spark高级排序彻底解秘
排序,真的非常重要!
RDD.scala(源码)
在其,没有罗列排序,不是说它不重要!
本博文的主要内容有:
1、基础排序算法实战
2、二次排序算法实战
3、更高级别排序算法
4、排序算法内幕解密
1、基础排序算法实战
启动hdfs集群
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh

启动spark集群
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
启动spark-shell

spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell --master spark://SparkSingleNode:7077 --executor-memory 1g
scala> sc.setLogLevel("WARN") //过滤日志提醒
scala> sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).map(pair => (pair._2,pair._1)).sortByKey(false).map(pair => (pair._2,pair._1)).collect

scala> sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).map(pair => (pair._2,pair._1)).sortByKey(false).map(pair => (pair._2,pair._1)).collect
res2: Array[(String, Int)] = Array(("",67), (the,21), (Spark,14), (to,14), (for,12), (a,10), (and,10), (##,8), (run,7), (is,6), (on,6), (can,6), (of,5), (also,5), (in,5), (if,4), (or,4), (Hadoop,4), (with,4), (you,4), (build,3), (including,3), (Please,3), (use,3), (particular,3), (documentation,3), (example,3), (an,3), (You,3), (building,3), (that,3), (guidance,3), (For,2), (This,2), (Hive,2), (To,2), (SparkPi,2), (refer,2), (Interactive,2), (be,2), (./bin/run-example,2), (1000:,2), (tests,2), (examples,2), (at,2), (using,2), (Shell,2), (class,2), (`examples`,2), (set,2), (Hadoop,,2), (cluster,2), (supports,2), (Python,2), (general,2), (locally,2), (following,2), (which,2), (should,2), ([project,2), (do,2), (how,2), (It,2), (Scala,2), (detailed,2), (return,2), (one,2), (Python,,2), (SQL...
scala>
则,可看出,是sortByKey(false)是按key排序且降序.
sortByKey源码
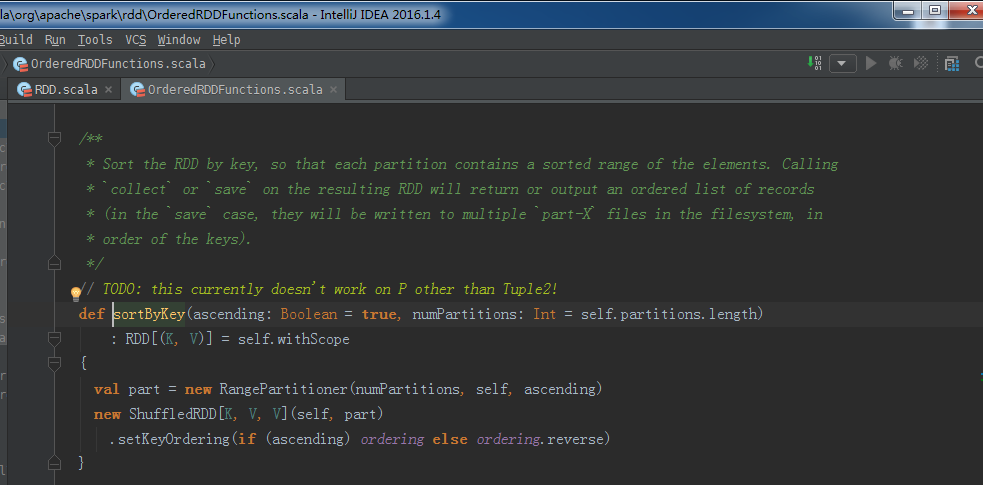
/**
* Sort the RDD by key, so that each partition contains a sorted range of the elements. Calling
* `collect` or `save` on the resulting RDD will return or output an ordered list of records
* (in the `save` case, they will be written to multiple `part-X` files in the filesystem, in
* order of the keys).
*/
// TODO: this currently doesn't work on P other than Tuple2!
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
由此,可看出,一旦排序,则产生ShuffledRDD。
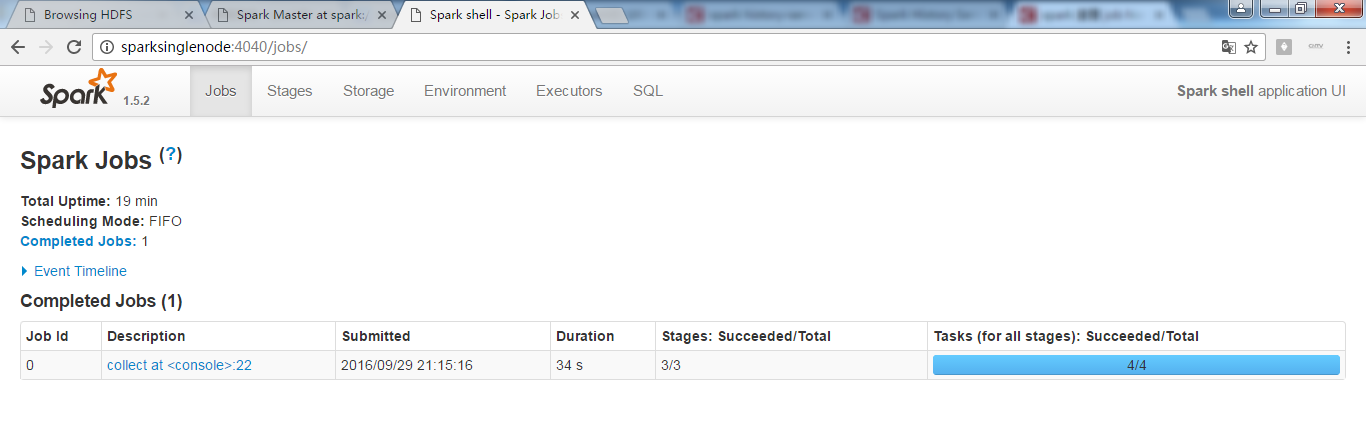
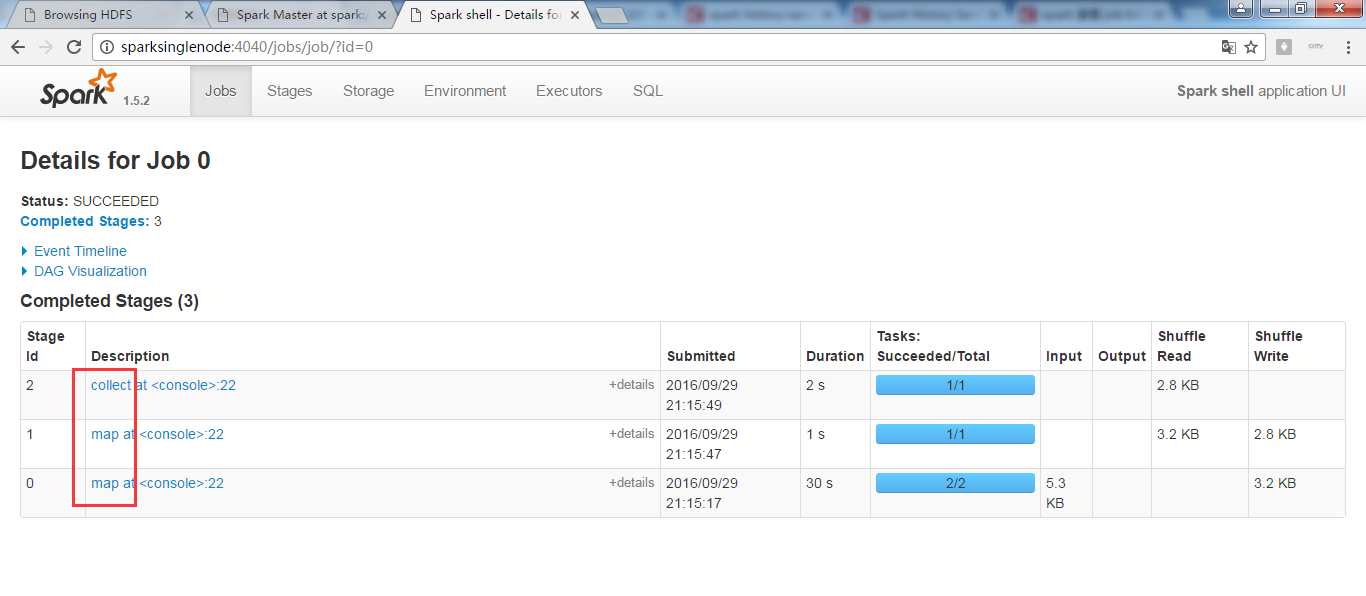
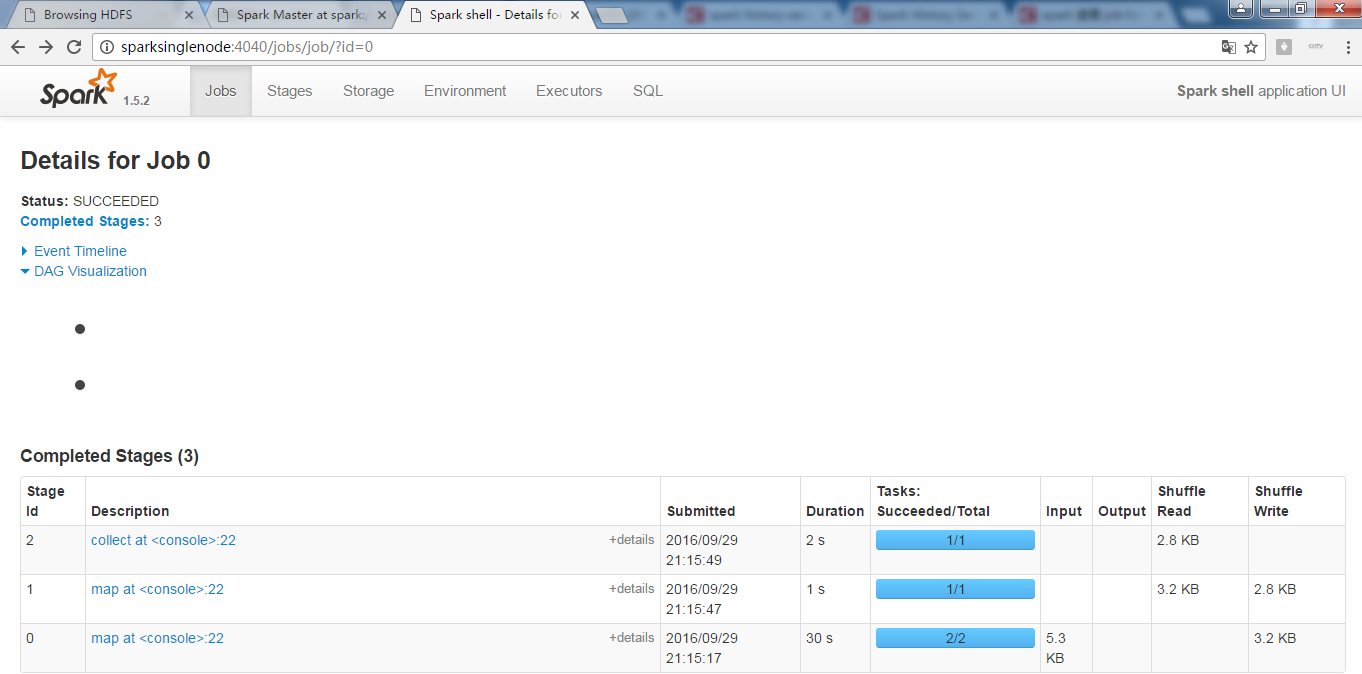
为什么我的是没显示出来?

rangPartition是怎么排序的呢?
好的,基础排序算法实战至此。
2、二次排序算法实战
所谓,二次排序,就是指排序的时候考虑两个维度。
如,在第一列,按照降序排,第一列的key相同,那么,再怎么排呢?则,考虑第二列,按照降序排。即,用到了二次排序。
准备

【数据文件Input】
2 3
4 1
3 2
4 3
8 7
2 1
【运行结果Output】
2 1
2 3
3 2
4 1
4 3
8 7
如果是去大公司的话,则要掌握,5个维度,甚至8个维度,而不是才2个维度而已。加油!zhouls。
这里,就用,Scala IDE for Eclipse,来写,
Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)


SecondarySortKey.java

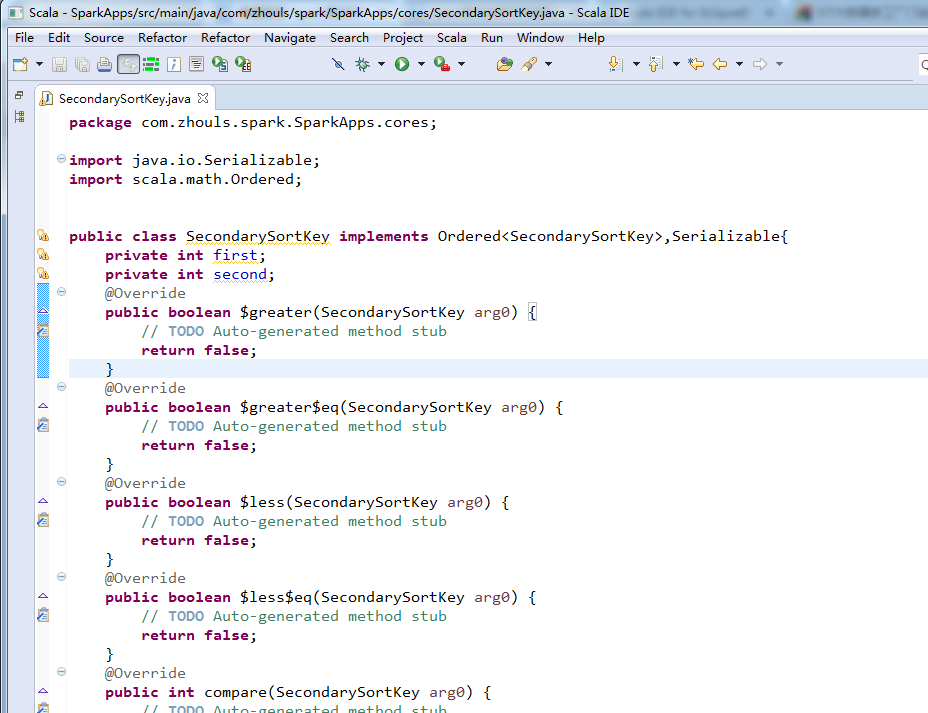
package com.zhouls.spark.SparkApps.cores; import java.io.Serializable;
import scala.math.Ordered; public class SecondarySortKey implements Ordered<SecondarySortKey>,Serializable{
private int first;
private int second; @Override
public boolean $greater(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return false;
} @Override
public boolean $greater$eq(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return false;
} @Override
public boolean $less(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return false;
} @Override
public boolean $less$eq(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return false;
} @Override
public int compare(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return 0;
} @Override
public int compareTo(SecondarySortKey arg0) {
// TODO Auto-generated method stub
return 0;
}
}
在这里,学下技巧。

然后,修改成我们自己想要的。
最终的SecondarySortKey.java如下:
package com.zhouls.spark.SparkApps.cores; import java.io.Serializable;
import scala.math.Ordered; public class SecondarySortKey implements Ordered<SecondarySortKey>,Serializable{
private int first;
private int second; //二次排序的公开构造器
public SecondarySortKey(int first,int second){
this.first=first;
this.second=second;
} public boolean $greater(SecondarySortKey other) {
if(this.first>other.getFirst()){
return true;
}else if(this.first==other.getFirst()&&this.second>other.getSecond()){
return true;
}
return false;
} public boolean $greater$eq(SecondarySortKey other) {
if(this.$greater(other)){
return true;
}else if(this.first==other.getFirst()&&this.second==other.getSecond()){
return true;
}
return false;
} public boolean $less(SecondarySortKey other) {
if(this.first<other.getFirst()){
return true;
}else if(this.first==other.getFirst()&&this.second<other.getSecond()){
return true;
}
return false;
} public boolean $less$eq(SecondarySortKey other) {
if(this.$less(other)){
return true;
}else if(this.first==other.getFirst()&&this.second==other.getSecond()){
return true;
}
return false;
} public int compare(SecondarySortKey other) {
if(this.first-other.getFirst() !=0){
return this.first-other.getFirst();
}else{
return this.second-other.getSecond();
}
} public int compareTo(SecondarySortKey other) {
if(this.first-other.getFirst() !=0){
return this.first-other.getFirst();
}else{
return this.second-other.getSecond();
}
} public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + first;
result = prime * result + second;
return result;
} public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
SecondarySortKey other = (SecondarySortKey) obj;
if (first != other.first)
return false;
if (second != other.second)
return false;
return true;
} public int getFirst() {
return first;
} public void setFirst(int first) {
this.first = first;
} public int getSecond() {
return second;
} public void setSecond(int second) {
this.second = second;
}
}
package com.zhouls.spark.SparkApps.cores; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; /*
* 二次排序,具体的实现步骤:
* 第一步:安装Ordered和Serrializable接口实现自定义排序的key
* 第二步:将要进行二次排序的文件加载进来<key,value>类型的RDD
* 第三步:使用sortByKey基于自定义的Key进行二次排序
* 第四步:去除掉排序的Key,只保留排序的结果
*/
public class SecondarySortApp {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("SecondarySortApp").setMaster("local");
JavaSparkContext sc=new JavaSparkContext(conf);//其底层实际上就是Scala的SparkContext
JavaRDD<String> lines = sc.textFile("D://SoftWare//spark-1.5.2-bin-hadoop2.6//helloSpark.txt");
JavaPairRDD<SecondarySortKey, String> pairs = lines.mapToPair(new PairFunction<String, SecondarySortKey, String>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<SecondarySortKey, String> call(String line) throws Exception {
String[] splited = line.split(" ");
SecondarySortKey key =new SecondarySortKey(Integer.valueOf(splited[0]),Integer.valueOf(splited[1]));
return new Tuple2<SecondarySortKey,String>(key,line);
}
}); JavaPairRDD<SecondarySortKey, String> sorted = pairs.sortByKey(); //过滤掉排序后自定的Key,保留排序的结果
JavaRDD<String> SecondaySorted=sorted.map(new Function<Tuple2<SecondarySortKey,String>, String>() { private static final long serialVersionUID = 1L; @Override
public String call(Tuple2<SecondarySortKey, String> sortedContent) throws Exception { System.out.println("sortedContent._1 "+(sortedContent._1).toString());
System.out.println("sortedContent._2 "+sortedContent._2); return sortedContent._2;
}
});
SecondaySorted.foreach(new VoidFunction<String>() { @Override
public void call(String sorted) throws Exception {
System.out.println(sorted);
}
}); }
}
Scala


package com.zhouls.spark.cores /**
* Created by Administrator on 2016/9/30.
*/
class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable {
def compare(that: SecondarySortKey): Int = {
if(this.first-that.first!=0){
return this.first-that.first
}else{
return this.second-that.second
}
}
}

package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/30.
* 二次排序:具体的实现步骤:
* 第一步:按照Ordered和Serrializable接口实现自定义排序的Key
* 第二步:将要进行二次排序的文件加载进来< key,value> 类型的RDD
* 第三步:使用sortByKey基于自定义的Key进行二次排序
* 第四步:去除掉排序的Key,只保留排序的结果
*/
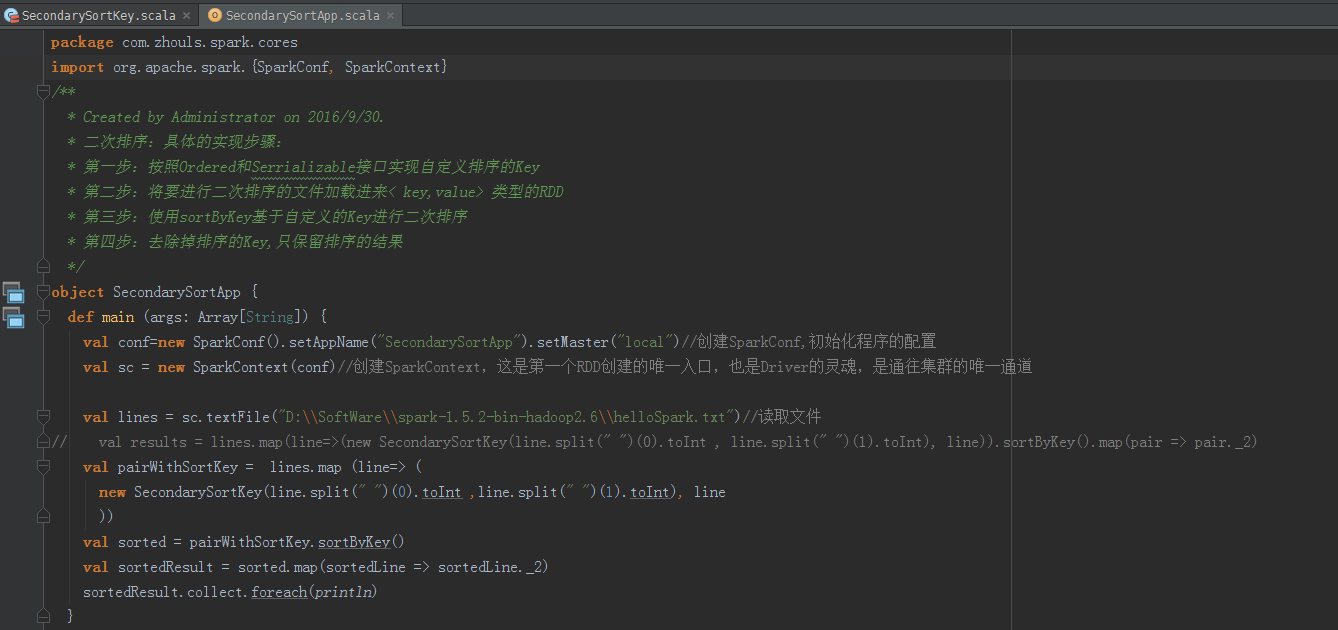
object SecondarySortApp {
def main (args: Array[String]) {
val conf=new SparkConf().setAppName("SecondarySortApp").setMaster("local")//创建SparkConf,初始化程序的配置
val sc = new SparkContext(conf)//创建SparkContext,这是第一个RDD创建的唯一入口,也是Driver的灵魂,是通往集群的唯一通道 val lines = sc.textFile("D:\\SoftWare\\spark-1.5.2-bin-hadoop2.6\\helloSpark.txt")//读取文件
// val results = lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt , line.split(" ")(1).toInt), line)).sortByKey().map(pair => pair._2)
val pairWithSortKey = lines.map (line=> (
new SecondarySortKey(line.split(" ")(0).toInt ,line.split(" ")(1).toInt), line
))
val sorted = pairWithSortKey.sortByKey()
val sortedResult = sorted.map(sortedLine => sortedLine._2)
sortedResult.collect.foreach(println)
} }
作业:
1:Scala实现二次排序
SecondarySortKey.scala的完整代码:
class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable{
override def compare(that: SecondarySortKey): Int = {
if(this.first-that.first!=0){
return this.first-that.first
}else{
return this.second-that.second
}
}
}
object SecondarySortKey extends scala.AnyRef with Serializable{
def apply(first:Int,second:Int): SecondarySortKey ={
new SecondarySortKey(first,second)
}
}
SecondarySortApp.scala的完整代码:
object SecondarySortApp {
def main (args: Array[String]) {
val conf=new SparkConf().setAppName("SecondarySortApp").setMaster("local")
val sc=new SparkContext(conf)
val lines=sc.textFile("D:\\SoftWare\\spark-1.5.2-bin-hadoop2.6\\helloSpark.txt")
//val results=lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line)).sortByKey().map(pair=>pair._2)
val results=lines.map(line=>(SecondarySortKey.apply(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line)).sortByKey().map(pair=>pair._2)
results.collect.foreach(println)
}
}
2:RangePartitioner的源码阅读:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark import java.io.{IOException, ObjectInputStream, ObjectOutputStream} import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
import scala.reflect.{ClassTag, classTag}
import scala.util.hashing.byteswap32 import org.apache.spark.rdd.{PartitionPruningRDD, RDD}
import org.apache.spark.serializer.JavaSerializer
import org.apache.spark.util.{CollectionsUtils, Utils}
import org.apache.spark.util.random.{XORShiftRandom, SamplingUtils} /**
* An object that defines how the elements in a key-value pair RDD are partitioned by key.
* Maps each key to a partition ID, from 0 to `numPartitions - 1`.
*/
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
} object Partitioner {
/**
* Choose a partitioner to use for a cogroup-like operation between a number of RDDs.
*
* If any of the RDDs already has a partitioner, choose that one.
*
* Otherwise, we use a default HashPartitioner. For the number of partitions, if
* spark.default.parallelism is set, then we'll use the value from SparkContext
* defaultParallelism, otherwise we'll use the max number of upstream partitions.
*
* Unless spark.default.parallelism is set, the number of partitions will be the
* same as the number of partitions in the largest upstream RDD, as this should
* be least likely to cause out-of-memory errors.
*
* We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD.
*/
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined && r.partitioner.get.numPartitions > 0) {
return r.partitioner.get
}
if (rdd.context.conf.contains("spark.default.parallelism")) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
} /**
* A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using
* Java's `Object.hashCode`.
*
* Java arrays have hashCodes that are based on the arrays' identities rather than their contents,
* so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will
* produce an unexpected or incorrect result.
*/
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.") def numPartitions: Int = partitions def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
} override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
} override def hashCode: Int = numPartitions
} /**
* A [[org.apache.spark.Partitioner]] that partitions sortable records by range into roughly
* equal ranges. The ranges are determined by sampling the content of the RDD passed in.
*
* Note that the actual number of partitions created by the RangePartitioner might not be the same
* as the `partitions` parameter, in the case where the number of sampled records is less than
* the value of `partitions`.
*/
class RangePartitioner[K : Ordering : ClassTag, V](
@transient partitions: Int,
@transient rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner { // We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.") private var ordering = implicitly[Ordering[K]] // An array of upper bounds for the first (partitions - 1) partitions
private var rangeBounds: Array[K] = {
if (partitions <= 1) {
Array.empty
} else {
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
val sampleSize = math.min(20.0 * partitions, 1e6)
// Assume the input partitions are roughly balanced and over-sample a little bit.
val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.size).toInt
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
if (numItems == 0L) {
Array.empty
} else {
// If a partition contains much more than the average number of items, we re-sample from it
// to ensure that enough items are collected from that partition.
val fraction = math.min(sampleSize / math.max(numItems, 1L), 1.0)
val candidates = ArrayBuffer.empty[(K, Float)]
val imbalancedPartitions = mutable.Set.empty[Int]
sketched.foreach { case (idx, n, sample) =>
if (fraction * n > sampleSizePerPartition) {
imbalancedPartitions += idx
} else {
// The weight is 1 over the sampling probability.
val weight = (n.toDouble / sample.size).toFloat
for (key <- sample) {
candidates += ((key, weight))
}
}
}
if (imbalancedPartitions.nonEmpty) {
// Re-sample imbalanced partitions with the desired sampling probability.
val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)
val seed = byteswap32(-rdd.id - 1)
val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()
val weight = (1.0 / fraction).toFloat
candidates ++= reSampled.map(x => (x, weight))
}
RangePartitioner.determineBounds(candidates, partitions)
}
}
} def numPartitions: Int = rangeBounds.length + 1 private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K] def getPartition(key: Any): Int = {
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <= 128) {
// If we have less than 128 partitions naive search
while (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {
partition += 1
}
} else {
// Determine which binary search method to use only once.
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition < 0) {
partition = -partition-1
}
if (partition > rangeBounds.length) {
partition = rangeBounds.length
}
}
if (ascending) {
partition
} else {
rangeBounds.length - partition
}
} override def equals(other: Any): Boolean = other match {
case r: RangePartitioner[_, _] =>
r.rangeBounds.sameElements(rangeBounds) && r.ascending == ascending
case _ =>
false
} override def hashCode(): Int = {
val prime = 31
var result = 1
var i = 0
while (i < rangeBounds.length) {
result = prime * result + rangeBounds(i).hashCode
i += 1
}
result = prime * result + ascending.hashCode
result
} @throws(classOf[IOException])
private def writeObject(out: ObjectOutputStream): Unit = Utils.tryOrIOException {
val sfactory = SparkEnv.get.serializer
sfactory match {
case js: JavaSerializer => out.defaultWriteObject()
case _ =>
out.writeBoolean(ascending)
out.writeObject(ordering)
out.writeObject(binarySearch) val ser = sfactory.newInstance()
Utils.serializeViaNestedStream(out, ser) { stream =>
stream.writeObject(scala.reflect.classTag[Array[K]])
stream.writeObject(rangeBounds)
}
}
} @throws(classOf[IOException])
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {
val sfactory = SparkEnv.get.serializer
sfactory match {
case js: JavaSerializer => in.defaultReadObject()
case _ =>
ascending = in.readBoolean()
ordering = in.readObject().asInstanceOf[Ordering[K]]
binarySearch = in.readObject().asInstanceOf[(Array[K], K) => Int] val ser = sfactory.newInstance()
Utils.deserializeViaNestedStream(in, ser) { ds =>
implicit val classTag = ds.readObject[ClassTag[Array[K]]]()
rangeBounds = ds.readObject[Array[K]]()
}
}
}
} private[spark] object RangePartitioner { /**
* Sketches the input RDD via reservoir sampling on each partition.
*
* @param rdd the input RDD to sketch
* @param sampleSizePerPartition max sample size per partition
* @return (total number of items, an array of (partitionId, number of items, sample))
*/
def sketch[K : ClassTag](
rdd: RDD[K],
sampleSizePerPartition: Int): (Long, Array[(Int, Int, Array[K])]) = {
val shift = rdd.id
// val classTagK = classTag[K] // to avoid serializing the entire partitioner object
val sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>
val seed = byteswap32(idx ^ (shift << 16))
val (sample, n) = SamplingUtils.reservoirSampleAndCount(
iter, sampleSizePerPartition, seed)
Iterator((idx, n, sample))
}.collect()
val numItems = sketched.map(_._2.toLong).sum
(numItems, sketched)
} /**
* Determines the bounds for range partitioning from candidates with weights indicating how many
* items each represents. Usually this is 1 over the probability used to sample this candidate.
*
* @param candidates unordered candidates with weights
* @param partitions number of partitions
* @return selected bounds
*/
def determineBounds[K : Ordering : ClassTag](
candidates: ArrayBuffer[(K, Float)],
partitions: Int): Array[K] = {
val ordering = implicitly[Ordering[K]]
val ordered = candidates.sortBy(_._1)
val numCandidates = ordered.size
val sumWeights = ordered.map(_._2.toDouble).sum
val step = sumWeights / partitions
var cumWeight = 0.0
var target = step
val bounds = ArrayBuffer.empty[K]
var i = 0
var j = 0
var previousBound = Option.empty[K]
while ((i < numCandidates) && (j < partitions - 1)) {
val (key, weight) = ordered(i)
cumWeight += weight
if (cumWeight > target) {
// Skip duplicate values.
if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {
bounds += key
target += step
j += 1
previousBound = Some(key)
}
}
i += 1
}
bounds.toArray
}
}
参考 :
http://blog.sina.com.cn/s/blog_4a7854d90102ws97.html
http://blog.csdn.net/duan_zhihua/article/details/50761582
spark高级排序彻底解秘的更多相关文章
- Python中的高级数据结构详解
这篇文章主要介绍了Python中的高级数据结构详解,本文讲解了Collection.Array.Heapq.Bisect.Weakref.Copy以及Pprint这些数据结构的用法,需要的朋友可以参考 ...
- 【高级排序算法】1、归并排序法 - Merge Sort
归并排序法 - Merge Sort 文章目录 归并排序法 - Merge Sort nlogn 比 n^2 快多少? 归并排序设计思想 时间.空间复杂度 归并排序图解 归并排序描述 归并排序小结 参 ...
- javascript数据结构与算法--高级排序算法
javascript数据结构与算法--高级排序算法 高级排序算法是处理大型数据集的最高效排序算法,它是处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个.现在我们来学习下2种高级排序算法-- ...
- 处理海量数据的高级排序之——希尔排序(C++)
希尔算法简介 ...
- Java数据结构和算法 - 高级排序
希尔排序 Q: 什么是希尔排序? A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法. A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插 ...
- javascript高级排序算法之快速排序(快排)
javascript高级排序算法之快速排序(快排)我们之前讨论了javascript基本排序算法 冒泡排序 选择排序 插入排序 简单复习: 冒泡排序: 比较相邻的两个元素,如果前一个比后一个大,则交换 ...
- Oracle 高级排序函数 和 高级分组函数
高级排序函数: [ ROW_NUMBER()| RANK() | DENSE_RANK ] OVER (partition by xx order by xx) 1.row_number() 连续且递 ...
- 【Python】 sort、sorted高级排序技巧
文章转载自:脚本之家 这篇文章主要介绍了python sort.sorted高级排序技巧,本文讲解了基础排序.升序和降序.排序的稳定性和复杂排序.cmp函数排序法等内容,需要的朋友可以参考下 Pyth ...
- javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法)
javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法) 一.快速排序算法 /* * 这个函数首先检查数组的长度是否为0.如果是,那么这个数组就不需要任何排序,函数直接返回. * ...
随机推荐
- windows平台 culture name 详细列表
点击打开链接http://msdn.microsoft.com/zh-cn/goglobal/bb896001.aspx LCID Culture Identifier Culture Name Lo ...
- 【转】oracle Sequence
http://blog.csdn.net/zhoufoxcn/article/details/1762351 在oracle中sequence就是序号,每次取的时候它会自动增加.sequence与表没 ...
- 如何在windows上安装部署设置SVN服务器
1 一.准备工作 1.SVN服务器:解压缩包,可以从官方网站下载最新版本. 2.SVN客户端:TortoiseSVN,即常说的小乌龟,是一个客户端程序,用来与服务器端通讯. 2 二.安装服务器和客 ...
- java中动态反射
java中动态反射能达到的效果和python的语法糖很像,能够截获方法的实现,在真实方法调用之前和之后进行修改,甚至能够用自己的实现进行特别的替代,也可以用其实现面向切片的部分功能.动态代理可以方便实 ...
- 旧版Xcode下载地址
怕忘记了,做个记号 https://developer.apple.com/downloads/
- javax.servlet不存在的问题
摘自:http://blog.csdn.net/tgeh23/article/details/2216682 最近在学习servlet,看书看的似乎还比较理想就想上机试下,这一试就发现,问题来 ...
- iOS - 应用程序国际化
开发的移动应用更希望获取更多用户,走向世界,这就需要应用国际化,国际化其实就是多语言.这篇文章介绍Xcode4.5以后的国际化,包括应用名国际化和应用内容国际化.如果是Xcode4.5之前版本请参考. ...
- 不建议使用NSUserDefault存储大量数据
NSUserDefaults 其实是一个 plist 文件(有待验证),即使只是修改一个 key 都会 load 整个文件,不适合存储大量数据. NSUserDefaults是保存成文本格式的,容易被 ...
- VMware下打开Chrome OS遇到没有网络连接可用
打开ChromeOS.vmx文件,最后一行添加 ethernet0.virtualDev = "e1000" 就能解决.
- hdu 4739
一个超级超级水的题,不明白当时比赛的时候没有出来: 思路很简单,dfs暴力一下就行,枚举每个顶点,题目一共才20个点,就是20^4方的时间复杂度,完全可以承受: 代码: #include<cst ...