Paxos协议理解
第三次报告: 理解Paxos协议
一、 Paxos协议背景
什么是Paxos协议?
一般地,从客户端和服务器的角度,任何一个分布式系统都可以理解成由一个服务器集合和一个客户端集合组成,一个或多个客户端向一个或多个服务器发送命令,服务器接收到命令后,执行相应操作以提供服务。可以将每个服务器建模成一个决定状态机(DSM:对任意输入只有唯一状态转移路径的状态机)。它具有自身的状态,在接收到客户端的命令后,作出相应的响应,进而状态发生转移。
现在考虑一个简单的存储数据A的服务。最简单的情况下,该服务对应的服务器集合只有一个元素,也就是说只有一个服务器负责处理来自客户端的对数据A的写入。这个服务器对应的状态机的状态可以定义为:数据A的值。当客户端的命令到来时,服务器状态机做出响应,并导致状态转移。即使有多个客户端发送命令,因为只有单个服务器且输入是离散的,因此只需要这个服务器决定执行哪个命令。
然而,当单个服务器出现故障甚至宕机,那么这个服务就会无法使用。为避免这种情况,负责数据A存储服务的服务器集合应该包含多个服务器,这样即使其中某(几)个服务器发生故障,其它服务器应当也能提供服务。这种当系统部分出错仍能提供服务的概念被称为错误容忍(Fault tolerant)。
现在,服务器集合中的每个服务器都要维护自己的状态机。每个状态机的状态都是自己那份数据A的值。显然,由于状态机是决定的,对于同一个来自客户端的命令序列,每一个状态机的状态转移序列也是相同的。对于不同的命令序列,状态机的状态转移序列就可能不不同,这时服务器集合中可能会出现多个不同的A的值的情况。这就是所谓的一致性(consistency)问题。为保证A的值的一致性,就需要保证每个正常的服务器的命令执行序列相同。具体地,假设一个服务器状态序列$S1,S2,...$,需要满足$\forall{i}, S_i\rightarrow S_{i+1}$的执行命令相同。
由于存在多个客户端,每个客户端通常对应一个服务器。因此当系统处于$S_i$状态时,可能有多个客户端同时向对应的服务器发送了不同的命令。因此就需要整个服务器集合决定执行某一个命令,这种分布式系统中多个节点对同一个命令达成一致的协议被称为共识(consensus)协议。而Paxos就是给出了这样一个共识协议,能够保证不同状态机对应状态在转移时,选择的转移操作相同,并且一旦协议执行完毕,即使某些节点宕机,仍能保证确定的转移操作不变。这样,最终A的值就能保证一致性。总的来说,Paxos是一个强一致性的共识协议。Paxos协议的意义
从上述存储单个数据A的角度看,Paxos协议的应用价值似乎并不是很高。但是,真正有价值的是Paxos能满足多个节点状态机状态转移操作的一致性。更精确地,Paxos完成了一个多机一致的有序的操作序列。而这种一致、有序的操作序列是很多系统所需要的,例如对于大多数分布式存储系统,通过AppendLog方式记录日志,当系统故障需要恢复存储时,就可以根据日志恢复到之前的正常状态。如果将每一次的log日志看成是状态转移时通过Paxos协议达成的转移操作的共识,那么通过Paxos就能实现多节点log日志序列的一致性,进而一致性的分布式存储服务必然不是问题。
二、Paxos协议推导
- 共识算法的目标
设想一个能够提交值的进程的集合,一个共识算法需要解决:- 从提交值集合中选择唯一一个值,
- 在一个值被选择后,所有进程最终都能了解到选择的值。
同时该算法还需要满足:
- 只有已经被提交的值能够被选择
- 只有一个值能被选择
- 只有一个值被选择之后,进程才能了解到被选择的值。
Paxos共识算法包含三类节点:能够提交值的节点被称为proposers(提交者),能够接收被提交值的节点被称为acceptors(接受者),另一类节点是learners
共识算法的设计
Paxos共识协议的设计过程也是协议的推导过程,推导基于基本的约束条件,并不断地推导约束条件的充分不必要条件,直到某个充分不必要条件在工程上易于实现
2.1 第一个目标:选择唯一一个值
共识算法的第一个目标是从提交值集合中选择一个值,容易想到可以使用唯一的一个接受者,每个提交者都将提议发送给这个接受者。该接受者采取自己的选择策略,或者只是简单的选择接收收到的第一个提议。然而,如果接受者出错,那么算法就无法继续进行。因此需要考虑多个接受者。
在多个接受者的情况下,为确保只有一个值被选择,Paxos要求这个值被超过半数的接受者接受,这被称为Quorom机制,即对一个数据的读/写操作执行之前必须有超过$N/2+1$个节点接受。这个机制能保证操作的唯一性,证明如下:如果某个值V被超过半数的接受者接受,由于任意两个超过半数的接受者集合必然有交集,因此每一个超过半数的接受者集合一定包含该值V,因此不存在一个超过半数的接受者集合均是非V的值。
最基本的情况下,Paxos算法希望即使只有一个提交者提交了一个值,这个值也应当能被选择。这引出了第一个约束条件:
约束条件 $P1$: 一个接受者必须接受它接收到的第一个提议。
然而,如果每个接受者只是接受一个提议的话,如果同时有多个提交者提交了不同的值,可能不存在一个超过半数的接受者集合它们接收到的提议的值相同。因此,接受者应当能接受多个提议。
定义提议(proposal) 如下:每一个提议包括一个序列号和一个值,不同的提议具有不同的序列号。序列号用于追踪提议的相对时间序。
定义数据被选择(chosen) 如下:当某个协议P被超过半数接受者接受时,就说P对应的值被选择,同时也说P被选择。
继续扩大充分条件的范围便于工程上实现:可以允许多个提议被选择,这意味着可以有多个协议被超过半数接受者接受。但是需要保证所有被选择的提议具有相同的值,这引出了第二个约束条件:
约束条件 $P2$: 如果一个值为v的提议被选择,则之后被接受的提议都有值v。
为满足该约束条件,其充分条件a为:
充分条件a $P2^{a}$: 如果一个值为v的提议被选择,则之后被接受的提议都具有值v。
但是该充分条件和$P1$有冲突,例如:在一个值为v的提议被选择后,一个新启动的提交者在不知道v被选择的情况下发出了一个值不为v的提议。根据$P1$,该提议需要被接受,但根据$P2^{a}$,该提议不能被接受。因此继续加强充分条件,得到充分条件b:
充分条件b $P2^{b}$: 如果一个值为v的提议被选择,则之后提交的提议都具有值v。
因为提交先于接受,因此如果提交的提议都满足值为v,则接受也能满足值为v。现通过证明充分条件b的方式,同时给出使充分条件b满足的充分条件c。证明:假设值为v,序列号为m的协议被选择。若满足充分条件c,则对发出的任意序列号为$n>m$的协议都具有值v
证:
由假设,因为值为v,序列号为m的协议被选择,因此存在集合C其中每个接受者都接受了$(m,v)$,且$|C|$超过半数接受者。对$n=m+1, m+2, m+3, ...$进行归纳:
假设序列号为$m...(n-1)$的提议值都为v,则对C中每一个接受者都接受了至少一个提议其序列号属于$m..(n-1)$,且它们值均为v。因此,任意一个超过半数的接受者集合K中至少含有一个集合C中的接受者,而这些C中的接受者能保证序列号比n小的K中第一个提议值为v,因此若序列号为n的提议取值为序列号比n小的K中第一个提议的值,则可以满足原命题,并且这种方式在工程上易于实现。给出充分条件c:
充分条件c $P2^{c}$: 对于任意的v和n,如果一个提议(n,v)被发出,则存在一个超过半数集合S满足,要么(a)S中接受者没有接受序列号比n小的提议,要么(b)v的值等于S中第一个序列号小于n的协议的值。
这个充分条件中:(a)保证了n发出时,一定没有提议被选择,否则S中一定存在序列号比n小的提议.(b)保证了如果n发出时,有提议被选中,自己选择的一定是被选中的提议的值,如果没有提议被选中,当然自己选择的一定不是被选中的提议的值,不过没有影响。
由于充分条件c中(b)情况下,要求v的值等于S中第一个序列号小于n的协议的值,但是由于系统中网络延时的问题,可能S接受的第一个序列号小于n的协议的值在n发出后一段时间,才到S并被S接受。因此,这个充分条件会涉及未来的情况。考虑进一步对接受者施加约束,要求接受者未来不会再接受序列号小于n的协议,这样就能保证满足充分条件c,并且序列号为n的协议的取值就只需要基于当前接受者已经接受的值就行了。
至此,提交者的算法已经推导完毕。简略地说,提交者的算法有两个步骤:
1. prepare阶段:首先,提交者向一个超过半数的集合发送请求,要求接受者未来不会再接受序列号小于n的协议,同时要求接受者传回序列号小于n的第一个协议的值。
2. accept阶段:接着,如果有超过半数集合返回响应,则提交者就可以根据响应分配v的为响应中序列号最大的协议的值,否则若响应中均不含该值,则提交者可以任意选择v的值。
而对于接受者,由于接受者是被提交者被动推进的,因此接受者只需满足提交者需要的条件,即对未来接受的协议的序列号的限制,对于那个限制之外的提议,接受者都可以接受。这引出了约束条件1的充分条件a:
充分条件a $P1^{a}$: 一个接受者可以接受序列号为n的提议,当且仅当它没有响应一个只能接受大于序列号为n的提议的prepare请求。
接下来是算法设计中的几个优化:- 如果接受者已经响应过一个"只能接受序列号大于n"的prepare请求,那么它可以忽略"只能接受序列号大于$a(a<=n)$"的请求,因为后者的提议一定不会得到accept
这样,接受者只需要保证自己具有最大的可接收下界的值的信息即可,并且该信息需要永久性存储。
2.2 共识算法的过程
Phase 1.
(a) 一个提交者选择一个协议号n并发送一个携带有n值的prepare请求给某个超过半数的接受者集合
(b) 如果值n大于接受者当前的可接受上界,接受者更改可接收上界,并且向提交者返回信息
Phase 2.
(a) 如果提交者收到超过半数的接受者的响应,就发送accept请求给这些响应的发出者,accept请求携带的值取决于提交者收到的接受者的响应中的值
(b) 接受者接收到了一个accept请求,如果该请求的值满足其可接受上界的限制,则接受者接受该值
2.3 共识算法的第二个目标:进程最终都能了解到选择的值
共识算法的第二个目标是要求进程最终都能了解到被选择的值。这引入了新的角色:Learner。为了确定被选择的值,要求acceptor在接受了某个值之后向learner报告。和有多个proposer和多个acceptor的原因类似,系统中也存在多个learner。
为满足第二个目标,一个简单的实现是:每当一个acceptor接受了一个值,就向每一个learner发一条消息。但是这样需要发送$|acceptor|*|learner|$条消息,开销太大。
也可以考虑acceptor只向唯一一个learner(即distinguished leader)发送消息。然后这个learner通知其它的learner该信息。不过,由于learner存在出现故障的可能,因此可靠性不是很好
当然也可以让acceptor向一个learner集合发送消息,这样可靠性更好。总之acceptor发送消息到learner的个数,取决于延迟和可靠性的折中。
- 如果接受者已经响应过一个"只能接受序列号大于n"的prepare请求,那么它可以忽略"只能接受序列号大于$a(a<=n)$"的请求,因为后者的提议一定不会得到accept
共识算法的实现
3.1 共识算法的优化-加入Leader
原始的Paxos算法允许有多个proposer,并能保证在多个proposer提交提议的情况下的一致性。但是,当proposer的数量增加,共识达成过程中不同提议冲突的概率也增加了。因此为改善性能,在实现中通常会选举一个Leader,当proposer接受到客户端的请求后,proposer首先将请求发送给Leader,这样先由Leader处理,能减小冲突的概率并提高性能。同时,即使Leader宕机,由于Paxos算法本身能够保证多个proposer的情况下系统的一致性,因此不会影响一致性。3.2 共识算法实现总结
Paxos算法设想一个进程集合。在实现中,每一个进程同时扮演proposer、acceptor、learner的角色。并且算法需要选举出一个Leader,同时作为distinguished proposer和distinguished learner的角色。
三、Paxos协议工业界实践:PaxosStore
由于主要目的是学习和理解Paxos算法,因此下文对"PaxosStore"的分析主要集中于它的Consensus Layer的设计和实现,以及该层是如何利用Paxos算法的
- 背景
微信的后台依赖各种不同的功能组件向用户提供服务,例如:瞬时的短信、社交网络、移动支付等。这些功能组件通常都需要可靠的存储以支持它们的实现。最初,各个子系统组件部署的是各自的现成的存储系统,各种各样碎片化的存储系统带来了下列问题:- 难以维护
- 难以扩展
因此基本的想法是应用一个全局的存储系统,并能服务不同的微信的业务逻辑。微信的业务组件具有以下通用的需求:- 数据的数量、生成速度、种类都在飞速增长,并且系统对数据通常是以单条记录的形式进行访问
- 存储服务首要考虑的是可用性,并且有严格的延迟限制
PaxosStore就是作为微信后台的高可靠、全局的存储系统而设计和实现的。
- 系统架构
PaxosStore的系统架构采用分层设计,如下图所示主要分为三层:- The Programming model(编程模型): 向外部应用程序提供各种数据结构
- The Consensus layer(共识层): 实现了基于Paxos的存储协议
- The Storage layer(存储层): 基于不同的存储模型实现了多个存储引擎
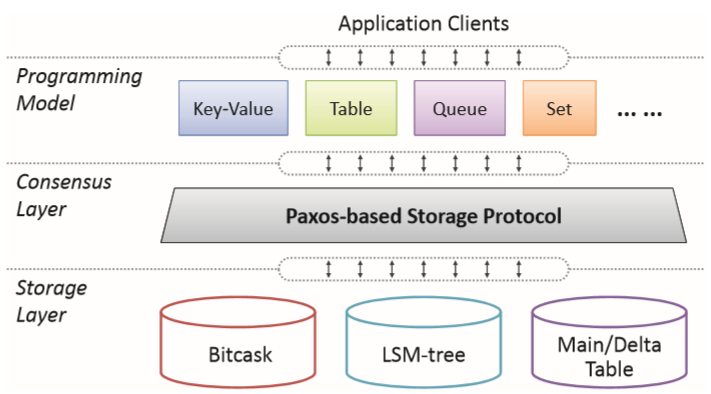
这种架构和以往的不同之处以及优势之处主要在于
- PaxosStore单独将共识协议作为中间件来实现以提供全局的数据共识保证
- PaxosStore避免了传统分布式存储系统不同存储子模块分治管理自己数据共识的复杂性和易错性
- PaxosStore使用组合存储设计使得在存储层实现多个存储模型
- PaxosStore组合存储设计避免了跨数据模型访问数据时需要独立实现共识算法的问题
- 由于Consensus Layer解耦了存储层数据共识的实现,因此存储层更容易为数据可用性作出优化
- Consensus Layer(共识层)
3.1 Paxos实现
因为是存储系统,Paxos算法主要用于保证存储于多个节点的数据备份的强一致性。具体地,PaxosStore中利用Paxos算法保证不同节点数据日志(PaxosLog)的相同的持久化存储序列。不同于传统Paxos算法基于状态机的描述,PaxosStore使用半对称的消息传递的方式进行描述。不同数据备份节点间的共识通过相互之间的各自节点的状态的消息传递来实现。
首先定义提议$P$为$P=(m,v)$表示该提议序列号为m,值为v。每个节点x的状态定义为$S{^{x}{x}}=(n, (m, v))=(n, P)$
表示节点x承诺了不会接受比n小的提议,且接受了提议{m, v}。同时每个节点在内存中维护其它数据备份节点的状态镜像,例如节点X中维护的Y的状态镜像表示为$S^{X}{Y}$。- 在prepare阶段:
- $Issue(m_i):$ 要发出提议的节点$N_{A}$首先确定一个序列号,并且向本地acceptor提交,在通过之后先更新本地状态、写日志、并向远程的每一个数据拷贝节点发送本地状态和镜像状态。
- $OnMessage(M_{x->y)}:$ 远程acceptor节点接收到prepare的请求后,首先更新本地状态和镜像状态,如果本地状态能够更新则写日志,同时判断如果镜像状态满足prepare请求的节点数超过半数则提交日志,即给出最小接受提议序列号下界的承诺。同时若发现proposer节点的镜像状态是就状态则将本地状态发送给proposer节点
- 在accept阶段:
- $Issue(P_i)$: 当proposer节点注意到超过半数的状态镜像的承诺和当前提议的序列号相同,则发起accept请求
- $OnMessage(M_{x->y})$:当acceptor本地状态内的$P$提议得到更新,则说明接受者接受了该提议,并写日志且提交日志
同时,提议的发起者会维持一个时间计数,如果在时间限制内不能达成一致。则超时后,proposer会选择一个更大的序列号,并重启Paxos过程。
3.2 PaxosLog实现
- 在prepare阶段:
四、参考文献
Paxos协议理解的更多相关文章
- 四:分布式事务一致性协议paxos通俗理解
转载地址:http://www.lxway.com/4618606.htm 维基的简介:Paxos算法是莱斯利·兰伯特(Leslie Lamport,就是 LaTeX 中的"La" ...
- 理解分布式一致性:Paxos协议之Generalized Paxos & Byzantine Paxos
理解分布式一致性:Paxos协议之Generalized Paxos & Byzantine Paxos Generalized Paxos Byzantine Paxos Byzantine ...
- 理解分布式一致性:Paxos协议之Cheap Paxos & Fast Paxos
理解分布式一致性:Paxos协议之Cheap Paxos & Fast Paxos Cheap Paxos Message flow: Cheap Multi-Paxos Fast Paxos ...
- 理解分布式一致性:Paxos协议之Multi-Paxos
理解分布式一致性:Paxos协议之Multi-Paxos Multi-Paxos without failures Multi-Paxos when phase 1 can be skipped Mu ...
- 理解分布式一致性:Paxos协议之Basic Paxos
理解分布式一致性:Paxos协议之Basic Paxos 角色 Proposal Number & Agreed Value Basic Paxos Basic Paxos without f ...
- 11张PPT介绍Paxos协议
之前翻译了<The Part-Time Parliament>一文,论文非常经常,强烈推荐读一读原文.翻译完论文后,希望自己能用简单的描述来整理自己的理解,所以花了一些时间通过PPT的形式 ...
- paxos协议(1)-朴素paxos
前言 学习paxos协议,最困惑我的两点是: 1. 朴素paxos是怎么样的?这部分主要是原理: 2. paxos协议是怎么运用到分布式系统解决问题的.因为很多博客的开篇说paxos协议可以运用在很多 ...
- Paxos协议超级详细解释+简单实例
转载自: https://blog.csdn.net/cnh294141800/article/details/53768464 Paxos协议超级详细解释+简单实例 Basic-Paxos算法 ...
- IIC协议理解(转)
目录 IIC协议理解(转) 个人小结记录 (记一下这个就够了) 以下为转载记录 概述 概述 输出级 主设备与从设备 速率 时序 空闲状态 起始位与停止位 数据的有效性 数据的传送 工作过程 主设备向从 ...
随机推荐
- Libraries&Workflow for a modern geospatial processing(现代地理空间处理的库与工作流)
Libraries for a modern geospatial workflow现代地理空间工作的类库 Distribution Writing, Running, and Distributin ...
- max函数结合lambda使用
说明:d.keys() 以及列表可以看做lambda函数的实参,max的判断对象是key的值.最终返回的是使得key的值最大的那个实参.
- Miniui 表单验证
自定义表单验证: input输入框的表单验证可通过vtype和onvalidation事件两种方式实现 可编辑列表(例如div)的表单验证只能通过vtye来实现表单验证 (1)vtype方式: jsp ...
- LeetCode 129. 求根到叶子节点数字之和(Sum Root to Leaf Numbers)
题目描述 给定一个二叉树,它的每个结点都存放一个 0-9 的数字,每条从根到叶子节点的路径都代表一个数字. 例如,从根到叶子节点路径 1->2->3 代表数字 123. 计算从根到叶子节点 ...
- windows spark1.6
jdk1.7 scala 2.10.5 spark 1.6.1 http://spark.apache.org/downloads.html hadoop 2.6.4 只需要留bin https:// ...
- 【编程漫谈】Hello world!
Hello world!是打开编程世界的第一把钥匙,只要你能运行出Hello world!,基本上就算入了个门了,因为程序正确的运行代表着基本开发环境都有了,包括编辑器,编译器,解释器,运行环境等待, ...
- 浏览器端-W3School-HTML:HTML DOM Style 对象
ylbtech-浏览器端-W3School-HTML:HTML DOM Style 对象 1.返回顶部 1. HTML DOM Style 对象 Style 对象 Style 对象代表一个单独的样式声 ...
- 常用 tcpdump 抓包方式
目录 文章目录 目录 tcpdump 指令 关键字 常用指令选项 常规操作示例 过滤主机 过滤端口 过滤网络(网段) 过滤协议 复杂的逻辑表达式过滤条件 参考资料 tcpdump 指令 tcpdump ...
- 阶段3 2.Spring_08.面向切面编程 AOP_4 spring基于XML的AOP-配置步骤
resources下新建bean.xml文件 xmlns:aop 先配置IOC aop 通知类就是logger.id配置为logAdvice表示日志的通知 梳理流程 首先我们在这有个Service它需 ...
- Redis 入门 3.3 散列类型
3.3.1 介绍 散列类型(hash)的键值也是一种字典结构,其储存了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,散列类型不能嵌套其他的数据类型.一个散列 ...