scrapy-splash抓取动态数据例子十三
一、介绍
本例子用scrapy-splash通过搜狗搜索引擎,输入给定关键字抓取微信资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
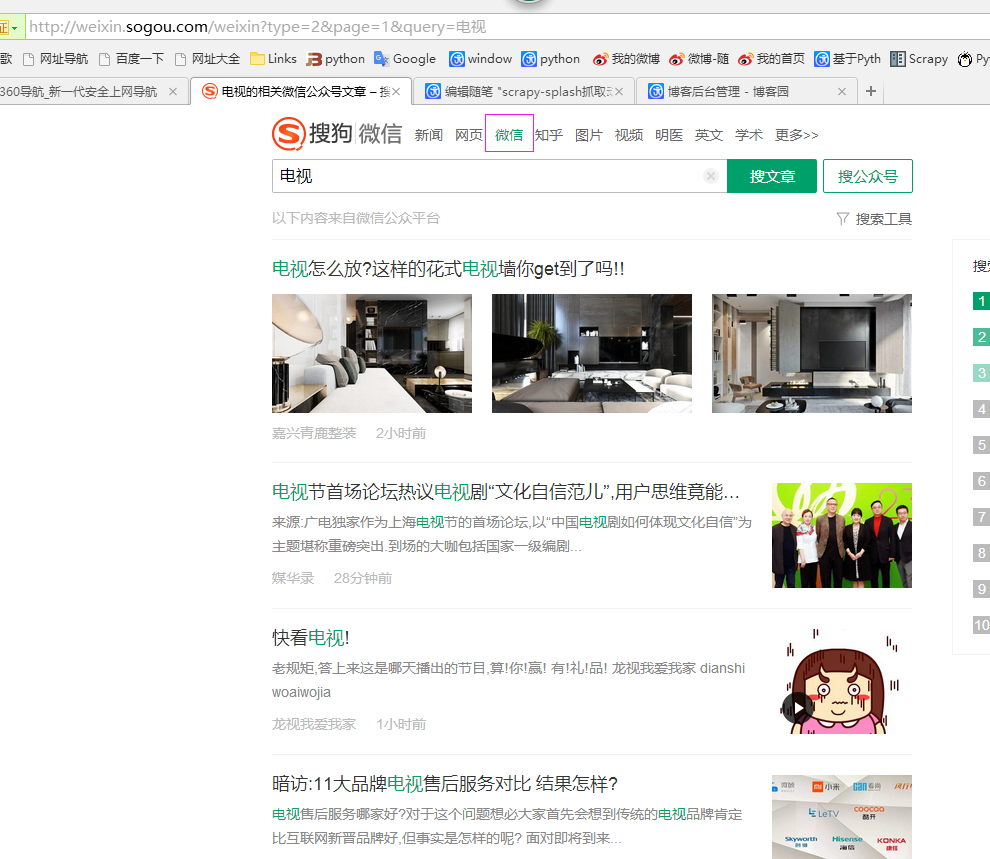

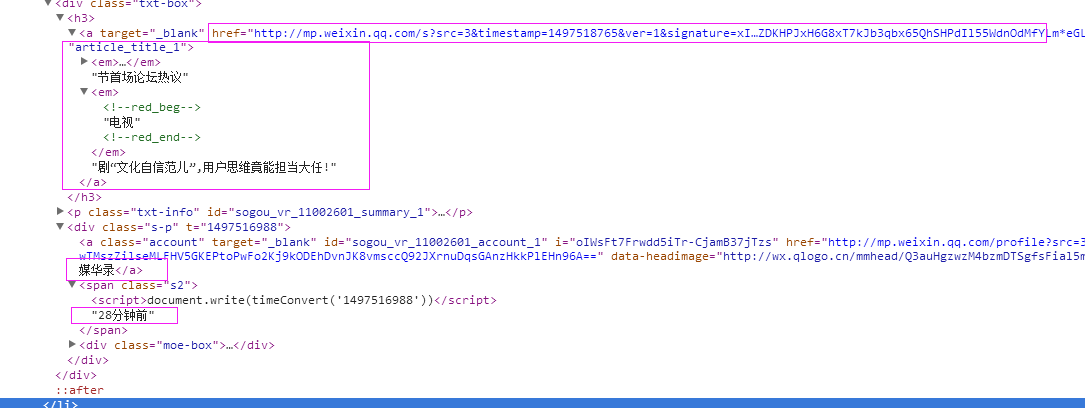
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:sels = site.xpath('//li[contains(@id,"sogou_vr")]')
2、抓取标题
抓取代码:titles = sel.xpath('.//div[@class="txt-box"]/h3/a/text()|.//div[@class="txt-box"]/h3/a/em/text()')
3、抓取链接
抓取代码:sel.xpath('.//div[@class="txt-box"]/h3/a/@href')[0].extract()
4、抓取日期
抓取代码:strdate = sel.xpath('.//span[@class="s2"]/text()')
5、抓取来源
抓取代码:sources = sel.xpath('.//div[@class="s-p"]/a/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from scrapy_ott.items import SplashTestItem
from scrapy_ott.mongoDB import mongoDbBase
import scrapy_ott.IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class weixinSpider(Spider):
name = 'weixin' db = mongoDbBase() configfile = os.path.join(os.getcwd(), 'scrapy_ott\setting.conf')
cf = scrapy_ott.IniFile.ConfigFile(configfile)
information_keywords = cf.GetValue("section", "information_keywords")
information_wordlist = information_keywords.split(';')
websearchurl_list = cf.GetValue("weixin", "websearchurl").split(';')
start_urls = []
for word in information_wordlist:
for url in websearchurl_list:
start_urls.append(url + word) # request需要封装成SplashRequest
def start_requests(self): for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '慧聪网 7小时前'; '新浪游戏 29分钟前' ; '中国行业研究网 2017-6-13'
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d') if strDateText.find('分钟前') > 0 :
return True,currentDate
elif strDateText.find('小时前') > 0:
datePattern = re.compile(r'\d{1,2}')
ch = int(time.strftime('%H')) # 当前小时数
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if int(strDate[0]) <= ch: # 只有小于当前小时数,才认为是今天
return True,currentDate
else:
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True,currentDate
return False, '' def parse(self, response):
keyword = response.meta['keyword']
site = Selector(response)
sels = site.xpath('//li[contains(@id,"sogou_vr")]')
item_list = []
for sel in sels:
strdate = sel.xpath('.//span[@class="s2"]/text()')
if len(strdate)>0:
flag,date = self.date_isValid(strdate[0].extract())
if flag:
titles = sel.xpath('.//div[@class="txt-box"]/h3/a/text()|.//div[@class="txt-box"]/h3/a/em/text()')
title = ''
for t in titles:
title += str(t.extract())
if title.find(keyword) > -1:
it = SplashTestItem()
sources = sel.xpath('.//div[@class="s-p"]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
it['url'] = sel.xpath('.//div[@class="txt-box"]/h3/a/@href')[0].extract()
it['date'] = date
it['keyword'] = keyword
it['title'] = title
item_list.append(it) if len(item_list)>0:
# self.db.SaveInformations(item_list)
return item_list
scrapy-splash抓取动态数据例子十三的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- Linux : select()详解 和 实现原理【转】
转自:http://blog.csdn.net/huntinux/article/details/39289317 原文:http://blog.csdn.net/boboiask/article/d ...
- inno setup 5 添加快捷方式默认选中
转载:https://www.cnblogs.com/x_wukong/p/5012412.html https://zhidao.baidu.com/question/312006120.html ...
- UVALIVE 3891 The Teacher's Side of Math
One of the tasks students routinely carry out in their mathematics classes is to solve a polynomial ...
- arm SecurCore 处理器【转】
转自:http://www.arm.com/zh/products/processors/securcore/index.php SecurCore 处理器 (View Larger SecurCor ...
- mybatis插入值的时候返回对象的主键值
mapping文件: <insert id="insert" parameterType="com.vimtech.bms.business.riskproject ...
- 2.aiomysql实现对数据库异步读取
有一个库叫做aiomysql,这是一个基于asyncio和pymysql的库.至于为什么可以在tornado中使用,是因为高版本tornado的底层使用了asyncio. import asyncio ...
- Selenium2+python自动化66-装饰器之运行失败截图【转载】
前言 对于用例失败截图,很多小伙伴都希望在用例执行失败的时候能自动截图,想法是很好的,实现起来并不是那么容易. 这里分享下我的一些思路,当然目前还没找到完美的解决方案,我的思路是用装饰器去解决,希望有 ...
- js实现侧边栏信息展示效果
目前的网页都右侧边栏,有的是在左侧,类似于导航栏,如一些购物商城,还有一些是在网页的右下角,一般是提示客服信息和微信/QQ等服务. 这里都涉及到一个动画效果的展示,即点击侧边栏时会在侧边栏的右侧或者左 ...
- AC日记——【清华集训2014】奇数国 uoj 38
#38. [清华集训2014]奇数国 思路: 题目中的number与product不想冲: 即为number与product互素: 所以,求phi(product)即可: 除一个数等同于在模的意义下乘 ...
- CF 1006B Polycarp's Practice【贪心】
Polycarp is practicing his problem solving skill. He has a list of n problems with difficulties a1,a ...