Texygen文本生成,交大计算机系14级的朱耀明
文本生成哪家强?上交大提出基准测试新平台 Texygen
新智元报道
来源:arxiv
编译:Marvin
【新智元导读】上海交通大学、伦敦大学学院朱耀明, 卢思迪,郑雷,郭家贤, 张伟楠, 汪军,俞勇等人的研究团队最新推出Texygen平台,这是一个支持开放域文本生成模型研究的基准平台。Texygen不仅实现了大部分的文本生成模型,而且还覆盖了一系列衡量生成文本的多样性、质量和一致性的评测指标。
项目地址: https://github.com/geek-ai/Texygen
论文:https://arxiv.org/abs/1802.01886
上海交通大学、伦敦大学学院朱耀明, 卢思迪,郑雷,郭家贤, 张伟楠 , 汪军,俞勇等人的研究团队最新推出Texygen,这是一个支持开放域文本生成模型研究的基准平台。Texygen不仅实现了大部分的文本生成模型,而且还提供了一系列衡量生成文本的多样性、质量和一致性的评测指标。Texygen平台可以帮助规范文本生成的研究,促进研究人员提供自己所呈现工作的官方开源实现。这将有助于提高文本生成的未来研究工作的可复现性和可靠性。
Texygen项目主要贡献者,上海交大计算机系14级的朱耀明同学表示:
目前计算机视觉与自然语言处理是人工智能的两大主要应用,生成对抗网络(GAN)作为深度学习界的一项技术,在前者的运用上日臻成熟,而在与后者的结合上还略欠火候。这次设计Texygen平台一方面目的便是总结了一下生成对抗网络在文本生成的前沿进展,并给大家的工作提供一个比较与交流的平台。另一方面,文本生成由于其任务的特殊性,至今还没有一项能让所有人信服的自动测试指标。因此,Texygen也实现了几大主流评价方法并提出了自己的指标,望能在文本生成评测这一主题下给研究者们一些启发,推动这方面的工作迈向下一阶段。
Texygen项目贡献者之一,上海交大致远学院15级计算机科学班的卢思迪同学感言道:
在开发新的模型的过程中,我们也比较了文本生成这一领域与图像生成/计算机视觉的相关问题的异同。我们发现,一个较为显著的问题是,与卷积神经网络(Convolution Neural Network)在那些领域的大放异彩不同,循环神经网络(Recurrent Neural Network)作为一种自回归(auto-regressive)工具并不够专一化。其包含的用于简化网络结构、提高收敛性能的假设过少,使得对语言模型、文本生成模型的训练变得相对而言较难取得革命性突破。我们将在Texygen的帮助下对这类问题进行进一步思考,同时也希望这个平台能够帮助学界的朋友们在这一问题上取得更多进展。
Texygen项目的指导者,上海交大计算机系John Hopcroft Center的助理教授张伟楠说:
基于生成式对抗网络(GAN)做图像生成的研究工作现在已经随处可见,这些模型之所以可以横向对比,其重要原因在于人们提出了Inception Score等评价指标,对于新生成的图像给出量化的评测和对比,进而推进研究的前沿。在文本生成方面,尽管近一年的研究工作越来越多,但像Inception Score这样的指标还并未发明出来。我们希望借助着Texygen平台,研究者们能更多地思考什么是一个好的文本生成评测指标以及如何公平地评测文本生成模型,这样才能真正推动这个领域朝着健康的方向发展。
评估文本生成模型的3个挑战
开放域文本生成问题的目标是对离散token的连续生成进行建模。它具有很多的实际应用,包括但不限于机器翻译[2],AI聊天机器人[9],自动生成图像说明[15],问题回答和信息检索[13]。与我们所已经看到的文本生成实际应用的各种成果相对的,文本生成模型的基础研究并没有取得太多重大进展。目前为止,大多数文本生成模型的基础算法仍然是最大似然估计(MLE)[11]或其变体。值得注意的是,由于这些常见的选择并不是这一序列生成问题的完美目标函数(正如文献[6]中所指出的“exposure bias”),研究人员一直在寻找替代的优化方法和目标函数。
生成对抗网络(GAN)[4]的成功激发了人们对文本离散数据对抗性训练研究的兴趣。例如,序列生成对抗网络SeqGAN是应用REINFORCE算法[14]解决原始GAN目标函数的离散优化的早期尝试之一。自那以后,研究人员提出了许多改进SeqGAN的方法来进一步提升SeqGAN的性能,例如梯度消失(MaliGAN [3],RankGAN [10],LeakGAN [5]使用的自举再激活),以及生成长文本时的鲁棒性(LeakGAN)。
然而,在评估文本生成模型时,学界面临3个主要的挑战。首先,一个好的文本生成模型的标准是什么还不明确。尽管研究人员已经开发了诸如困惑度(perplexity)[7], 基于人造数据的负对数似然估计(NLL)[16],基于图灵测试的人类评分,以及BLEU[12]等标准,但还没有一个单一的评测指标足够全面,可以评测一个文本生成模型性能的方方面面。因此,需要对多个评测指标进行评估才能得出明确的答案。
其次,研究人员并没有义务公开他们的源代码,这为第三方复现他们所报告的实验结果带来了不必要的额外困难。
第三,文本生成会遇到质量和多样性权衡的问题。在模型性能一定的情况下,人们可以通过调节一些参数来修改这一权衡。这使得研究者发布的工作是否具有重大突破变得更加难以衡量。据我们所知,关于文本生成的多样性还没有一个好的评测指标。因此,我们迫切需要一个可靠的平台,它可以对现有的文本生成模型进行全面的评估,并在一个共同的框架中促进新模型的开发。
在本文中,我们发布了Texygen,这是一个用于文本生成模型的完全开源的基准测试平台。Texygen不仅包含了大部分的基准模型的良好实现,而且还提供了各种评测指标来评估生成文本的多样性、质量和一致性。通过这些指标,我们可以对不同的文本生成模型进行更全面的评估。我们希望这个平台能够帮助规范文本生成研究的进程,提高这个领域研究工作的可复现性,并鼓励更高层次的应用。
Texygen平台
Texygen为文本生成模型提供了一个标准的自顶向下的多维评估系统。目前,Texygen包含两个基本组件:训练好的基准模型和可自动计算的评估标准。Texygen还提供了该平台的开源代码库,研究人员可以在其中找到API的规范和手册,以便实现他们的模型并使用Texygen进行评估。
基线模型
在目前版本的Texygen,我们实现了各种基于likelihood的模型,例如基础的MLE语言模型,SeqGAN [16],MaliGAN [3],RankGAN [10],TextGAN(Adversarial Feature Matching)[17],GSGAN(GAN with Gumbel Softmax trick )[8]和LeakGAN [5]。这些基准模型包含有监督的likelihood方法,对抗方法和层次化方法。虽然以后会增加更多模型,但我们相信现在的覆盖率已经足以为任何新模型提供一个充分的参照。
评测指标(Metrics)
到目前为止,Texygen实现了5个文本生成的评测指标,涵盖了以下类别的各个方面。Texygen还提供易用的API来检索自己的模型和生成的文本的结果。
基于文档相似度的指标。生成的文档质量的最直观的评测指标是文档与自然语言或者训练数据集的类似程度:
- BLEU:基于词袋(bag of words)模型的评测指标。以词和词组为基本单位。
- EmbSim :使用模型输出的序列训练出的词向量的相互相似性特征定义的评测指标。以基本词元(token)为基本单位。
基于似然性(likelihood)的指标:
- NLL-oracle:基于人造数据的似然度估计。衡量待评测语言模型的输出在构造出的人造数据模型衡量下的负对数似然。
- NLL-test:基于测试数据的似然度估计。衡量构造出测试数据在待评测语言模型的衡量下的负对数似然。
基于多样性评价的指标:
- Self-BLEU:基于词袋(bag of words)模型的评测指标。衡量一个模型的每一句输出与此模型其他输出的相似性。以词和词组为基本单位。
Texygen平台的架构
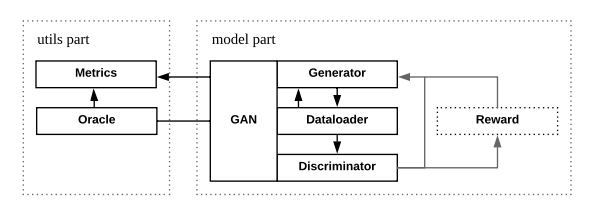
图1: Texygen的架构
Texygen是通过TensorFlow实现的[1]。如图1所示,系统由两部分组成,主要包括3个模块,彼此高度分离,易于定制化。
在utils部分,我们提供用户Metrics类和Oracle类。前者有3个用于计算BLEU score、NLL loss和EmbSim的子类,后者则允许用户初始化3种不同类型的Oracle:基于LSTM的,基于GRU的和基于SRU的。默认的oracle是基于LSTM的。
在模型部分,用户只需要与GAN类(作为一个主要类)交互就可以开始训练过程,而不必关心生成器、鉴别器和奖励(对于基于RL的GAN而言)类。Texygen还提供了两种不同类型的GAN训练过程:人造数据训练和真实数据训练。前者使用oracle LSTM生成的数据,后者使用真实世界的数据集(例如,COCO image caption数据集)。
实验
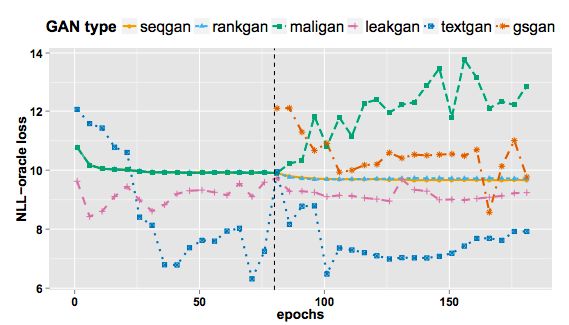
图2:整个训练过程的NLL-oracle loss的比较
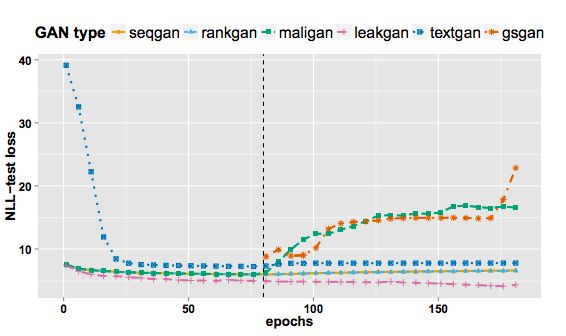
图3:整个训练过程的NLL-test loss的比较
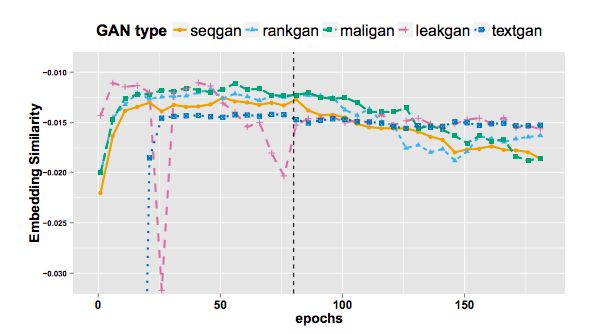
图4:整个训练过程的EmbSim比较
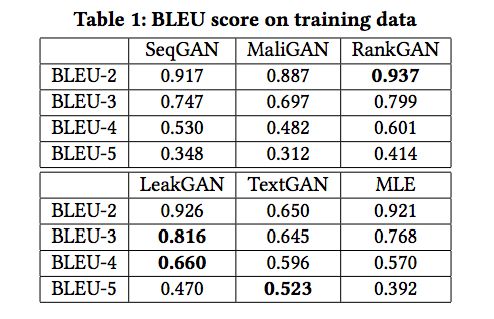
表1:训练数据的BLEU score
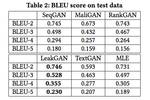
表2:测试数据的BLEU score
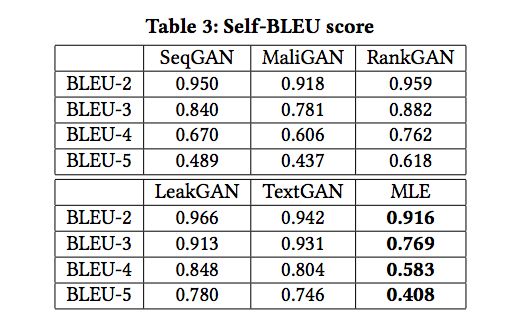
表3: Self-BLEU score
结论和将来的工作
Texygen是一个文本生成的基准平台,帮助研究人员评估自己的模型,并从不同的角度公平,方便地与现有的基准模型进行比较。Texygen已经设计和实现了各种评估标准,以提供一个全面的基准。
我们发现并不是所有的NLP 评测指标都适用于文本生成模型。例如,上下文无关语法(context free grammar,CFG)是文本语法分析中广泛使用的评测指标,并且在一些相关工作中被用作评测指标[8]。但实际上,我们发现这个metric不能区分不同的文本生成模型,甚至倾向于支持更严重的mode collapse,因为这些模型只能学习几个语法。未来,我们将不断加入对新的模型和新的metric实现支持,以更好地对文本生成任务进行基准测试。
项目地址: https://github.com/geek-ai/Texygen
论文:https://arxiv.org/abs/1802.01886
Texygen文本生成,交大计算机系14级的朱耀明的更多相关文章
- 如何生成每秒百万级别的 HTTP 请求?
第一篇:<如何生成每秒百万级别的 HTTP 请求?> 第二篇:<为最佳性能调优 Nginx> 第三篇:<用 LVS 搭建一个负载均衡集群> 本文是构建能够每秒处理 ...
- 使用 paddle来进行文本生成
paddle 简单介绍 paddle 是百度在2016年9月份开源的深度学习框架. 就我最近体验的感受来说的它具有几大优点: 1. 本身内嵌了许多和实际业务非常贴近的模型比如个性化推荐,情感分析,词向 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 复旦大学2014--2015学年第二学期(14级)高等代数II期末考试第八大题解答
八.(本题10分) 设 $A,B$ 为 $n$ 阶半正定实对称阵, 求证: $AB$ 可对角化. 分析 证明分成两个步骤: 第一步, 将 $A,B$ 中的某一个简化为合同标准形来考虑问题, 这是矩 ...
- Python将文本生成二维码
#coding:utf-8 ''' Python生成二维码 v1.0 主要将文本生成二维码图片 测试一:将文本生成白底黑字的二维码图片 测试二:将文本生成带logo的二维码图片 ''' __autho ...
- GANs用于文本生成
上学期期末老师给了我本杂志让我好好看看里面的Gans网络是如何应用在文本生成上的,文章里面也没有介绍原理性的东西,只是说了加入这个Gans模型后效果有多好,给出了模型架构图和训练时所用的语料例子,也没 ...
- 实现nlp文本生成中的beam search解码器
自然语言处理任务,比如caption generation(图片描述文本生成).机器翻译中,都需要进行词或者字符序列的生成.常见于seq2seq模型或者RNNLM模型中. 这篇博文主要介绍文本生成解码 ...
- python根据文本生成词云图
python根据文本生成词云图 效果 代码 from wordcloud import WordCloud import codecs import jieba #import jieba.analy ...
- 学习笔记(21)- texar 文本生成
今天试了文本生成框架texar https://github.com/asyml/texar 这个texar框架里面,也有端到端的实现 pwd /Users/huihui/git/ git clone ...
随机推荐
- 【BZOJ】2442: [Usaco2011 Open]修剪草坪
[算法]动态规划 [题解] 万物皆动规,每时每刻都要想着DP!特别是这种明显可以序列递推的题目. 一个简单的思路是f[i]表示前i个选择合法方案(第i个可选可不选)的最大效率 f[i]=max(f[i ...
- ShadowBroker公开的SMB远程命令执行漏洞修复
有人不知道如何获得MS对应的补丁KB编号,可以看这篇文章了~ 漏洞编号为ms17-010,如何查看对应MS号的补丁已经安装: 下载微软官方的补丁信息列表(Microsoft Security Bull ...
- LeetCode 151 reverse word in a string
Given an input string, reverse the string word by word. For example, Given s = "the sky is blue ...
- 如何在本机搭建SVN服务器【转】
转自:http://www.cnblogs.com/loveclumsybaby/archive/2012/08/21/2649353.html 目的:在没有正式的SVN服务器的情况下,完成代码的本地 ...
- 数据类型转换,JS操作HTML
数据类型转换 1.自动转换(在某种运算环境下) Number环境 String环境 Boolean环境 2.强制类型转换 Number() 字符串:纯数字和空字符转为正常数字,其他NaN 布尔值:tu ...
- ubuntu下中文输入法安装
个人认为ubantu下fcitx比sogo好用 安装fcitx首先到ubantu软件中心下载fcitx两个软件,一个是配置软件,一个是输入法软件 到system setting中language su ...
- Ubuntu 16.04下开启Mysql 3306端口远程访问
原文地址:传送门 0. 前言 网上看到很多开启Mysql远程访问端口,修改的配置文件我都没有找到. 特意查看了我的Linux版本 $ sudo lsb_release -a 显示如下: Distrib ...
- 单词接龙(dragon)(BFS)
单词接龙(dragon) 时间限制: 1 Sec 内存限制: 64 MB提交: 12 解决: 5[提交][状态][讨论版] 题目描述 单 词接龙是一个与我们经常玩的成语接龙相类似的游戏,现在我们已 ...
- hihocoder Popular Products(STL)
Popular Products 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 Given N lists of customer purchase, your tas ...
- centos7 启用iptables
在centos 7下启用iptables systemctl stop firewalld.service systemctl disable firewalld.service yum instal ...