Packet flow in l2(receive and transmit)
Receive
1. napi && none napi
讲网络收报过程,必然要涉及到网卡收报模型发展历史。总体上看,网络收报过经历了如下发展过程:
轮询 ---à 中断 ---à 中断期间处理多帧 ---à定时器驱动的中断 ---à中断加轮询
轮询:最早出现的收报方式,易于理解和编程,核心思想是cpu不断读取网卡指定寄存器来判断是否有数据达到netdevice,从而进一步决定是否启动收报线程。轮询的特点是低流量时浪费cpu资源,cpu负载过高,高流量时表现较好。
中断:每当有一个数据帧到达网卡时候,网卡负责发出收报中断,cpu启动收报线程。显而易见,在低负载时候,cpu只需要响应网卡的收报中断,其他时间可以shedule 别的内核线程,资源利用率较高,然而在高负载的情况下,cpu必然后因为疲于应付网卡中断而无暇顾及其它优先级较低的中断,耗费掉大量的cpu资源。此方式即为我们常说的 none napi。
中断期间处理多帧:中断收报方式的改进,一次收报中断,cpu处理多个网络数据帧。在网络流量较大的情况下,避免了频繁中断。此情况网卡需要较大缓存。
定时器驱动中断:由网卡定时发出中断(也可由cpu模拟)。
中断加轮询:结合中断在低负载和轮询在高负载的优势, mac收到一个包来后会产生接收中断,但是马上关闭。直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断。此方式即为我们常说的napi。
2. data structure
- 1218 struct softnet_data
- 1219 {
- 1220 struct Qdisc *output_queue;
- 1221 struct sk_buff_head input_pkt_queue;
- 1222 struct list_head poll_list;
- 1223 struct sk_buff *completion_queue;
- 1224
- 1225 struct napi_struct backlog;
- 1226 };
上面提到的softdate_net结构是用于进行报文收发调度的结构,内核为每个CPU维护一个这样的结构,这样不同CPU之间就没必要使用上锁机制。其中需要重点关注如下三种数据结构:
a.input_pkt_queue: none napi情况下,接受到的skb被放入该队列。
b.backlog: none napi情况下会用到的一个虚拟网络设备。
c.poll_list: 网络设备dev的队列。其中的设备接收到了报文,需要被处理;napi和none napi都会用到的。
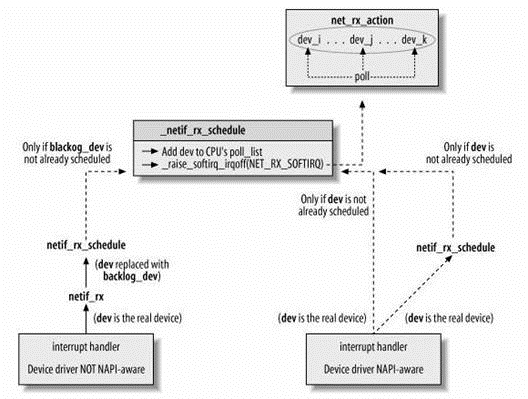
如下图所示,napi 和 none napi 方式,都会调用 __netif_rx_schedule 将收到数据的dev链接到poll_list结构,然后触发软中段,稍后再由软中断处理函数 net_rx_action 对当前CPU的softdate_net结构的poll_list队列中的所有dev,调用dev->poll方法。对于napi 来说,dev->poll 方法是驱动程序自己提供的。对于 none napi设备来说,为了兼容这样的处理方式,接收到skb被放入input_pkt_queue队列,然后虚拟设备backlog_dev被加入poll_list。而最后, process_backlog作为虚拟设备backlog_dev->poll函数将对input_pkt_queue队列中的skb进行处理。
3. napi(e100网卡)

每个网络设备(MAC层)都有自己的net_device数据结构,这个结构上有napi_struct。每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量上。
这样在软中断时,net_rx_action会遍历cpu私有变量的poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。
3.1 初始化相关全局数据结构,并注册收报和发包相关软中断处理函数
start_kernel()
--> rest_init()
-->
do_basic_setup()
--> do_initcall
-->net_dev_init
- static int __init net_dev_init(void)
- {
- for_each_possible_cpu(i) {
- struct softnet_data *queue;
- queue = &per_cpu(softnet_data, i);
- skb_queue_head_init(&queue->input_pkt_queue);
- queue->completion_queue = NULL;
- INIT_LIST_HEAD(&queue->poll_list);
- queue->backlog.poll = process_backlog;
- queue->backlog.weight = weight_p;
- queue->backlog.gro_list = NULL;
- queue->backlog.gro_count = ;
- }
- goto out;
- open_softirq(NET_TX_SOFTIRQ, net_tx_action);
- open_softirq(NET_RX_SOFTIRQ, net_rx_action);
- }
3.2 在驱动的 e100_probe 方法中,初始化napi结构,注册 e100_poll 轮询处理函数.
- 2717 static int __devinit e100_probe(struct pci_dev *pdev,
- 2718 const struct pci_device_id *ent)
- 2719 {
- 2720 struct net_device *netdev;
- 2721 struct nic *nic;
- 2722 int err;
- 2723
- 2724 if (!(netdev = alloc_etherdev(sizeof(struct nic)))) {
- 2725 if (((1 << debug) - 1) & NETIF_MSG_PROBE)
- 2726 printk(KERN_ERR PFX "Etherdev alloc failed, abort.\n");
- 2727 return -ENOMEM;
- 2728 }
- 2729
- 2730 netdev->netdev_ops = &e100_netdev_ops;
- 2731 SET_ETHTOOL_OPS(netdev, &e100_ethtool_ops);
- 2732 netdev->watchdog_timeo = E100_WATCHDOG_PERIOD;
- 2733 strncpy(netdev->name, pci_name(pdev), sizeof(netdev->name) - 1);
- 2734
- 2735 nic = netdev_priv(netdev);
- 2736 netif_napi_add(netdev, &nic->napi, e100_poll, E100_NAPI_WEIGHT);
- 2737 nic->netdev = netdev;
- 2738 nic->pdev = pdev;
- 2739 nic->msg_enable = (1 << debug) - 1;
3.3. 在 e100_open 方法:
a.分配存储以太网包的skb:
e100_open()
àe100_up()
àe100_rx_alloc_list()
- 2065 static int e100_rx_alloc_list(struct nic *nic)
- 2066 {
- 2067 struct rx *rx;
- 2068 unsigned int i, count = nic->params.rfds.count;
- 2069 struct rfd *before_last;
- 2070
- 2071 nic->rx_to_use = nic->rx_to_clean = NULL;
- 2072 nic->ru_running = RU_UNINITIALIZED;
- 2073
- 2074 if (!(nic->rxs = kcalloc(count, sizeof(struct rx), GFP_ATOMIC)))
- 2075 return -ENOMEM;
- 2076
- 2077 for (rx = nic->rxs, i = 0; i < count; rx++, i++) {
- 2078 rx->next = (i + 1 < count) ? rx + 1 : nic->rxs;
- 2079 rx->prev = (i == 0) ? nic->rxs + count - 1 : rx - 1;
- 2080 if (e100_rx_alloc_skb(nic, rx)) {
- 2081 e100_rx_clean_list(nic);
- 2082 return -ENOMEM;
- 2083 }
- 2084 }
b.e100_up中注册收报硬中断处理函数e100_intr().
- if ((err = request_irq(nic->pdev->irq, e100_intr, IRQF_SHARED,
- nic->netdev->name, nic->netdev)))
- goto err_no_irq;
3.4 ok,前期贮备工作好了,下面开始收报流程。
网卡收到数据包后,将数据DMA到skb->data结构中,然后保存现场,根据中断掩码,调用硬中断处理函数e100_intr()。e100_intr() 调用 __napi_schedule 将该网卡的 napi 结构挂载到当前cpu 的poll_list ,同时调用 __raise_softirq_irqoff() 触发收报软中断处理函数。
- static irqreturn_t e100_intr(int irq, void *dev_id)
- {
- if (likely(napi_schedule_prep(&nic->napi))) {
- e100_disable_irq(nic);
- __napi_schedule(&nic->napi);
- }
- void __napi_schedule(struct napi_struct *n)
- {
- unsigned long flags;
- local_irq_save(flags);
- list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);
- __raise_softirq_irqoff(NET_RX_SOFTIRQ);
- local_irq_restore(flags);
- }
3.5 软中断函数net_rx_action().主要工作是遍历有数据帧等待接收的设备链表,对于每个设备,执行它相应的poll函数。
- 2834 static void net_rx_action(struct softirq_action *h)
- 2835 {
- 2836 struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
- //通过 napi_struct.poll_list, 将N多个 napi_struct 链接到一条链上
- //通过 CPU私有变量,我们找到了链头,然后开始遍历这个链
- 2837 unsigned long time_limit = jiffies + 2;
- 2838 int budget = netdev_budget;
- //这个值就是 net.core.netdev_max_backlog,通过sysctl来修改
- 2839 void *have;
- 2840
- 2841 local_irq_disable();
- 2842
- 2843 while (!list_empty(list)) {
- 2844 struct napi_struct *n;
- 2845 int work, weight;
- 2846
- 2847 /* If softirq window is exhuasted then punt.
- 2848 * Allow this to run for 2 jiffies since which will allow
- 2849 * an average latency of 1.5/HZ.
- 2850 */
- 2851 if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
- 2852 goto softnet_break;
- 2853
- 2854 local_irq_enable();
- 2855
- 2861 n = list_entry(list->next, struct napi_struct, poll_list);
- 2862
- 2863 have = netpoll_poll_lock(n);
- 2864
- 2865 weight = n->weight;
- 2866
- 2867 /* This NAPI_STATE_SCHED test is for avoiding a race
- 2868 * with netpoll's poll_napi(). Only the entity which
- 2869 * obtains the lock and sees NAPI_STATE_SCHED set will
- 2870 * actually make the ->poll() call. Therefore we avoid
- 2871 * accidently calling ->poll() when NAPI is not scheduled.
- 2872 */
- 2873 work = 0;
- 2874 if (test_bit(NAPI_STATE_SCHED, &n->state)) {//检查状态标记,此标记在接收中断里加上的.
- 2875 work = n->poll(n, weight);
- //使用NAPI的话,使用的是网络设备自己的napi_struct.poll/对于e100,是e100_poll
- 2876 trace_napi_poll(n);
- 2877 }
- 2878
- 2879 WARN_ON_ONCE(work > weight);
- 3.6 e100_poll.
- 2132 static int e100_poll(struct napi_struct *napi, int budget)
- 2133 {
- 2137 e100_rx_clean(nic, &work_done, budget);
- 2138 e100_tx_clean(nic);
- 2139 ……
- 2147 }
- 1967 static void e100_rx_clean(struct nic *nic, unsigned int *work_done,
- 1968 unsigned int work_to_do)
- 1969 {
- 1974
- 1975 /* Indicate newly arrived packets */
- 1976 for (rx = nic->rx_to_clean; rx->skb; rx = nic->rx_to_clean = rx->next) {
- 1977 err = e100_rx_indicate(nic, rx, work_done, work_to_do);
- 1981 }
- 1884 static int e100_rx_indicate(struct nic *nic, struct rx *rx,
- 1885 unsigned int *work_done, unsigned int work_to_do)
- 1886 {
- 1887 struct net_device *dev = nic->netdev;
- 1888 struct sk_buff *skb = rx->skb;
- 1889 struct rfd *rfd = (struct rfd *)skb->data;
- 1890 u16 rfd_status, actual_size;
- 1891
- 1941
- 1942 /* Pull off the RFD and put the actual data (minus eth hdr) */
- 1943 skb_reserve(skb, sizeof(struct rfd));
- 1944 skb_put(skb, actual_size);
- 1945 skb->protocol = eth_type_trans(skb, nic->netdev);
- 1946
- 1947 if (unlikely(!(rfd_status & cb_ok))) {
- 1948 /* Don't indicate if hardware indicates errors */
- 1949 dev_kfree_skb_any(skb);
- 1950 } else if (actual_size > ETH_DATA_LEN + VLAN_ETH_HLEN) {
- 1951 /* Don't indicate oversized frames */
- 1952 nic->rx_over_length_errors++;
- 1953 dev_kfree_skb_any(skb);
- 1954 } else {
- 1955 dev->stats.rx_packets++;
- 1956 dev->stats.rx_bytes += actual_size;
- 1957 netif_receive_skb(skb);
- 1958 if (work_done)
- 1959 (*work_done)++;
- 1960 }
- 1961
- 1962 rx->skb = NULL;
- 1963
- 1964 return 0;
- 1965 }
主要工作在e100_rx_indicate()中完成,这主要重设SKB的一些参数,然后跟process_backlog(),一样,最终调用netif_receive_skb(skb)。
3.7 netif_receive_skb(skb)
这是一个辅助函数,用于在poll中处理接收到的帧。它主要是向各个已注册的协议处理例程发送一个SKB。
4. none napi (3c59x)
4.1 vortex_open() 方法注册硬中断处理函数 vortex_interrupt().
- 1698 vortex_open(struct net_device *dev)
- 1699 {
- 1700 struct vortex_private *vp = netdev_priv(dev);
- 1701 int i;
- 1702 int retval;
- 1703
- 1704 /* Use the now-standard shared IRQ implementation. */
- 1705 if ((retval = request_irq(dev->irq, vp->full_bus_master_rx ?
- 1706 &boomerang_interrupt : &vortex_interrupt, IRQF_SHARED, dev->name, dev))) {
- 1707 pr_err("%s: Could not reserve IRQ %d\n", dev->name, dev->irq);
- 1708 goto err;
- 1709 }
vortex_interrupt(),它会判断寄存器的值作出相应的动作:
- if (status & RxComplete)
- vortex_rx(dev);
如上,当中断指示,有数据包在等待接收,这时,中断例程会调用接收函数vortex_rx(dev)接收新到来的包(如下,只保留核心部分):
- static int vortex_rx(struct net_device *dev)
- {
- int pkt_len = rx_status & 0x1fff;
- struct sk_buff *skb;
- skb = dev_alloc_skb(pkt_len + );
- if (vortex_debug > )
- pr_debug("Receiving packet size %d status %4.4x.\n",
- pkt_len, rx_status);
- if (skb != NULL) {
- skb_reserve(skb, ); /* Align IP on 16 byte boundaries */
- /* 'skb_put()' points to the start of sk_buff data area. */
- if (vp->bus_master &&
- ! (ioread16(ioaddr + Wn7_MasterStatus) & 0x8000)) {
- dma_addr_t dma = pci_map_single(VORTEX_PCI(vp), skb_put(skb, pkt_len),
- pkt_len, PCI_DMA_FROMDEVICE);
- iowrite32(dma, ioaddr + Wn7_MasterAddr);
- iowrite16((skb->len + ) & ~, ioaddr + Wn7_MasterLen);
- iowrite16(StartDMAUp, ioaddr + EL3_CMD);
- while (ioread16(ioaddr + Wn7_MasterStatus) & 0x8000)
- ;
- pci_unmap_single(VORTEX_PCI(vp), dma, pkt_len, PCI_DMA_FROMDEVICE);
- } else {
- ioread32_rep(ioaddr + RX_FIFO,
- skb_put(skb, pkt_len),
- (pkt_len + ) >> );
- }
- iowrite16(RxDiscard, ioaddr + EL3_CMD); /* Pop top Rx packet. */
- skb->protocol = eth_type_trans(skb, dev);
- netif_rx(skb);
- dev->stats.rx_packets++;
- /* Wait a limited time to go to next packet. */
- for (i = ; i >= ; i--)
- if ( ! (ioread16(ioaddr + EL3_STATUS) & CmdInProgress))
- break;
- continue;
它首先为新到来的数据包分配一个skb结构及pkt_len+5大小的数据长度,然后便将接收到的数据从网卡复制到(DMA)这个SKB的数据部分中。最后,调用netif_rx(skb)进一步处理数据:
- 2016 int netif_rx(struct sk_buff *skb)
- 2017 {
- 2018 struct softnet_data *queue;
- 2019 unsigned long flags;
- 2031 */
- 2032 local_irq_save(flags);
- 2033 queue = &__get_cpu_var(softnet_data);
- 2034
- 2035 __get_cpu_var(netdev_rx_stat).total++;
- 2036 if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
- 2037 if (queue->input_pkt_queue.qlen) {
- 2038 enqueue:
- 2039 __skb_queue_tail(&queue->input_pkt_queue, skb);
- 2040 local_irq_restore(flags);
- 2041 return NET_RX_SUCCESS;
- 2042 }
- 2043
- 2044 napi_schedule(&queue->backlog);
- 2045 goto enqueue;
- 2046 }
- 2047
- 2048 __get_cpu_var(netdev_rx_stat).dropped++;
- 2049 local_irq_restore(flags);
- 2050
- 2051 kfree_skb(skb);
- 2052 return NET_RX_DROP;
- 2053 }
这段代码关键是,将这个SKB加入到相应的input_pkt_queue队列中,并调用napi_schedule(),
- static inline void napi_schedule(struct napi_struct *n)
- {
- if (napi_schedule_prep(n))
- __napi_schedule(n);
- }
napi_schedule()调用__napi_schedule(),__napi_schedule()作用在前面已经见过。到这里,napi和 none napi 方式函数调用路径得到统一.
总之,NONE-NAPI的中断上半部接收过程可以简单的描述为,它首先为新到来的数据帧分配合适长度的SKB,再将接收到的数据从NIC中拷贝过来,然后将这个SKB链入当前CPU的softnet_data中的链表中,最后进一步触发中断下半部继续处理。
4.2 process_backlog:
process_backlog 为none-napi 对应的poll 函数。
- static int process_backlog(struct napi_struct *napi, int quota)
- {
- int work = ;
- struct softnet_data *queue = &__get_cpu_var(softnet_data);
- unsigned long start_time = jiffies;
- napi->weight = weight_p;
- do {
- struct sk_buff *skb;
- local_irq_disable();
- skb = __skb_dequeue(&queue->input_pkt_queue);
- if (!skb) {
- __napi_complete(napi);
- local_irq_enable();
- break;
- }
- local_irq_enable();
- netif_receive_skb(skb);
- } while (++work < quota && jiffies == start_time);
- return work;
- }
它首先找到当前CPU的softnet_data结构,然后遍历其数据队SKB,并将数据上交netif_receive_skb(skb)处理。
Transmit
报文的发送是由网络协议栈的上层发起的。网络协议栈上层构造一个需要发送的skb结构后(该skb已经包含了数据链路层的报头),调用dev_queue_xmit函数进行发送;
dev_queue_xmit(skb);
该函数先会处理一些缓冲区重组、计算校验和之类的杂事,然后开始处理报文的发送。
发送报文有两种策略,有队列或无队列。这是由网络设备驱动程序在定义其对应的dev结构时指定的,一般的设备都会使用队列。
dev->qdisc指向一个队列的实例,里面包含了队列本身以及操作队列的方法(enqueue、dequeue、requeue)。这些方法的集合组成了一种队列规则(skb将以某种规则入队、以某种规则出队,并不一定是简单的先进先出),这样的规则可用于流量控制。
网络设备驱动程序可以选择自己的设备使用什么样的队列,或是不使用队列。
- int dev_queue_xmit(struct sk_buff *skb)
- {
- struct net_device *dev = skb->dev;
- struct netdev_queue *txq;
- struct Qdisc *q;
- int rc = -ENOMEM;
- /* GSO will handle the following emulations directly. */
- if (netif_needs_gso(dev, skb))
- goto gso;
- if (skb_has_frags(skb) &&
- !(dev->features & NETIF_F_FRAGLIST) &&
- __skb_linearize(skb))
- goto out_kfree_skb;
- /* Fragmented skb is linearized if device does not support SG,
- 1903 * or if at least one of fragments is in highmem and device
- 1904 * does not support DMA from it.
- 1905 */
- if (skb_shinfo(skb)->nr_frags &&
- (!(dev->features & NETIF_F_SG) || illegal_highdma(dev, skb)) &&
- __skb_linearize(skb))
- goto out_kfree_skb;
- skb->tc_verd = SET_TC_AT(skb->tc_verd, AT_EGRESS);
- #endif
- //对于有队列设备处理
- if (q->enqueue) {
- rc = __dev_xmit_skb(skb, q, dev, txq);
- goto out;
- }
- if (dev->flags & IFF_UP) {
- int cpu = smp_processor_id(); /* ok because BHs are off */
- if (txq->xmit_lock_owner != cpu) {
- HARD_TX_LOCK(dev, txq, cpu);
- if (!netif_tx_queue_stopped(txq)) {
- rc = NET_XMIT_SUCCESS;
- //对于无队列设备直接调用dev_hard_start_xmit发送
- if (!dev_hard_start_xmit(skb, dev, txq)) {
- HARD_TX_UNLOCK(dev, txq);
- goto out;
- }
- }
- 对于__dev_xmit_skb包含了enqueue和qdis_run函数的调用.
- static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
- struct net_device *dev,
- struct netdev_queue *txq)
- {
- spinlock_t *root_lock = qdisc_lock(q);
- int rc;
- } else {
- rc = qdisc_enqueue_root(skb, q);
- qdisc_run(q);
- }
- qdis_run__qdis_runqdis_restart
- static inline int qdisc_restart(struct Qdisc *q)
- {
- struct netdev_queue *txq;
- struct net_device *dev;
- spinlock_t *root_lock;
- struct sk_buff *skb;
- /* Dequeue packet */
- skb = dequeue_skb(q);
- if (unlikely(!skb))
- return ;
- root_lock = qdisc_lock(q);
- dev = qdisc_dev(q);
- txq = netdev_get_tx_queue(dev, skb_get_queue_mapping(skb));
- return sch_direct_xmit(skb, q, dev, txq, root_lock);
- }
qdisc_restart的主要工作就是不断调用dev->qdisc->dequeue方法从队列中取出待发送的报文,然后调用sch_direct_xmit方法进行发送。sch_direct_xmit间接调用设备驱动程序实现的方法,会直接和网络设备去打交道,将报文发送出去.
如果报文发送失败,sch_direct_xmit会调用dev->qdisc->requeue方法将skb重新放回队列
- default:
- /* Driver returned NETDEV_TX_BUSY - requeue skb */
- if (unlikely (ret != NETDEV_TX_BUSY && net_ratelimit()))
- printk(KERN_WARNING "BUG %s code %d qlen %d\n",
- dev->name, ret, q->q.qlen);
- ret = dev_requeue_skb(skb, q);
- break;
- }
__qdisc_run会循环调用qdisc_restart,当此函数调用时间过长或者有其它进程需要调度的时候,调用__netif_schedule.
- void __qdisc_run(struct Qdisc *q)
- {
- unsigned long start_time = jiffies;
- while (qdisc_restart(q)) {
- /*
- 201 * Postpone processing if
- 202 * 1. another process needs the CPU;
- 203 * 2. we've been doing it for too long.
- 204 */
- if (need_resched() || jiffies != start_time) {
- __netif_schedule(q);
- break;
- }
- }
- clear_bit(__QDISC_STATE_RUNNING, &q->state);
- }
- __netif_schedule __netif_reschedule
- static inline void __netif_reschedule(struct Qdisc *q)
- {
- struct softnet_data *sd;
- unsigned long flags;
- local_irq_save(flags);
- sd = &__get_cpu_var(softnet_data);
- q->next_sched = sd->output_queue;
- sd->output_queue = q;
- raise_softirq_irqoff(NET_TX_SOFTIRQ);
- local_irq_restore(flags);
- }
__netif_reschedule函数将dev加入softdate_net的output_queue队列中(其中的设备都是有报文等待发送的,将在稍后被处理)。然后触发一次NET_TX_SOFTIRQ软中断。于是在下一个中断到来时,对应的软中断处理函数net_tx_action将被调用
软中断NET_TX_SOFTIRQ被触发,将使得net_tx_action函数被调用。该函数主要做了两件事:
1、从softdate_net的completion_queue队列中取出每一个skb,将其释放;
2、对于softdate_net的output_queue队列中的dev,调用qdisc_run继续尝试发送其qdisc队列中的报文;
参考资料
http://blog.chinaunix.net/uid-24148050-id-473352.html
https://yq.aliyun.com/articles/8898
http://bbs.chinaunix.net/thread-2141004-1-1.html
source code : linux-2.6.32.67
Packet flow in l2(receive and transmit)的更多相关文章
- RFID Reader 线路图收集
This 125 kHz RFID reader http://www.serasidis.gr/circuits/RFID_reader/125kHz_RFID_reader.htm http:// ...
- VNF网络性能提升解决方案及实践
VNF网络性能提升解决方案及实践 2016年7月 作者: 王智民 贡献者: 创建时间: 2016-7-20 稳定程度: 初稿 修改历史 版本 日期 修订人 说明 1.0 20 ...
- linux kernel 关于RSS/RPS/RFS/XPS的介绍
Introduction============ This document describes a set of complementary techniques in the Linuxnetwo ...
- Lock-less and zero copy messaging scheme for telecommunication network applications
A computer-implemented system and method for a lock-less, zero data copy messaging mechanism in a mu ...
- sock skbuf 结构:
/** * struct sock - network layer representation of sockets * @__sk_common: shared layout with inet_ ...
- 扩展Linux网络栈
扩展Linux网络栈 来自Linux内核文档.之前看过这篇文章,一直好奇,问什么一条网络流会固定在一个CPU上进行处理,本文档可以解决这个疑问.为了更好地理解本文章中的功能,将这篇文章穿插入内. 简介 ...
- 蓝牙BLE实用教程
蓝牙BLE实用教程 Bluetooth BLE 欢迎使用 小书匠(xiaoshujiang)编辑器,您可以通过 设置 里的修改模板来改变新建文章的内容. 1.蓝牙BLE常见问答 Q: Smart Re ...
- Enhancing the Scalability of Memcached
原文地址: https://software.intel.com/en-us/articles/enhancing-the-scalability-of-memcached-0 1 Introduct ...
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
http://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/ ...
随机推荐
- 计算机网络(九),HTTP简介
目录 1.超文本传输协议HTTP的主要特点 2.HTTP请求结构 3.HTTP响应结构 4.http请求/响应的步骤 九.HTTP简介 1.超文本传输协议HTTP的主要特点 (1)支持客户/服务器模式 ...
- CSP2019-S2参赛总结 暨 近期学习反思
前言 岁月不居,时节如流.眨眼间,2019的联赛就已经落下帷幕了,回忆这一年的学习,有许许多多的事情想写下来.趁联赛结果还未出来,赶紧写下这篇文章,以记录我这段时间的学习和生活. "你怎么又 ...
- Acwing:137. 雪花雪花雪花(Hash表)
有N片雪花,每片雪花由六个角组成,每个角都有长度. 第i片雪花六个角的长度从某个角开始顺时针依次记为ai,1,ai,2,…,ai,6ai,1,ai,2,…,ai,6. 因为雪花的形状是封闭的环形,所以 ...
- H5 video全屏与取消全屏兼容
H5 video全屏与取消全屏各浏览器兼容, requestFullscreen()全屏方法,exitFullscreen()退出全屏方法.兼容各个浏览器与css3兼容一样加个前缀即可. // 全屏 ...
- php 将几个变量合为数组,变量名和值对应
<?php $firstname = "Bill"; $lastname = "Gates"; $age = "60"; $resul ...
- Java内存模型之可见性问题
本博客系列是学习并发编程过程中的记录总结.由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅. 并发编程系列博客传送门 前言 之前的文章中讲到,JMM是内存模型规范在Java语 ...
- 深入理解java集合
集合 Java集合分为三大接口:①Collection ②Map ③Iterator
- 一、基础篇--1.2Java集合-ArrayList和Vector的区别
ArrayList和Vector的区别 ArrayList和Vector都是基于动态数组实现的. 区别 ArrayList是非线程安全的,Vector是线程安全的. Vector的方法都加了同步锁 ...
- 【flask】flask项目配置 app.config
[理论] 在很多情况下,你需要设置程序的某些行为,这时你就需要使用配置变量.在Flask中,配置变量就是一些大写形式的Python变量, 你也可以称之为配置参数或配置键.使用统一的配置变量可以避免在程 ...
- Linux_系统破坏性修复实验
目录 目录 修改系统用户密码 grub修复 系统修复 最后 修改系统用户密码 随便介绍一个修改Linux系统用户密码的方法. 步骤: 开机读秒时按任意键 进入grub列表项配置按e 选择系统kerne ...