换
package com.JUtils.beanConvert; import java.beans.BeanInfo; import java.beans.IntrospectionException ...
- 文档压缩 | gzip、bzip2、xz
6.文档的压缩与打包 Linux下常见后缀名所对应的的压缩工具 .gz 表示由gzip压缩工具压缩的文件 .bz2 表示由bzip2压缩工具压缩的文件 .tar 表示由tar打包程序打包的文件(tar ...
- 牛客练习赛46 E 华华和奕奕学物理 (树状数组)
https://ac.nowcoder.com/acm/contest/894/E 一开始写了一个简单的模拟 通过率只有5%...... 看题解真的理解了好久!!肥宅大哭orz 题解如下 最后一句:“ ...
- Phone List POJ-3630 字典树 or 暴力
Phone List POJ-3630 字典树 or 暴力 题意 目前有 t 组数据, n 个电话号码,如果拨打号码的时候 先拨通了某个号码,那么这一串号码就无法全部拨通. 举个例子 911 和 91 ...
- Java并发编程:锁的释放
Java并发编程:锁的释放 */--> code {color: #FF0000} pre.src {background-color: #002b36; color: #839496;} Ja ...
- zebra代码分析
http://blog.csdn.net/xuyanbo2008/article/details/7439738
- Scrapy 教程(七)-架构与中间件
Scrapy 使用 Twisted 这个异步框架来处理网络通信,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求. Scrapy 架构 其实之前的教程都有涉及,这里再做个系统介绍 Engin ...
- 背包问题: HDU1114Piggy-Bank
Piggy-Bank Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- django中的FBV和CBV??
django中请求处理方式有2种:FBV 和 CBV 一.FBV FBV(function base views) 就是在视图里使用函数处理请求. 看代码: urls.py from django.c ...
- JDK集合框架源码分析 - 简单概要
1.类继承体系 在集合框架的类继承体系中,最顶层有两个接口Collection.Map: Collection 表示一组纯数据 Map 表示一组key-value对 Collection的类继承体系: ...