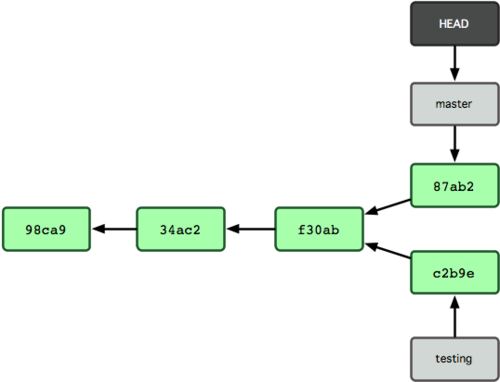
直接使用github的客户端即可
1、简介
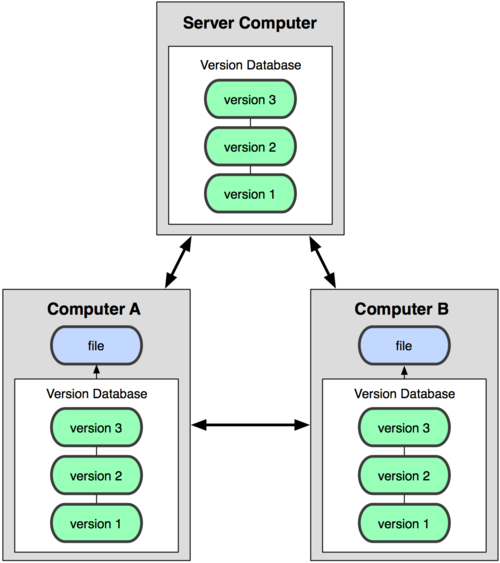
集中化的版本控制系统( Centralized Version Control Systems,简称 CVCS )应运而生。这类系统,诸如 CVS,Subversion 以及 Perforce 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。

分布式版本控制系统( Distributed Version Control System,简称 DVCS )面世了。在这类系统中,像 Git,Mercurial,Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份
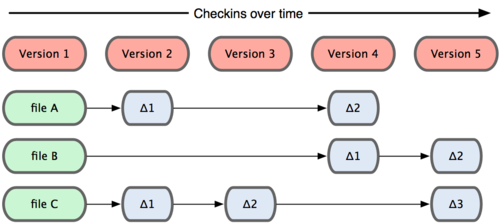
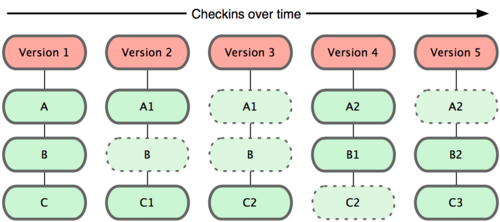
Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。这类系统(CVS,Subversion,Perforce,Bazaar 等等)每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容
Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。
因为 Git 在本地磁盘上就保存着所有当前项目的历史更新,所以处理起来速度飞快。
用 CVCS 的话,没有网络或者断开 VPN 你就无法做任何事情。但用 Git 的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程仓库。同样,在回家的路上,不用连接 VPN 你也可以继续工作。换作其他版本控制系统,这么做几乎不可能,抑或非常麻烦。比如 Perforce,如果不连到服务器,几乎什么都做不了(译注:默认无法发出命令 p4 edit file 开始编辑文件,因为 Perforce 需要联网通知系统声明该文件正在被谁修订。但实际上手工修改文件权限可以绕过这个限制,只是完成后还是无法提交更新。);如果是 Subversion 或 CVS,虽然可以编辑文件,但无法提交更新,因为数据库在网络上。看上去好像这些都不是什么大问题,但实际体验过之后,你就会惊喜地发现,这其实是会带来很大不同的。
2、基本使用
配置个人信息,每次 Git 提交时都会引用这两条信息,说明是谁提交了更新,所以会随更新内容一起被永久纳入历史记录:
git config --global user.name "John Doe"
git config --global user.email johndoe@example.com
初始化当前目录为新仓库
git init
已有文件的文件夹创建仓库
在该文件夹下新建temp文件夹,在temp文件夹下创建仓库,然后将生成的文件剪切粘贴到上级目录,删除temp即可。
从现有仓库克隆
git clone git://github.com/schacon/grit.git
检查文件状态
git status
添加所有改动的已跟踪文件和未跟踪文件。会自动根据.gitignore文件忽略文件
git add -A
查看即将所有改动的已跟踪文件和未跟踪文件。
git add -A -n
查看中当前文件和暂存区域快照之间的差异
git diff
查看已经暂存起来的文件和上次提交时的快照之间的差异
git diff --staged
跳过使用暂存区域提交更新,Git 会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤
git commit -a
直接附带说明提交更新
git commit -m "Story 182: Fix benchmarks for speed"
移除文件
git rm
提交的时候,该文件就不再纳入版本管理了。如果删除之前修改过并且已经放到暂存区域的话,则必须要用强制删除选项 -f(译注:即 force 的首字母),以防误删除文件后丢失修改的内容。
仅从跟踪清单中删除
git rm --cached readme.txt
移动文件
git mv file_from file_to
查看提交历史
git log
显示每次提交的内容差异,-2 则仅显示最近的两次更新
git log -p -2
仅显示简要的增改行数统计
git log --stat
指定使用完全不同于默认格式的方式展示提交历史。
git log --pretty=oneline\short\full\fuller
git log --pretty=format:"%h - %an, %ar : %s"
选项 说明
%H 提交对象(commit)的完整哈希字串
%h 提交对象的简短哈希字串
%T 树对象(tree)的完整哈希字串
%t 树对象的简短哈希字串
%P 父对象(parent)的完整哈希字串
%p 父对象的简短哈希字串
%an 作者(author)的名字
%ae 作者的电子邮件地址
%ad 作者修订日期(可以用 -date= 选项定制格式)
%ar 作者修订日期,按多久以前的方式显示
%cn 提交者(committer)的名字
%ce 提交者的电子邮件地址
%cd 提交日期
%cr 提交日期,按多久以前的方式显示
%s 提交说明
其他历史参数
-p 按补丁格式显示每个更新之间的差异。
--stat 显示每次更新的文件修改统计信息。
--shortstat 只显示 --stat 中最后的行数修改添加移除统计。
--name-only 仅在提交信息后显示已修改的文件清单。
--name-status 显示新增、修改、删除的文件清单。
--abbrev-commit 仅显示 SHA-1 的前几个字符,而非所有的 40 个字符。
--relative-date 使用较短的相对时间显示(比如,“2 weeks ago”)。
--graph 显示 ASCII 图形表示的分支合并历史。
--pretty 使用其他格式显示历史提交信息。可用的选项包括 oneline,short,full,fuller 和 format(后跟指定格式)。
发现漏掉了几个文件没有加,或者提交信息写错了,想要撤消刚才的提交操作,重新提交。
git commit --amend
取消已经暂存的文件
git reset HEAD <file>...
取消对文件的修改,回到之前的状态(也就是修改之前的版本)
git checkout -- <file>...
查看当前的远程库
git remote -v
添加远程仓库
git remote add pb git://github.com/paulboone/ticgit.git
可以用字符串 pb 指代对应的仓库地址了
从远程仓库抓取数据
git fetch [remote-name]
从远程仓库抓取数据并自动合并
git pull
推送数据到远程仓库
git push origin master
查看远程仓库信息
git remote show [remote-name]
远程仓库的删除和重命名,比如想把 pb 改成 paul
git remote rename
Git 也可以对某一时间点上的版本打上标签。人们在发布某个软件版本(比如 v1.0 等等)的时候,经常这么做。
列显已有的标签
git tag
用特定的搜索模式列出符合条件的标签
git tag -l 'v1.4.2.*'
新建含附注的标签
git tag -a v1.4 -m 'my version 1.4'
查看相应标签的版本信息
git show v1.4
分享标签到远端仓库
git push origin [tagname]
引用日志信息只存在于本地——这是一个记录你在你自己的仓库里做过什么的日志,其他人拷贝的仓库里的引用日志不会和你的相同;而你新克隆一个仓库的时候,引用日志是空的,因为你在仓库里还没有操作。
查看仓库中 HEAD 在五次前的值
git show HEAD@{5}
显示昨天分支的顶端在哪
git show master@{yesterday}
看上一次(N次)提交
git show HEAD^(^代表第几次)
git show HEAD~(~代表第几次)
显示d921970 的第二父提交
git show d921970^2
查看你的试验分支上哪些没有被提交到主分支
git log master..experiment
查看所有在 master 而不在 experiment 中的分支
git log experiment..master
显示任何在你当前分支上而不在远程origin 上的提交
git log origin/master..HEAD
如果你运行 git push 并且的你的当前分支正在跟踪 origin/master,被git log origin/master..HEAD 列出的提交就是将被传输到服务器上的提交。
查找所有从refA或refB包含的但是不被refC包含的提交
git log refA refB ^refC
git log refA refB --not refC
这建立了一个非常强大的修订版本查询系统,应该可以帮助你解决分支里包含了什么这个问题。
查找指定被两个引用中的一个包含但又不被两者同时包含的分支
git log master...experiment
查看master或者experiment中包含的但不是两者共有的引用
显示每个提交到底处于哪一侧的分支
git log --left-right master...experiment
进入交互式暂存
git add -i
想切换分支,但是你还不想提交你正在进行中的工作;所以你储藏这些变更。
git stash
“储藏”可以获取你工作目录的中间状态——也就是你修改过的被追踪的文件和暂存的变更——并将它保存到一个未完结变更的堆栈中,随时可以重新应用。
查看现有的储藏
git stash list
重新应用刚刚实施的储藏
git stash apply
git stash apply stash@{2}
重新应用被暂存的变更
git stash apply --index
移除储藏
git stash drop stash@{0}
重新应用储藏,同时立刻将其从堆栈中移走
git stash pop
取消之前所应用储藏的修改
git stash show -p stash@{0} | git apply -R
用更方便的方法来重新检验你储藏的变更
git stash branch testchanges
如果你储藏了一些工作,暂时不去理会,然后继续在你储藏工作的分支上工作,你在重新应用工作时可能会碰到一些问题。如果尝试应用的变更是针对一个你那之后修改过的文件,你会碰到一个归并冲突并且必须去化解它。这会创建一个新的分支,检出你储藏工作时的所处的提交,重新应用你的工作,如果成功,将会丢弃储藏。
修改最近一次提交说明
git commit --amend
如果你完成提交后又想修改被提交的快照,增加或者修改其中的文件,可能因为你最初提交时,忘了添加一个新建的文件,这个过程基本上一样。你通过修改文件然后对其运行git add或对一个已被记录的文件运行git rm,随后的git commit --amend会获取你当前的暂存区并将它作为新提交对应的快照。
使用这项技术的时候你必须小心,因为修正会改变提交的SHA-1值。这个很像是一次非常小的rebase——不要在你最近一次提交被推送后还去修正它。
修改多个提交说明
git rebase -i HEAD~3
你想修改最近三次的提交说明,或者其中任意一次,你必须给git rebase -i提供一个参数,指明你想要修改的提交的父提交,例如HEAD~2或者HEAD~3。可能记住~3更加容易,因为你想修改最近三次提交;但是请记住你事实上所指的是四次提交之前,即你想修改的提交的父提交。
再次提醒这是一个衍合命令——HEAD~3..HEAD范围内的每一次提交都会被重写,无论你是否修改说明。不要涵盖你已经推送到中心服务器的提交——这么做会使其他开发者产生混乱,因为你提供了同样变更的不同版本。
你需要修改这个脚本来让它停留在你想修改的变更上。要做到这一点,你只要将你想修改的每一次提交前面的pick改为edit
使用交互式的衍合来彻底重排或删除提交
删除修改编辑器内容即可
压制(Squashing)提交
pick f7f3f6d changed my name a bit
squash 310154e updated README formatting and added blame
squash a5f4a0d added cat-file
当你保存并退出编辑器,Git 会应用全部三次变更然后将你送回编辑器来归并三次提交说明。当你保存之后,你就拥有了一个包含前三次提交的全部变更的单一提交。
拆分提交
pick f7f3f6d changed my name a bit
edit 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
这个脚本就将你带入命令行,你重置那次提交,提取被重置的变更,从中创建多次提交。当你保存并退出编辑器,Git 倒回到列表中第一次提交的父提交,应用第一次提交(f7f3f6d),应用第二次提交(310154e),然后将你带到控制台。
$ git reset HEAD^
$ git add README
$ git commit -m 'updated README formatting'
$ git add lib/simplegit.rb
$ git commit -m 'added blame'
$ git rebase --continue
再次提醒,这会修改你列表中的提交的 SHA 值,所以请确保这个列表里不包含你已经推送到共享仓库的提交。
从所有提交中删除一个文件
git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
--tree-filter选项会在每次检出项目时先执行指定的命令然后重新提交结果。在这个例子中,你会在所有快照中删除一个名叫 password.txt 的文件,无论它是否存在。
将一个子目录设置为新的根目录
git filter-branch --subdirectory-filter trunk HEAD
假设你完成了从另外一个代码控制系统的导入工作,得到了一些没有意义的子目录(trunk, tags等等)。如果你想让trunk子目录成为每一次提交的新的项目根目录
现在你的项目根目录就是trunk子目录了。Git 会自动地删除不对这个子目录产生影响的提交。
全局性地更换电子邮件地址
在开始时忘了运行git config来设置你的姓名和电子邮件地址
git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEAD
无论哪种情况你都可以用filter-branch来更换多次提交里的电子邮件地址。你必须小心一些,只改变属于你的电子邮件地址,所以你使用--commit-filter
显示文件中对每一行进行修改的最近一次提交
git blame -L 12,22 simplegit.rb
-L选项来限制输出范围在第12至22行
^来修饰一个提交未被修改过
找出其中代码片段的原始出处
git blame -C -L 141,153 GITPackUpload.m
在提交历史中进行二分查找来尽快地确定哪一次提交引入了错误
$ git bisect start
$ git bisect bad
$ git bisect good v1.0
Bisecting: 6 revisions left to test after this
[ecb6e1bc347ccecc5f9350d878ce677feb13d3b2] error handling on repo
Git 发现在你标记为正常的提交(v1.0)和当前的错误版本之间有大约12次提交,于是它检出中间的一个。在这里,你可以运行测试来检查问题是否存在于这次提交。如果是,那么它是在这个中间提交之前的某一次引入的;如果否,那么问题是在中间提交之后引入的。假设这里是没有错误的,那么你就通过git bisect good来告诉 Git 然后继续你的旅程:
$ git bisect good
Bisecting: 3 revisions left to test after this
[b047b02ea83310a70fd603dc8cd7a6cd13d15c04] secure this thing
现在你在另外一个提交上了,在你刚刚测试通过的和一个错误提交的中点处。你再次运行测试然后发现这次提交是错误的,因此你通过git bisect bad来告诉Git:
$ git bisect bad
Bisecting: 1 revisions left to test after this
[f71ce38690acf49c1f3c9bea38e09d82a5ce6014] drop exceptions table
当你完成之后,你应该运行git bisect reset来重设你的HEAD到你开始前的地方,否则你会处于一个诡异的地方:
这是个强大的工具,可以帮助你检查上百的提交,在几分钟内找出缺陷引入的位置。事实上,如果你有一个脚本会在工程正常时返回0,错误时返回非0的话,你可以完全自动地执行git bisect。首先你需要提供已知的错误和正确提交来告诉它二分查找的范围。你可以通过bisect start命令来列出它们,先列出已知的错误提交再列出已知的正确提交:
$ git bisect start HEAD v1.0
$ git bisect run test-error.sh
这样会自动地在每一个检出的提交里运行test-error.sh直到Git找出第一个破损的提交。你也可以运行像make或者make tests或者任何你所拥有的来为你执行自动化的测试。
将外部项目加为子模块
git submodule add git://github.com/chneukirchen/rack.git rack
克隆一个带子模块的项目
git submodule init
Submodule 'rack' (git://github.com/chneukirchen/rack.git) registered for path 'rack'
git submodule update
如果你先执行了一次submodule update,然后在那个子模块目录里不创建分支就进行提交,然后再次从上层项目里运行git submodule update同时不进行提交,Git会毫无提示地覆盖你的变更。
3、分支
理解分支的概念并熟练运用后,你才会意识到为什么 Git 是一个如此强大而独特的工具,并从此真正改变你的开发方式。
在 Git 中提交时,会保存一个提交(commit)对象,该对象包含一个指向暂存内容快照的指针,包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针:首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先。
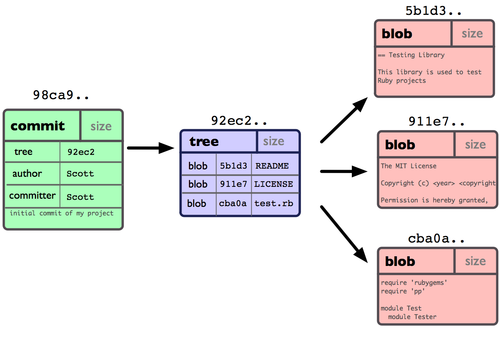
为直观起见,我们假设在工作目录中有三个文件,准备将它们暂存后提交。暂存操作会对每一个文件计算校验和(即第一章中提到的 SHA-1 哈希字串),然后把当前版本的文件快照保存到 Git 仓库中(Git 使用 blob 类型的对象存储这些快照),并将校验和加入暂存区域:
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'
当使用 git commit 新建一个提交对象前,Git 会先计算每一个子目录(本例中就是项目根目录)的校验和,然后在 Git 仓库中将这些目录保存为树(tree)对象。之后 Git 创建的提交对象,除了包含相关提交信息以外,还包含着指向这个树对象(项目根目录)的指针,如此它就可以在将来需要的时候,重现此次快照的内容了。
现在,Git 仓库中有五个对象:三个表示文件快照内容的 blob 对象;一个记录着目录树内容及其中各个文件对应 blob 对象索引的 tree 对象;以及一个包含指向 tree 对象(根目录)的索引和其他提交信息元数据的 commit 对象。概念上来说,仓库中的各个对象保存的数据和相互关系看起来如图 3-1 所示:
图 3-1. 单个提交对象在仓库中的数据结构
作些修改后再次提交,那么这次的提交对象会包含一个指向上次提交对象的指针(译注:即下图中的 parent 对象)。两次提交后,仓库历史会变成图 3-2 的样子:
图 3-2. 多个提交对象之间的链接关系
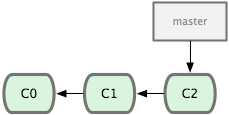
现在来谈分支。Git 中的分支,其实本质上仅仅是个指向 commit 对象的可变指针。Git 会使用 master 作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次提交对象的 master 分支,它在每次提交的时候都会自动向前移动。
图 3-3. 分支其实就是从某个提交对象往回看的历史
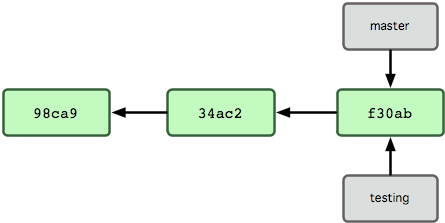
那么,Git 又是如何创建一个新的分支的呢?答案很简单,创建一个新的分支指针。比如新建一个 testing 分支,可以使用 git branch 命令:
$ git branch testing
这会在当前 commit 对象上新建一个分支指针(见图 3-4)。
图 3-4. 多个分支指向提交数据的历史
那么,Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。请注意它和你熟知的许多其他版本控制系统(比如 Subversion 或 CVS)里的 HEAD 概念大不相同。在 Git 中,它是一个指向你正在工作中的本地分支的指针(译注:将 HEAD 想象为当前分支的别名。)。运行 git branch 命令,仅仅是建立了一个新的分支,但不会自动切换到这个分支中去,所以在这个例子中,我们依然还在 master 分支里工作(参考图 3-5)。
图 3-5. HEAD 指向当前所在的分支
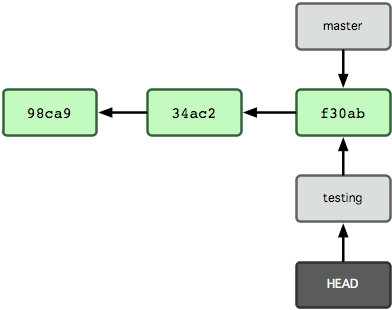
要切换到其他分支,可以执行 git checkout 命令。我们现在转换到新建的 testing 分支:
$ git checkout testing
这样 HEAD 就指向了 testing 分支(见图3-6)。
图 3-6. HEAD 在你转换分支时指向新的分支
这样的实现方式会给我们带来什么好处呢?好吧,现在不妨再提交一次:
$ vim test.rb
$ git commit -a -m 'made a change'
图 3-7 展示了提交后的结果。
图 3-7. 每次提交后 HEAD 随着分支一起向前移动
非常有趣,现在 testing 分支向前移动了一格,而 master 分支仍然指向原先 git checkout 时所在的 commit 对象。现在我们回到 master 分支看看:
$ git checkout master
图 3-8. HEAD 在一次 checkout 之后移动到了另一个分支
这条命令做了两件事。它把 HEAD 指针移回到 master 分支,并把工作目录中的文件换成了 master 分支所指向的快照内容。也就是说,现在开始所做的改动,将始于本项目中一个较老的版本。它的主要作用是将 testing 分支里作出的修改暂时取消,这样你就可以向另一个方向进行开发。
我们作些修改后再次提交:
$ vim test.rb
$ git commit -a -m 'made other changes'
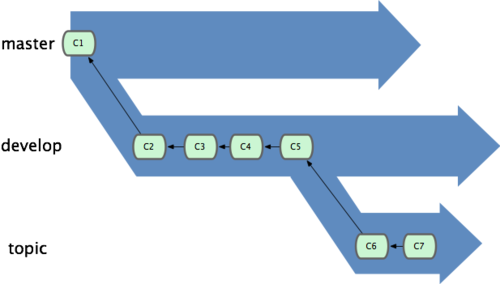
现在我们的项目提交历史产生了分叉(如图 3-9 所示),因为刚才我们创建了一个分支,转换到其中进行了一些工作,然后又回到原来的主分支进行了另外一些工作。这些改变分别孤立在不同的分支里:我们可以在不同分支里反复切换,并在时机成熟时把它们合并到一起。而所有这些工作,仅仅需要 branch 和 checkout 这两条命令就可以完成。
不同流向的分支历史
由于 Git 中的分支实际上仅是一个包含所指对象校验和(40 个字符长度 SHA-1 字串)的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,当然也就很快了。
这和大多数版本控制系统形成了鲜明对比,它们管理分支大多采取备份所有项目文件到特定目录的方式,所以根据项目文件数量和大小不同,可能花费的时间也会有相当大的差别,快则几秒,慢则数分钟。而 Git 的实现与项目复杂度无关,它永远可以在几毫秒的时间内完成分支的创建和切换。同时,因为每次提交时都记录了祖先信息(译注:即 parent 对象),将来要合并分支时,寻找恰当的合并基础(译注:即共同祖先)的工作其实已经自然而然地摆在那里了,所以实现起来非常容易。Git 鼓励开发者频繁使用分支,正是因为有着这些特性作保障。
分支工作示例
现在让我们来看一个简单的分支与合并的例子,实际工作中大体也会用到这样的工作流程:
- 开发某个网站。
- 为实现某个新的需求,创建一个分支。
- 在这个分支上开展工作。
假设此时,你突然接到一个电话说有个很严重的问题需要紧急修补,那么可以按照下面的方式处理:
- 返回到原先已经发布到生产服务器上的分支。
- 为这次紧急修补建立一个新分支,并在其中修复问题。
- 通过测试后,回到生产服务器所在的分支,将修补分支合并进来,然后再推送到生产服务器上。
- 切换到之前实现新需求的分支,继续工作。
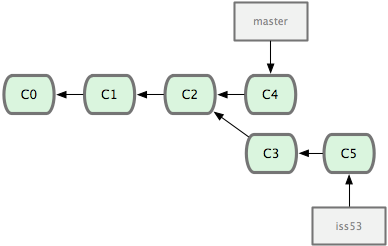
首先,我们假设你正在项目中愉快地工作,并且已经提交了几次更新(见图 3-10)。
分支的新建与切换
git checkout -b iss53
这相当于执行下面这两条命令:
$ git branch iss53
$ git checkout iss53
$ vim index.html
$ git commit -a -m 'added a new footer [issue 53]'
现在你就接到了那个网站问题的紧急电话,需要马上修补。有了 Git ,我们就不需要同时发布这个补丁和 iss53 里作出的修改,也不需要在创建和发布该补丁到服务器之前花费大力气来复原这些修改。唯一需要的仅仅是切换回 master 分支。
不过在此之前,留心你的暂存区或者工作目录里,那些还没有提交的修改,它会和你即将检出的分支产生冲突从而阻止 Git 为你切换分支(这里可以使用储藏来保存临时工作仓库)。切换分支的时候最好保持一个清洁的工作区域。稍后会介绍几个绕过这种问题的办法(分别叫做 stashing 和 commit amending)。目前已经提交了所有的修改,所以接下来可以正常转换到 master 分支:
$ git checkout master
此时工作目录中的内容和你在解决问题 #53 之前一模一样,你可以集中精力进行紧急修补。这一点值得牢记:Git 会把工作目录的内容恢复为检出某分支时它所指向的那个提交对象的快照。它会自动添加、删除和修改文件以确保目录的内容和你当时提交时完全一样。
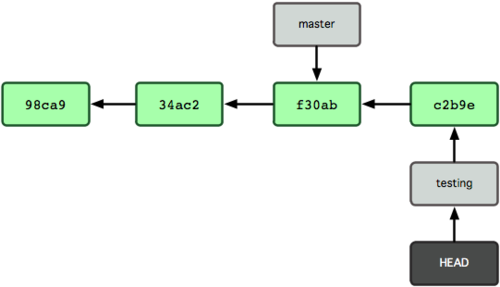
接下来,你得进行紧急修补。我们创建一个紧急修补分支 hotfix 来开展工作,直到搞定(见图 3-13):
$ git checkout -b 'hotfix'
Switched to a new branch "hotfix"
$ vim index.html
$ git commit -a -m 'fixed the broken email address'
[hotfix]: created 3a0874c: "fixed the broken email address"
1 files changed, 0 insertions(+), 1 deletions(-)
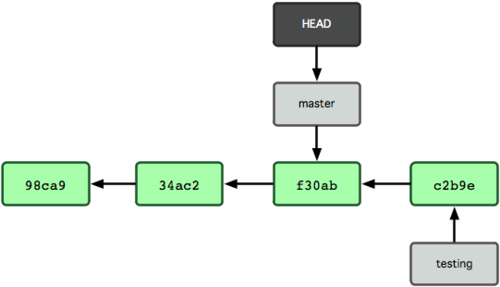
有必要作些测试,确保修补是成功的,然后回到 master 分支并把它合并进来,然后发布到生产服务器。用 git merge 命令来进行合并:
分支合并
$ git checkout master
$ git merge hotfix
Updating f42c576..3a0874c
Fast forward
README | 1 -
1 files changed, 0 insertions(+), 1 deletions(-)
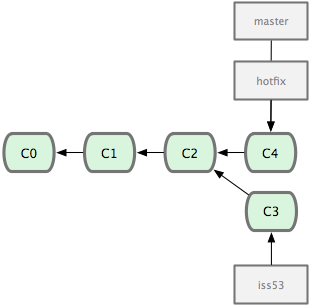
请注意,合并时出现了“Fast forward”的提示。由于当前 master 分支所在的提交对象是要并入的 hotfix 分支的直接上游,Git 只需把 master 分支指针直接右移。换句话说,如果顺着一个分支走下去可以到达另一个分支的话,那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。
现在最新的修改已经在当前 master 分支所指向的提交对象中了,可以部署到生产服务器上去了(见图 3-14)。
在那个超级重要的修补发布以后,你想要回到被打扰之前的工作。由于当前 hotfix 分支和 master 都指向相同的提交对象,所以 hotfix 已经完成了历史使命,可以删掉了。使用 git branch 的 -d 选项执行删除操作:
删除分支
$ git branch -d hotfix
Deleted branch hotfix (3a0874c).
现在回到之前未完成的 #53 问题修复分支上继续工作(图 3-15):
$ git checkout iss53
Switched to branch "iss53"
$ vim index.html
$ git commit -a -m 'finished the new footer [issue 53]'
[iss53]: created ad82d7a: "finished the new footer [issue 53]"
1 files changed, 1 insertions(+), 0 deletions(-)
不用担心之前 hotfix 分支的修改内容尚未包含到 iss53 中来。如果确实需要纳入此次修补,可以用 git merge master 把 master 分支合并到 iss53;或者等 iss53 完成之后,再将 iss53 分支中的更新并入 master。
在问题 #53 相关的工作完成之后,可以合并回 master 分支。实际操作同前面合并 hotfix 分支差不多,只需回到 master 分支,运行 git merge 命令指定要合并进来的分支:
$ git checkout master
$ git merge iss53
Merge made by recursive.
README | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
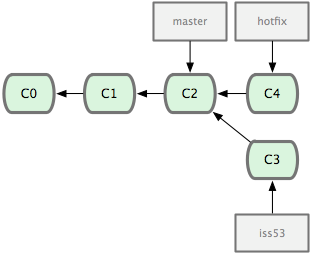
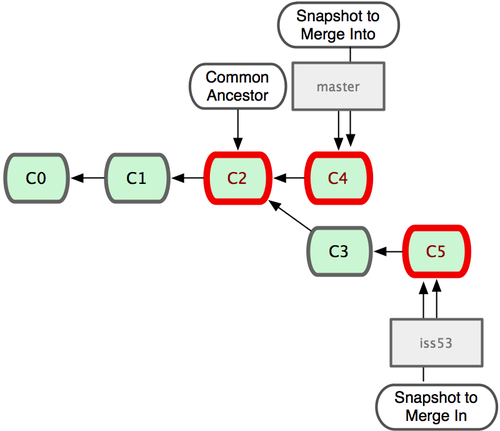
请注意,这次合并操作的底层实现,并不同于之前 hotfix 的并入方式。因为这次你的开发历史是从更早的地方开始分叉的。由于当前 master 分支所指向的提交对象(C4)并不是 iss53 分支的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(C4 和 C5)以及它们的共同祖先(C2)进行一次简单的三方合并计算。图 3-16 用红框标出了 Git 用于合并的三个提交对象:
图 3-16. Git 为分支合并自动识别出最佳的同源合并点。
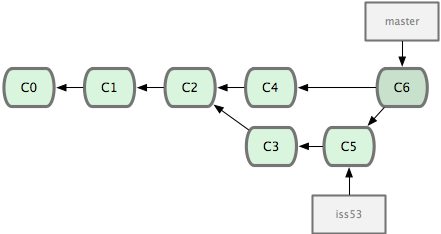
这次,Git 没有简单地把分支指针右移,而是对三方合并后的结果重新做一个新的快照,并自动创建一个指向它的提交对象(C6)(见图 3-17)。这个提交对象比较特殊,它有两个祖先(C4 和 C5)。
值得一提的是 Git 可以自己裁决哪个共同祖先才是最佳合并基础;这和 CVS 或 Subversion(1.5 以后的版本)不同,它们需要开发者手工指定合并基础。所以此特性让 Git 的合并操作比其他系统都要简单不少。
图 3-17. Git 自动创建了一个包含了合并结果的提交对象。
既然之前的工作成果已经合并到 master 了,那么 iss53 也就没用了。你可以就此删除它,并在问题追踪系统里关闭该问题。
$ git branch -d iss53
解决冲突
1、手动编辑,然后git add
2、git mergetool 调用一个可视化的合并工具并引导你解决所有冲突
当前所有分支的清单
git branch
* 字符:它表示当前所在的分支。
查看各个分支最后一个提交对象的信息
git branch -v
查看已经(或尚未)与当前分支合并的分支
git branch --merged
git branch --no-merged
强制删除分支
git branch -d testing
推送本地分支
git push (远程仓库名) (分支名)
若想把远程分支叫作 awesomebranch,可以用 git push origin serverfix:awesomebranch 来推送数据。
获取远程分支
git fetch (远程仓库名) (分支名)
值得注意的是,在 fetch 操作下载好新的远程分支之后,你仍然无法在本地编辑该远程仓库中的分支。换句话说,在本例中,你不会有一个新的 serverfix 分支,有的只是一个你无法移动的 origin/serverfix 指针。
git checkout -b serverfix origin/serverfix
这会切换到新建的 serverfix 本地分支,其内容同远程分支 origin/serverfix 一致,这样你就可以在里面继续开发了。
跟踪远程分支
git checkout --track origin/serverfix
为本地分支设定不同于远程分支的名字
git checkout -b sf origin/serverfix
现在你的本地分支 sf 会自动将推送和抓取数据的位置定位到 origin/serverfix 了。
删除远程分支
git push origin :serverfix
git push [远程名] [本地分支]:[远程分支] 语法,如果省略 [本地分支],那就等于是在说“在这里提取空白然后把它变成[远程分支]
分支的衍合
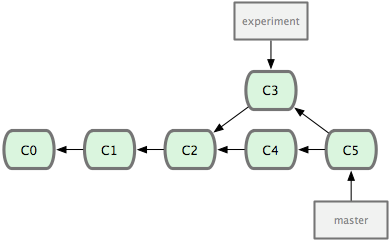
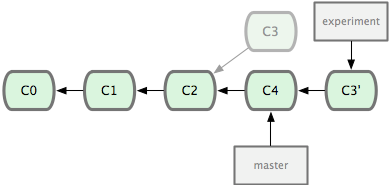
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
图 3-27. 最初分叉的提交历史。
图 3-28. 通过合并一个分支来整合分叉了的历史。
它的原理是回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支 experiment)后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3'),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游,如图 3-29 所示:
图 3-29. 把 C3 里产生的改变到 C4 上重演一遍。
一般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁 — 比如某些项目你不是维护者,但想帮点忙的话,最好用衍合:先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次衍合操作然后再提交,这样维护者就不需要做任何整合工作(译注:实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。
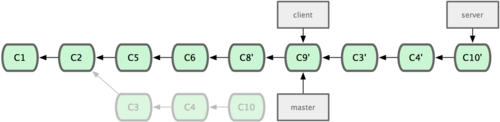
其他分支进行衍合
$ git rebase --onto master server client
$ git checkout master
$ git merge client
$ git rebase master server
$ git checkout master
$ git merge server
$ git branch -d client
$ git branch -d server
一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行衍合操作。
在进行衍合的时候,实际上抛弃了一些现存的提交对象而创造了一些类似但不同的新的提交对象。如果你把原来分支中的提交对象发布出去,并且其他人更新下载后在其基础上开展工作,而稍后你又用 git rebase 抛弃这些提交对象,把新的重演后的提交对象发布出去的话,你的合作者就不得不重新合并他们的工作,这样当你再次从他们那里获取内容时,提交历史就会变得一团糟。
如果把衍合当成一种在推送之前清理提交历史的手段,而且仅仅衍合那些尚未公开的提交对象,就没问题。如果衍合那些已经公开的提交对象,并且已经有人基于这些提交对象开展了后续开发工作的话,就会出现叫人沮丧的麻烦。
长期分支
由于 Git 使用简单的三方合并,所以就算在较长一段时间内,反复多次把某个分支合并到另一分支,也不是什么难事。也就是说,你可以同时拥有多个开放的分支,每个分支用于完成特定的任务,随着开发的推进,你可以随时把某个特性分支的成果并到其他分支中。
许多使用 Git 的开发者都喜欢用这种方式来开展工作,比如仅在 master 分支中保留完全稳定的代码,即已经发布或即将发布的代码。与此同时,他们还有一个名为 develop 或 next 的平行分支,专门用于后续的开发,或仅用于稳定性测试 — 当然并不是说一定要绝对稳定,不过一旦进入某种稳定状态,便可以把它合并到 master 里。这样,在确保这些已完成的特性分支(短期分支,比如之前的 iss53 分支)能够通过所有测试,并且不会引入更多错误之后,就可以并到主干分支中,等待下一次的发布。
本质上我们刚才谈论的,是随着提交对象不断右移的指针。稳定分支的指针总是在提交历史中落后一大截,而前沿分支总是比较靠前(见图 3-18)。
图 3-18. 稳定分支总是比较老旧。
或者把它们想象成工作流水线,或许更好理解一些,经过测试的提交对象集合被遴选到更稳定的流水线(见图 3-19)。
图 3-19. 想象成流水线可能会容易点。
你可以用这招维护不同层次的稳定性。某些大项目还会有个 proposed(建议)或 pu(proposed updates,建议更新)分支,它包含着那些可能还没有成熟到进入 next 或 master 的内容。这么做的目的是拥有不同层次的稳定性:当这些分支进入到更稳定的水平时,再把它们合并到更高层分支中去。再次说明下,使用多个长期分支的做法并非必需,不过一般来说,对于特大型项目或特复杂的项目,这么做确实更容易管理。
特性分支
在任何规模的项目中都可以使用特性(Topic)分支。一个特性分支是指一个短期的,用来实现单一特性或与其相关工作的分支。可能你在以前的版本控制系统里从未做过类似这样的事情,因为通常创建与合并分支消耗太大。然而在 Git 中,一天之内建立、使用、合并再删除多个分支是常见的事。
我们在上节的例子里已经见过这种用法了。我们创建了 iss53 和 hotfix 这两个特性分支,在提交了若干更新后,把它们合并到主干分支,然后删除。该技术允许你迅速且完全的进行语境切换 — 因为你的工作分散在不同的流水线里,每个分支里的改变都和它的目标特性相关,浏览代码之类的事情因而变得更简单了。你可以把作出的改变保持在特性分支中几分钟,几天甚至几个月,等它们成熟以后再合并,而不用在乎它们建立的顺序或者进度。
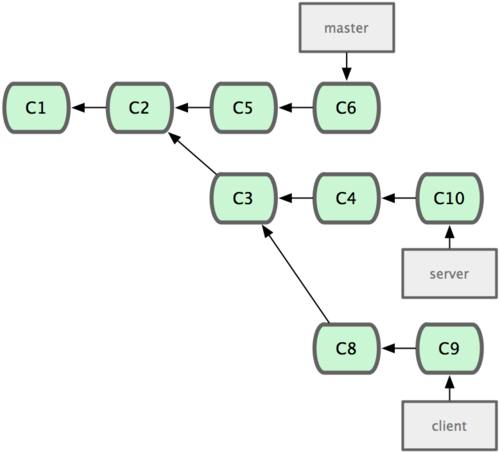
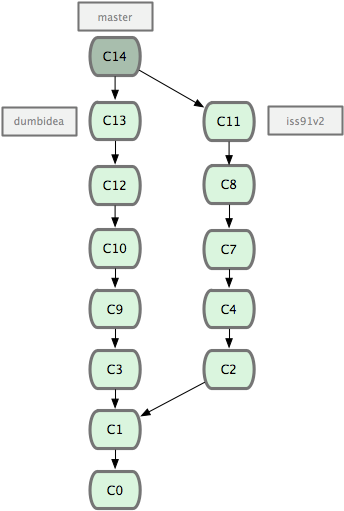
现在我们来看一个实际的例子。请看图 3-20,由下往上,起先我们在 master 工作到 C1,然后开始一个新分支 iss91 尝试修复 91 号缺陷,提交到 C6 的时候,又冒出一个解决该问题的新办法,于是从之前 C4 的地方又分出一个分支 iss91v2,干到 C8 的时候,又回到主干 master 中提交了 C9 和 C10,再回到 iss91v2 继续工作,提交 C11,接着,又冒出个不太确定的想法,从 master 的最新提交 C10 处开了个新的分支 dumbidea 做些试验。
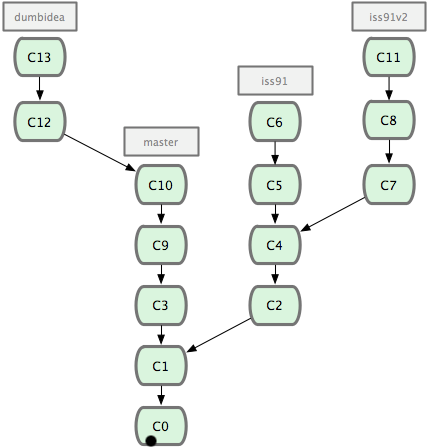
图 3-20. 拥有多个特性分支的提交历史。
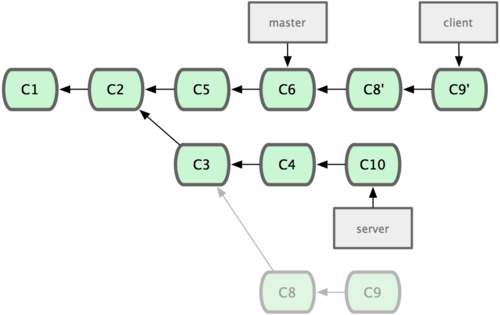
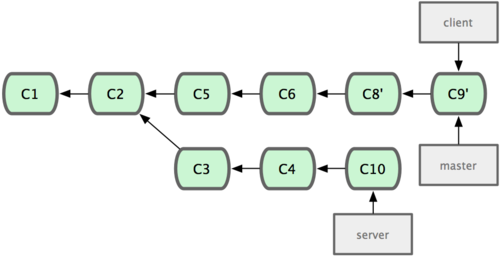
现在,假定两件事情:我们最终决定使用第二个解决方案,即 iss91v2 中的办法;另外,我们把 dumbidea 分支拿给同事们看了以后,发现它竟然是个天才之作。所以接下来,我们准备抛弃原来的 iss91 分支(实际上会丢弃 C5 和 C6),直接在主干中并入另外两个分支。最终的提交历史将变成图 3-21 这样:
请务必牢记这些分支全部都是本地分支,这一点很重要。当你在使用分支及合并的时候,一切都是在你自己的 Git 仓库中进行的 — 完全不涉及与服务器的交互。
以当前 origin/master 分支为基准,开始一个新的特性分支 featureBv2,然后把原来的 featureB 的更新拿过来,解决冲突,按要求重新实现部分代码,然后将此特性分支推送上去
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
$ (change implementation)
$ git commit
$ git push myfork featureBv2
这里的 --squash 选项将目标分支上的所有更改全拿来应用到当前分支上,而 --no-commit 选项告诉 Git 此时无需自动生成和记录(合并)提交。这样,你就可以在原来代码基础上,继续工作,直到最后一起提交。
通过开发者邮件列表接受补丁
git format-patch -M origin/master
format-patch 命令依次创建补丁文件,并输出文件名。上面的 -M 选项允许 Git 检查是否有对文件重命名的提交。
查看当前分支同其他分支合并时的完整内容差异
git diff master...contrib
4、发布
制作压缩包
git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
git archive master --prefix='project/' --format=zip > `git describe
制作简报
git shortlog --no-merges master --not v1.0.1
5、git svn
Subversion 桥接命令
git svn
克隆普通的 Git 仓库时,可以以 origin/[branch] 的形式获取远程服务器上所有可用的分支——分配到远程服务的名称下。然而 git svn 假定不存在多个远程服务器,所以把所有指向远程服务的引用不加区分的保存下来。
提交到 Subversion
git svn dcommit
如果既要向 Git 远程服务器推送内容,又要推送到 Subversion 远程服务器,则必须先向 Subversion 推送(dcommit),因为该操作会改变所提交的数据内容。
拉取Subversion最新进展
git svn rebase
它会拉取服务器上所有最新的改变,再次基础上衍合你的修改
不时地运行一下 git svn rebase 可以确保你的代码没有过时。不过,运行该命令时需要确保工作目录的整洁。如果在本地做了修改,则必须在运行 git svn rebase 之前或暂存工作,或暂时提交内容——否则,该命令会发现衍合的结果包含着冲突因而终止。
创建新的 SVN 分支
git svn branch [分支名]
这相当于在 Subversion 中的 svn copy trunk branches/opera 命令,并会对 Subversion 服务器进行相关操作。值得注意的是它没有检出和转换到那个分支
切换当前SVN分支
git branch opera remotes/opera
如果要把 opera 分支并入 trunk (本地的 master 分支),可以使用普通的 git merge,把一个分支合并到另一个分支以后,你没法像在 Git 中那样轻易的回到那个分支上继续工作。提交时运行的 dcommit 命令擦除了全部有关哪个分支被并入的信息,因而以后的合并基础计算将是不正确的—— dcommit 让 git merge 的结果变得类似于 git merge --squash。不幸的是,我们没有什么好办法来避免该情况—— Subversion 无法储存这个信息,所以在使用它作为服务器的时候你将永远为这个缺陷所困。在把本地分支(本例中的 opera)并入 trunk 以后应该立即将其删除。
查看SVN 风格的历史
git svn log
查看SVN 日志
git svn blame README.txt
查看SVN 服务器信息
git svn info
Git-Svn 总结
git svn 工具集在当前不得不使用 Subversion 服务器或者开发环境要求使用 Subversion 服务器的时候格外有用。不妨把它看成一个跛脚的 Git,然而,你还是有可能在转换过程中碰到一些困惑你和合作者们的迷题。为了避免麻烦,试着遵守如下守则:
保持一个不包含由 git merge 生成的 commit 的线性提交历史。将在主线分支外进行的开发通通衍合回主线;避免直接合并。
不要单独建立和使用一个 Git 服务来搞合作。可以为了加速新开发者的克隆进程建立一个,但是不要向它提供任何不包含 git-svn-id 条目的内容。甚至可以添加一个 pre-receive 挂钩来在每一个提交信息中查找 git-svn-id 并拒绝提交那些不包含它的 commit。
如果遵循这些守则,在 Subversion 上工作还可以接受。然而,如果能迁徙到真正的 Git 服务器,则能为团队带来更多好处。
参考
http://git.oschina.net/progit/
- git学习手记(也许仅对本人有用)
首先明白git的三种状态 commited已提交 =====>git仓库(存着各种版本)modified已修改(此时就是我们的编辑器中的未保存状态)====>工作目录staged暂存状态= ...
- Git 学习看这篇就够了!
Git是一个开源的分布式版本控制系统,可以有效.高速的处理从很小到非常大的项目版本管理. 可能新手会问"git和github有什么关系啊?" git是一个版本控制工具: githu ...
- Linux.NET学习手记(7)
前一篇中,我们简单的讲述了下如何在Linux.NET中部署第一个ASP.NET MVC 5.0的程序.而目前微软已经提出OWIN并致力于发展VNext,接下来系列中,我们将会向OWIN方向转战. 早在 ...
- Linux.NET学习手记(8)
上一回合中,我们讲解了Linux.NET面对OWIN需要做出的准备,以及介绍了如何将两个支持OWIN协议的框架:SignalR以及NancyFX以OwinHost的方式部署到Linux.NET当中.这 ...
- 关于《Linux.NET学习手记(8)》的补充说明
早前的一两天<Linux.NET学习手记(8)>发布了,这一篇主要是讲述OWIN框架与OwinHost之间如何根据OWIN协议进行通信构成一套完整的系统.文中我们还直接学习如何直接操作OW ...
- Git学习笔记与IntelliJ IDEA整合
Git学习笔记与IntelliJ IDEA整合 一.Git学习笔记(基于Github) 1.安装和配置Git 下载地址:http://git-scm.com/downloads Git简要使用说明:h ...
- git学习之branch分支
作为新手,站在我的角度肤浅的来理解,分支就是相当于开辟了一个新的临时工作区,在这个工作区进行文件代码改动,然后在合并到master主工作区,这样能保证主工作区的安全性和稳定性,对于团队协作尤为重要. ...
- git学习手册
#git学习手册 git: Git是一个开源的分布式版本控制系统,可以有效.高速的处理从很小到非常大的项目版本管理.[2] Git 是 Linus Torvalds 为了帮助管理 Linux内核开发而 ...
- Git学习笔记(10)——搭建Git服务器
本文主要记录了Git服务器的搭建,以及一些其他的配置,和最后的小总结. Git远程仓库服务器 其实远程仓库和本地仓库没啥不同,远程仓库只是每天24小时开机为大家服务,所以叫做服务器.我们完全可以把自己 ...
随机推荐
- jQuery 隐藏和显示
jQuery 隐藏和显示 通过 hide() 和 show() 两个函数,jQuery 支持对 HTML 元素的隐藏和显示: 实例 $("#hide").click(functio ...
- delphi 金额大小写转换函数
{*------------------------------------------------ 金额大小写转换函数 @author 王云盼 @version V1506.01 在delphi7测 ...
- [bash] 显示配色
#/bin/bash for STYLE in 0 1 2 3 4 5 6 7; do for FG in 30 31 32 33 34 35 36 37; do for BG in 40 41 42 ...
- Quicksort------代码之美
#include<iostream> #include<cstdlib> #include<time.h> using namespace std; void sw ...
- C# LINQ(6)
目前说了 select group...by where from join on equal 这几个关键字,如果经过练习,熟练使用这几个关键字,大部分的LINQ查询基本都是可以完成的. 今天说一下l ...
- Xcode打包提交至itunes connect后,提交审核成功,随后出现二进制文件无效
1.问题描述 Xcode打包提交至itunes connect后,提交审核成功,应用处于待审核状态,过了大概半个小时状态更改为二进制文件无效 2.原因分析 2.1 登陆在苹果中预留的邮箱 ---- 邮 ...
- django中ImageField模块使用
https://blog.csdn.net/meylovezn/article/details/47124923
- Java面向对象之关键字static 入门实例
一.基础概念 静态关键字 static 是成员修饰符,直接用于修饰成员. (一)特点: 1.被静态修饰的成果,可以直接被类名所调用. 2.静态成员优先于对象存在. 3.静态成员随着类的加载而加载.随着 ...
- LAMP课程(3)
LAMP课程(3) 一.bash的使用 1.1.输出重定向 >:覆盖输出(写入内容) 具体实例1:将内容写入到文件中 >>:追加输出 具体实例2: 1.2 && ...
- python中xml解析
import xml.dom.minidom input_xml_string = '''<root><a>hello</a></root>'''#打开 ...